python 常用的库
本节大纲:
- 模块介绍
- time &datetime模块
- random
- os
- sys
- shutil
- json & picle
- shelve
- xml处理
- yaml处理
- configparser
- hashlib
- subprocess
- logging模块
- re正则表达式
模块,用一砣代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
自定义模块 和开源模块的使用参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块导入方法
1 import 语句
import module1[, module2[,... moduleN]
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path里。
['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu',
'/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
2 from…import 语句
from modname import name1[, name2[, ... nameN]]
这个声明不会把整个modulename模块导入到当前的命名空间中,只会将它里面的name1或name2单个引入到执行这个声明的模块的全局符号表。
3 From…import* 语句
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
4 运行本质
#1 import test
#2 from test import add
无论1还是2,首先通过sys.path找到test.py,然后执行test脚本(全部执行),区别是1会将test这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:
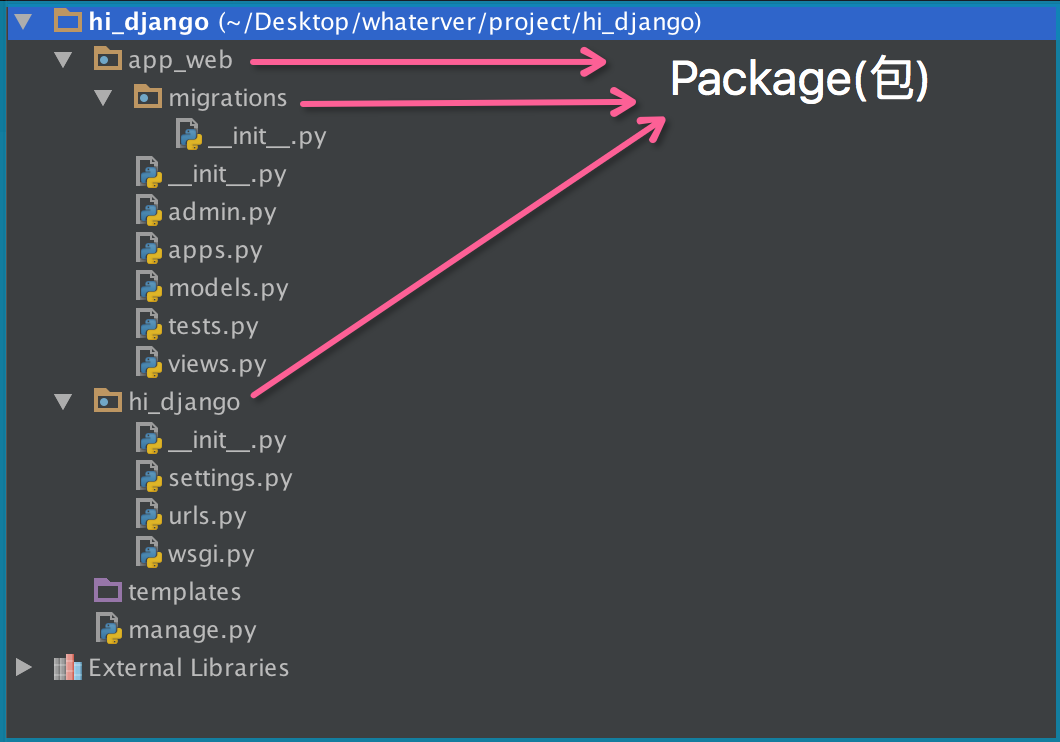
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
注意点(important)
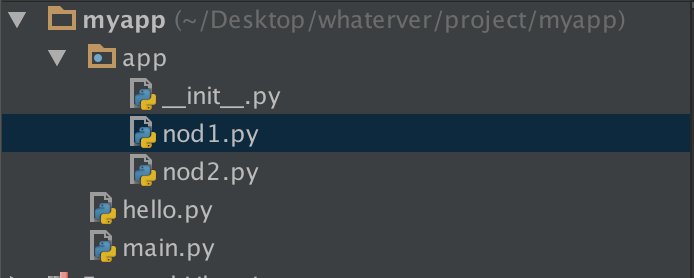
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
import sys,os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
import hello
hello.hello1()
2 --------------
if __name__=='__main__':
print('ok')
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!s
3


##-------------cal.py
def add(x,y): return x+y
##-------------main.py
import cal #from module import cal def main(): cal.add(1,2) ##--------------bin.py
from module import main main.main()
包中包调用模块:
eg:调用包web1中包web2下模块logger中的logger函数
from web1.web2 import logger
logger.logger() from web1.web2.logger import logger logger()
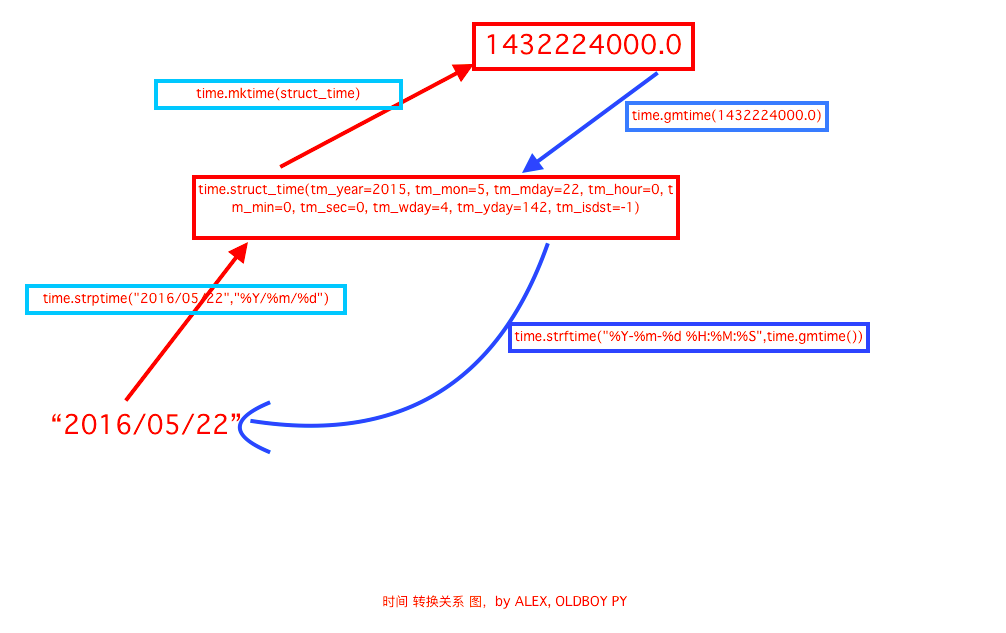
time & datetime模块
| Directive | Meaning | Notes |
|---|---|---|
%a |
Locale’s abbreviated weekday name. | |
%A |
Locale’s full weekday name. | |
%b |
Locale’s abbreviated month name. | |
%B |
Locale’s full month name. | |
%c |
Locale’s appropriate date and time representation. | |
%d |
Day of the month as a decimal number [01,31]. | |
%H |
Hour (24-hour clock) as a decimal number [00,23]. | |
%I |
Hour (12-hour clock) as a decimal number [01,12]. | |
%j |
Day of the year as a decimal number [001,366]. | |
%m |
Month as a decimal number [01,12]. | |
%M |
Minute as a decimal number [00,59]. | |
%p |
Locale’s equivalent of either AM or PM. | (1) |
%S |
Second as a decimal number [00,61]. | (2) |
%U |
Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. | (3) |
%w |
Weekday as a decimal number [0(Sunday),6]. | |
%W |
Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. | (3) |
%x |
Locale’s appropriate date representation. | |
%X |
Locale’s appropriate time representation. | |
%y |
Year without century as a decimal number [00,99]. | |
%Y |
Year with century as a decimal number. | |
%z |
Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. | |
%Z |
Time zone name (no characters if no time zone exists). | |
%% |
A literal '%' character. |
random模块
随机数
1 mport random
2 print random.random()
3 print random.randint(1,2)
4 print random.randrange(1,10)
生成随机验证码
1 import random
2 checkcode = ''
3 for i in range(4):
4 current = random.randrange(0,4)
5 if current != i:
6 temp = chr(random.randint(65,90))
7 else:
8 temp = random.randint(0,9)
9 checkcode += str(temp)
10 print checkcode
OS模块
提供对操作系统进行调用的接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
更多猛击这里 https://docs.python.org/2/library/os.html?highlight=os#module-os
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
shutil 模块
直接参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
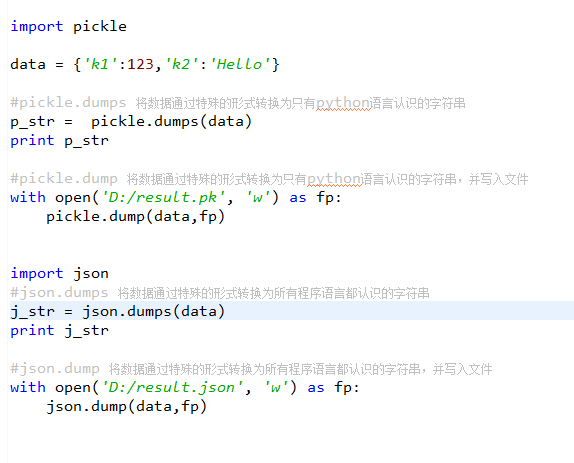
json & pickle 模块
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
shelve 模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
d = shelve.open('shelve_test') #打开一个文件
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #持久化列表
d["t1"] = t #持久化类
d["t2"] = t2
d.close()
xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
自己创建xml文档
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
ConfigParser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
来看一个好多软件的常见文档格式如下
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'} config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
写完了还可以再读出来哈。
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
'50022'
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
configparser增删改查语法
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello")
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass '''
import hashlib # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hmac
h = hmac.new(b'天王盖地虎', b'宝塔镇河妖')
print h.hexdigest()
更多关于md5,sha1,sha256等介绍的文章看这里https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
Subprocess模块
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes. This module intends to replace several older modules and functions:
os.system
os.spawn*
The recommended approach to invoking subprocesses is to use the run() function for all use cases it can handle. For more advanced use cases, the underlying Popen interface can be used directly.
The run() function was added in Python 3.5; if you need to retain compatibility with older versions, see the Older high-level API section.
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False)
Run the command described by args. Wait for command to complete, then return a CompletedProcess instance.
The arguments shown above are merely the most common ones, described below in Frequently Used Arguments (hence the use of keyword-only notation in the abbreviated signature). The full function signature is largely the same as that of the Popen constructor - apart from timeout, input and check, all the arguments to this function are passed through to that interface.
This does not capture stdout or stderr by default. To do so, pass PIPE for the stdout and/or stderr arguments.
The timeout argument is passed to Popen.communicate(). If the timeout expires, the child process will be killed and waited for. The TimeoutExpired exception will be re-raised after the child process has terminated.
The input argument is passed to Popen.communicate() and thus to the subprocess’s stdin. If used it must be a byte sequence, or a string if universal_newlines=True. When used, the internal Popen object is automatically created withstdin=PIPE, and the stdin argument may not be used as well.
If check is True, and the process exits with a non-zero exit code, a CalledProcessError exception will be raised. Attributes of that exception hold the arguments, the exit code, and stdout and stderr if they were captured.
常用subprocess方法示例
#执行命令,返回命令执行状态 , 0 or 非0
>>> retcode = subprocess.call(["ls", "-l"])#执行命令,如果命令结果为0,就正常返回,否则抛异常
>>> subprocess.check_call(["ls", "-l"])
0#接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
>>> subprocess.getstatusoutput('ls /bin/ls')
(0, '/bin/ls')#接收字符串格式命令,并返回结果
>>> subprocess.getoutput('ls /bin/ls')
'/bin/ls'#执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
>>> res=subprocess.check_output(['ls','-l'])
>>> res
b'total 0\ndrwxr-xr-x 12 alex staff 408 Nov 2 11:05 OldBoyCRM\n'#上面那些方法,底层都是封装的subprocess.Popen
poll()
Check if child process has terminated. Returns returncodewait()
Wait for child process to terminate. Returns returncode attribute.terminate() 杀掉所启动进程
communicate() 等待任务结束stdin 标准输入
stdout 标准输出
stderr 标准错误pid
The process ID of the child process.#例子
>>> p = subprocess.Popen("df -h|grep disk",stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
>>> p.stdout.read()
b'/dev/disk1 465Gi 64Gi 400Gi 14% 16901472 104938142 14% /\n'>>> subprocess.run(["ls", "-l"]) # doesn't capture output
CompletedProcess(args=['ls', '-l'], returncode=0) >>> subprocess.run("exit 1", shell=True, check=True)
Traceback (most recent call last):
...
subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1 >>> subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE)
CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0,
stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null\n')调用subprocess.run(...)是推荐的常用方法,在大多数情况下能满足需求,但如果你可能需要进行一些复杂的与系统的交互的话,你还可以用subprocess.Popen(),语法如下:
p = subprocess.Popen("find / -size +1000000 -exec ls -shl {} \;",shell=True,stdout=subprocess.PIPE)
print(p.stdout.read())可用参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。- shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
需要交互的命令示例
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write('print 1 \n ')
obj.stdin.write('print 2 \n ')
obj.stdin.write('print 3 \n ')
obj.stdin.write('print 4 \n ') out_error_list = obj.communicate(timeout=10)
print out_error_listsubprocess实现sudo 自动输入密码
import subprocess def mypass():
mypass = '123' #or get the password from anywhere
return mypass echo = subprocess.Popen(['echo',mypass()],
stdout=subprocess.PIPE,
) sudo = subprocess.Popen(['sudo','-S','iptables','-L'],
stdin=echo.stdout,
stdout=subprocess.PIPE,
) end_of_pipe = sudo.stdout print "Password ok \n Iptables Chains %s" % end_of_pipe.read()logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为
debug(),info(),warning(),error()andcritical() 5个级别,下面我们看一下怎么用。最简单用法
import logging logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down") #输出
WARNING:root:user [alex] attempted wrong password more than 3 times
CRITICAL:root:server is down看一下这几个日志级别分别代表什么意思
Level When it’s used DEBUGDetailed information, typically of interest only when diagnosing problems. INFOConfirmation that things are working as expected. WARNINGAn indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. ERRORDue to a more serious problem, the software has not been able to perform some function. CRITICALA serious error, indicating that the program itself may be unable to continue running.
如果想把日志写到文件里,也很简单
import logging logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.') #输出
12/12/2010 11:46:36 AM is when this event was logged.日志格式
%(name)s
Logger的名字
%(levelno)s
数字形式的日志级别
%(levelname)s
文本形式的日志级别
%(pathname)s
调用日志输出函数的模块的完整路径名,可能没有
%(filename)s
调用日志输出函数的模块的文件名
%(module)s
调用日志输出函数的模块名
%(funcName)s
调用日志输出函数的函数名
%(lineno)d
调用日志输出函数的语句所在的代码行
%(created)f
当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d
输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d
线程ID。可能没有
%(threadName)s
线程名。可能没有
%(process)d
进程ID。可能没有
%(message)s
用户输出的消息
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
文件自动截断例子
re模块
常用正则表达式符号
意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.splitall 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
S(DOTALL): 点任意匹配模式,改变'.'的行为
python 常用的库的更多相关文章
- python常用三方库 - openpyxl
目录 python常用三方库 - openpyxl 读取Excel文件 写入Excel文件 python常用三方库 - openpyxl openpyxl是一个第三方库, 可以处理xlsx格式的Exc ...
- Python常用的库简单介绍一下
Python常用的库简单介绍一下fuzzywuzzy ,字符串模糊匹配. esmre ,正则表达式的加速器. colorama 主要用来给文本添加各种颜色,并且非常简单易用. Prettytable ...
- python常用第三方库(转载)
Python标准库与第三方库详解(转载) 转载地址: http://www.codeweblog.com/python%e6%a0%87%e5%87%86%e5%ba%93%e4%b8%8e%e7%a ...
- python常用函数库收集。
学习过Python都知道python中有很多库.python本身就是万能胶水,众多强大的库/模块正是它的优势. 收集一些Python常用的函数库,方便大家选择要学习的库,也方便自己学习收集,熟悉运用好 ...
- python常用删除库的方法
本文记于初学py的时候,两年后补发. python常用库的安装方法一般有几种,比如: 1.编译过的exe包,直接无脑下一步就可以了. 2.pip install 库名,快速安装.自动匹配最新版本. 3 ...
- 吐血整理!Python常用第三方库,码住!!!
Python作为一种编程语言近年来越来越受欢迎,它为什么这么火? 其中一个重要原因就是因为Python的库丰富--Python语言提供超过15万个第三方库,Python库之间广泛联系.逐层封装.几 ...
- python常用工具库介绍
Numpy:科学计算 HOME: http://www.numpy.org/ NumPy is the fundamental package for scientific computing wi ...
- python常用函数 库 转
可能经常用到的标准模块和第三方常用的50个库 本文由python培训班授课老师整理 数学计算: numbers - Numeric abstract base classes math ...
- python常用数据处理库
Python之所以能够成为数据分析与挖掘领域的最佳语言,是有其独特的优势的.因为他有很多这个领域相关的库可以用,而且很好用,比如Numpy.SciPy.Matploglib.Pandas.Scikit ...
随机推荐
- javascript和XML
一,浏览器对XML DOM的支持1,DOM2级核心 var xmldom = document.implementation.createDocument("","roo ...
- 2019南昌网络赛H The Nth Item(二阶线性数列递推 + 广义斐波那契循环节 + 分段打表)题解
题意: 传送门 已知\(F(n)=3F(n-1)+2F(n-2) \mod 998244353,F(0)=0,F(1)=1\),给出初始的\(n_1\)和询问次数\(q\),设每一次的答案\(a_i= ...
- 12.tomcat7切换tomcat8导致cookie异常
一.现象 换成Tomcat8后出现cookie报错 二.分析 经异常去查看源码发现,Tomcat8对cookie校验规则改变,更为严格的校验了cookieHeader不允许有, 日志中的[XXXXX, ...
- hdu5303贪心
http://acm.hdu.edu.cn/showproblem.php?pid=5303 说一下题目大意.. 有一个长为L的环..你家在原点位置0,那么剩下L-1个点上种有一些树, 给你树的位置和 ...
- Code Book All In One
Code Book All In One Jupyter Notebook Jupyter Lab https://jupyter.org/ Storybook https://storybook.j ...
- js with All In One
js with All In One 不推荐,要废弃 function f(x, o) { with (o) { console.log(x); } } function f(foo, values) ...
- HTMLMediaElement.srcObject & URL.createObjectURL & HTMLMediaElement.src
HTMLMediaElement.srcObject & URL.createObjectURL & HTMLMediaElement.src Uncaught TypeError: ...
- API 注解 & Java API annotation
API 注解 & Java API annotation 注解 annotation
- react slot component with args
react slot component with args how to pass args to react props child component https://codesandbox.i ...
- Nodejs file path to url path
import * as path from 'path'; import * as url from 'url'; const savePath = path.join('public', 'imag ...