Hadoop MapReduce基本原理
一、什么是:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
源于Google MapReduce论文(04年)。
MapReduce的核心是:分而治之,并行处理;以及其调度和处理数据的自动化。
Hadoop中MR的主要内容:
hadoop序列化writable接口,数据类型
应用开发 (debug 单元测试)解决基本数据处理,作业调优
工作机制 作业提交流程,作业调度,shuffle与排序
MR类型 输入输出类型
特性:二次排序(全排、部分排),join
压缩算法
二、基本流程:
1、MR中主要是Map和Reduce两个阶段,其中基本流程是:
1、mr的数据处理单位是一个split,一个split对应一个map任务,处理时会有多个map任务同时运行;当map从HDFS上读取一个split时,这里会有“移动计算,不移动数据”的机制来减少网络的数据传输,使得效率能最大化;
2、获取到split时,默认会以TextInputFormat的格式读入,文件中的字符位置的偏移量作为 key,以及每一行的数据作为 value;
3、之后则进入map函数中进行处理,这个阶段可以获取需要的数据并加以处理,并以key value的形式写出,作为后面reduce函数的输入;
4、map到reduce之间会有一个shuffle的过程,大致过程是把不同key利用partitioner分散到各个reduce节点上去;
5、在reduce上会先通过 比较排序(前面shuffl会有预排序) 进行文件的归并,之后进入reduce函数,在每个reduce函数中key是唯一的,对应的value则是一个 Iterable接口类型,通过Iterable可以遍历所有当前key对应的所有value;
6、之后在reduce中对数据进行处理后,利用OutputFormat对处理后的key value保存到HDFS上即完成了整个流程。
注:一个split的大小计算:max( minimumSize, min( maximumSize, blockSize ));
通常 blockSize 在 minimumSize和maximumSize之间,所以一般分片大小就是块大小。
2、流程图:
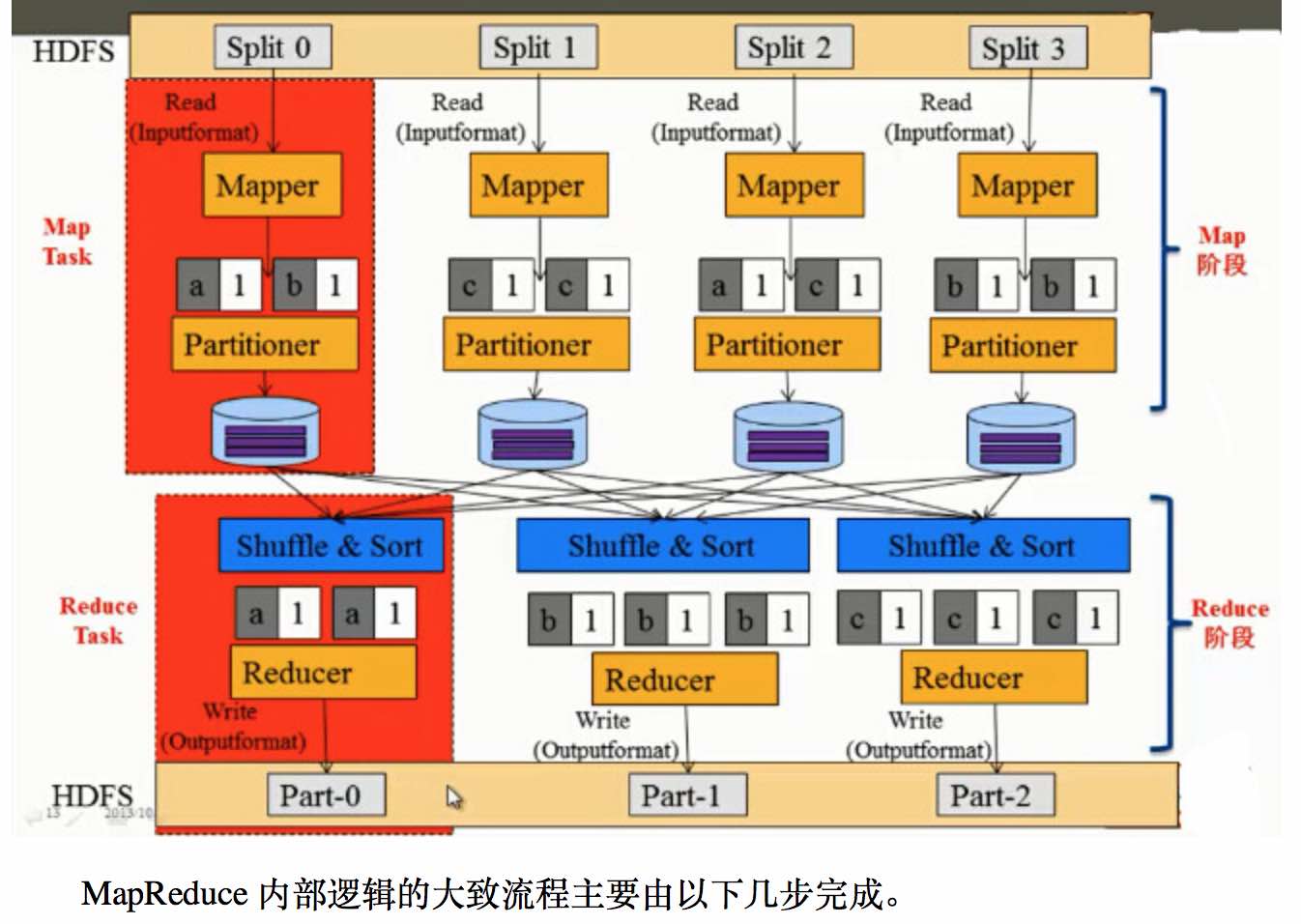
3、编程中可定制的类:
InputFormat —> Mapper —> Partitioner (HashPartitioner) —> Combiner —> Reducer —> OutputFormat
4、shuffle过程:map输出 到 reduce获取数据的过程。
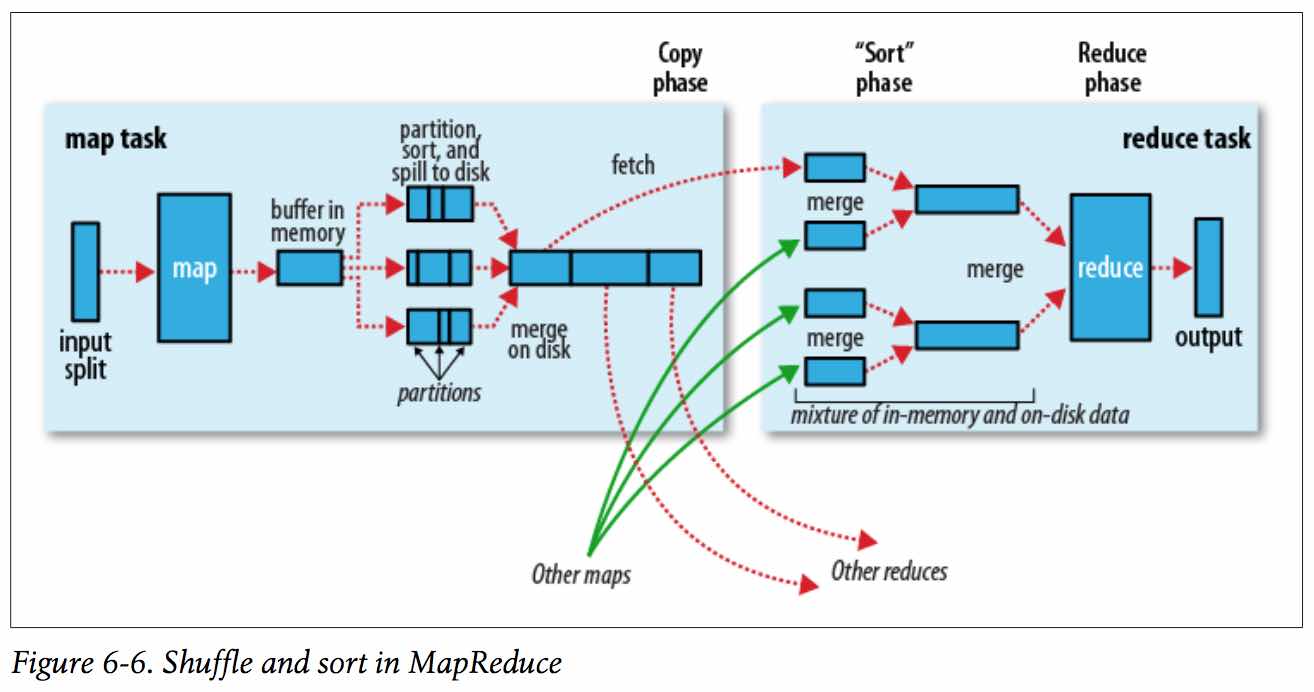
三、优缺点:
优点:
Hadoop MapReduce基本原理的更多相关文章
- 从分治算法到 Hadoop MapReduce
从分治算法说起 要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 .其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再 ...
- python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍 59888745@qq.com 大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽), 把用户的交易 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
文章为作者原创,未经许可,禁止转载. -Sun Yat-sen University 冯兴伟 一. 项目简介: 电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
随机推荐
- 【二叉树】hdu 1710 Binary Tree Traversals
acm.hdu.edu.cn/showproblem.php?pid=1710 [题意] 给定一棵二叉树的前序遍历和中序遍历,输出后序遍历 [思路] 根据前序遍历和中序遍历递归建树,再后续遍历输出 m ...
- SpringBoot项目整合Druid进行统计监控
0.druid介绍,参考官网 1.在项目的POM文件中添加alibaba的druid依赖 <dependency> <groupId>com.alibaba</group ...
- 16.1113 模拟考试T3
城堡[问题描述]给定一张N个点M条边的无向连通图,每条边有边权.我们需要从M条边中选出N − 1条, 构成一棵树. 记原图中从 1 号点到每个节点的最短路径长度为?Di ,树中从 1 号点到每个节点的 ...
- dos中定义变量与获取常见的引用变量以及四则运算、备份文件(set用法)
在dos中使用set定义变量: set a=8 (注意等号两边没有空格) 引用变量如: echo %a% 将打印a的值 (%a%是获取变量a的值) dos中 ...
- 安卓解析JSON文件
安卓解析JSON文件 根据JOSN文件的格式,文件只有两种数据,一是对象数据,以 {}为分隔,二是数组,以[]分隔 以下介绍安卓如何解析一个JSON文件,该文件存放在assets目录下,即:asset ...
- hdu 2686 费用流 / 双线程DP
题意:给一个方阵,求从左上角出到右下角(并返回到起点),经过每个点一次不重复,求最大获益(走到某处获得改点数值),下来时每次只能向右或向下,反之向上或向左. 俩种解法: 1 费用流法:思路转化:从左 ...
- 安装破解版的webstorne
参考以下链接:https://www.cnblogs.com/cui-cui/p/8507435.html
- 2018.11.6 PION 模拟赛
期望:100 + 40 + 50 = 190 实际:60 + 10 + 50 = 120 考得好炸啊!!T1数组开小了炸掉40,T2用 int 读入 long long ,int存储 long lon ...
- Android-事件体系全面总结+实践分析
事件分发在Android中是很重要的基础知识,网上相关的文章也很多,但是花了很多精力看了很多别人的分析总结,最终的感觉还是似懂非懂,所以决定自己动手研究一下,去发现其中的规律.本文顺着我自己的思路去研 ...
- websocket笔记
本文为原创,转载请注明出处: cnzt 文章:cnzt-p http://www.cnblogs.com/zt-blog/p/6742746.html websocket -- 双向通信网 ...