Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场
在各种环境中部署和操作Apache Flink的方法有很多。无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用。
在这个操场上,你将学习如何管理和运行Flink Jobs。您将看到如何部署和监控应用程序,体验Flink如何从Job故障中恢复,并执行日常操作任务,如升级和重新缩放。
这个游乐场的构造
这个游乐场由一个长寿的Flink Session Cluster和一个Kafka Cluster组成。
一个Flink Cluster总是由一个JobManager和一个或多个Flink TaskManagers组成。JobManager负责处理Job提交,监督Job以及资源管理。Flink TaskManagers是工人进程,负责执行构成Flink Job的实际任务。在这个游戏场中,你将从一个单一的TaskManager开始,但以后会扩展到更多的TaskManager。此外,这个游乐场还带有一个专门的客户端容器,我们使用它来提交Flink Job,并在以后执行各种操作任务。客户端容器不是Flink Cluster本身需要的,只是为了方便使用才包含在里面。
Kafka集群由一个Zookeeper服务器和一个Kafka Broker组成。
当游乐场启动时,一个名为Flink Event Count的Flink Job将被提交给JobManager。此外,还会创建两个Kafka主题输入和输出。
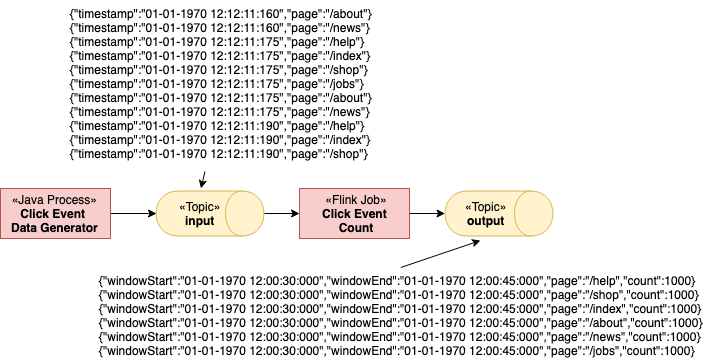
该作业从输入主题中消耗ClickEvents,每个ClickEvents都有一个时间戳和一个页面。然后按页面对事件进行键入,并在 15 秒的窗口中进行计数。结果被写入输出主题。
有6个不同的页面,我们在每个页面和15秒内产生1000个点击事件。因此,Flink作业的输出应该显示每个页面和窗口有1000个浏览量。
启动游乐场
游戏场环境的设置只需几步。我们将引导你完成必要的命令,并展示如何验证一切都在正确运行。
我们假设你的机器上安装了Docker(1.12+)和docker-compose(2.1+)。
所需的配置文件可以在flink-playgrounds仓库中找到。检查一下,然后旋转环境。
git clone --branch release-1.12 https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker-compose build
docker-compose up -d
之后,你可以用以下命令检查正在运行的Docker容器。
docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------
operations-playground_clickevent-generator_1 /docker-entrypoint.sh java ... Up 6123/tcp, 8081/tcp
operations-playground_client_1 /docker-entrypoint.sh flin ... Exit 0
operations-playground_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp
operations-playground_kafka_1 start-kafka.sh Up 0.0.0.0:9094->9094/tcp
operations-playground_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
operations-playground_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
这表明客户端容器已经成功提交了Flink Job(Exit 0),所有集群组件以及数据生成器都在运行(Up)。
您可以通过调用来停止游乐场环境。
docker-compose down -v
进入游乐场
在这个游乐场中,有很多东西你可以尝试和检查。在下面的两节中,我们将向您展示如何与Flink集群进行交互,并展示Flink的一些主要功能。
Flink WebUI
观察你的Flink集群最自然的出发点是在http://localhost:8081 下暴露的 WebUI。如果一切顺利,你会看到集群最初由一个任务管理器组成,并执行一个名为Click Event Count的Job。

Flink WebUI包含了很多关于Flink集群和它的工作的有用和有趣的信息(JobGraph, Metrics, Checkpointing Statistics, TaskManager Status, ...)。
日志
JobManager
JobManager的日志可以通过docker-compose进行尾随。
docker-compose logs -f jobmanager
在初始启动后,你应该主要看到每一个检查点完成的日志信息。
TaskManager
任务管理器的日志也可以用同样的方式进行尾随。
docker-compose logs -f taskmanager
在初始启动后,你应该主要看到每一个检查点完成的日志信息。
Flink 客户端命令
Flink CLI可以在客户端容器中使用。例如,要打印Flink CLI的帮助信息,你可以运行以下命令
docker-compose run --no-deps client flink --help
Flink REST API
Flink REST API通过主机上的localhost:8081或客户端容器中的jobmanager:8081暴露出来,例如,要列出所有当前正在运行的作业,你可以运行。
curl localhost:8081/jobs
Kafka Topics
你可以通过运行以下命令来查看写入Kafka主题的记录
//input topic (1000 records/s)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input //output topic (24 records/min)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
Time to Play!开玩
现在你已经学会了如何与Flink和Docker容器进行交互,让我们来看看一些常见的操作任务,你可以在我们的操场上尝试一下。所有这些任务都是相互独立的,即你可以以任何顺序执行它们。大多数任务可以通过CLI和REST API来执行。
Listing Running Jobs列出正在运行的作业
命令1
docker-compose run --no-deps client flink list预期输出1
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.07.2019 16:37:55 : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------
No scheduled jobs.JobID在提交时分配给作业,并且需要通过CLI或REST API对作业执行操作。
命令2
curl localhost:8081/jobs预期输出2
{
"jobs": [
{
"id": "<job-id>",
"status": "RUNNING"
}
]
}JobID在提交时分配给作业,并且需要通过CLI或REST API对作业执行操作。
观察故障和恢复
Flink在(部分)失败下提供了精确的一次处理保证。在这个游戏场中,你可以观察并--在一定程度上--验证这种行为。
步骤1:观察输出
如上所述,在这个游戏场中的事件是这样生成的,每个窗口正好包含一千条记录。因此,为了验证Flink是否成功地从TaskManager故障中恢复,而没有数据丢失或重复,你可以跟踪输出主题,并检查--恢复后--所有的窗口都存在,而且计数是正确的。
为此,从输出主题开始读取,并让这个命令运行到恢复后(步骤3)。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
步骤2:引入故障
为了模拟部分故障,你可以杀死一个任务管理器。在生产设置中,这可能对应于TaskManager进程、TaskManager机器的丢失,或者仅仅是框架或用户代码抛出的一个短暂的异常(例如,由于外部资源的暂时不可用)。
docker-compose kill taskmanager
几秒钟后,JobManager会注意到任务管理器的丢失,取消受影响的Job,并立即重新提交它进行恢复。当Job被重新启动后,它的任务仍然处于SCHEDULED状态,紫色的方块表示(见下面的截图)。
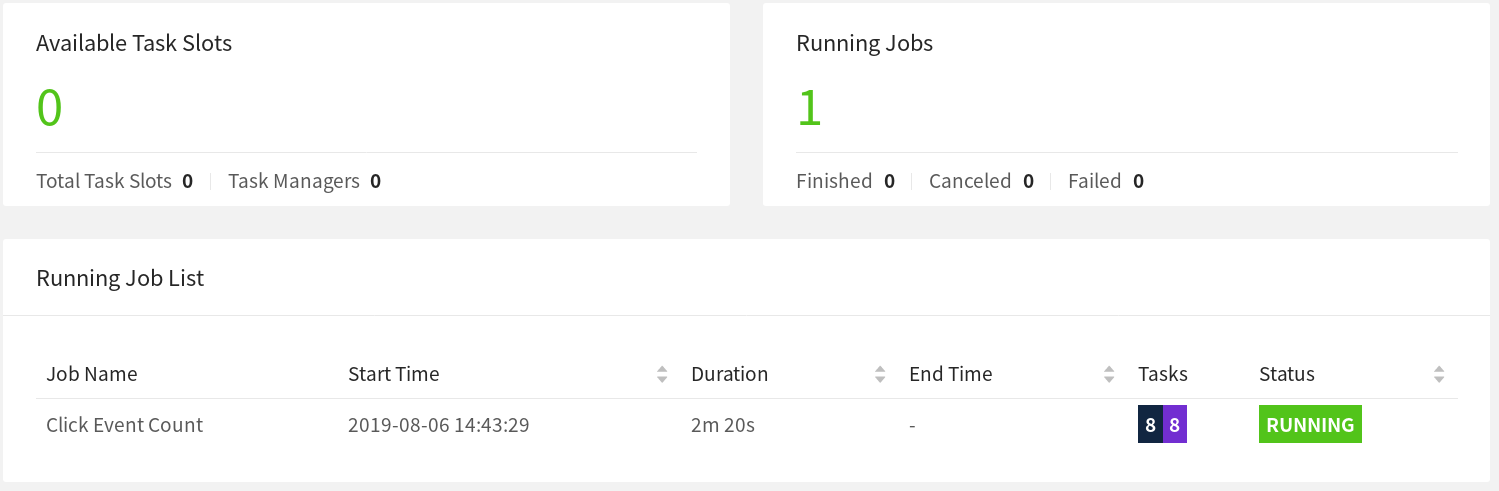
注意:即使作业的任务处于SCHEDULED状态,还没有RUNNING,作业的整体状态也会显示为RUNNING。
此时,Job的任务不能从SCHEDULED状态转为RUNNING状态,因为没有资源(TaskManagers提供的TaskSlots)来运行任务。在新的任务管理器可用之前,Job将经历一个取消和重新提交的循环。
同时,数据生成器会不断地将ClickEvents推送到输入主题中。这类似于真正的生产设置,在生产数据的同时,要处理数据的Job却停机了。
步骤3:恢复
一旦你重新启动任务管理器,它就会重新连接到JobManager。
docker-compose up -d taskmanager
当JobManager被通知到新的任务管理器时,它将恢复中的Job的任务调度到新的可用任务槽。重新启动后,任务会从故障前最后一次成功的检查点恢复其状态,并切换到RUNNING状态。
Job将快速处理来自Kafka的全部积压输入事件(在故障期间积累的),并以更高的速度(>24条记录/分钟)产生输出,直到到达流的头部。在输出中,你会看到所有的键(页)都存在于所有的时间窗口中,而且每个计数都是精确的一千。由于我们是在 "至少一次 "模式下使用FlinkKafkaProducer,所以你有可能会看到一些重复的输出记录。
注意:大多数生产设置依赖于资源管理器(Kubernetes、Yarn、Mesos)来自动重启失败的进程。
升级和重新缩放一个作业
升级Flink作业总是涉及两个步骤。首先,用一个保存点优雅地停止Flink Job。保存点是在一个明确定义的、全局一致的时间点(类似于检查点)上的完整应用状态的一致快照。其次,升级后的Flink Job从Savepoint开始。在这种情况下,"升级 "可以意味着不同的事情,包括以下内容。
- 配置的升级(包括作业的并行性)。
- 对工作的拓扑结构进行升级(增加/删除操作员)。
- 对Job的用户定义功能进行升级。
在开始升级之前,你可能要开始尾随输出主题,以观察在升级过程中没有数据丢失或损坏。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output
步骤1:停止作业
要优雅地停止作业,您需要使用 CLI 或 REST API 的 "stop "命令。为此,您需要该作业的JobID,您可以通过列出所有正在运行的Job或从WebWeb中获得。有了JobID,您就可以继续停止该作业。
第一种:CLI方式
命令
docker-compose run --no-deps client flink stop <job-id>预期输出
Suspending job "<job-id>" with a savepoint.
Savepoint completed. Path: file:<savepoint-path>Savepoint已经被存储到flink-conf.yaml中配置的state.savepoint.dir中,它被安装在本地机器的/tmp/flink-savepoints-directory/下。在下一步,你将需要这个Savepoint的路径。
第二种:REST方式
请求
{
"request-id": "<trigger-id>"
}预期输出
{
"request-id": "<trigger-id>"
}请求
# 检查停止动作的状态并检索保存点路径
curl localhost:8081/jobs/<job-id>/savepoints/<trigger-id>预期输出
{
"status": {
"id": "COMPLETED"
},
"operation": {
"location": "<savepoint-path>"
}
}步骤2A:重新启动作业而不做更改
现在您可以从该保存点重新启动升级后的作业。为了简单起见,您可以在不做任何更改的情况下重新启动它。
第一种方式:CLI方式
命令
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time预期输出
Job has been submitted with JobID <job-id>一旦作业再次运行,您将在输出主题中看到,在作业处理中断期间积累的积压时,记录以更高的速度产生。此外,您还会看到在升级过程中没有丢失任何数据:所有窗口都存在,数量正好是一千。
第二种方式:REST方式
请求
请求
# 从客户端容器上传JAR
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload预期输出
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}请求
# 提交工作
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'预期输出
{
"jobid": "<job-id>"
}一旦作业再次运行,您将在输出主题中看到,在作业处理中断期间积累的积压时,记录以更高的速度产生。此外,您还会看到在升级过程中没有丢失任何数据:所有窗口都存在,数量正好是一千。
步骤2B:以不同的并行度重新启动作业(重新缩放)
另外,您也可以在重新提交时通过传递不同的并行性,从这个保存点重新缩放作业。
第一种方式:CLI方式
命令
docker-compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time预期输出
Starting execution of program
Job has been submitted with JobID <job-id>第二种方式:REST方式
请求
请求
# 从客户端容器上传JAR
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload预期输出
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}请求
# 提交工作
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"parallelism": 3, "programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'预期输出
{
"jobid": "<job-id>"
}现在,作业已经被重新提交,但它不会启动,因为没有足够的TaskSlots在增加的并行度下执行它(2个可用,3个需要)。有了
docker-compose scale taskmanager=2
你可以在Flink集群中添加一个带有两个任务槽的第二个任务管理器,它将自动注册到JobManager中。添加任务管理器后不久,该任务应该再次开始运行。
一旦Job再次 "RUNNING",你会在输出Topic中看到在重新缩放过程中没有丢失数据:所有的窗口都存在,计数正好是一千。
查询作业的指标
JobManager通过其REST API公开系统和用户指标。
端点取决于这些指标的范围。可以通过 jobs/<job-id>/metrics 来列出一个作业的范围内的度量。指标的实际值可以通过get query参数进行查询。
请求
curl "localhost:8081/jobs/<jod-id>/metrics?get=lastCheckpointSize"
预期输出
[
{
"id": "lastCheckpointSize",
"value": "9378"
}
]
REST API不仅可以用来查询指标,还可以检索运行中的作业状态的详细信息。
请求
# find the vertex-id of the vertex of interest
curl localhost:8081/jobs/<jod-id>
预期输出
{
"jid": "<job-id>",
"name": "Click Event Count",
"isStoppable": false,
"state": "RUNNING",
"start-time": 1564467066026,
"end-time": -1,
"duration": 374793,
"now": 1564467440819,
"timestamps": {
"CREATED": 1564467066026,
"FINISHED": 0,
"SUSPENDED": 0,
"FAILING": 0,
"CANCELLING": 0,
"CANCELED": 0,
"RECONCILING": 0,
"RUNNING": 1564467066126,
"FAILED": 0,
"RESTARTING": 0
},
"vertices": [
{
"id": "<vertex-id>",
"name": "ClickEvent Source",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066423,
"end-time": -1,
"duration": 374396,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 0,
"read-bytes-complete": true,
"write-bytes": 5033461,
"write-bytes-complete": true,
"read-records": 0,
"read-records-complete": true,
"write-records": 166351,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "Timestamps/Watermarks",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066441,
"end-time": -1,
"duration": 374378,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5066280,
"read-bytes-complete": true,
"write-bytes": 5033496,
"write-bytes-complete": true,
"read-records": 166349,
"read-records-complete": true,
"write-records": 166349,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEvent Counter",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066469,
"end-time": -1,
"duration": 374350,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5085332,
"read-bytes-complete": true,
"write-bytes": 316,
"write-bytes-complete": true,
"read-records": 166305,
"read-records-complete": true,
"write-records": 6,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEventStatistics Sink",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066476,
"end-time": -1,
"duration": 374343,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 20668,
"read-bytes-complete": true,
"write-bytes": 0,
"write-bytes-complete": true,
"read-records": 6,
"read-records-complete": true,
"write-records": 0,
"write-records-complete": true
}
}
],
"status-counts": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 4,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"plan": {
"jid": "<job-id>",
"name": "Click Event Count",
"nodes": [
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEventStatistics Sink",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Counter",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "HASH",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "Timestamps/Watermarks",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Source",
"optimizer_properties": {}
}
]
}
}
请参考REST API参考资料,了解可能查询的完整列表,包括如何查询不同范围的指标(如TaskManager指标)。
变体
你可能已经注意到,Click Event Count应用程序总是以--checkpointing和--event-time程序参数启动。通过在docker-compose.yaml的客户端容器的命令中省略这些,你可以改变Job的行为。
- --checkpointing启用了checkpoint,这是Flink的容错机制。如果你在没有它的情况下运行,并通过故障和恢复,你应该会看到数据实际上已经丢失了。
- --event-time 启用了你的 Job 的事件时间语义。当禁用时,作业将根据挂钟时间而不是ClickEvent的时间戳将事件分配给窗口。因此,每个窗口的事件数量将不再是精确的一千。
Click Event Count应用程序还有另一个选项,默认情况下是关闭的,你可以启用这个选项来探索这个作业在背压下的行为。你可以在docker-compose.yaml的客户端容器的命令中添加这个选项。
- -backpressure在作业中间增加了一个额外的操作者,在偶数分钟内会造成严重的背压(例如,在10:12期间,但在10:13期间不会)。这可以通过检查各种网络指标(如 outputQueueLength 和 outPoolUsage)和/或使用 WebUI 中的背压监控来观察。
Flink-v1.12官方网站翻译-P004-Flink Operations Playground的更多相关文章
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P014-Flink Architecture
Flink架构 Flink是一个分布式系统,为了执行流式应用,需要对计算资源进行有效的分配和管理.它集成了所有常见的集群资源管理器,如Hadoop YARN.Apache Mesos和Kubernet ...
- Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots
通过状态快照进行容错 状态后台 Flink管理的键控状态是一种碎片化的.键/值存储,每项键控状态的工作副本都被保存在负责该键的任务管理员的本地某处.操作员的状态也被保存在需要它的机器的本地.Flink ...
- Flink-v1.12官方网站翻译-P003-Real Time Reporting with the Table API
利用表格API进行实时报告 Apache Flink提供的Table API是一个统一的.关系型的API,用于批处理和流处理,即在无边界的.实时的流或有边界的.批处理的数据集上以相同的语义执行查询,并 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P001-Local Installation
本地安装 按照以下几个步骤下载最新的稳定版本并开始使用. 第一步:下载 为了能够运行Flink,唯一的要求是安装了一个有效的Java 8或11.你可以通过以下命令检查Java的正确安装. java - ...
随机推荐
- PyCharm 2019、2020、2021专业版激活
PyCharm下载地址:https://www.jetbrains.com/pycharm/download/ PyCharm社区版功能基本够用,但是作为傲娇的程序员,咱都是上来就专业版,然后各种破解 ...
- 附录 A ES6附加特性
目录 模板字符串 解构 对象的解构 数组的解构 增强版对象字面量 模板字符串 const student = { name: "Wango", age: 24, } // 普通字符 ...
- Solon rpc 之 SocketD 协议 - RPC调用模式
Solon rpc 之 SocketD 协议系列 Solon rpc 之 SocketD 协议 - 概述 Solon rpc 之 SocketD 协议 - 消息上报模式 Solon rpc 之 Soc ...
- IntelliJ IDEA启动界面的秘密:当编程遇到艺术
细心的同学会发现Intellij IDEA每次发版本的时候都会有不同的启动界面背景,都很比较抽象的艺术图像. JetBrains的其它产品也有自己独特的设计. 但是这背后是怎么实现的.有什么寓意却很少 ...
- 计算机科学: 寄存器&内存
参考: [十分钟速成课:计算机科学]6.寄存器&内存 要想聊寄存器Latch,首先要聊内存.什么是内存? Memory,就是储存信息的东西. 我们都玩过单机游戏,如果突然关机,游戏结束但是没有 ...
- Centos 6 下安装 OSSEC-2.8.1 (一)
ossec -2.8.1 安装: ## 1 ) 安装依赖包: RedHat / Centos / Fedora / Amazon Linux yum install -y pcre mysql mys ...
- 【Linux】CentOS4 系统最后的网络yum源
------------------------------------------------------------------------------------------------- | ...
- druid discard long time none received connection问题解析
最新项目中用的druid连接数据库遇到一个困扰很久的问题 1 开始用的druid版本是1.1.22版本,由于业务需求,单个连接需要执行很久,理论上不需要用到自动回收,但为了安全,还是加了自动回收,时间 ...
- VL02N发货过账BAPI
使用BAPI函数: BAPI_OUTB_DELIVERY_CONFIRM_DEC 进行delivery的发货过账,可能会有如此的需求,就是修改实际的发货日期.规划的GI.交货日期.装载日期.传输计划日 ...
- python3.8.1安装cx_Freeze
按照官网的提示命令python -m pip install cx_Freeze --upgrade安装,不成功,报了一个错误,说cx_Freeze找不到需要的版本,还有一些警告说PIP需要升级,没理 ...