Spark集群环境搭建——服务器环境初始化
Spark也是属于Hadoop生态圈的一部分,需要用到Hadoop框架里的HDFS存储和YARN调度,可以用Spark来替换MR做分布式计算引擎。
接下来,讲解一下spark集群环境的搭建部署。
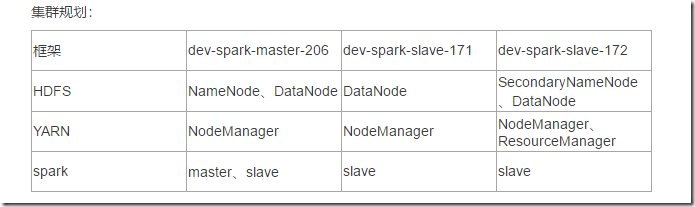
一、集群规划
我们这里使用三台Linux服务器来搭建一个Spark集群。各个组件的分布规划如下:
二、服务器环境初始化
系统初始化:
1、设置系统IP (三台机器都要设置)
每个人的环境都不一样,根据自己的网络环境,设置自己三台机器的ip,最好设置为静态ip,不要每次都从DHCP获取,避免ip发生变动。
我们这里三台机器的ip如下:
dev-spark-master-206:192.168.90.206
dev-spark-slave-171:192.168.90.171
dev-spark-slave-172:192.168.90.172
三台机器都各自设置好静态ip
# dev-spark-master-206
# vi /etc/sysconfig/network-scripts/ifcfg-enp2s0
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static # 改为静态ip
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp2s0
UUID=d7af5ebf-4755-4a35-bcd6-267ab7adbba6
DEVICE=enp2s0
ONBOOT=yes # 开启网卡
IPADDR=192.168.90.206 # 设置属于自己网络的静态ip
NETMASK=255.255.255.0 # 设置掩码
GATEWAY=192.168.90.1 # 设置网关
DNS1=202.96.128.166 # 设置DNS地址
DNS2=8.8.8.8 # 设置副DNS地址
重启网络
systemctl restart network
三台机器都要配置好ip,并确保可以上外网。
2、关闭系统防火墙 (三台机器都要设置)
# 先查看selinux状态
[root@localhost ~]# getenforce
permissive
[root@localhost ~]# setenforce 0
# 修改selinux状态为disabled
[root@localhost ~]# vim /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled # 修改为disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted [root@localhost ~]# 关闭firewalld
# 查看当前状态
[root@localhost ~]# systemctl status firewalld
# 关闭
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
# 清除iptables规则
[root@localhost ~]# iptables -F
3、更换yum源,可选 (三台机器一起设置)
# 这里使用aliyun的yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# 清除yum缓存
yum clean all
yum makecache
4、安装基础软件包 (三台机器一起设置)
yum install -y net-tools vim lrzsz wget tree lsof tcpdump bash-completion.noarch ntp zip unzip git lvm2
yum install -y gcc gcc-c++ libstdc++ make cmake curl bind-utils
5、设置hostname (三台机器一起设置)
我们三台机器的规划是:(可以根据自己的习惯,单独命名)
所以依次设置主机名:
在第一台机器上,修改主机名
hostnamectl set-hostname dev-spark-master-206
第二台机器上,修改主机名
hostnamectl set-hostname dev-spark-slave-171
第三台机器上,修改主机名:
hostnamectl set-hostname dev-spark-slave-172
编辑hosts配置(三台机器都要配置)
三台机器都配置好IP之后,为了方便互相访问,可以配置hosts配置,使用主机名来访问。
# 编辑hosts文件,增加以下配置,根据自己的环境,修改为自己的ip和主机名。 # vim /etc/hosts
192.168.90.206 dev-spark-master-206
192.168.90.171 dev-spark-slave-171
192.168.90.172 dev-spark-slave-172
6、设置ssh免密登录 (三台机器)
1) 在第一台机器上生成一对钥匙,公钥和私钥
# 输入命令,生成秘钥
ssh-keygen -t rsa
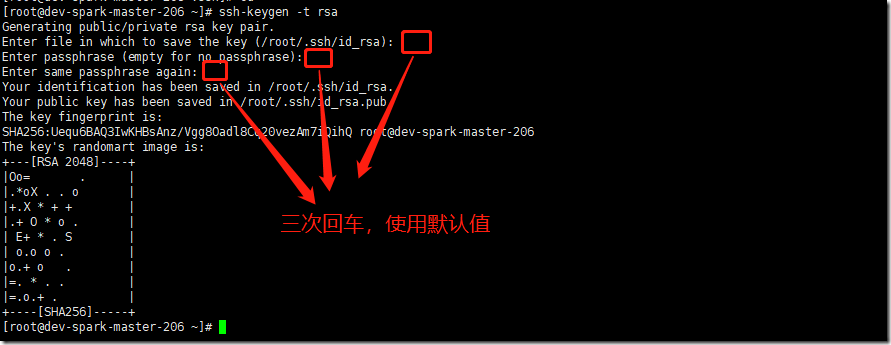
当前用户的宿主目录下的.ssh目录多了两个文件,一个是私钥,一个是公钥
ll /root/.ssh/

2) 将公钥拷贝给要免密码登录的机器
将本机生成的公钥id_rsa.pub文件拷贝到另外两台机器,就可以从另外两台机器免密登录本机了。
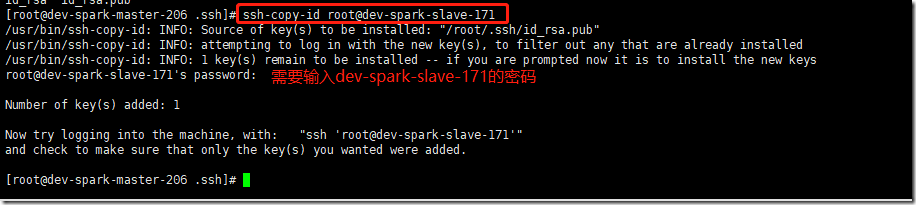
拷贝到dev-spark-slave-171上:
# ssh-copy-id root@dev-spark-slave-171
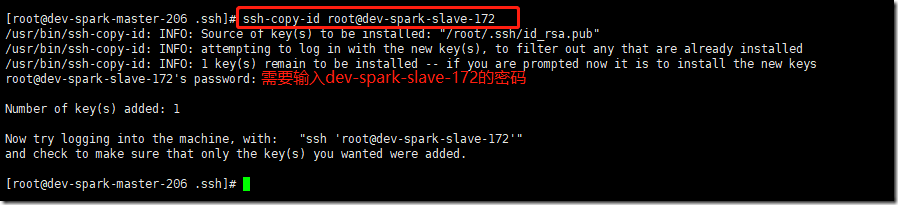
拷贝到dev-spark-slave-172上:
# ssh-copy-id root@dev-spark-slave-172
注意:
注意:
1.主机名和ip都可以(确保配置了主机名 ip的映射)
2.如果出现-bash: ssh-copy-id: command not found,说明ssh-copy-id这个指令没有找到,自己安装下即可
安装命令:yum -y install openssh-clients
如果感觉ssh-copy-id这个命令不好使,你也可以自己新建authorized_keys文件,把公钥贴进去
# 在另外两台机器上
# 查看.ssh目录是否存在
ll /root/.ssh
# 不存在则创建
mkdir /root/.ssh
# 编辑authorized_keys,将第一台机器上生成的id_rsa.pub文件里的内容复制,粘贴在这里。
vim /root/.ssh/authorized_keys
# 因为是自己创建的文件,需要修改权限,文件目录权限不能错
chown -R root.root /root/.ssh
chmod 700 /root/.ssh
chmod 600 /root/.ssh/authorized_keys
3)拷贝完成之后,会在要免密登录的机器(另外两台机器)上生成授权密码文件


在dev-spark-slave-171上,尝试免密登录dev-spark-master-206
ssh root@dev-spark-master-206

在dev-spark-slave-172上,尝试免密登录dev-spark-master-206
ssh root@dev-spark-master-206

4)、在另外两台机器上,重复上述1-3步骤。
注意:免密码登录是单向的,必须要在另外两台机器也生成一对公钥私钥,并把公钥发送到其他服务器上。
最后的结果是:三台机器上,每台机器都有其他两台机器的公钥。才能实现三台机器互相免密登录。
7、设置时间 (三台机器)
# ll /etc/localtime
lrwxrwxrwx. 1 root root 35 Aug 1 2020 /etc/localtime -> ../usr/share/zoneinfo/Asia/Shanghai
# 如果不正确,则修改
mv /etc/localtime /etc/localtime_bak
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # 时钟同步:
# 这里使用aliyun的时钟服务器
crontab -e
*/30 * * * * ntpdate ntp1.aliyun.com
8、时钟同步:
时间同步的方式:在集群中找一台机器,作为时间服务器。(以master为主)
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
ntpdate us.pool.ntp.org;
阿里云时钟同步服务器
ntpdate ntp4.aliyun.com
集群中其他机器与这台机器定时的同步时间,比如,每 隔十分钟,同步一次时间。
8.1、时间服务器配置(必须root用户)(在master上设置)
第一步:确定是否安装了ntpd的服务
如果没有安装,可以进行在线安装
yum -y install ntp
启动ntpd的服务
systemctl start ntpd
设置ntpd的服务开机启动
systemctl enable ntpd
确定是否安装了ntpd的服务
rpm -qa | grep ntpd
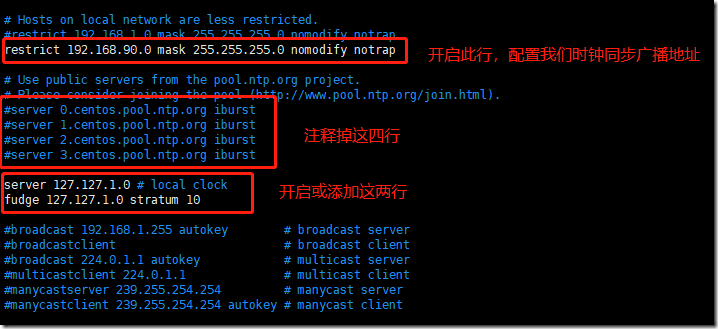
第二步:编辑/etc/ntp.conf
编辑第一台机器器的/etc/ntp.conf
vim /etc/ntp.conf
在文件中添加如下内容
restrict 192.168.90.0 mask 255.255.255.0 nomodify notrap
注释一下四⾏行行内容
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
#server 3.centos.pool.ntp.org
去掉以下内容的注释,如果没有这两行注释,那就自己添加上
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
配置以下内容,保证BIOS与系统时间同步 vim /etc/sysconfig/ntpd
添加一行内容
SYNC_HWLOCK=yes
第三步:
重新启动ntpd
systemctl restart ntpd
systemctl status ntpd
8.2、其他机器配置(必须root用户)
第一步:在其他机器配置10分钟与时间服务器同步一次
# 另外两台机器与192.168.90.206进行时钟同步
# crontab -e
*/10 * * * * /usr/sbin/ntpdate 192.168.90.206
9、安装jdk (三台机器都要配置)
jdk下载地址:https://www.oracle.com/java/technologies/downloads/#java8
查看自带的openjdk
rpm -qa | grep java
如果有自带的,卸载系统自带的openjdk
# 将上面找出来的包复制到下面命令中,使用rpm -e卸载
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps
创建软件包目录:
mkdir -p /data/apps/shell/software
mkdir /usr/java
软件安装目录:/data/apps
自己去oracle官网下载指定版本的jdk,这里使用的是jdk1.8
上传jdk并解压然后配置环境变量
cd /data/apps/shell/software
tar xf jdk-8u162-linux-x64.tar.gz -C /usr/java/
配置环境变量:
vim /etc/profile
# jdk1,8
export JAVA_HOME=/usr/java/jdk1.8.0_162
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
加载profile使立即生效:
source /etc/profile
测试jdk是否生效:
# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
10、编写rsync-script工具:
rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。
scp是把所有文件都复制过去。
基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
rsync案例
10.1、三台虚拟机安装rsync (系统默认已经安装了)
yum install rsync -y
10.2、期望脚本
脚本+要同步的文件名称
10.3. 说明:在/usr/local/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
10.4. 脚本实现
touch rsync-script
vim rsync-script
脚本内容如下:
#!/bin/bash
#1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$# if((paramnum==0)); then
echo no params;
exit;
fi #2 根据传入参数获取文件名称
p1=$1
file_name=`basename $p1`
echo fname=$file_name #3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir #4 获取用户名称
user=`whoami` #5 循环执行rsync
host_arr=("dev-spark-master-206" "dev-spark-slave-171" "dev-spark-slave-172")
for host in ${host_arr[@]}; do
echo ------------------- $host --------------
rsync -rvl $pdir/$file_name $user@$host:$pdir
done
赋予权限:
chmod 777 rsync-script
cp rsync-script /usr/local/sbin/
测试:
touch test
# rsync-script test
fname=test
pdir=/data/apps/shell
------------------- dev-spark-master-206 --------------
sending incremental file list sent 40 bytes received 12 bytes 104.00 bytes/sec
total size is 0 speedup is 0.00
------------------- dev-spark-slave-171 --------------
sending incremental file list
test sent 83 bytes received 35 bytes 236.00 bytes/sec
total size is 0 speedup is 0.00
------------------- dev-spark-slave-172 --------------
sending incremental file list
test sent 83 bytes received 35 bytes 78.67 bytes/sec
total size is 0 speedup is 0.00
Spark集群环境搭建——服务器环境初始化的更多相关文章
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- mesos+marathon+zookeeper的docker管理集群亲手搭建实例(环境Centos6.8)
资源:3台centos6.8虚拟机 4cpu 8G内存 ip 10.19.54.111-113 1台centos6.8虚拟机2cpu 8G ip 10.19.53.55 1.System Requir ...
- spark集群的构建,python环境
个人笔记,问题较多 符号说明 [] 表示其中内容可以没有 su [root] 获取root权限 vi /etc/sudoers 1.点击I或Insert获得插入权限 2.在root ALL=(ALL) ...
- Spark集群环境搭建——部署Spark集群
在前面我们已经准备了三台服务器,并做好初始化,配置好jdk与免密登录等.并且已经安装好了hadoop集群. 如果还没有配置好的,参考我前面两篇博客: Spark集群环境搭建--服务器环境初始化:htt ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
随机推荐
- 数据流中的中位数 牛客网 剑指Offer
数据流中的中位数 牛客网 剑指Offer 题目描述 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就 ...
- best-time-to-buy-and-sell-stock-ii leetcode C++
Say you have an array for which the i th element is the price of a given stock on day i. Design an a ...
- poj 2060 Taxi Cab Scheme(DAG图的最小路径覆盖)
题意: 出租车公司有M个订单. 订单格式: hh:mm a b c d 含义:在hh:mm这个时刻客人将从(a,b)这个位置出发,他(她)要去(c,d)这个位置. 规定1:从(a,b) ...
- Go 日常开发常备第三方库和工具
不知不觉写 Go 已经快一年了,上线了大大小小好几个项目:心态也经历了几轮变化. 因为我个人大概前五年时间写的是 Java ,中途写过一年多的 Python,所以刚接触到 Go 时的感觉如下图: 既没 ...
- LOTO示波器配合VI曲线测试仪在电路板维修中的应用
LOTO示波器配合VI曲线测试仪在电路板维修中的应用 市面上的VI曲线测试仪价格都在2000元到万元不等,同时大多携带不方便,有个别产品可以携带,但是功能单一(比如无法保存曲线,对比曲线等),那么LO ...
- supervisor安装
supervisor管理进程,是通过fork/exec的方式将这些被管理的进程当作supervisor的子进程来启动,所以我们只需要将要管理进程的可执行文件的路径添加到supervisor的配置文件中 ...
- requestAnimationFrame 执行机制探索
1.什么是 requestAnimationFrame window.requestAnimationFrame() 告诉浏览器--你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更 ...
- sql常见题目
1 --student学生表(sno,sname,sex,birthday,tel) 2 --Course课程表(cno,cname) 3 --Sc 学生成绩表(sno,cno,score) 4 1. ...
- [bzoj5338]xor
维护两颗可持久化字典树(当然可以放在一起),第一棵维护每一个点到根的每一位的二进制数量,在其父亲的基础上建立:第二棵维护dfs序上每一个点到第1个点的二进制数量,在其上一个点的基础上建立. 对于询问1 ...
- 简单的MISC,writerup
(Tips:此题是我自己出给新生写的题目) 解压压缩包,发现两个文件,一个压缩包一个图片 尝试解压,发现有密码,正常思路及密码被藏在了图片里 把图片拉进010editor,无发现,再拉进stegsol ...