druid简单教程
一、缓存更新场景介绍
缓存是一种提高系统读性能的常见技术,对于读多写少的应用场景,我们经常使用缓存来进行优化。
例如对于用户的余额信息表account(uid, money),业务上的需求是:
(1)查询用户的余额,SELECT money FROM account WHERE uid=XXX,占99%的请求
(2)更改用户余额,UPDATE account SET money=XXX WHERE uid=XXX,占1%的请求
由于大部分的请求是查询,我们在缓存中建立uid到money的键值对,能够极大降低数据库的压力。
读操作流程
有了数据库和缓存两个地方存放数据之后(uid->money),每当需要读取相关数据时(money),操作流程一般是这样的:
(1)读取缓存中是否有相关数据,uid->money
(2)如果缓存中有相关数据money,则返回【这就是所谓的数据命中“hit”】
(3)如果缓存中没有相关数据money,则从数据库读取相关数据money【这就是所谓的数据未命中“miss”】,放入缓存中uid->money,再返回
缓存的命中率 = 命中缓存请求个数/总缓存访问请求个数 = hit/(hit+miss)
上面举例的余额场景,99%的读,1%的写,这个缓存的命中率是非常高的,会在95%以上。
问题
当数据money发生变化的时候:
(1)是更新缓存中的数据,还是淘汰缓存中的数据呢?
(2)是先操纵数据库中的数据再操纵缓存中的数据,还是先操纵缓存中的数据再操纵数据库中的数据呢?
(3)缓存与数据库的操作,在架构上是否有优化的空间呢?
这是本文关注的三个核心问题。
1.1、更新缓存 VS 淘汰缓存
什么是更新缓存:数据不但写入数据库,还会写入缓存
什么是淘汰缓存:数据只会写入数据库,不会写入缓存,只会把数据淘汰掉
更新缓存的优点:缓存不会增加一次miss,命中率高
淘汰缓存的优点:简单
那到底是选择更新缓存还是淘汰缓存呢,主要取决于“更新缓存的复杂度”。
例如,上述场景,只是简单的把余额money设置成一个值,那么:
(1)淘汰缓存的操作为deleteCache(uid)
(2)更新缓存的操作为setCache(uid, money)
更新缓存的代价很小,此时我们应该更倾向于更新缓存,以保证更高的缓存命中率
如果余额是通过很复杂的数据计算得出来的,例如业务上除了账户表account,还有商品表product,折扣表discount
account(uid, money)
product(pid, type, price, pinfo)
discount(type, zhekou)
业务场景是用户买了一个商品product,这个商品的价格是price,这个商品从属于type类商品,type类商品在做促销活动要打折扣zhekou,购买了商品过后,这个余额的计算就复杂了,需要:
(1)先把商品的品类,价格取出来:SELECT type, price FROM product WHERE pid=XXX
(2)再把这个品类的折扣取出来:SELECT zhekou FROM discount WHERE type=XXX
(3)再把原有余额从缓存中查询出来money = getCache(uid)
(4)再把新的余额写入到缓存中去setCache(uid, money-price*zhekou)
更新缓存的代价很大,此时我们应该更倾向于淘汰缓存。
however,淘汰缓存操作简单,并且带来的副作用只是增加了一次cache miss,建议作为通用的处理方式。
1.2、先操作数据库 vs 先操作缓存
OK,当写操作发生时,假设淘汰缓存作为对缓存通用的处理方式,又面临两种抉择:
(1)先写数据库,再淘汰缓存
(2)先淘汰缓存,再写数据库
究竟采用哪种时序呢?
还记得在《数据库间的一致性:数据库冗余表数据一致性》文章(点击查看)里“究竟先写正表还是先写反表”的结论么?
对于一个不能保证事务性的操作,一定涉及“哪个任务先做,哪个任务后做”的问题,解决这个问题的方向是:
如果出现不一致,谁先做对业务的影响较小,就谁先执行。
由于写数据库与淘汰缓存不能保证原子性,谁先谁后同样要遵循上述原则。
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAIAAACQd1PeAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAyBpVFh0WE1MOmNvbS5hZG9iZS54bXAAAAAAADw/eHBhY2tldCBiZWdpbj0i77u/IiBpZD0iVzVNME1wQ2VoaUh6cmVTek5UY3prYzlkIj8+IDx4OnhtcG1ldGEgeG1sbnM6eD0iYWRvYmU6bnM6bWV0YS8iIHg6eG1wdGs9IkFkb2JlIFhNUCBDb3JlIDUuMC1jMDYwIDYxLjEzNDc3NywgMjAxMC8wMi8xMi0xNzozMjowMCAgICAgICAgIj4gPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4gPHJkZjpEZXNjcmlwdGlvbiByZGY6YWJvdXQ9IiIgeG1sbnM6eG1wPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvIiB4bWxuczp4bXBNTT0iaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wL21tLyIgeG1sbnM6c3RSZWY9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9zVHlwZS9SZXNvdXJjZVJlZiMiIHhtcDpDcmVhdG9yVG9vbD0iQWRvYmUgUGhvdG9zaG9wIENTNSBXaW5kb3dzIiB4bXBNTTpJbnN0YW5jZUlEPSJ4bXAuaWlkOkJDQzA1MTVGNkE2MjExRTRBRjEzODVCM0Q0NEVFMjFBIiB4bXBNTTpEb2N1bWVudElEPSJ4bXAuZGlkOkJDQzA1MTYwNkE2MjExRTRBRjEzODVCM0Q0NEVFMjFBIj4gPHhtcE1NOkRlcml2ZWRGcm9tIHN0UmVmOmluc3RhbmNlSUQ9InhtcC5paWQ6QkNDMDUxNUQ2QTYyMTFFNEFGMTM4NUIzRDQ0RUUyMUEiIHN0UmVmOmRvY3VtZW50SUQ9InhtcC5kaWQ6QkNDMDUxNUU2QTYyMTFFNEFGMTM4NUIzRDQ0RUUyMUEiLz4gPC9yZGY6RGVzY3JpcHRpb24+IDwvcmRmOlJERj4gPC94OnhtcG1ldGE+IDw/eHBhY2tldCBlbmQ9InIiPz6p+a6fAAAAD0lEQVR42mJ89/Y1QIABAAWXAsgVS/hWAAAAAElFTkSuQmCC" alt="" data-s="300,640" data-type="png" data-src="http://mmbiz.qpic.cn/mmbiz/YrezxckhYOyR7CQ7rQic03drREJm157sg6CAcHNibRJeZPlIhWPWZtkH6o0a3I33IljtKDkf4By4tUOqPycwCZ9A/0?wx_fmt=jpeg" data-ratio="0.4482758620689655" data-w="290" />
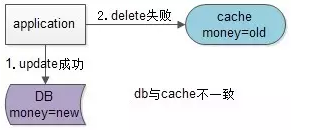
假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。
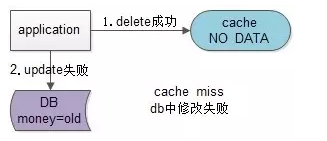
假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。
结论:数据和缓存的操作时序,结论是清楚的:先淘汰缓存,再写数据库。
1.3、缓存架构优化
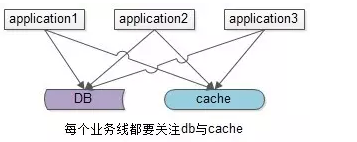
上述缓存架构有一个缺点:业务方需要同时关注缓存与DB,有没有进一步的优化空间呢?有两种常见的方案,一种主流方案,一种非主流方案(一家之言,勿拍)。
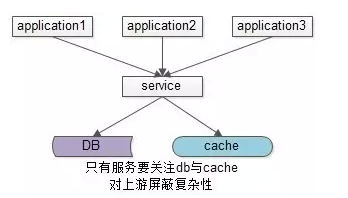
主流优化方案是服务化:加入一个服务层,向上游提供帅气的数据访问接口,向上游屏蔽底层数据存储的细节,这样业务线不需要关注数据是来自于cache还是DB。
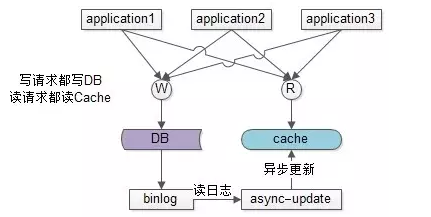
非主流方案是异步缓存更新:业务线所有的写操作都走数据库,所有的读操作都总缓存,由一个异步的工具来做数据库与缓存之间数据的同步,具体细节是:
(1)要有一个init cache的过程,将需要缓存的数据全量写入cache
(2)如果DB有写操作,异步更新程序读取binlog,更新cache
在(1)和(2)的合作下,cache中有全部的数据,这样:
(a)业务线读cache,一定能够hit(很短的时间内,可能有脏数据),无需关注数据库
(b)业务线写DB,cache中能得到异步更新,无需关注缓存
这样将大大简化业务线的调用逻辑,存在的缺点是,如果缓存的数据业务逻辑比较复杂,async-update异步更新的逻辑可能也会比较复杂。
五、其他未尽事宜
本文只讨论了缓存架构设计中需要注意的几个细节点,如果数据库架构采用了一主多从,读写分离的架构,在特殊时序下,还很可能引发数据库与缓存的不一致,这个不一致如何优化,后续的文章再讨论吧。
六、结论强调
(1)淘汰缓存是一种通用的缓存处理方式
(2)先淘汰缓存,再写数据库的时序是毋庸置疑的
(3)服务化是向业务方屏蔽底层数据库与缓存复杂性的一种通用方式
七、那这种问题有什么好办法解决呢?
要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
有一个比较巧妙的作法是,可以将这个不存在的key预先设定一个值。
比如,"key" , “&&”。
在返回这个&&值的时候,我们的应用就可以认为这是不存在的key,那我们的应用就可以决定是否继续等待继续访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取到的值不再是&&,则可以认为这时候key有值了,从而避免了透传到数据库,从而把大量的类似请求挡在了缓存之中。
二、缓存并发
有时候如果网站并发访问高,一个缓存如果失效,可能出现多个进程同时查询DB,同时设置缓存的情况,如果并发确实很大,这也可能造成DB压力过大,还有缓存频繁更新的问题。
我现在的想法是对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询。
这种情况和刚才说的预先设定值问题有些类似,只不过利用锁的方式,会造成部分请求等待。
三、缓存失效
引起这个问题的主要原因还是高并发的时候,平时我们设定一个缓存的过期时间时,可能有一些会设置1分钟啊,5分钟这些,并发很高时可能会出在某一个时间同时生成了很多的缓存,并且过期时间都一样,这个时候就可能引发一当过期时间到后,这些缓存同时失效,请求全部转发到DB,DB可能会压力过重。
那如何解决这些问题呢?
其中的一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
我们讨论的第二个问题时针对同一个缓存,第三个问题时针对很多缓存。
总结来看:
1、缓存穿透:查询一个必然不存在的数据。比如文章表,查询一个不存在的id,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成影响。
2、缓存失效:如果缓存集中在一段时间内失效,DB的压力凸显。这个没有完美解决办法,但可以分析用户行为,尽量让失效时间点均匀分布。
当发生大量的缓存穿透,例如对某个失效的缓存的大并发访问就造成了缓存雪崩。
转自:http://mp.weixin.qq.com/s/CY4jntpM7VNkBrz1FKRsOw
druid简单教程的更多相关文章
- Git和Github简单教程
原文链接:Git和Github简单教程 网络上关于Git和GitHub的教程不少,但是这些教程有的命令太少不够用,有的命令太多,使得初期学习的时候需要额外花不少时间在一些当前用不到的命令上. 这篇文章 ...
- FusionCharts简单教程(三)-----如何自定义图表上的工具提示
最近有蛮多人总是问我这个FusionCharts制表的问题,帮助他们解决之后,在昨晚发现以前整理的笔记中有这个简单教程,而且以前也发表了几篇这个博文,所以就将其全部上传上来供别人参考.如有不正确之处望 ...
- FusionCharts简单教程(八)-----使用网格组件
有时候我们会觉得使用图像不够直接,对于数据的显示没有表格那样直接明了.所以这里就介绍如何使用网格组件.将网格与图像结合起来.网格组件能够将FusionCharts中的单序列数据以列表的 ...
- Qt Quick 简单教程
上一篇<Qt Quick 之 Hello World 图文详解>我们已经分别在电脑和 Android 手机上运行了第一个 Qt Quick 示例—— HelloQtQuickApp ,这篇 ...
- Git和Github简单教程(收藏)
原文链接:Git和Github简单教程 目录: 零.Git是什么 一.Git的主要功能:版本控制 二.概览 三.Git for Windows软件安装 四.本地Git的使用 五.Github与Git的 ...
- mysql安装简单教程(自动安装/配置安装)
mysql安装简单教程(自动安装/配置安装) 1.1前言: 由于特殊原因,在最近2-3个月里mysql真是安装了无数遍,每次安装都要上网找教程,每个教程基本都不一样,因此还是自己写下来比较好,毕竟自己 ...
- 平衡树简单教程及模板(splay, 替罪羊树, 非旋treap)
原文链接https://www.cnblogs.com/zhouzhendong/p/Balanced-Binary-Tree.html 注意是简单教程,不是入门教程. splay 1. 旋转: 假设 ...
- LayaAir引擎开发HTML5最简单教程(面向JS开发者)
LayaAir引擎开发HTML5最简单教程(面向JS开发者) 一.总结 一句话总结:开发游戏还是得用游戏引擎来开发,其实很简单啦 切记:开发游戏还是得用游戏引擎来开发,其实很简单,引擎很多东西都帮你做 ...
- mockito简单教程
注:本文来源:sdyy321的<mockito简单教程> 官网: http://mockito.org API文档:http://docs.mockito.googlecode.com/h ...
随机推荐
- A Case for Flash Memory SSD in Enterprise Database Applications
通过分析固态硬盘的特性对数据库中不同对象,如:表,索引,回滚段,重做日志等的应用进行具体研究,最后将数据库中不同的对象进行区别应用
- Linux初始root密码设置
刚安装好的Linux系统是没有设置root用户密码的,下边介绍如何设置root用户的密码 第一步:sudo passwd 第二步:输入密码 第三步:确认密码 这样三个步骤过后root用户的密码就设置好 ...
- java StringBuffer与StringBuilder
StringBuffer:就是字符串缓冲区. * 用于存储数据的容器. * 特点: * 1,长度的可变的. * 2,可以存储不同类型数 ...
- PHPExcel说明
下面是总结的几个使用方法include 'PHPExcel.php';include 'PHPExcel/Writer/Excel2007.php';//或者include 'PHPExcel/Wri ...
- PHP页面中文乱码分析
php出现出现乱码的原因:页面文件的编码方式(.html,.php等).html.head中指定浏览器的编码方式.MySql数据库传输的编码方式.Apache字符集. PHP页面中文乱码出现的原因有几 ...
- 原创:Javascript循环队列类
需要滚动显示最多一定数量的信息,于弄了个这个 var LeesCircleQueue=function(size) { // 队列数组 var _queue=[]; // 队首索引 var _fron ...
- android报表图形引擎(AChartEngine)demo解析与源码
AchartEngine支持多种图表样式,本文介绍两种:线状表和柱状表. AchartEngine有两种启动的方式:一种是通过ChartFactory.get***View()方式来直接获取到view ...
- php的post和get方法
<?php function post($url,$fields) { $fields_string = ''; foreach($fields as $key=>$value) { $f ...
- js二级下拉菜单
看似简单的一个菜单,确需要不少的知识点 1. getByClass getElementsByClassName 已经有大部分现代浏览器支持了,只有ie6,ie7,ie8是不支持的.所以对ie6,7, ...
- Docker 监控- Prometheus VS Cloud Insight
如今,越来越多的公司开始使用 Docker 了,2 / 3 的公司在尝试了 Docker 后最终使用了它.为了能够更精确的分配每个容器能使用的资源,我们想要实时获取容器运行时使用资源的情况,怎样对 D ...