【关系抽取-R-BERT】模型结构
模型的整体结构
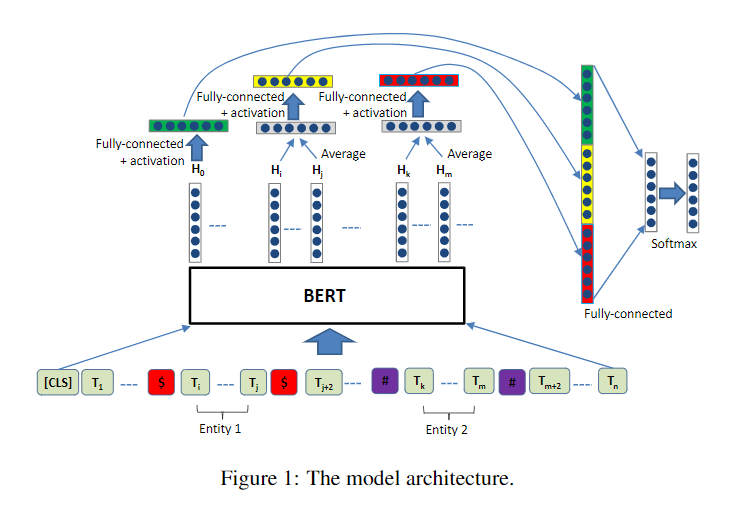
相关代码
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
class FCLayer(nn.Module):
def __init__(self, input_dim, output_dim, dropout_rate=0.0, use_activation=True):
super(FCLayer, self).__init__()
self.use_activation = use_activation
self.dropout = nn.Dropout(dropout_rate)
self.linear = nn.Linear(input_dim, output_dim)
self.tanh = nn.Tanh()
def forward(self, x):
x = self.dropout(x)
if self.use_activation:
x = self.tanh(x)
return self.linear(x)
class RBERT(BertPreTrainedModel):
def __init__(self, config, args):
super(RBERT, self).__init__(config)
self.bert = BertModel(config=config) # Load pretrained bert
self.num_labels = config.num_labels
self.cls_fc_layer = FCLayer(config.hidden_size, config.hidden_size, args.dropout_rate)
self.entity_fc_layer = FCLayer(config.hidden_size, config.hidden_size, args.dropout_rate)
self.label_classifier = FCLayer(
config.hidden_size * 3,
config.num_labels,
args.dropout_rate,
use_activation=False,
)
@staticmethod
def entity_average(hidden_output, e_mask):
"""
Average the entity hidden state vectors (H_i ~ H_j)
:param hidden_output: [batch_size, j-i+1, dim]
:param e_mask: [batch_size, max_seq_len]
e.g. e_mask[0] == [0, 0, 0, 1, 1, 1, 0, 0, ... 0]
:return: [batch_size, dim]
"""
e_mask_unsqueeze = e_mask.unsqueeze(1) # [b, 1, j-i+1]
length_tensor = (e_mask != 0).sum(dim=1).unsqueeze(1) # [batch_size, 1]
# [b, 1, j-i+1] * [b, j-i+1, dim] = [b, 1, dim] -> [b, dim]
sum_vector = torch.bmm(e_mask_unsqueeze.float(), hidden_output).squeeze(1)
avg_vector = sum_vector.float() / length_tensor.float() # broadcasting
return avg_vector
def forward(self, input_ids, attention_mask, token_type_ids, labels, e1_mask, e2_mask):
outputs = self.bert(
input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids
) # sequence_output, pooled_output, (hidden_states), (attentions)
sequence_output = outputs[0]
pooled_output = outputs[1] # [CLS]
# Average
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
# Dropout -> tanh -> fc_layer (Share FC layer for e1 and e2)
pooled_output = self.cls_fc_layer(pooled_output)
e1_h = self.entity_fc_layer(e1_h)
e2_h = self.entity_fc_layer(e2_h)
# Concat -> fc_layer
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=-1)
logits = self.label_classifier(concat_h)
outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
# Softmax
if labels is not None:
if self.num_labels == 1:
loss_fct = nn.MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)
代码解析
- 首先我们来看RBERT类,它继承了BertPreTrainedModel类,在类初始化的时候要传入两个参数:config和args,config是模型相关的,args是其它的一些配置。
- 假设输入的input_ids, attention_mask, token_type_ids, labels, e1_mask, e2_mask的维度分别是:(16表示的是batchsize的大小,384表示的是设置的句子的最大长度)
input_ids.shape= torch.Size([16, 384])
attention_mask.shape= torch.Size([16, 384])
token_type_ids.shape= torch.Size([16, 384])
labels.shape= torch.Size([16])
e1_mask.shape= torch.Size([16, 384])
e2_mask.shape= torch.Size([16, 384])
经过原始的bert之后得到output,其中outputs[0]的维度是[16,384,768],也就是每一个句子的表示,outputs[1]表示的是经过池化之后的句子表示,维度是[16,768],意思是将384个字的每个维度的特征通过池化将信息聚合在一起。 - 对于sequence_output, e1_mask或者sequence_output, e2_mask,我们将他们分别传入到entity_averag函数中,针对于e1_mask或者e2_mask,他们的维度都是[16,384],然后进行变换为[16,1,384],通过将[16,1,384]和[16,384,768]进行矩阵相乘,就得到了实体的特征表示,维度是[16,1,768],去除掉第1维再除以实体的长度进行归一化,最终得到一个[16,768]的表示。
- 我们将cls,也就是outputs[1],和实体1以及实体2的特征表示进行拼接,得到一个维度为[16,2304]的张量,再经过一个全连接层映射成[16,19],这里的19是类别的数目,最后使用相关的损失函数计算损失即可。
使用
最后是这么使用的:
定义相关参数以及设置
self.args = args
self.train_dataset = train_dataset
self.dev_dataset = dev_dataset
self.test_dataset = test_dataset
self.label_lst = get_label(args)
self.num_labels = len(self.label_lst)
self.config = BertConfig.from_pretrained(
args.model_name_or_path,
num_labels=self.num_labels,
finetuning_task=args.task,
id2label={str(i): label for i, label in enumerate(self.label_lst)},
label2id={label: i for i, label in enumerate(self.label_lst)},
)
self.model = RBERT.from_pretrained(args.model_name_or_path, config=self.config, args=args)
# GPU or CPU
self.device = "cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu"
self.model.to(self.device)
【关系抽取-R-BERT】模型结构的更多相关文章
- 学习笔记CB003:分块、标记、关系抽取、文法特征结构
分块,根据句子的词和词性,按照规则组织合分块,分块代表实体.常见实体,组织.人员.地点.日期.时间.名词短语分块(NP-chunking),通过词性标记.规则识别,通过机器学习方法识别.介词短语(PP ...
- 【关系抽取-R-BERT】定义训练和验证循环
[关系抽取-R-BERT]加载数据集 [关系抽取-R-BERT]模型结构 [关系抽取-R-BERT]定义训练和验证循环 相关代码 import logging import os import num ...
- Bert模型实现垃圾邮件分类
近日,对近些年在NLP领域很火的BERT模型进行了学习,并进行实践.今天在这里做一下笔记. 本篇博客包含下列内容: BERT模型简介 概览 BERT模型结构 BERT项目学习及代码走读 项目基本特性介 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- NLP(二十一)人物关系抽取的一次实战
去年,笔者写过一篇文章利用关系抽取构建知识图谱的一次尝试,试图用现在的深度学习办法去做开放领域的关系抽取,但是遗憾的是,目前在开放领域的关系抽取,还没有成熟的解决方案和模型.当时的文章仅作为笔者的 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 图示详解BERT模型的输入与输出
一.BERT整体结构 BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务.整体架 ...
随机推荐
- module patterns
module patterns ebooks https://github.com/xyzata/2017-new-ebooks/blob/master/Succinctly/modulepatter ...
- 高级数据结构之 BloomFilter
高级数据结构之 BloomFilter 布隆过滤器 https://en.wikipedia.org/wiki/Bloom_filter A Bloom filter is a space-effic ...
- Flutter: 使用相机拍照
文档 camera import 'dart:io'; import 'package:camera/camera.dart'; import 'package:flutter/material.da ...
- 调整是为了更好的上涨,牛市下的SPC空投来了!
2021年刚过没几天,比特币就开启了牛市的旅程,BTC涨到4万美元,ETH涨到1300多美元,BGV也涨到了621.05美元,牛市已然来袭. 虽然从近两日,比特币带领着主流币进行了一波调整,但是只涨不 ...
- 鸿蒙js开发7 鸿蒙分组列表和弹出menu菜单
鸿蒙入门指南,小白速来!从萌新到高手,怎样快速掌握鸿蒙开发?[课程入口]目录:1.鸿蒙视图效果2.js业务数据和事件3.页面视图代码4.跳转页面后的视图层5.js业务逻辑部分6.<鸿蒙js开发& ...
- 如何使用irealtime.js实现一个基于websocket的同步画板
同步画板演示 同时打开2个tab,分别在画布上写下任意内容,观察演示结果,同时可设置画笔颜色及线条宽度.演示地址 初始化画布 <canvas id="drawBoard" w ...
- docker08容器监控工具-WeaveScope
容器监控工具WeaveScope 一 背景 在生成环境中k8s应用部署众多,需要一款可视化工具方便日常获知集群的实时状态,并为故障排查提供及时和准确的数据支持. weavescope支持docker和 ...
- yum install valgrind.x86_64
Reference: https://cloudlinux.zendesk.com/hc/en-us/articles/115004075294-Fix-rpmdb-Thread-died-in-Be ...
- Java基础语法:abstract修饰符
一.简介 描述: 'abstract'修饰符可以用来修饰方法,也可以修饰类. 如果修饰方法,那么该方法就是抽象方法:如果修饰类,那么该类就是抽象类. 抽象类和抽象方法起到一个框架作用,方便后期扩展的重 ...
- TcaplusDB服务体系揭秘
导言 TcaplusDB是腾讯出品的分布式NoSQL数据库,存储和调度的代码完全自研.具备缓存+落地融合架构.PB级存储.毫秒级时延.无损水平扩展和复杂数据结构等特性.同时具备丰富的生态.便捷的迁移. ...