JVM之调优及常见场景分析
JVM调优
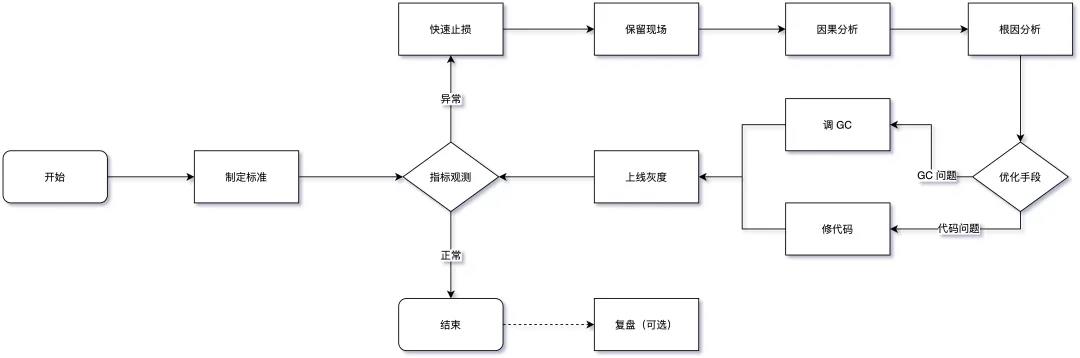
GC调优是最后要做的工作,GC调优的目的可以总结为下面两点:
- 减少对象晋升到老年代的数量
- 减少FullGC的执行时间
通过监控排查问题及验证优化结果,可以分为:
- 命令监控:jps、jinfo、jstack、jmap、jstat、jhat
- 图形化监控:JConsole和VisualVM
- 阿里巴巴开源的 Java 诊断工具:Arthas(阿尔萨斯):
如果GC执行时间满足下列所有条件,就没有必要进行GC优化了:
- Minor GC执行非常迅速(50ms以内)
- Minor GC没有频繁执行(大约10s执行一次)
- Full GC执行非常迅速(1s以内)
- Full GC没有频繁执行(大约10min执行一次)
案例参考:
常见场景分析
动态扩容引起的空间震荡
现象
服务刚刚启动时 GC 次数较多,最大空间剩余很多但是依然发生 GC,这种情况我们可以通过观察 GC 日志或者通过监控工具来观察堆的空间变化情况即可。GC Cause 一般为 Allocation Failure,且在 GC 日志中会观察到经历一次 GC ,堆内各个空间的大小会被调整,如下图所示:

原因分析
在 JVM 的参数中 -Xms 和 -Xmx 设置的不一致,在初始化时只会初始 -Xms 大小的空间存储信息,每当空间不够用时再向操作系统申请,这样的话必然要进行一次 GC。另外,如果空间剩余很多时也会进行缩容操作,JVM 通过 -XX:MinHeapFreeRatio 和 -XX:MaxHeapFreeRatio 来控制扩容和缩容的比例,调节这两个值也可以控制伸缩的时机。
解决方案
尽量将成对出现的空间大小配置参数设置成固定的,如 -Xms 和 -Xmx,-XX:MaxNewSize 和 -XX:NewSize,-XX:MetaSpaceSize 和 -XX:MaxMetaSpaceSize 等。不过在不追求停顿时间的情况下震荡的空间也是有利的,可以动态地伸缩以节省空间,例如作为富客户端的 Java 应用。
显式GC的去和留
现象
手动调用 System.gc 方法会引发一次 STW 的 Full GC,对整个堆做收集,可以在 GC 日志中的 GC Cause 中确认。同时JVM提供-XX:+DisableExplicitGC 参数可以避免这种 GC。那么有没有必要启用该参数呢?
去留分析
首先需要了解下DirectByteBuffer,它有着零拷贝等特点,被 Netty 等各种 NIO 框架使用,会使用到堆外内存。它的 Native Memory 的清理工作是通过 sun.misc.Cleaner 自动完成的,是一种基于虚引用PhantomReference的清理工具,比普通的 Finalizer 轻量些。而为 DirectByteBuffer 分配空间过程中会显式调用 System.gc ,希望通过 Full GC 来强迫已经无用的 DirectByteBuffer 对象释放掉它们关联的 Native Memory。
如果通过-XX:+DisableExplicitGC关闭显式GC,DirectByteBuffer分配空间中System.gc将失效,这时如果很长一段时间没有做过GC或者只做了Young GC,则不会触发Cleaner 的工作,Native Memory得不到及时释放,有可能发生内存泄漏。
所以一般建议保留显式GC,但需要规范使用,避免频繁GC带来的性能开销。可通过-XX:+ExplicitGCInvokesConcurrent 和 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses 参数来将 System.gc 的触发类型从 Foreground 改为 Background,同时 Background 也会做 Reference Processing,这样的话就能大幅降低了 STW 开销,同时也不会发生 NIO Direct Memory OOM。
MetaSpace 区 OOM
现象
JVM 在启动后或者某个时间点开始,MetaSpace 的已使用大小在持续增长,同时每次 GC 也无法释放,调大 MetaSpace 空间也无法彻底解决。
原因分析
Java 7 之前字符串常量池被放到了 Perm 区,所有被 intern 的 String 都会被存在这里,由于 String.intern 是不受控的,所以 -XX:MaxPermSize 的值也不太好设置,经常会出现 java.lang.OutOfMemoryError: PermGen space 异常。但在 Java 7 之后常量池等字面量(Literal)、类静态变量(Class Static)、符号引用(Symbols Reference)等几项被移到 Heap 中,PermGen 也被移除,取而代之的是 MetaSpace。在最底层,JVM 通过 mmap 接口向操作系统申请内存映射,每次申请 2MB 空间,这里是虚拟内存映射,不是真的就消耗了主存的 2MB,只有之后在使用的时候才会真的消耗内存。申请的这些内存放到一个链表中 VirtualSpaceList,作为其中的一个 Node。
关键原因就是 ClassLoader 不停地在内存中 load 了新的 Class ,一般这种问题都发生在动态类加载等情况上。
解决方案
dump 快照之后通过 JProfiler 或 MAT 观察 Classes 的 Histogram(直方图)即可,或者直接通过命令即可定位, jcmd 打几次 Histogram 的图,看一下具体是哪个包下的 Class 增加较多就可以定位了。
jcmd <PID> GC.class_stats|awk '{print$13}'|sed 's/\(.*\)\.\(.*\)/\1/g'|sort |uniq -c|sort -nrk1
经常会出问题的几个点有 Orika 的 classMap、JSON 的 ASMSerializer、Groovy 动态加载类等,基本都集中在反射、Javasisit 字节码增强、CGLIB 动态代理、OSGi 自定义类加载器等的技术点上。
过早晋升
现象
- 分配速率接近于晋升速率,对象晋升年龄较小
- Full GC 比较频繁,且经历过一次 GC 之后 Old 区的变化比例非常大
原因分析及策略
- Young/Eden 区过小:一般情况下 Old 的大小应当为活跃对象的 2~3 倍左右,考虑到浮动垃圾问题最好在 3 倍左右,剩下的都可以分给 Young 区
- 分配速率过大:
- 偶发较大:通过内存分析工具找到问题代码,从业务逻辑上做一些优化
- 一直较大:当前的 Collector 已经不满足应用程序的期望了,这种情况要么增加应用程序的 机器,要么调整 GC 收集器类型或加大空间
CMS Old GC频繁
现象
Old 区频繁的做 CMS GC,但是每次耗时不是特别长,整体最大 STW 也在可接受范围内,但由于 GC 太频繁导致吞吐下降比较多。
原因分析
基本都是一次 Young GC 完成后,负责处理 CMS GC 的一个后台线程 concurrentMarkSweepThread 会不断地轮询,使用 shouldConcurrentCollect() 方法做一次检测,判断是否达到了回收条件。如果达到条件(参考上文中CMS GC触发条件),使用 collect_in_background() 启动一次 Background 模式 GC。轮询的判断是使用 sleepBeforeNextCycle() 方法,间隔周期为 -XX:CMSWaitDuration 决定,默认为2s。
解决方案
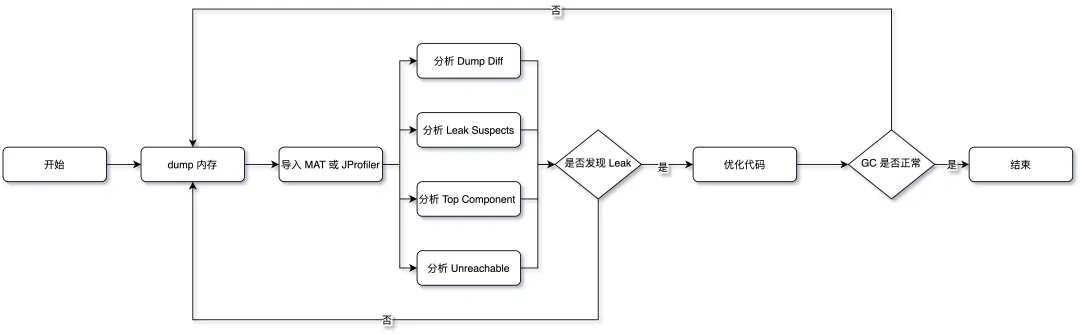
- Dump Diff:分别在 CMS GC 的发生前后分别 dump 一次,进行dump文件差异分析
- Leak Suspects:内存泄露报告
- Top Component分析:按照对象、类、类加载器、包等多个维度观察 Histogram,同时使用 outgoing 和 incoming 分析关联的对象,另外就是 Soft Reference 和 Weak Reference、Finalizer 等也要看一下
- Unreachable分析:不可达对象分析
单次 CMS Old GC 耗时长
现象
CMS GC 单次 STW 最大超过 1000ms,不会频繁发生。但这种场景非常危险,某些场景下会引起“雪崩效应”,我们应该尽量避免出现。
原因分析
可能造成STW的情况如下:
Init Mark

整个过程比较简单,从 GC Root 出发标记 Old 中的对象,处理完成后借助 BitMap 处理下 Young 区对 Old 区的引用,整个过程基本都比较快,很少会有较大的停顿。
Final Mark
Final Remark 的开始阶段与 Init Mark 处理的流程相同,但是后续多了 Card Table 遍历、Reference 实例的清理,并将其加入到 Reference 维护的
pend_list中,如果要收集元数据信息,还要清理 SystemDictionary、CodeCache、SymbolTable、StringTable 等组件中不再使用的资源。STW前等待应用线程到达安全点(较少发生)
由此可见,大部分问题都出在 Final Remark 过程,观察详细 GC 日志,找到出问题时 Final Remark 日志,分析下 Reference 处理和元数据处理 real 耗时是否正常,详细信息需要通过 -XX:+PrintReferenceGC 参数开启。基本在日志里面就能定位到大概是哪个方向出了问题,耗时超过 10% 的就需要关注。
一般来说最容易出问题的地方就是 Reference 中的 FinalReference 和元数据信息处理中的 scrub symbol table 两个阶段,想要找到具体问题代码就需要内存分析工具 MAT 或 JProfiler 了,注意要 dump 即将开始 CMS GC 的堆。在用 MAT 等工具前也可以先用命令行看下对象 Histogram,有可能直接就能定位问题。
- 对 FinalReference 的分析主要观察
java.lang.ref.Finalizer对象的 dominator tree,找到泄漏的来源。经常会出现问题的几个点有 Socket 的SocksSocketImpl、Jersey 的ClientRuntime、MySQL 的ConnectionImpl等等。 - scrub symbol table 表示清理元数据符号引用耗时,符号引用是 Java 代码被编译成字节码时,方法在 JVM 中的表现形式,生命周期一般与 Class 一致,当
_should_unload_classes被设置为 true 时在CMSCollector::refProcessingWork()中与 Class Unload、String Table 一起被处理。
解决方案
一般不会大面积同时爆发,不过有很多时候单台 STW 的时间会比较长,如果业务影响比较大,及时摘掉流量,具体后续优化策略如下:
- FinalReference:找到内存来源后通过优化代码的方式来解决,如果短时间无法定位可以增加
-XX:+ParallelRefProcEnabled对 Reference 进行并行处理。 - symbol table:观察 MetaSpace 区的历史使用峰值,以及每次 GC 前后的回收情况,一般没有使用动态类加载或者 DSL 处理等,MetaSpace 的使用率上不会有什么变化,这种情况可以通过
-XX:-CMSClassUnloadingEnabled来避免 MetaSpace 的处理,JDK8 会默认开启 CMSClassUnloadingEnabled,这会使得 CMS 在 CMS-Remark 阶段尝试进行类的卸载。
内存碎片&收集器退化
现象
并发的 CMS GC 算法,退化为 Foreground 单线程串行 GC 模式,STW 时间超长,有时会长达十几秒。其中 CMS 收集器退化后单线程串行 GC 算法有两种:
- 带压缩动作的算法,称为 MSC,上面我们介绍过,使用标记-清理-压缩,单线程全暂停的方式,对整个堆进行垃圾收集,也就是真正意义上的 Full GC,暂停时间要长于普通 CMS。
- 不带压缩动作的算法,收集 Old 区,和普通的 CMS 算法比较相似,暂停时间相对 MSC 算法短一些。
原型分析
- 晋升失败(Promotion Failed):old空间不足或者碎片导致晋升失败,由于concurrentMarkSweepThread 和担保机制的存在,发生的条件是很苛刻的
- 增量收集担保失败:分配内存失败后,会判断统计得到的 Young GC 晋升到 Old 的平均大小,以及当前 Young 区已使用的大小也就是最大可能晋升的对象大小,是否大于 Old 区的剩余空间。只要 CMS 的剩余空间比前两者的任意一者大,CMS 就认为晋升还是安全的,反之,则代表不安全,不进行Young GC,直接触发Full GC。
- 显示GC
- 并发模式失败(Concurrent Mode Failure)
解决方案
分析到具体原因后,我们就可以针对性解决了,具体思路还是从根因出发,具体解决策略:
- 内存碎片:通过配置
-XX:UseCMSCompactAtFullCollection=true来控制 Full GC的过程中是否进行空间的整理(默认开启,注意是Full GC,不是普通CMS GC),以及-XX: CMSFullGCsBeforeCompaction=n来控制多少次 Full GC 后进行一次压缩(可以使用-XX:PrintFLSStatistics来观察内存碎片率情况,然后再设置具体的值) - 增量收集:降低触发 CMS GC 的阈值,即参数
-XX:CMSInitiatingOccupancyFraction的值,让 CMS GC 尽早执行,以保证有足够的连续空间,也减少 Old 区空间的使用大小,另外需要使用-XX:+UseCMSInitiatingOccupancyOnly来配合使用,不然 JVM 仅在第一次使用设定值,后续则自动调整。 - 浮动垃圾:视情况控制每次晋升对象的大小,或者缩短每次 CMS GC 的时间,必要时可调节 NewRatio 的值。另外就是使用
-XX:+CMSScavengeBeforeRemark在过程中提前触发一次 Young GC,防止后续晋升过多对象。
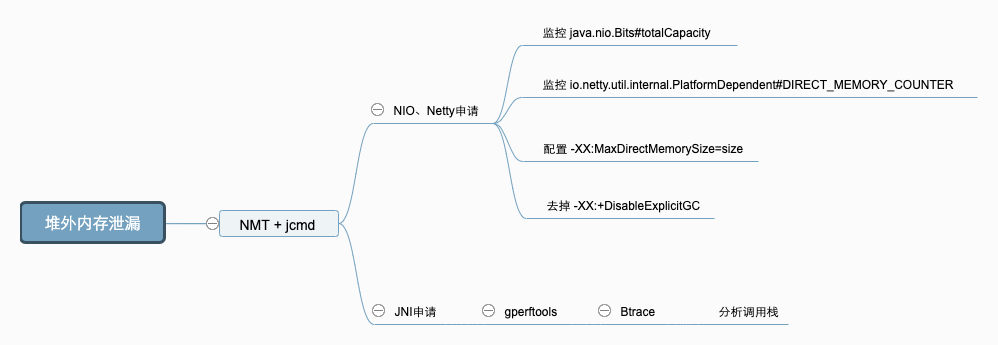
堆外内存OOM
现象
内存使用率不断上升,甚至开始使用 SWAP 内存,同时可能出现 GC 时间飙升,线程被 Block 等现象,通过 top 命令发现 Java 进程的 RES 甚至超过了 -Xmx 的大小。出现这些现象时,基本可以确定是出现了堆外内存泄漏。
原因分析
JVM 的堆外内存泄漏,主要有两种的原因:
- 通过
UnSafe#allocateMemory,ByteBuffer#allocateDirect主动申请了堆外内存而没有释放,常见于 NIO、Netty 等相关组件。 - 代码中有通过 JNI 调用 Native Code 申请的内存没有释放。
解决方案
首先可以使用 NMT(NativeMemoryTracking) + jcmd 分析泄漏的堆外内存是哪里申请,确定原因后,使用不同的手段,进行原因定位。
JVM之调优及常见场景分析的更多相关文章
- 性能测试三十六:内存溢出和JVM常见参数及JVM参数调优
堆内存溢出: 此种溢出,加内存只能缓解问题,不能根除问题,需优化代码堆内存中存在大量对象,这些对象都有被引用,当所有对象占用空间达到堆内存的最大值,就会出现内存溢出OutOfMemory:Java h ...
- JVM、垃圾回收、内存调优、常见參数
一.什么是JVM JVM是Java Virtual Machine(Java虚拟机)的缩写.JVM是一种用于计算设备的规范.它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现 ...
- JVM性能调优(3) —— 内存分配和垃圾回收调优
前序文章: JVM性能调优(1) -- JVM内存模型和类加载运行机制 JVM性能调优(2) -- 垃圾回收器和回收策略 一.内存调优的目标 新生代的垃圾回收是比较简单的,Eden区满了无法分配新对象 ...
- JVM性能调优与实战基础理论篇-上
Java虚拟机 概述 Java官方文档 https://docs.oracle.com/en/java/index.html JVM是一种规范,通过Oracle Java 官方文档找到JVM的规范查阅 ...
- jvm的调优
首先我们要知道jvm的调优,主要是对那些部分的优化.通过jvm内存模型我们可以,首先是分析遇到的问题,然后通过一些工具或者手段找到问题所在,然后通过一定的措施解决问题,下面我们也将按着这个思路来给出具 ...
- JVM性能调优实践——JVM篇
前言 在遇到实际性能问题时,除了关注系统性能指标.还要结合应用程序的系统的日志.堆栈信息.GClog.threaddump等数据进行问题分析和定位.关于性能指标分析可以参考前一篇JVM性能调优实践-- ...
- 【学习】011 JVM参数调优配置
自动内存管理机制 Java虚拟机原理 所谓虚拟机,就是一台虚拟的机器.他是一款软件,用来执行一系列虚拟计算指令,大体上虚拟机可以分为 系统虚拟机和程序虚拟机, 大名鼎鼎的Visual Box.Vmar ...
- JVM常用调优工具介绍
前言 王子在之前的JVM文章中已经大体上把一些原理性问题说清楚了,今天主要是介绍一些实际进行JVM调优工作的工具和命令,不会深入讲解,因为网上资料很多,篇幅可能不长,但都是实用的内容,小伙伴们有不清楚 ...
- JAVA系列之JVM内存调优
一.前提 JVM性能调优牵扯到各方面的取舍与平衡,往往是牵一发而动全身,需要全盘考虑各方面的影响.在优化时候,切勿凭感觉或经验主义进行调整,而是需要通过系统运行的客观数据指标,不断找到最优解.同时,在 ...
随机推荐
- KafkaBroker 简析
Kafka 依赖 Zookeeper 来维护集群成员的信息: Kafka 使用 Zookeeper 的临时节点来选举 controller Zookeeper 在 broker 加入集群或退出集群时通 ...
- SSH Keys vs GPG Keys
SSH Keys vs GPG Keys SSH Keys SSH keys allow you to establish a secure connection between your compu ...
- node os env reader
node os env reader node-os-env-reader.js #!/usr/bin/env node "use strict"; /** * * @author ...
- React Learning Paths
React Learning Paths React Expert React in Action The assessment may cover: Components Events and Bi ...
- 3D 室内装修线设计软件
3D 室内装修线设计软件 WebGL & canvas https://threejs.org/ xgqfrms 2012-2020 www.cnblogs.com 发布文章使用:只允许注册用 ...
- CSS Layout All In One
CSS Layout All In One CSS2 position float % px , rem, em CSS3 flex grid multi column vw / vh 常见布局模式 ...
- useState & useEffect
useState & useEffect https://overreacted.io/zh-hans/a-complete-guide-to-useeffect/ https://react ...
- PM2 in depth
PM2 in depth ecosystem.config.js module.exports = { apps : [{ name: "app", script: ". ...
- ip & 0.0.0.0 & 127.0.0.1 & localhost
ip & 0.0.0.0 & 127.0.0.1 7 localhost host https://www.howtogeek.com/225487/what-is-the-diffe ...
- Nifi组件脚本开发—ExecuteScript 使用指南(三)
上一篇:Nifi组件脚本开发-ExecuteScript 使用指南(二) Part 3 - 高级特征 本系列的前两篇文章涵盖了 flow file 的基本操作, 如读写属性和内容, 以及使用" ...