算法(Java实现)—— KMP算法
KMP算法
应用场景
字符串匹配问题
有一个字符串str1 = “ hello hello llo hhello lloh helo”
一个子串str2 = “hello”
现要判断str1是否含有str2,如果存在,就返回第一次出现的位置,如果不存在就返回-1.
暴力匹配算法
思路:
假设str1匹配到i位置,str2匹配到j位置,则有:
如果当前字符匹配成功(str1[i] = str2[j]),则i++,j++ 继续匹配下一个字符
后面如果匹配失败,回到str1从当前位置向后匹配,重复上述步骤
直到在str1中匹配到和str2相同的字串
代码实现
package whyAlgorithm.kmp;
/**
* @Description TODO 暴力匹配算法
* @Author why
* @Date 2020/12/16 18:50
* Version 1.0
**/
public class ViolentMatch {
public static void main(String[] args) {
String str1 = "hhellohellollohhellollohhelo";
String str2 = "hello";
ViolentMatch violentMatch = new ViolentMatch();
int match = violentMatch.getMatch(str1, str2);
System.out.println(match);
}
/**
* 暴力匹配算法
* 匹配到返回第一个字符的下标否则返回-1
* @param str1
* @param str2
* @return
*/
public int getMatch(String str1,String str2){
//将字符串转成字符数组
char[] chars1 = str1.toCharArray();
char[] chars2 = str2.toCharArray();
int s1Len = chars1.length;
int s2Len = chars2.length;
int i = 0;//指向chars1
int j = 0;//指向chars2
while (i < s1Len && j < s2Len){//保证匹配时不越界
if (chars1[i] == chars2[j]) {//匹配成功
i++;
j++;
}else {
i = i -(j-1);
j = 0;
}
}
if (j == s2Len){//匹配成功
return i - j;
}else{
return -1;
}
}
}
KMP算法
KMP算法介绍
KMP算法时一个解决模式串在文本串是否出现过,如果出现过,返回最早出现的位置的经典算法
Knuth-Morris-Pratt字符串查找算法,简称KMP算法
KMP算法通过利用之前判断该信息,通过一个next数组,保存模式串中前后最长公共子序列的长度,每次回溯时,通过next数组找到,前面匹配过的位置,省去大量时间
算法图解
举例来说,有一个字符串 Str1 = “BBC ABCDAB ABCDABCDABDE”,判断,里面是否包含另一个字符串 Str2 = “ABCDABD”?
首先,用 Str1 的第一个字符和 Str2 的第一个字符去比较,不符合,关键词向后移动一位

重复第一步,还是不符合,再后移

一直重复,直到str1有一个字符域str2的第一个字符符合为止

接着比较字符串和搜索词的下一个字符,还是符合

遇到str1有一个字符与str2对应的字符不符合
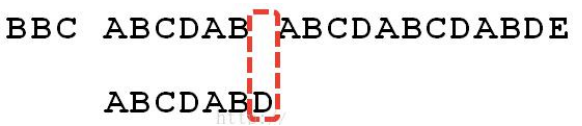
这时候,想到的是继续遍历 Str1 的下一个字符,重复第 1 步。(其实是很不明智的,因为此时 BCD 已经比较过了, 没有必要再做重复的工作,一个基本事实是,当空格与 D 不匹配时,你其实知道前面六个字符是”ABCDAB”。 KMP 算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这 样就提高了效率。)

怎么做到把刚刚重复的步骤省略掉?可以对 Str2 计算出一张《部分匹配表》,这张表怎么产生的后面介绍

.已知空格与 D 不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符 B 对应的”部分 匹配值”为 2,因此按照下面的公式算出向后移动的位数: 移动位数 = 已匹配的字符数 - 对应的部分匹配值 因为 6 - 2 等于 4,所以将搜索词向后移动 4 位。
.因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为 2(”AB”),对应的”部分匹配值” 为 0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移 2 位。

因为空格与 A 不匹配,继续后移一位。

逐位比较,直到发现 C 与 D 不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动 4 位。

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配), 移动位数 = 7 - 0,再将搜索词向后移动 7 位,这里就不再重复了。

部分匹配表的产生
介绍《部分匹配表》怎么产生的 先介绍前缀,后缀是什么

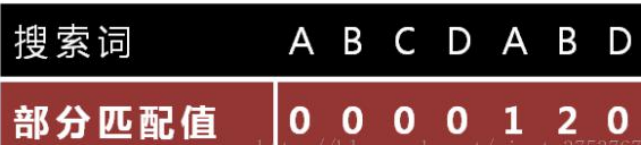
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
-”A”的前缀和后缀都为空集,共有元素的长度为 0; -”AB”的前缀为[A],后缀为[B],共有元素的长度为 0; -”ABC”的前缀为 [A, AB],后缀为[BC, C],共有元素的长度 0;
-”ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为 0;
-”ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为 1;
-”ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”, 长度为 2;
-”ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的 长度为 0。
”部分匹配”的实质是,有时候,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么 它的”部分匹配值”就是 2(”AB”的长度)。搜索词移动的时候,第一个”AB”向后移动 4 位(字符串长度- 部分匹配值),就可以来到第二个”AB”的位置。
代码实现
package whyAlgorithm.kmp;
import java.util.Arrays;
/**
* @Description TODO KMP算法
* @Author why
* @Date 2020/12/16 20:15
* Version 1.0
**/
public class KMPAlgorithm {
public static void main(String[] args) {
String str1 = "BBC ABCDAB ABCDABCDABDE";
String str2 = "ABCDABD";
kmp(str1, str2);
}
public static void kmp(String str1, String str2) {
int[] next = kmpNext(str2);
System.out.println("部分匹配表:");
System.out.println(Arrays.toString(next));
int index = kmpSearch(str1, str2, next);
if (index == -1){
System.out.println("未找到");
}else {
System.out.println("初始位置:" + index);
}
}
/**
* kmp匹配算法
* @param str1 原字符串
* @param str2 子串
* @param next 部分匹配表
* @return 如果是-1,没有匹配到,匹配到返回第一个匹配的位置
*/
public static int kmpSearch(String str1, String str2, int[] next) {
//遍历
for(int i = 0, j = 0; i < str1.length(); i++) {
//需要处理 str1.charAt(i) != str2.charAt(j), 去调整j的大小
//KMP算法核心点, 可以验证...
while( j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j-1];
}
if(str1.charAt(i) == str2.charAt(j)) {
j++;
}
if(j == str2.length()) {//找到了 // j = 3 i
return i - j + 1;
}
}
return -1;
}
/**
* 获取字符串的部分匹配表
* @param dest
* @return
*/
public static int[] kmpNext(String dest) {
//创建一个next 数组保存部分匹配值
int[] next = new int[dest.length()];
next[0] = 0; //如果字符串是长度为1 部分匹配值就是0
for(int i = 1, j = 0; i < dest.length(); i++) {
//当dest.charAt(i) != dest.charAt(j) ,我们需要从next[j-1]获取新的j
//直到我们发现 有 dest.charAt(i) == dest.charAt(j)成立才退出
//这时kmp算法的核心点
while(j > 0 && dest.charAt(i) != dest.charAt(j)) {
j = next[j-1];
}
//当dest.charAt(i) == dest.charAt(j) 满足时,部分匹配值就是+1
if(dest.charAt(i) == dest.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
}
算法(Java实现)—— KMP算法的更多相关文章
- Java实现KMP算法
/** * Java实现KMP算法 * * 思想:每当一趟匹配过程中出现字符比较不等,不需要回溯i指针, * 而是利用已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远 * 的一段 ...
- 算法起步之kmp算法
[作者Idlear 博客:http://blog.csdn.net/idlear/article/details/19555905] 这估计是算法连载文章的最后几篇了,马上就要 ...
- 算法笔记之KMP算法
本文是<算法笔记>KMP算法章节的阅读笔记,文中主要内容来源于<算法笔记>.本文主要介绍了next数组.KMP算法及其应用以及对KMP算法的优化. KMP算法主要用于解决字符串 ...
- 大话数据结构(十二)java程序——KMP算法及改进的KMP算法实现
1.朴素的模式匹配算法 朴素的模式匹配算法:就是对主串的每个字符作为子串开头,与要连接的字符串进行匹配.对主串做大循环,每个字符开头做T的长度的小循环,直到成功匹配或全部遍历完成为止. 又称BF算法 ...
- 问题 1690: 算法4-7:KMP算法中的模式串移动数组
题目链接:https://www.dotcpp.com/oj/problem1690.html 题目描述 字符串的子串定位称为模式匹配,模式匹配可以有多种方法.简单的算法可以使用两重嵌套循环,时间复杂 ...
- 字符串匹配(BF算法和KMP算法及改进KMP算法)
#include <stdio.h> #include <string.h> #include <stdlib.h> #include<cstring> ...
- JAVA分析html算法(JAVA网页蜘蛛算法)
近来有些朋友在做蜘蛛算法,或者在网页上面做深度的数据挖掘.但是遇到复杂而繁琐的html页面大家都望而却步.因为很难获取到相应的数据. 最古老的办法的是尝试用正则表达式,估计那么繁琐的东西得不偿失,浪费 ...
- 排序算法-Java实现快速排序算法
- 算法 | Java 常见排序算法(纯代码)
目录 汇总 1. 冒泡排序 2. 选择排序 3. 插入排序 4. 快速排序 5. 归并排序 6. 希尔排序 6.1 希尔-冒泡排序(慢) 6.2 希尔-插入排序(快) 7. 堆排序 8. 计数排序 9 ...
- 算法总结篇---KMP算法
目录 写在前面 例题 剪花布条 Radio Transmission OKR-Periods of Words 似乎在梦中见过的样子 Censoring 写在前面 仅为自用,不做推广 一起来看猫片吧! ...
随机推荐
- FL Studio进行侧链的三种方式(上)
在本系列教程中,我们将学习如何在FL Studio中进行侧链.侧链是一种信号处理技术,通过它我们可以使用一个信号波形的振幅(音量)来控制另一个信号的某些参数.在电子音乐中,例如trance,house ...
- layui $().click() 失效问题
//使用此点击事件失效 $(".sub2").on('click', function() { alert('响应点击事件'); }); //将指定的事件绑定在document上, ...
- python-交互模式
1.打开python交互式命令行: Windows+R→回车→输入python 如图 输入python进入交互模式,相当于启动了python解释器,输入一行代码就执行一行代码,可以用交互模式去验证每一 ...
- Leetcode 双周赛#32 题解
1540 K次操作转变字符串 #计数 题目链接 题意 给定两字符串\(s\)和\(t\),要求你在\(k\)次操作以内将字符串\(s\)转变为\(t\),其中第\(i\)次操作时,可选择如下操作: 选 ...
- Java基础教程——命令行运行Java代码
视屏讲解:https://www.bilibili.com/video/av48196406/?p=4 命令行运行Java代码 (1)使用记事本新建文本文件[Test.java]. 注意,默认状态下W ...
- 如何解析 redis 的 rdb 文件
目录 安装工具 解析 redis 的 rdb 文件 命令行工具使用,先看 --help 生成内存报告 使用参数过滤想要的数据 比较两个 rdb 文件 查看一个 key 的内存使用情况 常见问题 FAQ ...
- 使用RestTemplate,显示请求信息,响应信息
使用RestTemplate,显示请求信息,响应信息 这里不讲怎么用RestTemplate具体细节用法,就是一个学习中的过程记录 一个简单的例子 public class App { public ...
- centos7安装Python的虚拟环境
1. 安装virtualenv.virtualenvwrapper # pip3 install virtualenv # pip3 install virtualenvwrapper 2. 进入.b ...
- java并发编程实战《五》死锁
一不小心就死锁了,怎么办? 在上一篇文章中,我们用 Account.class 作为互斥锁,来解决银行业务里面的转账问题,虽然这个方案不存在并发问题,但是所有账户的转账操作都是串行的,性能太差. 向现 ...
- PyQt(Python+Qt)学习随笔:QTabWidget选项卡部件的tabBar、count、indexOf方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTabWidget的每个选项卡都有一个对应的页面部件对象,可用通过count方法获取选项卡个数,可 ...