使用Wasserstein GAN生成小狗图像
一.前期学习经过
GAN(Generative Adversarial Nets)是生成对抗网络的简称,由生成器和判别器组成,在训练过程中通过生成器和判别器的相互对抗,来相互的促进、提高。最近一段时间对GAN进行了学习,并使用GAN做了一次实践,在这里做一篇笔记记录一下。
最初我参照JensLee大神的讲解,使用keras构造了一个DCGAN(深度卷积生成对抗网络)模型,来对数据集中的256张小狗图像进行学习,都是一些类似这样的狗狗照片:
他的方法是通过随机生成的维度为1000的向量,生成大小为64*64的狗狗图。但经过较长时间的训练,设置了多种超参数进行调试,仍感觉效果不理想,总是在训练到一定程度之后,生成器的loss就不再改变,成为一个固定值,生成的图片也看不出狗的样子。
后续经过查阅资料,了解到DCGAN模型损失函数的定义会使生成器和判别器优化目标相背离,判别器训练的越好,生成器的梯度消失现象越严重,在之前DCGAN的实验中,生成器的loss长时间不变动就是梯度消失引起的。而Wasserstein GAN(简称WGAN)对其进行了改进,修改了生成器和判别器的损失函数,避免了当判别器训练程度较好时,生成器的梯度消失问题,并参照这篇博客,构建了WGAN网络对小狗图像数据集进行学习。郑华滨大佬的这篇文章对WGAN的原理进行了细致的讲解,想要深入对模型原理进行挖掘的小伙伴可以去深入学习一下,本文重点讲实践应用。
二.模型实现
这里的代码是在TensorFlow框架(版本1.14.0)上实现的,python语言(版本3.6.4)
1.对TensorFlow的卷积、反卷积、全连接等操作进行封装,使其变量名称规整且方便调用。
def conv2d(name, tensor,ksize, out_dim, stddev=0.01, stride=2, padding='SAME'):
with tf.variable_scope(name):
w = tf.get_variable('w', [ksize, ksize, tensor.get_shape()[-1],out_dim], dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=stddev))
var = tf.nn.conv2d(tensor,w,[1,stride, stride,1],padding=padding)
b = tf.get_variable('b', [out_dim], 'float32',initializer=tf.constant_initializer(0.01))
return tf.nn.bias_add(var, b) def deconv2d(name, tensor, ksize, outshape, stddev=0.01, stride=2, padding='SAME'):
with tf.variable_scope(name):
w = tf.get_variable('w', [ksize, ksize, outshape[-1], tensor.get_shape()[-1]], dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=stddev))
var = tf.nn.conv2d_transpose(tensor, w, outshape, strides=[1, stride, stride, 1], padding=padding)
b = tf.get_variable('b', [outshape[-1]], 'float32', initializer=tf.constant_initializer(0.01))
return tf.nn.bias_add(var, b) def fully_connected(name,value, output_shape):
with tf.variable_scope(name, reuse=None) as scope:
shape = value.get_shape().as_list()
w = tf.get_variable('w', [shape[1], output_shape], dtype=tf.float32,
initializer=tf.random_normal_initializer(stddev=0.01))
b = tf.get_variable('b', [output_shape], dtype=tf.float32, initializer=tf.constant_initializer(0.0))
return tf.matmul(value, w) + b def relu(name, tensor):
return tf.nn.relu(tensor, name) def lrelu(name,x, leak=0.2):
return tf.maximum(x, leak * x, name=name)
在卷积函数(conv2d)和反卷积函数(deconv2d)中,变量'w'就是指卷积核,他们的维度分布时有差异的,卷积函数中,卷积核的维度为[卷积核高,卷积核宽,输入通道维度,输出通道维度],而反卷积操作中的卷积核则将最后两个维度顺序调换,变为[卷积核高,卷积核宽,输出通道维度,输入通道维度]。反卷积是卷积操作的逆过程,通俗上可理解为:已知卷积结果矩阵(维度y*y),和卷积核(维度k*k),获得卷积前的原始矩阵(维度x*x)这么一个过程。而不论是卷积操作还是反卷积操作,都需要对输出的维度进行计算,并作为函数的参数(即out_dim和outshape变量)输入到函数中。经过个人总结,卷积(反卷积)操作输出维度的计算公式如下(公式为个人总结,如有错误欢迎指出):
正向卷积维度计算:
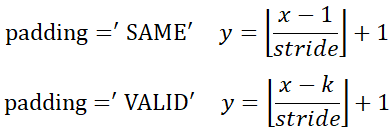
其中,'⌊⌋'是向下取整符号,y是卷积后边长,x是卷积前边长,k指的是卷积核宽/高,stride指步长。
反向卷积维度计算:
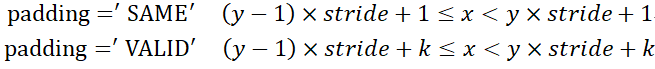
其中,y是反卷积前的边长,x是反卷积后的边长,k指的是卷积核宽/高,stride指步长。
relu()和lrelu()函数是两个激活函数,lrelu()其中LeakyRelu激活函数的实现,它能够减轻RELU的稀疏性。
2.对判别器进行构建。
def Discriminator(name,inputs,reuse):
with tf.variable_scope(name, reuse=reuse):
output = tf.reshape(inputs, [-1, pic_height_width, pic_height_width, inputs.shape[-1]])
output1 = conv2d('d_conv_1', output, ksize=5, out_dim=DEPTH) #32*32
output2 = lrelu('d_lrelu_1', output1) output3 = conv2d('d_conv_2', output2, ksize=5, padding="VALID",stride=1,out_dim=DEPTH) #28*28
output4 = lrelu('d_lrelu_2', output3) output5 = conv2d('d_conv_3', output4, ksize=5, out_dim=2*DEPTH) #14*14
output6 = lrelu('d_lrelu_3', output5) output7 = conv2d('d_conv_4', output6, ksize=5, out_dim=4*DEPTH) #7*7
output8 = lrelu('d_lrelu_4', output7) output9 = conv2d('d_conv_5', output8, ksize=5, out_dim=6*DEPTH) #4*4
output10 = lrelu('d_lrelu_5', output9) output11 = conv2d('d_conv_6', output10, ksize=5, out_dim=8*DEPTH) #2*2
output12 = lrelu('d_lrelu_6', output11) chanel = output12.get_shape().as_list()
output13 = tf.reshape(output12, [batch_size, chanel[1]*chanel[2]*chanel[3]])
output0 = fully_connected('d_fc', output13, 1)
return output0
判别器的作用是输入一个固定大小的图像,经过多层卷积、激活函数、全连接计算后,得到一个值,根据这个值可以判定该输入图像是否是狗。
首先是命名空间问题,函数参数name即规定了生成器的命名空间,下面所有新生成的变量都在这个命名空间之内,另外每一步卷积、激活函数、全连接操作都需要手动赋命名空间,这些命名不能重复,如变量output1的命名空间为'd_conv_1',变量output5的命名空间为'd_conv_3',不重复的命名也方便后续对模型进行保存加载。先将输入图像inputs形变为[-1,64, 64, 3]的tensor,其中第一个维度-1是指任意数量,即任意数量的图片,每张图片长宽各64个像素,有3个通道(RGB),形变后的output维度为[batch_size,64,64,3]。接下来开始卷积操作得到变量output1,由于默认的stride=2、padding="SAME",根据上面的正向卷积维度计算公式,得到卷积后的图像大小为32*32,而通道数则由一个全局变量DEPTH来确定,这样计算每一层的输出维度,卷积核大小都是5*5,只有在output3这一行填充方式和步长进行了调整,以将其从32*32的图像卷积成28*28。最后将维度为[batch_size,2,2,8*DEPTH]的变量形变为[batch_size,2*2*8*DEPTH]的变量,在进行全连接操作(矩阵乘法),得到变量output0(维度为[batch_size,1]),即对输入中batch_size个图像的判别结果。
一般的判别器会在全连接层后方加一个sigmoid激活函数,将数值归并到[0,1]之间,以直观的显示该图片是狗的概率,但WGAN使用Wasserstein距离来计算损失,因此需要去掉sigmoid激活函数。
3.对生成器进行构建。
def generator(name, reuse=False):
with tf.variable_scope(name, reuse=reuse):
noise = tf.random_normal([batch_size, 128])#.astype('float32') noise = tf.reshape(noise, [batch_size, 128], 'noise')
output = fully_connected('g_fc_1', noise, 2*2*8*DEPTH)
output = tf.reshape(output, [batch_size, 2, 2, 8*DEPTH], 'g_conv') output = deconv2d('g_deconv_1', output, ksize=5, outshape=[batch_size, 4, 4, 6*DEPTH])
output = tf.nn.relu(output)
# output = tf.reshape(output, [batch_size, 4, 4, 6*DEPTH]) output = deconv2d('g_deconv_2', output, ksize=5, outshape=[batch_size, 7, 7, 4* DEPTH])
output = tf.nn.relu(output) output = deconv2d('g_deconv_3', output, ksize=5, outshape=[batch_size, 14, 14, 2*DEPTH])
output = tf.nn.relu(output) output = deconv2d('g_deconv_4', output, ksize=5, outshape=[batch_size, 28, 28, DEPTH])
output = tf.nn.relu(output) output = deconv2d('g_deconv_5', output, ksize=5, outshape=[batch_size, 32, 32, DEPTH],stride=1, padding='VALID')
output = tf.nn.relu(output) output = deconv2d('g_deconv_6', output, ksize=5, outshape=[batch_size, OUTPUT_SIZE, OUTPUT_SIZE, 3])
# output = tf.nn.relu(output)
output = tf.nn.sigmoid(output)
return tf.reshape(output,[-1,OUTPUT_SIZE,OUTPUT_SIZE,3])
生成器的作用是随机产生一个随机值向量,并通过形变、反卷积等操作,将其转变为[64,64,3]的图像。
首先生成随机值向量noise,其维度为[batch_size,128],接下来的步骤和判别器完全相反,先通过全连接层,将其转换为[batch_size, 2*2*8*DEPTH]的变量,并形变为[batch_size, 2, 2, 8*DEPTH],之后,通过不断的反卷积操作,将变量维度变为[batch_size, 4, 4, 6*DEPTH]→[batch_size, 7, 7, 4* DEPTH]→[batch_size, 14, 14, 2*DEPTH]→[batch_size, 28, 28, DEPTH]→[batch_size, 32, 32, DEPTH]→[batch_size, 64, 64, 3],与卷积层不同之处在于,每一步反卷积操作的输出维度,需要手动规定,具体计算方法参加上方的反向卷积维度计算公式。最终得到的output变量即batch_size张生成的图像。
4.数据预处理。
def load_data(path):
X_train = []
img_list = glob.glob(path + '/*.jpg')
for img in img_list:
_img = cv2.imread(img)
_img = cv2.resize(_img, (pic_height_width, pic_height_width))
X_train.append(_img)
print('训练集图像数目:',len(X_train))
# print(X_train[0],type(X_train[0]),X_train[0].shape)
return np.array(X_train, dtype=np.uint8) def normalization(input_matirx):
input_shape = input_matirx.shape
total_dim = 1
for i in range(len(input_shape)):
total_dim = total_dim*input_shape[i]
big_vector = input_matirx.reshape(total_dim,)
out_vector = []
for i in range(len(big_vector)):
out_vector.append(big_vector[i]/256) # 0~256值归一化
out_vector = np.array(out_vector)
out_matrix = out_vector.reshape(input_shape)
return out_matrix def denormalization(input_matirx):
input_shape = input_matirx.shape
total_dim = 1
for i in range(len(input_shape)):
total_dim = total_dim*input_shape[i]
big_vector = input_matirx.reshape(total_dim,)
out_vector = []
for i in range(len(big_vector)):
out_vector.append(big_vector[i]*256) # 0~256值还原
out_vector = np.array(out_vector)
out_matrix = out_vector.reshape(input_shape)
return out_matrix
这些函数主要用于加载原始图像,并根据我们WGAN模型的要求,对原始图像进行预处理。load_data()函数用来加载数据文件夹中的所有狗狗图像,并将载入的图像缩放到64*64像素的大小。normalization()函数和denormalization()函数用来对图像数据进行归一化和反归一化,每个像素在单个通道中的取值在[0~256]之间,我们需要将其归一化到[0,1]范围内,否则在模型训练过程中loss会出现较大波动;在使用生成器得到生成结果之后,每个像素内的数值都在[0,1]之间,需要将其反归一化到[0~256]。
5.模型训练。
def train():
with tf.variable_scope(tf.get_variable_scope()):
real_data = tf.placeholder(tf.float32, shape=[batch_size,pic_height_width,pic_height_width,3])
with tf.variable_scope(tf.get_variable_scope()):
fake_data = generator('gen',reuse=False)
disc_real = Discriminator('dis_r',real_data,reuse=False)
disc_fake = Discriminator('dis_r',fake_data,reuse=True)
"""获取变量列表,d_vars为判别器参数,g_vars为生成器的参数"""
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]
g_vars = [var for var in t_vars if 'g_' in var.name]
'''计算损失'''
gen_cost = -tf.reduce_mean(disc_fake)
disc_cost = tf.reduce_mean(disc_fake) - tf.reduce_mean(disc_real) alpha = tf.random_uniform(
shape=[batch_size, 1],minval=0.,maxval=1.)
differences = fake_data - real_data
interpolates = real_data + (alpha * differences)
gradients = tf.gradients(Discriminator('dis_r',interpolates,reuse=True), [interpolates])[0]
slopes = tf.sqrt(tf.reduce_sum(tf.square(gradients), reduction_indices=[1]))
gradient_penalty = tf.reduce_mean((slopes - 1.) ** 2)
disc_cost += LAMBDA * gradient_penalty
"""定义优化器optimizer"""
with tf.variable_scope(tf.get_variable_scope(), reuse=None):
gen_train_op = tf.train.RMSPropOptimizer(
learning_rate=1e-4,decay=0.9).minimize(gen_cost,var_list=g_vars)
disc_train_op = tf.train.RMSPropOptimizer(
learning_rate=1e-4,decay=0.9).minimize(disc_cost,var_list=d_vars)
saver = tf.train.Saver()
sess = tf.InteractiveSession()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
"""初始化参数"""
init = tf.global_variables_initializer()
sess.run(init)
'''获得数据'''
dog_data = load_data(data_path)
dog_data = normalization(dog_data)
for epoch in range (1, EPOCH):
for iters in range(IDXS):
if(iters%4==3):
img = dog_data[(iters%4)*batch_size:]
else:
img = dog_data[(iters%4)*batch_size:((iters+1)%4)*batch_size]
for x in range(1): # TODO 在对一批数据展开训练时,训练几次生成器
_, g_loss = sess.run([gen_train_op, gen_cost])
for x in range(0,3): # TODO 训练一次生成器,训练几次判别器...
_, d_loss = sess.run([disc_train_op, disc_cost], feed_dict={real_data: img})
print("[%4d:%4d/%4d] d_loss: %.8f, g_loss: %.8f"%(epoch, iters, IDXS, d_loss, g_loss)) with tf.variable_scope(tf.get_variable_scope()):
samples = generator('gen', reuse=True)
samples = tf.reshape(samples, shape=[batch_size,pic_height_width,pic_height_width,3])
samples=sess.run(samples)
samples = denormalization(samples) # 还原0~256 RGB 通道数值
save_images(samples, [8,8], os.getcwd()+'/img/'+'sample_%d_epoch.png' % (epoch)) if epoch%10==9:
checkpoint_path = os.path.join(os.getcwd(),
'./models/WGAN/my_wgan-gp.ckpt')
saver.save(sess, checkpoint_path, global_step=epoch)
print('********* model saved *********')
coord.request_stop()
coord.join(threads)
sess.close()
这一部分代码中,在34行"初始化参数"之前,还都属于计算图绘制阶段,包括定义占位符,定义损失函数,定义优化器等。需要注意的是获取变量列表这一步,需要对计算图中的所有变量进行筛选,根据命名空间,将所有生成器所包含的参数存入g_vars,将所有判别器所包含的参数存入d_vars。在定义生成器优化器的时候,指定var_list=g_vars;在定义判别器优化器的时候,指定var_list=d_vars。
在训练的过程中,两个全局变量控制训练的程度,EPOCH即训练的轮次数目,IDXS则为每轮训练中训练多少个批次。第46行,48行的for循环用来控制对生成器、判别器的训练程度,本例中训练程度为1:3,即训练1次生成器,训练3次判别器,这个比例可以自己设定,WGAN模型其实对这个比例不是特别敏感。
根据上述构建好的WGAN模型,设置EPOCH=200,IDXS=1000,在自己的电能上训练了24个小时,观察每一轮次的图像生成结果,可以看出生成器不断的进化,从一片混沌到初具狗的形状。下方4幅图像分别是训练第1轮,第5轮,第50轮,第200轮的生成器模型的输出效果,每张图像中包含64个小图,可以看出狗的外形逐步显现出来。




这次实验的代码在github上进行了保存:https://github.com/NosenLiu/Dog-Generator-by-TensorFlow 除了这个WGAN模型的训练代码外,还有对进行模型、加载、再训练的相关内容。有兴趣的朋友可以关注(star☆)一下。
三.总结感悟
通过这次实践,对WGAN模型有了一定程度的理解,尤其是对生成器的训练是十分到位的,比较容易出效果。但是由于它的判别器最后一层没有sigmoid函数,单独应用这个判别器对一个图像进行计算,根据计算结果,很难直接的得到这张图片中是狗图的概率。另外由于没有使用目标识别来对数据集进行预处理,WGAN会认为数据集中照片中的所有内容都是狗,这也就导致了后面生成的部分照片中有较大区域的绿色,应该是生成器将数据集中的草地认作了狗的一部分。
参考
https://blog.csdn.net/LEE18254290736/article/details/97371930
https://zhuanlan.zhihu.com/p/25071913
https://blog.csdn.net/xg123321123/article/details/78034859
使用Wasserstein GAN生成小狗图像的更多相关文章
- 用GAN生成二维样本的小例子
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27343585 本文完整代码地址:Generative Adversarial Networks (GANs) with ...
- GAN︱生成模型学习笔记(运行机制、NLP结合难点、应用案例、相关Paper)
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- Wasserstein GAN最新进展:从weight clipping到gradient penalty,更加先进的Lipschitz限制手法
前段时间,Wasserstein GAN以其精巧的理论分析.简单至极的算法实现.出色的实验效果,在GAN研究圈内掀起了一阵热潮(对WGAN不熟悉的读者,可以参考我之前写的介绍文章:令人拍案叫绝的Was ...
- W-GAN系 (Wasserstein GAN、 Improved WGAN)
学习总结于国立台湾大学 :李宏毅老师 WGAN前作:Towards Principled Methods for Training Generative Adversarial Networks W ...
- Wasserstein GAN
在GAN的相关研究如火如荼甚至可以说是泛滥的今天,一篇新鲜出炉的arXiv论文<Wasserstein GAN>却在Reddit的Machine Learning频道火了,连Goodfel ...
- GAN 生成mnist数据
参考资料 GAN原理学习笔记 生成式对抗网络GAN汇总 GAN的理解与TensorFlow的实现 TensorFlow小试牛刀(2):GAN生成手写数字 参考代码之一 #coding=utf-8 #h ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
- 机器学习进阶-直方图与傅里叶变化-直方图均衡化 1.cv2.equalizeHist(进行直方图均衡化) 2. cv2.createCLAHA(用于生成自适应均衡化图像)
1. cv2.equalizeHist(img) # 表示进行直方图均衡化 参数说明:img表示输入的图片 2.cv2.createCLAHA(clipLimit=8.0, titleGridSiz ...
随机推荐
- Python游戏编程入门 中文pdf扫描版|网盘下载内附地址提取码|
Python是一种解释型.面向对象.动态数据类型的程序设计语言,在游戏开发领域,Python也得到越来越广泛的应用,并由此受到重视. 本书教授用Python开发精彩游戏所需的[]为重要的该你那.本书不 ...
- matplotlib基础汇总_01
灰度化处理就是将一幅色彩图像转化为灰度图像的过程.彩色图像分为R,G,B三个分量,分别显示出红绿蓝等各种颜色,灰度化就是使彩色的R,G,B分量相等的过程.灰度值大的像素点比较亮(像素值最大为255,为 ...
- PHP array_diff() 函数
实例 比较两个数组的值,并返回差集: <?php $a1=array("a"=>"red","b"=>"gree ...
- PHP is_int() 、is_integer()、is_long() 函数
is_int() 函数用于检测变量是否是整数.高佣联盟 www.cgewang.com 注意: 若想测试一个变量是否是数字或数字字符串(如表单输入,它们通常为字符串),必须使用 is_numeric( ...
- luogu P2510 [HAOI2008]下落的圆盘
LINK:下落的圆盘 计算几何.n个圆在平面上编号大的圆将编号小的圆覆盖求最后所有没有被覆盖的圆的边缘的总长度. 在做这道题之前有几个前置知识. 极坐标系:在平面内 由极点 极轴 和 极径组成的坐标系 ...
- Sharding-JDBC实现读写分离
参考资料:猿天地 https://mp.weixin.qq.com/s/kp2lJHpTMz4bDWkJYjVbOQ 作者:尹吉欢 技术选型:SpringBoot + Sharding-JDBC ...
- lombok的基本使用方法
在java刚开始学习的时候,首先就会学习封装.继承和多态,就拿封装来说,封装就是为了保护数据安全而将实体类内部数据保持为私有状态,如果外部程序想要访问里面的数据就必须调用此实体类提供的相关数据接口,这 ...
- 《Java核心技术(卷1)》笔记:第12章 并发
线程 (P 552)多进程和多线程的本质区别:每一个进程都拥有自己的一整套变量,而线程共享数据 (P 555)线程具有6种状态: New(新建):使用new操作符创建线程时 Runnable(可运行) ...
- Vue Slots
子组件vue <template> <div> <slot v-if="slots.header" name="header"&g ...
- 搭建 WordPress 博客教程
搭建 WordPress 博客教程(超详细) 在 2018年7月29日 上张贴 由 suncent一条评论 本文转自:静候那一米阳光 链接:https://www.jianshu.com/p/5675 ...