Kafka实战:如何把Kafka消息时延秒降10倍
背景
国内某大型税务系统,业务应用分布式上云改造。
业务难题
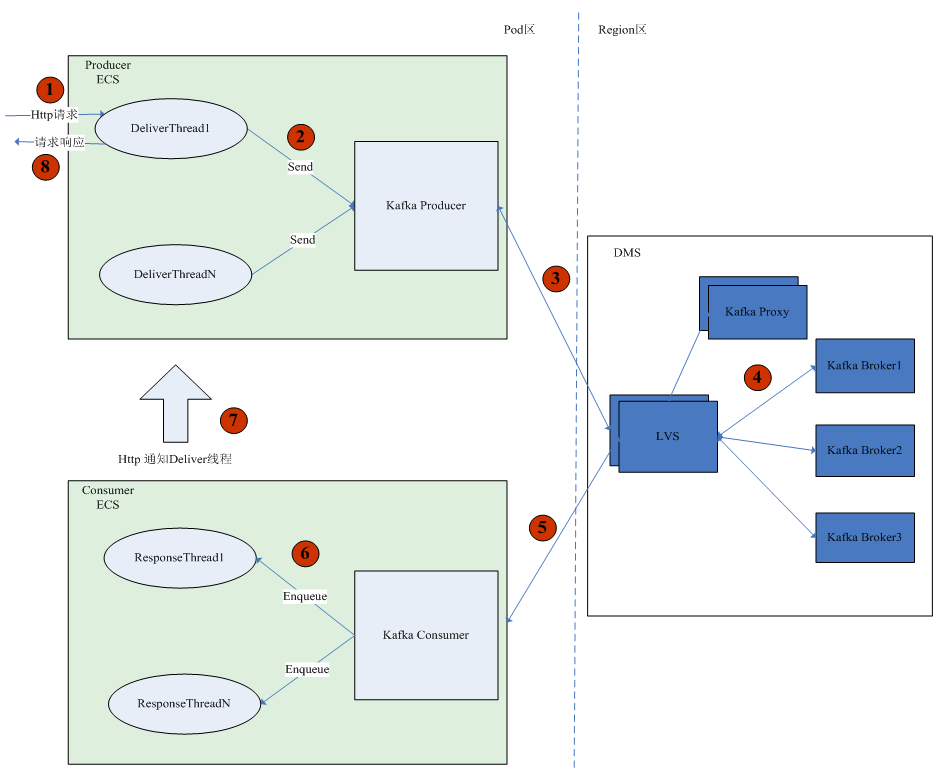
如上图所示是模拟客户的业务网页构建的一个并发访问模型。用户在页面点击从而产生一个HTTP请求,这个请求发送到业务生产进程,就会启动一个投递线程(Deliver Thread)调用Kafka的SDK接口,并发送3条消息到DMS(分布式消息服务),每条消息大小3k,需要等待3条消息都被处理完成后才会返回请求响应⑧。当消息达到DMS后,业务消费进程调用Kafka的消费接口把消息取出来,然后将每条消息放到一个响应线程(Response Thread)中进行处理,响应线程处理完后,通过HTTP请求通知投递线程,投递线程收到响应后返回回复响应。
100并发访问时延500ms,未达成用户业务要求
客户提出了明确的要求:每1个两核的ECS要能够支撑并发访问量100,每条消息端到端的时延范围是几十毫秒,即从生产者发送开始到接收到消费者响应的时间。客户实测在使用了DMS的Kafka 队列后,并发访问量为100时时延高达到500ms左右,甚至出现达到秒级的时延,远未达到客户提出的业务诉求。相比较而言,客户在Pod区使用的是自己搭建的原生Kafka,在并发访问量为100时测试到的时延大约只有10~20ms左右。那么问题来了,在并发访问量相同的条件下,DMS的Kafka 队列与Pod区自建的原生Kafka相比为什么时延会有这么大的差异呢?我们DMS的架构师 Mr. Peng对这个时延难题进行了一系列分析后完美解决了这个客户难题,下面就让我们来看看他的心路历程。
难题剖析
根据模拟的客户业务模型,Mr. Peng在华为云类生产环境上也构造了一个测试程序,同样模拟构造了100的并发访问量,通过测试发现,类生产环境上压测得到的时延平均时间在60ms左右。类生产上的时延数值跟客户在真实生产环境上测到的时延差距这么大,这是怎么回事呢?问题变得扑朔迷离起来。
Mr. Peng当机立断,决定就在华为云现网上运行构造的测试程序,来看看到底是什么原因。同时,在客户的ECS服务器上,也部署了相同的测试程序,模拟构建了100的并发量,得到如下的时延结果对比表:
|
调优前时延 |
现网时延(ms) |
类生产时延(ms) |
|
100并发 |
500ms ~ 4000ms |
40ms ~ 80 ms |
|
1并发 |
31ms |
6ms |
|
Ping测试 |
0.9ms ~ 1.2ms |
0.3ms ~ 0.4ms |
表1 华为云现网与类生产环境时延对比表
从时延对比表的结果看来,Mr. Peng发现,即使在相同的并发压力下,华为云现网的时延比类生产差很多。Mr. Peng意识到,现在有2个问题需要分析:为什么华为云现网的时延会比类生产差?DMS的Kafka队列时延比原生自建的Kafka队列时延表现差的问题怎么解决?Mr. Peng进行了如下分析:
时延分析
回归问题的本质,DMS Kafka队列的时延到底是怎么产生的?可控的端到端时延具体分为哪些?Mr. Peng给出了如下的计算公式:
总时延 = 入队时延 + 发送时延 + 写入时延 + 复制时延 + 拉取时延
让我们来依次了解一下,公式中的每一项都是指什么。
入队时延: 消息进入Kafka sdk后,先进入到要发送分区的队列,完成消息打包后再发送,这一过程所用的时间。
发送时延:消息从生产者发送到服务端的时间。
写入时延:消息写入到Kafka Leader的时间。
复制时延:消费者只可以消费到高水位以下的消息(即被多个副本都保存的消息),所以消息从写入到Kafka Leader,到所有副本都写入该消息直到上涨至高水位这段时间就是消息复制的时延。
拉取时延:消费者采用pull模式拉取数据,拉取过程所用的时间。
(1) 入队时延
现网是哪一部分的时延最大呢?通过我们的程序可以看到,入队列等待发送时延非常大,如下图:

即消息都等待在生产端的队列中,来不及发送!
我们再看其他时延分析,因为无法在现网测试,我们分别在类生产测试了相同压力的,测试其他各种时延如下:
(2) 复制时延
以下是类生产环境测试的1并发下的

从日志上看,复制时延包括在remoteTime里面,当然这个时间也会包括生产者写入时延比较慢导致的,但是也从一定的程度反映复制时延也是提升性能时延的一个因素。
(3) 写入时延
因为用户使用的是高吞吐队列,写入都是异步落盘,我们从日志看到写入时延非常低(localTime),可以判断不是瓶颈
发送时延与拉取时延都是跟网络传输有关系,这个优化主要是通过调TCP的参数来决定的。轻轻松松把Kafka消息时延秒降10倍,就用华为云DMS
Kafka实战:如何把Kafka消息时延秒降10倍的更多相关文章
- Kafka实战宝典:Kafka的控制器controller详解
一.控制器简介 控制器组件(Controller),是 Apache Kafka 的核心组件.它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群.集群中任意一 ...
- Flink-Kafka-Connector Flink结合Kafka实战
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- Kafka实战-实时日志统计流程
1.概述 在<Kafka实战-简单示例>一文中给大家介绍来Kafka的简单示例,演示了如何编写Kafka的代码去生产数据和消费数据,今天给大家介绍如何去整合一个完整的项目,本篇博客我打算为 ...
- Kafka实战(七) - 优雅地部署 Kafka 集群
既然是集群,必然有多个Kafka节点,只有单节点构成的Kafka伪集群只能用于日常测试,不可能满足线上生产需求. 真正的线上环境需要考量各种因素,结合自身的业务需求而制定.看一些考虑因素(以下顺序,可 ...
随机推荐
- 动态代理在WEB与JDBC开发中的应用
WEB案例 目前有一个2005年开始,基于Struts1的Web项目A,其验证部分依赖于主站的SSO(单点登录).在请求站点A的时候,用户会被强制带去做SSO验证,通过身份验证后后,主站会自动地把请求 ...
- https与http的访问,应对苹果ATS验证问题
为应对2017年1月1日苹果ATS的问题,微信.微博等等APP要求挂载的网页必须https访问,需要添加ssl认证. 一.SSL认证 选取了阿里云提供的免费SSL,使用期限为一年.电话咨询阿里客服,免 ...
- VMware 12虚拟机下Ubuntu 16连不上网解决方法
打开自带Firefox浏览器,显示连接不上网,终端下 ping 也显示 unkown 解决方法: 1.打开虚拟机的“编辑”选项,选择“虚拟网络编辑器” 2.选择VMnet8(我不知道为啥VMnet ...
- C++_运算符重载 总结
什么是运算符的重载? 运算符与类结合,产生新的含义. 为什么要引入运算符重载? 作用:为了实现类的多态性(多态是指一个函数名有多种含义) 怎么实现运算符的重载? 方式:类的成员函数 或 友元函数(类外 ...
- Invalid character found in the request target.The valid characters are defined in RFC 7230 and RFC3986
Tomcat在 7.0.73, 8.0.39, 8.5.7 版本后,添加了对于http头的验证. 具体来说,就是添加了些规则去限制HTTP头的规范性 参考这里 具体来说: org.apache.tom ...
- Getting start with dbus in systemd (01) - Interface, method, path
Getting start with dbus in systemd (01) 基本概念 几个概念 dbus name: connetion: 如下,第一行,看到的就是 "dbus name ...
- pyinstaller打包问题总结
1.pyinstaller常见用法 -w:禁止cmd窗口 -F:打包为单文件 比如:pyinstaller -w -F test.py 2.QT中UI转py文件 pyuic5 test.ui -o t ...
- STM32 内存管理实验
参考原文<STM32F1开发指南> 内存管理简介 内存管理,是指软件运行时对计算机内存资源的分配和使用的技术.最主要的目的是如何高效.快速的分配,并且在适当的时候释放和回收内存资源.内存管 ...
- ACM多校联赛7 2018 Multi-University Training Contest 7 1009 Tree
[题意概述] 给一棵以1为根的树,树上的每个节点有一个ai值,代表它可以传送到自己的ai倍祖先,如果不存在则传送出这棵树.现在询问某个节点传送出这棵树需要多少步. [题解] 其实是把“弹飞绵羊”那道题 ...
- Python基础—面向对象(进阶篇)
通过上一篇博客我们已经对面向对象有所了解,下面我们先回顾一下上篇文章介绍的内容: 上篇博客地址:http://www.cnblogs.com/phennry/p/5606718.html 面向对象是一 ...