) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
DROP TABLE IF EXISTS teacher;
CREATE TABLE `teacher` (
`tid` int(3) DEFAULT NULL,
`tname` varchar(20) DEFAULT NULL,
`tcid` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
DROP TABLE IF EXISTS teacher_contact;
CREATE TABLE `teacher_contact` (
`tcid` int(3) DEFAULT NULL,
`phone` varchar(200) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `course` VALUES ('1', 'mysql', '1');
INSERT INTO `course` VALUES ('2', 'jvm', '1');
INSERT INTO `course` VALUES ('3', 'juc', '2');
INSERT INTO `course` VALUES ('4', 'spring', '3');
INSERT INTO `teacher` VALUES ('1', 'qingshan', '1');
INSERT INTO `teacher` VALUES ('2', 'jack', '2');
INSERT INTO `teacher` VALUES ('3', 'mic', '3');
INSERT INTO `teacher_contact` VALUES ('1', '13688888888');
INSERT INTO `teacher_contact` VALUES ('2', '18166669999');
INSERT INTO `teacher_contact` VALUES ('3', '17722225555');
explain 的结果有很多的字段,我们详细地分析一下。
先确认一下环境:
select version();
show variables like '%engine%';
4.3.1 id
id 是查询序列编号。
id 值不同
id 值不同的时候,先查询 id 值大的(先大后小)。
-- 查询 mysql 课程的老师手机号
EXPLAIN SELECT tc.phone
FROM teacher_contact tc
WHERE tcid = (
SELECT tcid
FROM teacher t
WHERE t.tid = (
SELECT c.tid
FROM course c
WHERE c.cname = 'mysql'
)
);
查询顺序:course c——teacher t——teacher_contact tc

先查课程表,再查老师表,最后查老师联系方式表。子查询只能以这种方式进行,
只有拿到内层的结果之后才能进行外层的查询。
id 值相同
-- 查询课程 ID 为 2,或者联系表 ID 为 3 的老师
EXPLAIN
SELECT t.tname,c.cname,tc.phone
FROM teacher t, course c, teacher_contact tc
WHERE t.tid = c.tid
AND t.tcid = tc.tcid
AND (c.cid = 2
OR tc.tcid = 3);

id 值相同时,表的查询顺序是从上往下顺序执行。例如这次查询的 id 都是 1,查询
的顺序是 teacher t(3 条)——course c(4 条)——teacher_contact tc(3 条)。
teacher 表插入 3 条数据后:
INSERT INTO `teacher` VALUES (4, 'james', 4);
INSERT INTO `teacher` VALUES (5, 'tom', 5);
INSERT INTO `teacher` VALUES (6, 'seven', 6);
COMMIT;
-- (备份)恢复语句
DELETE FROM teacher where tid in (4,5,6);
COMMIT;
id 也都是 1,但是从上往下查询顺序变成了:
teacher_contact tc(3 条)——teacher
t(6 条)——course c(4 条)。

为什么数据量不同的时候顺序会发生变化呢?这个是由笛卡尔积决定的。
举例:假如有 a、b、c 三张表,分别有 2、3、4 条数据,如果做三张表的联合查询,
当查询顺序是 a→b→c 的时候,它的笛卡尔积是:2*3*4=6*4=24。如果查询顺序是 c
→b→a,它的笛卡尔积是 4*3*2=12*2=24。
因为 MySQL 要把查询的结果,包括中间结果和最终结果都保存到内存,所以 MySQL
会优先选择中间结果数据量比较小的顺序进行查询。所以最终联表查询的顺序是 a→b→
c。这个就是为什么 teacher 表插入数据以后查询顺序会发生变化。
(小标驱动大表的思想)
既有相同也有不同
如果 ID 有相同也有不同,就是 ID 不同的先大后小,ID 相同的从上往下。
4.3.2 select type 查询类型
这里并没有列举全部(其它:DEPENDENT UNION、DEPENDENT SUBQUERY、
MATERIALIZED、UNCACHEABLE SUBQUERY、UNCACHEABLE UNION)。
下面列举了一些常见的查询类型:
SIMPLE
简单查询,不包含子查询,不包含关联查询 union。
EXPLAIN SELECT * FROM teacher;

再看一个包含子查询的案例:
-- 查询 mysql 课程的老师手机号
EXPLAIN SELECT tc.phone
FROM teacher_contact tc
WHERE tcid = (
SELECT tcid
FROM teacher t
WHERE t.tid = (
SELECT c.tid
FROM course c
WHERE c.cname = 'mysql'
)
);

PRIMARY
子查询 SQL 语句中的主查询,也就是最外面的那层查询。
SUBQUERY
子查询中所有的内层查询都是 SUBQUERY 类型的。
DERIVED
衍生查询,表示在得到最终查询结果之前会用到临时表。例如:
-- 查询 ID 为 1 或 2 的老师教授的课程
EXPLAIN SELECT cr.cname
FROM (
SELECT * FROM course WHERE tid = 1
UNION
SELECT * FROM course WHERE tid = 2
) cr;

对于关联查询,先执行右边的 table(UNION),再执行左边的 table,类型是
DERIVED。
UNION
用到了 UNION 查询。同上例。
UNION RESULT
主要是显示哪些表之间存在 UNION 查询。<union2,3>代表 id=2 和 id=3 的查询
存在 UNION。同上例。
4.3.3 type 连接类型
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
所有的连接类型中,上面的最好,越往下越差。
在常用的链接类型中:system > const > eq_ref > ref > range > index > all
这 里 并 没 有 列 举 全 部 ( 其 他 : fulltext 、 ref_or_null 、 index_merger 、
unique_subquery、index_subquery)。
以上访问类型除了 all,都能用到索引。
const
主键索引或者唯一索引,只能查到一条数据的 SQL。
DROP TABLE IF EXISTS single_data;
CREATE TABLE single_data(
id int(3) PRIMARY KEY,
content varchar(20)
);
insert into single_data values(1,'a');
EXPLAIN SELECT * FROM single_data a where id = 1;

system
system 是 const 的一种特例,只有一行满足条件。例如:只有一条数据的系统表。
EXPLAIN SELECT * FROM mysql.proxies_priv;

eq_ref
通常出现在多表的 join 查询,表示对于前表的每一个结果,,都只能匹配到后表的
一行结果。一般是唯一性索引的查询(UNIQUE 或 PRIMARY KEY)。
eq_ref 是除 const 之外最好的访问类型。
先删除 teacher 表中多余的数据,teacher_contact 有 3 条数据,teacher 表有 3
条数据。
DELETE FROM teacher where tid in (4,5,6);
commit;
-- 备份
INSERT INTO `teacher` VALUES (4, 'james', 4);
INSERT INTO `teacher` VALUES (5, 'tom', 5);
INSERT INTO `teacher` VALUES (6, 'seven', 6);
commit;
为 teacher_contact 表的 tcid(第一个字段)创建主键索引。
-- ALTER TABLE teacher_contact DROP PRIMARY KEY;
ALTER TABLE teacher_contact ADD PRIMARY KEY(tcid);
为 teacher 表的 tcid(第三个字段)创建普通索引。
-- ALTER TABLE teacher DROP INDEX idx_tcid;
ALTER TABLE teacher ADD INDEX idx_tcid (tcid);
执行以下 SQL 语句:
select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;

此时的执行计划(teacher_contact 表是 eq_ref):

小结:
以上三种 system,const,eq_ref,都是可遇而不可求的,基本上很难优化到这个
状态。
ref
查询用到了非唯一性索引,或者关联操作只使用了索引的最左前缀。
例如:使用 tcid 上的普通索引查询:
explain SELECT * FROM teacher where tcid = 3;

range
索引范围扫描。
如果 where 后面是 between and 或 <或 > 或 >= 或 <=或 in 这些,type 类型
就为 range。
不走索引一定是全表扫描(ALL),所以先加上普通索引。
-- ALTER TABLE teacher DROP INDEX idx_tid;
ALTER TABLE teacher ADD INDEX idx_tid (tid);
执行范围查询(字段上有普通索引):
EXPLAIN SELECT * FROM teacher t WHERE t.tid <3;
-- 或
EXPLAIN SELECT * FROM teacher t WHERE tid BETWEEN 1 AND 2;

IN 查询也是 range(字段有主键索引)
EXPLAIN SELECT * FROM teacher_contact t WHERE tcid in (1,2,3);

index
Full Index Scan,查询全部索引中的数据(比不走索引要快)。
EXPLAIN SELECT tid FROM teacher;

all
Full Table Scan,如果没有索引或者没有用到索引,type 就是 ALL。代表全表扫描。
NULL
不用访问表或者索引就能得到结果,例如:
EXPLAIN select 1 from dual where 1=1;
小结:
一般来说,需要保证查询至少达到 range 级别,最好能达到 ref。
ALL(全表扫描)和 index(查询全部索引)都是需要优化的。
4.3.4 possible_key、key
可能用到的索引和实际用到的索引。如果是 NULL 就代表没有用到索引。
possible_key 可以有一个或者多个,可能用到索引不代表一定用到索引。
反过来,possible_key 为空,key 可能有值吗?
表上创建联合索引:
ALTER TABLE user_innodb DROP INDEX comidx_name_phone;
ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);
执行计划(改成 select name 也能用到索引):
explain select phone from user_innodb where phone='126';

结论:是有可能的(这里是覆盖索引的情况)。
如果通过分析发现没有用到索引,就要检查 SQL 或者创建索引
4.3.5 key_len
索引的长度(使用的字节数)。跟索引字段的类型、长度有关。
4.3.6 rows
MySQL 认为扫描多少行才能返回请求的数据,是一个预估值。一般来说行数越少越
好。
4.3.7 filtered
这个字段表示存储引擎返回的数据在 server 层过滤后,剩下多少满足查询的记录数
量的比例,它是一个百分比。
4.3.8 ref
使用哪个列或者常数和索引一起从表中筛选数据。
4.3.9 Extra
执行计划给出的额外的信息说明。
using index
用到了覆盖索引,不需要回表。
EXPLAIN SELECT tid FROM teacher ;
using where
使用了 where 过滤,表示存储引擎返回的记录并不是所有的都满足查询条件,需要
在 server 层进行过滤(跟是否使用索引没有关系)。
EXPLAIN select * from user_innodb where phone ='13866667777';

Using index condition(索引条件下推)
索引下推,在第二节课中已经讲解过了。
https://dev.mysql.com/doc/refman/5.7/en/index-condition-pushdown-optimization.html
using filesort
不能使用索引来排序,用到了额外的排序(跟磁盘或文件没有关系)。需要优化。
(复合索引的前提)
ALTER TABLE user_innodb DROP INDEX comidx_name_phone;
ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);
EXPLAIN select * from user_innodb where name ='青山' order by id;

using temporary
用到了临时表。例如(以下不是全部的情况):
1、distinct 非索引列
EXPLAIN select DISTINCT(tid) from teacher t;
2、group by 非索引列
EXPLAIN select tname from teacher group by tname;
3、使用 join 的时候,group 任意列
EXPLAIN select t.tid from teacher t join course c on t.tid = c.tid group by t.tid;
需要优化,例如创建复合索引
总结一下:
模拟优化器执行 SQL 查询语句的过程,来知道 MySQL 是怎么处理一条 SQL 语句的。
通过这种方式我们可以分析语句或者表的性能瓶颈。
分析出问题之后,就是对 SQL 语句的具体优化。
比如怎么用到索引,怎么减少锁的阻塞等待,在前面两次课已经讲过。
4.4 SQL 与索引优化
当我们的 SQL 语句比较复杂,有多个关联和子查询的时候,就要分析 SQL 语句有没
有改写的方法。
举个简单的例子,一模一样的数据:
-- 大偏移量的 limit
select * from user_innodb limit 900000,10;
-- 改成先过滤 ID,再 limit
SELECT * FROM user_innodb WHERE id >= 900000 LIMIT 10;
对于具体的 SQL 语句的优化,MySQL 官网也提供了很多建议,这个是我们在分析
具体的 SQL 语句的时候需要注意的,也是大家在以后的工作里面要去慢慢地积累的(这
里我们就不一一地分析了)。
https://dev.mysql.com/doc/refman/5.7/en/optimization.html
5 存储引擎
5.1 存储引擎的选择
为不同的业务表选择不同的存储引擎,例如:查询插入操作多的业务表,用 MyISAM。
临时数据用 Memeroy。常规的并发大更新多的表用 InnoDB。
5.2 分区或者分表
分区不推荐。
交易历史表:在年底为下一年度建立 12 个分区,每个月一个分区。
渠道交易表:分成当日表;当月表;历史表,历史表再做分区。
5.3 字段定义
原则:使用可以正确存储数据的最小数据类型。
为每一列选择合适的字段类型:
5.3.1 整数类型
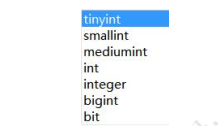
INT 有 8 种类型,不同的类型的最大存储范围是不一样的。
性别?用 TINYINT,因为 ENUM 也是整型存储。
5.3.2 字符类型
变长情况下,varchar 更节省空间,但是对于 varchar 字段,需要一个字节来记录长
度。
固定长度的用 char,不要用 varchar。
5.3.3 非空
非空字段尽量定义成 NOT NULL,提供默认值,或者使用特殊值、空串代替 null。
NULL 类型的存储、优化、使用都会存在问题。
5.3.4 不要用外键、触发器、视图
降低了可读性;
影响数据库性能,应该把把计算的事情交给程序,数据库专心做存储;
数据的完整性应该在程序中检查。
5.3.5 大文件存储
不要用数据库存储图片(比如 base64 编码)或者大文件;
把文件放在 NAS 上,数据库只需要存储 URI(相对路径),在应用中配置 NAS 服
务器地址。
5.3.6 表拆分
将不常用的字段拆分出去,避免列数过多和数据量过大。
比如在业务系统中,要记录所有接收和发送的消息,这个消息是 XML 格式的,用
blob 或者 text 存储,用来追踪和判断重复,可以建立一张表专门用来存储报文。
6 总结:优化体系
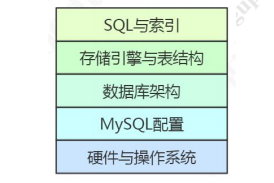
除了对于代码、SQL 语句、表定义、架构、配置优化之外,业务层面的优化也不能
忽视。举几个例子:
1)在某一年的双十一,为什么会做一个充值到余额宝和余额有奖金的活动(充 300
送 50)?
因为使用余额或者余额宝付款是记录本地或者内部数据库,而使用银行卡付款,需
要调用接口,操作内部数据库肯定更快。
2)在去年的双十一,为什么在凌晨禁止查询今天之外的账单?
这是一种降级措施,用来保证当前最核心的业务。
3)最近几年的双十一,为什么提前一个多星期就已经有双十一当天的价格了?
预售分流。
在应用层面同样有很多其他的方案来优化,达到尽量减轻数据库的压力的目的,比
如限流,或者引入 MQ 削峰,等等等等。
为什么同样用 MySQL,有的公司可以扛住百万千万级别的并发,而有的公司几百个
并发都扛不住,关键在于怎么用。所以,用数据库慢,不代表数据库本身慢,有的时候
还要往上层去优化
当然,如果关系型数据库解决不了的问题,我们可能需要用到搜索引擎或者大数据
的方案了,并不是所有的数据都要放到关系型数据库存储。