Python爬虫笔记一(来自MOOC) Requests库入门
Python爬虫笔记一(来自MOOC)
提示:本文是我在中国大学MOOC里面自学以及敲的一部分代码,纯一个记录文,如果刚好有人也是看的这个课,方便搬运在自己电脑上运行。
课程为:北京理工大学-嵩天-Python爬虫与信息提取
提示:多多自我发挥更有助于学习语言逻辑哦!
@
前言
 通用代码框架:
通用代码框架:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeput=30)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding=r.apparemt_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
例子都是这一周的内容的
提示:以下是代码和运行结果
一、嵩天老师课件给出的代码部分
1.京东商品页面的爬取
代码如下:
import requests
url="https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print ("爬取失败")
运行结果:
<script>window.location.href='https://passport.jd.com/new/login.aspx?ReturnUrl=http%3A%2F%2Fitem.jd.com%2F2967929.html'</script> 进程已结束,退出代码0
2.亚马逊商品页面的爬取
代码如下:
import requests
url="https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv={'user-agent':'Mozilla/5.0'}
r = requests.get(url,headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")
运行结果:
ue_sid = (document.cookie.match(/session-id=([0-9-]+)/) || [])[1],
ue_sn = "opfcaptcha.amazon.cn",
ue_id = 'FNY2VQ38P3R6JETHXGX2';
}
</script>
</head>
<body>
<!--
To discuss automated access to Amazon data please contact api-services-support@amazon.com.
For information about migrating to our APIs refer to our Marketplace APIs at https://developer.amazonservices.com.cn/index.html/ref=rm_c_sv, or our Product Advertising API at https://associates.amazon.cn/gp/advertising/api/detail/main.html/ref=rm_c_ac for advertising use cases.
-->
<!--
Correios.DoNotSend
-->
<div class="a-container a-padding-double-large" style="min-width:350px;padding:44px 0 !important">
<div class="a-row a-spacing-double-large" style="width: 350px; margin: 0 auto">
<div class="a-row a-spacing-medium a-text-center"><i class="a-icon a-logo"></i></div>
<div class="a-box a-alert a-alert-info a-spacing-base">
<div class="a-box-inner">
进程已结束,退出代码0
3.百度/360关键字提交
百度代码如下:
import requests
keyword="Python"
try:
kv = {'wd':keyword}
r = requests.get("http://www.baidu.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except :
print("爬取失败")
运行结果
http://www.baidu.com/s?wd=Python
660082
进程已结束,退出代码0
360代码如下:
import requests
keyword="Python"
try:
kv={'q':keyword}
r=requests.get("http://www.so.com/s",params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
运行结果
https://www.so.com/s?q=Python
327996
进程已结束,退出代码0
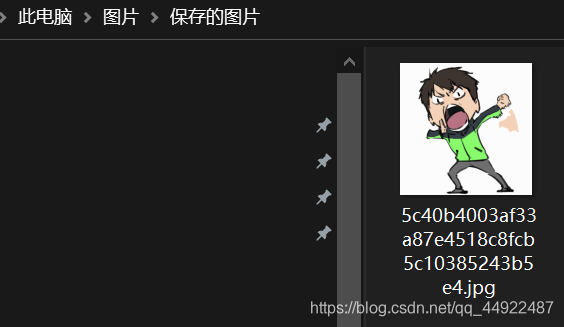
4.网络图片的爬取与储存
代码如下:
import requests
import os
url="https://imgsa.baidu.com/forum/w%3D580/sign=dc59751a6181800a6ee58906813433d6/5c40b4003af33a87e4518c8fcb5c10385243b5e4.jpg"
root="C://Users//灰二//Pictures//Saved Pictures//"
path=root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb')as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
运行结果:
文件保存成功
进程已结束,退出代码0
5.ip归属地的自动查询
代码如下:
import requests
url="http://m.ip138.com/ip.asp?ip="
try:
r=requests.get(url+'202.204.80.112')
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
运行结果:
爬取失败
进程已结束,退出代码0
二、个人运行过程中的一些问题和尝试的方法
1.ip归属地自动查询
这个代码的问题我觉得不是代码问题,但是在运行会反馈回来爬取失败的信息,所以程序的运行是没有问题的,就是状态非200,我觉得问题应该是出现在了这里,giao。
2.其他网页的一些爬取过程
我发现有的网页也会出现一些不是我上面所给出的结果,大部分我看了都是要登录账号,所以可能是因为这个原因吧(瞎猜),如果有解决办法也想各位大哥给出建议。
小练习题
也是教学的评论区里的题目
爬取访问一个网页100次,统计耗时
大部分代码也都是相似的,所以我的也是抄抄改改得到的,不过我发现一个很有趣的现象,先上代码,代码如下:
import requests
import time
def getHtmlText(url):
try:
r = requests.get(url, timeout=30)#获取url的内容,设定超时时间为30秒
r.raise_for_status()#如果不是200,产生异常requests.HTTPError
# r.raise_for_status()
# 在方法内部判断r.status_code是否等于200,不需要
# 增加额外的if语句,该语句便于利用try‐except进行异常处理
r.encoding = r.apparent_encoding #从HTTP header中猜测的响应内容编码方式
return r.text#返回html响应内容的字符串形式,即是url对应的页面内容
except:
return '运行异常'
if __name__ == "__main__":
url = 'https://www.tudou.com' # 任意填入某个网址即可,我爬的土豆
totaltime = 0
for i in range(100):
starttime = time.perf_counter()
getHtmlText(url)
endtime = time.perf_counter()
print('第{0}次爬取用时{1:.4f}秒;'.format(i + 1, endtime - starttime))
totaltime = totaltime + endtime - starttime
print('总共用时{:.4f}秒'.format(totaltime))
第一次运行结果:
C:\Users\灰二\AppData\Local\Programs\Python\Python39\python.exe C:/Users/灰二/PycharmProjects/Spider/spider1.py
第1次爬取用时0.8227秒;
第2次爬取用时0.7693秒;
第3次爬取用时0.7562秒;
第4次爬取用时0.7901秒;
第5次爬取用时0.1493秒;
第6次爬取用时0.1525秒;
第7次爬取用时0.1509秒;
第8次爬取用时0.1475秒;
第9次爬取用时0.1459秒;
第10次爬取用时0.1505秒;
第11次爬取用时0.1519秒;
第12次爬取用时0.1520秒;
第13次爬取用时0.1479秒;
第14次爬取用时0.1407秒;
第15次爬取用时0.1476秒;
第16次爬取用时0.1528秒;
第17次爬取用时0.1507秒;
第18次爬取用时0.1508秒;
第19次爬取用时0.1563秒;
第20次爬取用时0.1515秒;
第21次爬取用时0.1475秒;
第22次爬取用时0.1574秒;
第23次爬取用时0.1467秒;
第24次爬取用时0.1551秒;
第25次爬取用时0.1580秒;
第26次爬取用时0.1489秒;
第27次爬取用时0.1469秒;
第28次爬取用时0.1578秒;
第29次爬取用时0.1576秒;
第30次爬取用时0.1541秒;
第31次爬取用时0.1482秒;
第32次爬取用时0.1489秒;
第33次爬取用时0.1493秒;
第34次爬取用时0.1560秒;
第35次爬取用时0.1531秒;
第36次爬取用时0.1519秒;
第37次爬取用时0.1480秒;
第38次爬取用时0.1476秒;
第39次爬取用时0.1481秒;
第40次爬取用时0.1491秒;
第41次爬取用时0.1460秒;
第42次爬取用时0.1420秒;
第43次爬取用时0.1724秒;
第44次爬取用时0.1520秒;
第45次爬取用时0.1509秒;
第46次爬取用时0.1536秒;
第47次爬取用时0.1484秒;
第48次爬取用时0.1499秒;
第49次爬取用时0.1478秒;
第50次爬取用时0.1471秒;
第51次爬取用时0.1593秒;
第52次爬取用时0.1560秒;
第53次爬取用时0.1606秒;
第54次爬取用时0.1516秒;
第55次爬取用时0.1518秒;
第56次爬取用时0.1562秒;
第57次爬取用时0.1541秒;
第58次爬取用时0.1452秒;
第59次爬取用时0.1510秒;
第60次爬取用时0.1504秒;
第61次爬取用时0.1475秒;
第62次爬取用时0.1588秒;
第63次爬取用时0.1615秒;
第64次爬取用时0.1512秒;
第65次爬取用时0.1497秒;
第66次爬取用时0.1524秒;
第67次爬取用时0.1565秒;
第68次爬取用时0.1565秒;
第69次爬取用时0.1765秒;
第70次爬取用时0.1601秒;
第71次爬取用时0.1574秒;
第72次爬取用时0.1463秒;
第73次爬取用时0.1488秒;
第74次爬取用时0.1771秒;
第75次爬取用时0.1589秒;
第76次爬取用时0.1582秒;
第77次爬取用时0.1474秒;
第78次爬取用时0.1692秒;
第79次爬取用时0.1542秒;
第80次爬取用时0.1560秒;
第81次爬取用时0.1439秒;
第82次爬取用时0.1464秒;
第83次爬取用时0.1505秒;
第84次爬取用时0.1574秒;
第85次爬取用时0.1706秒;
第86次爬取用时0.1520秒;
第87次爬取用时0.1603秒;
第88次爬取用时0.1629秒;
第89次爬取用时0.1483秒;
第90次爬取用时0.1504秒;
第91次爬取用时0.1560秒;
第92次爬取用时0.1702秒;
第93次爬取用时0.1525秒;
第94次爬取用时0.1501秒;
第95次爬取用时0.1587秒;
第96次爬取用时0.1555秒;
第97次爬取用时0.1535秒;
第98次爬取用时0.1521秒;
第99次爬取用时0.1463秒;
第100次爬取用时0.1486秒;
总共用时17.8437秒
进程已结束,退出代码0
第二次运行结果:
C:\Users\灰二\AppData\Local\Programs\Python\Python39\python.exe C:/Users/灰二/PycharmProjects/Spider/spider1.py
第1次爬取用时0.2139秒;
第2次爬取用时0.1623秒;
第3次爬取用时0.1626秒;
第4次爬取用时0.1517秒;
第5次爬取用时0.1464秒;
第6次爬取用时0.1650秒;
第7次爬取用时0.1583秒;
第8次爬取用时0.1636秒;
第9次爬取用时0.1567秒;
第10次爬取用时0.1541秒;
第11次爬取用时0.1458秒;
第12次爬取用时0.1575秒;
第13次爬取用时0.1507秒;
第14次爬取用时0.1615秒;
第15次爬取用时0.1579秒;
第16次爬取用时0.1538秒;
第17次爬取用时0.1548秒;
第18次爬取用时0.1672秒;
第19次爬取用时0.1584秒;
第20次爬取用时0.1739秒;
第21次爬取用时0.1481秒;
第22次爬取用时0.1510秒;
第23次爬取用时0.1552秒;
第24次爬取用时0.1521秒;
第25次爬取用时0.1567秒;
第26次爬取用时0.1539秒;
第27次爬取用时0.1452秒;
第28次爬取用时0.1547秒;
第29次爬取用时0.1510秒;
第30次爬取用时0.1476秒;
第31次爬取用时0.1540秒;
第32次爬取用时0.1586秒;
第33次爬取用时0.1588秒;
第34次爬取用时0.1574秒;
第35次爬取用时0.1663秒;
第36次爬取用时0.1593秒;
第37次爬取用时0.1474秒;
第38次爬取用时0.1612秒;
第39次爬取用时0.1568秒;
第40次爬取用时0.1677秒;
第41次爬取用时0.1660秒;
第42次爬取用时0.1542秒;
第43次爬取用时0.1844秒;
第44次爬取用时0.1568秒;
第45次爬取用时0.1601秒;
第46次爬取用时0.1524秒;
第47次爬取用时0.1578秒;
第48次爬取用时0.1521秒;
第49次爬取用时0.1598秒;
第50次爬取用时0.1508秒;
第51次爬取用时0.1464秒;
第52次爬取用时0.1452秒;
第53次爬取用时0.1617秒;
第54次爬取用时0.1652秒;
第55次爬取用时0.1500秒;
第56次爬取用时0.1532秒;
第57次爬取用时0.1473秒;
第58次爬取用时0.1525秒;
第59次爬取用时0.1594秒;
第60次爬取用时0.1496秒;
第61次爬取用时0.1482秒;
第62次爬取用时0.1484秒;
第63次爬取用时0.3039秒;
第64次爬取用时0.1562秒;
第65次爬取用时0.1579秒;
第66次爬取用时0.1717秒;
第67次爬取用时0.1652秒;
第68次爬取用时0.1505秒;
第69次爬取用时0.1652秒;
第70次爬取用时0.1548秒;
第71次爬取用时0.1624秒;
第72次爬取用时0.1704秒;
第73次爬取用时0.1552秒;
第74次爬取用时0.1550秒;
第75次爬取用时0.1539秒;
第76次爬取用时0.1476秒;
第77次爬取用时0.1586秒;
第78次爬取用时0.1500秒;
第79次爬取用时0.1553秒;
第80次爬取用时0.1504秒;
第81次爬取用时0.1666秒;
第82次爬取用时0.1464秒;
第83次爬取用时0.1562秒;
第84次爬取用时0.1534秒;
第85次爬取用时0.1571秒;
第86次爬取用时0.1542秒;
第87次爬取用时0.1549秒;
第88次爬取用时0.1472秒;
第89次爬取用时0.1523秒;
第90次爬取用时0.1807秒;
第91次爬取用时0.1606秒;
第92次爬取用时0.1585秒;
第93次爬取用时0.1551秒;
第94次爬取用时0.1577秒;
第95次爬取用时0.1603秒;
第96次爬取用时0.1542秒;
第97次爬取用时0.1575秒;
第98次爬取用时0.1590秒;
第99次爬取用时0.1623秒;
第100次爬取用时0.1639秒;
总共用时15.8824秒
进程已结束,退出代码0
可能没怎么明白我所说的有趣在哪,第一次爬取的前四次时长相比较与其他的次数所花费的时间比较多
第1次爬取用时0.8227秒;
第2次爬取用时0.7693秒;
第3次爬取用时0.7562秒;
第4次爬取用时0.7901秒;
第5次爬取用时0.1493秒;
但是第二次的时候不会有这种情况。
第1次爬取用时0.2139秒;
第2次爬取用时0.1623秒;
第3次爬取用时0.1626秒;
第4次爬取用时0.1517秒;
第5次爬取用时0.1464秒;
所以我就比较好奇了。百度了一下没有什么有参考性的答案(也只是随便搜了一下),如果有大哥知晓可以告知一下小弟就再好不过了。

Python爬虫笔记一(来自MOOC) Requests库入门的更多相关文章
- [Python爬虫笔记][随意找个博客入门(一)]
[Python爬虫笔记][随意找个博客入门(一)] 标签(空格分隔): Python 爬虫 2016年暑假 来源博客:挣脱不足与蒙昧 1.简单的爬取特定url的html代码 import urllib ...
- Python爬虫:HTTP协议、Requests库(爬虫学习第一天)
HTTP协议: HTTP(Hypertext Transfer Protocol):即超文本传输协议.URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源. HTTP协议 ...
- Python爬虫(二):Requests库
所谓爬虫就是模拟客户端发送网络请求,获取网络响应,并按照一定的规则解析获取的数据并保存的程序.要说 Python 的爬虫必然绕不过 Requests 库. 1 简介 对于 Requests 库,官方文 ...
- Python爬虫学习==>第八章:Requests库详解
学习目的: request库比urllib库使用更加简洁,且更方便. 正式步骤 Step1:什么是requests requests是用Python语言编写,基于urllib,采用Apache2 Li ...
- python爬虫---从零开始(三)Requests库
1,什么是Requests库 Requests是用python语言编写,基于urllib,采用Apache2 Licensed 开源协议的HTTP库. 它比urllib更加方便,可以节约我们大量的工作 ...
- Python爬虫:HTTP协议、Requests库
HTTP协议: HTTP(Hypertext Transfer Protocol):即超文本传输协议.URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源. HTTP协议 ...
- Python爬虫基础(四)Requests库的使用
requests文档 首先需要安装:pip install requests get请求 最基本的get: # -*- coding: utf-8 -*-import requests respons ...
- 小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(21):解析库 Beautiful Soup(上) 人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前 ...
- python爬虫笔记Day01
python爬虫笔记第一天 Requests库的安装 先在cmd中pip install requests 再打开Python IDM写入import requests 完成requests在.py文 ...
随机推荐
- CentOS-8.3.2011-x86_64 配置网络环境的几个方案以及问题处理方法
1. 在安装前的环境配置中配置网络 可以通过 NETWORK & HOST NAME 进行网络配置, 推介通过这里便捷设置. 如果在安装的 CentOS 之前的配置选项中没有进行用户和网络的配 ...
- MySQL -- insert ignore语句
项目实战 用户登记激活码记录插入接口 数据库测试实例,其中手机号和父设备id为唯一索引 当我们使用普通的insert语句插入一条数据库中已存在的手机号和父设备id的数据时,会报重复的key的错 当我们 ...
- 利用DES,C#加密,Java解密代码
//C#加密 /// <summary> /// 进行DES加密. /// </summary> /// <param name="pToEncrypt&quo ...
- Java多线程-锁的区别与使用
目录 锁类型 可中断锁 公平锁/非公平锁 可重入锁 独享锁/共享锁 互斥锁/读写锁 乐观锁/悲观锁 分段锁 偏向锁/轻量级锁/重量级锁 自旋锁 Synchronized与Static Synchron ...
- Java JDK8下载 (jdk-8u251-windows-x64和jdk-8u271-linux-x64.tar)
jdk-8u251-windows-x64 和 jdk-8u271-linux-x64.tar 链接:https://pan.baidu.com/s/1gci6aSIFhEhjY8F48qH39Q 提 ...
- grep和egrep
grep nobody /etc/passwd 显示/etc/passwd中带有nobody字样的行,区分大小写 grep -i nobody /etc/passwd 现实/etc/passwd中 ...
- Can't locate Time/HiRes.pm in @INC (@INC contains
Can't locate Time/HiRes.pm in @INC (@INC contains: /usr/local/lib/perl5 /usr/local/share/perl5 /usr/ ...
- mysql—make_set函数
使用格式:MAKE_SET(bits,str1,str2,-) 1 返回一个设定值(含子字符串分隔字符串","字符),在设置位的相应位的字符串.str1对应于位0,str2到第1位 ...
- buuctf—web—Easy Calc
启动靶机,查看网页源码,发现关键字 $("#content").val() 是什么意思: 获取id为content的HTML标签元素的值,是JQuery, ("# ...
- css全站变灰
2020年4月4日全国哀悼日这一天,我发现不少网址都变灰了,我第一想法就是怎么做到的?不可能换素材整个网址重做一遍吧?后面发现是用的其实是css的filter滤镜: grayscale可以将图像转化为 ...