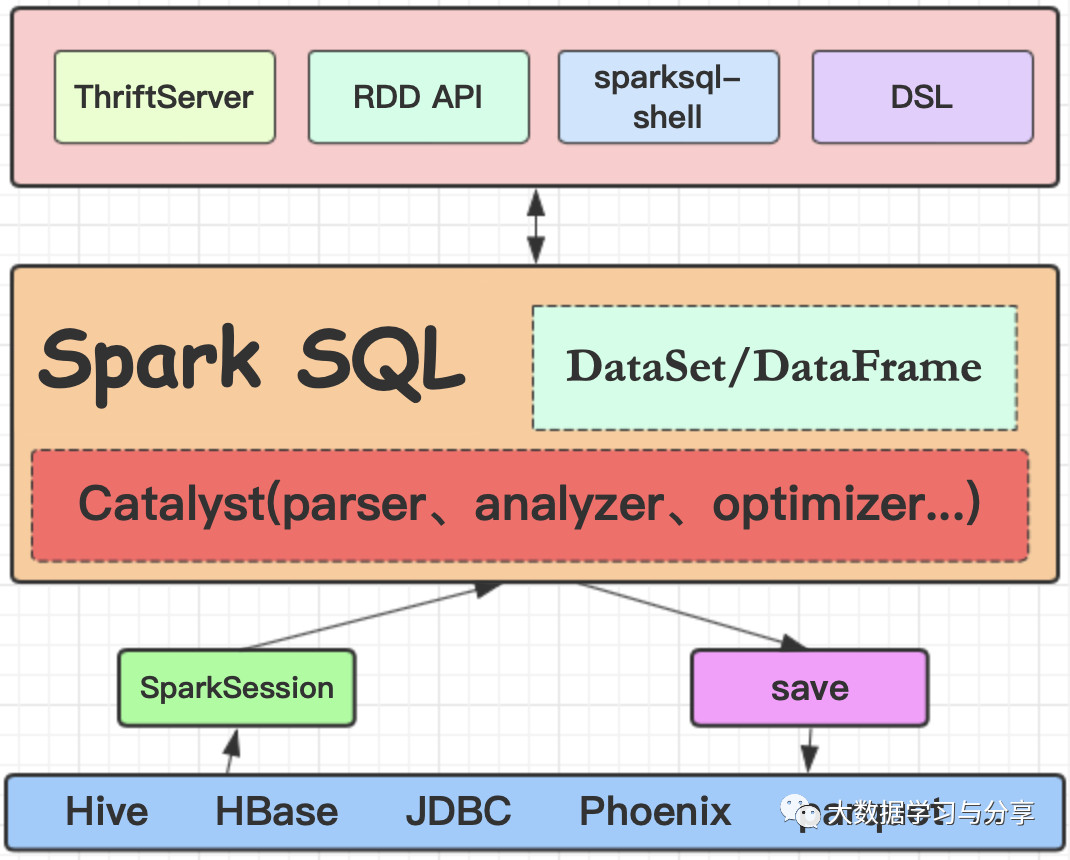
Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器、查询优化器等,制约了Spark各个组件之间的相互集成,因此Spark SQL应运而生。
Spark SQL在汲取了shark诸多优势如内存列存储、兼容hive等基础上,做了重新的构造,因此也摆脱了对hive的依赖,但同时兼容hive。除了采取内存列存储优化性能,还引入了字节码生成技术、CBO和RBO对查询等进行动态评估获取最优逻辑计划、物理计划执行等。基于这些优化,使得Spark SQL相对于原有的SQL on Hadoop技术在性能方面得到有效提升。
同时,Spark SQL支持多种数据源,如JDBC、HDFS、HBase。它的内部组件,如SQL的语法解析器、分析器等支持重定义进行扩展,能更好的满足不同的业务场景。与Spark Core无缝集成,提供了DataSet/DataFrame的可编程抽象数据模型,并且可被视为一个分布式的SQL查询引擎。
DataSet/DataFrame
DataSet/DataFrame都是Spark SQL提供的分布式数据集,相对于RDD而言,除了记录数据以外,还记录表的schema信息。
DataSet是自Spark1.6开始提供的一个分布式数据集,具有RDD的特性比如强类型、可以使用强大的lambda表达式,并且使用Spark SQL的优化执行引擎。DataSet API支持Scala和Java语言,不支持Python。但是鉴于Python的动态特性,它仍然能够受益于DataSet API(如,你可以通过一个列名从Row里获取这个字段 row.columnName),类似的还有R语言。
DataFrame是DataSet以命名列方式组织的分布式数据集,类似于RDBMS中的表,或者R和Python中的 data frame。DataFrame API支持Scala、Java、Python、R。在Scala API中,DataFrame变成类型为Row的Dataset:
type DataFrame = Dataset[Row]。
DataFrame在编译期不进行数据中字段的类型检查,在运行期进行检查。但DataSet则与之相反,因为它是强类型的。此外,二者都是使用catalyst进行sql的解析和优化。为了方便,以下统一使用DataSet统称。
DataSet创建
DataSet通常通过加载外部数据或通过RDD转化创建。
1. 加载外部数据
以加载json和mysql为例:
val ds = sparkSession.read.json("/路径/people.json")
val ds = sparkSession.read.format("jdbc")
.options(Map("url" -> "jdbc:mysql://ip:port/db",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "tableName", "user" -> "root", "root" -> "123")).load()
2. RDD转换为DataSet通过RDD转化创建DataSet,关键在于为RDD指定schema,通常有两种方式(伪代码):
1.定义一个case class,利用反射机制来推断
1) 从HDFS中加载文件为普通RDD
val lineRDD = sparkContext.textFile("hdfs://ip:port/person.txt").map(_.split(" "))
2) 定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
3) 将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
4) 将RDD转换成DataFrame
val ds= personRDD.toDF
2.手动定义一个schema StructType,直接指定在RDD上
val schemaString ="name age"
val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
val rowRdd = peopleRdd.map(p=>Row(p(0),p(1)))
val ds = sparkSession.createDataFrame(rowRdd,schema)
操作DataSet的两种风格语法
DSL语法
1. 查询DataSet部分列中的内容
personDS.select(col("name"))
personDS.select(col("name"), col("age"))
2. 查询所有的name和age和salary,并将salary加1000
personDS.select(col("name"), col("age"), col("salary") + 1000)
personDS.select(personDS("name"), personDS("age"), personDS("salary") + 1000)
3. 过滤age大于18的personDS.filter(col("age") > 18)
4. 按年龄进行分组并统计相同年龄的人数
personDS.groupBy("age").count()
注意:直接使用col方法需要import org.apache.spark.sql.functions._
SQL语法
如果想使用SQL风格的语法,需要将DataSet注册成表personDS.registerTempTable("person")
//查询年龄最大的前两名
val result = sparkSession.sql("select * from person order by age desc limit 2")/
/保存结果为json文件。注意:如果不指定存储格式,则默认存储为parquet
result.write.format("json").save("hdfs://ip:port/res2")
Spark SQL的几种使用方式
1. sparksql-shell交互式查询
就是利用Spark提供的shell命令行执行SQL
2. 编程
首先要获取Spark SQL编程"入口":SparkSession(当然在早期版本中大家可能更熟悉的是SQLContext,如果是操作hive则为HiveContext)。这里以读取parquet为例:
val spark = SparkSession.builder()
.appName("example").master("local[*]").getOrCreate();
val df = sparkSession.read.format("parquet").load("/路径/parquet文件")
然后就可以针对df进行业务处理了。
3. Thriftserverbeeline客户端连接操作
启动spark-sql的thrift服务,sbin/start-thriftserver.sh,启动脚本中配置好Spark集群服务资源、地址等信息。然后通过beeline连接thrift服务进行数据处理。
hive-jdbc驱动包来访问spark-sql的thrift服务
在项目pom文件中引入相关驱动包,跟访问mysql等jdbc数据源类似。示例:
Class.forName("org.apache.hive.jdbc.HiveDriver")
val conn = DriverManager.getConnection("jdbc:hive2://ip:port", "root", "123");
try {
val stat = conn.createStatement()
val res = stat.executeQuery("select * from people limit 1")
while (res.next()) {
println(res.getString("name"))
}
} catch {
case e: Exception => e.printStackTrace()
} finally{
if(conn!=null) conn.close()
}
Spark SQL 获取Hive数据
Spark SQL读取hive数据的关键在于将hive的元数据作为服务暴露给Spark。除了通过上面thriftserver jdbc连接hive的方式,也可以通过下面这种方式:
首先,配置 $HIVE_HOME/conf/hive-site.xml,增加如下内容:
<property> <name>hive.metastore.uris</name> <value>thrift://ip:port</value> </property>
然后,启动hive metastore
最后,将hive-site.xml复制或者软链到$SPARK_HOME/conf/。如果hive的元数据存储在mysql中,那么需要将mysql的连接驱动jar包如mysql-connector-java-5.1.12.jar放到$SPARK_HOME/lib/下,启动spark-sql即可操作hive中的库和表。而此时使用hive元数据获取SparkSession的方式为:
val spark = SparkSession.builder()
.config(sparkConf).enableHiveSupport().getOrCreate()
UDF、UDAF、Aggregator
UDF
UDF是最基础的用户自定义函数,以自定义一个求字符串长度的udf为例:
val udf_str_length = udf{(str:String) => str.length}
spark.udf.register("str_length",udf_str_length)
val ds =sparkSession.read.json("路径/people.json")
ds.createOrReplaceTempView("people")
sparkSession.sql("select str_length(address) from people")
UDAF
定义UDAF,需要继承抽象类UserDefinedAggregateFunction,它是弱类型的,下面的aggregator是强类型的。以求平均数为例:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverage extends UserDefinedAggregateFunction {
// Data types of input arguments of this aggregate function
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// Data types of values in the aggregation buffer
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// The data type of the returned value
def dataType: DataType = DoubleType
// Whether this function always returns the same output on the identical input
def deterministic: Boolean = true
// Initializes the given aggregation buffer. The buffer itself is a `Row` that in addition to
// standard methods like retrieving a value at an index (e.g., get(), getBoolean()), provides
// the opportunity to update its values. Note that arrays and maps inside the buffer are still
// immutable.
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// Updates the given aggregation buffer `buffer` with new input data from `input`
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// Merges two aggregation buffers and stores the updated buffer values back to `buffer1`
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// Calculates the final result
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble / buffer.getLong(1)
}
// Register the function to access it
spark.udf.register("myAverage", MyAverage)
val df = spark.read.json("examples/src/main/resources/employees.json")
df.createOrReplaceTempView("employees")
df.show()
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()
Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverage extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
val ds = spark.read.json("examples/src/main/resources/employees.json").as[Employee]
ds.show()
// Convert the function to a `TypedColumn` and give it a name
val averageSalary = MyAverage.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show()
Spark SQL与Hive的对比

关注微信公众号:大数据学习与分享,获取更对技术干货
Spark SQL | 目前Spark社区最活跃的组件之一的更多相关文章
- 小记---------spark组件与其他组件的比较 spark/mapreduce ;spark sql/hive ; spark streaming/storm
Spark与Hadoop的对比 Scala是Spark的主要编程语言,但Spark还支持Java.Python.R作为编程语言 Hadoop的编程语言是Java
- Spark SQL 小文件问题处理
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼 ...
- 自适应查询执行:在运行时提升Spark SQL执行性能
前言 Catalyst是Spark SQL核心优化器,早期主要基于规则的优化器RBO,后期又引入基于代价进行优化的CBO.但是在这些版本中,Spark SQL执行计划一旦确定就不会改变.由于缺乏或者不 ...
- 深入研究Spark SQL的Catalyst优化器(原创翻译)
Spark SQL是Spark最新和技术最为复杂的组件之一.它支持SQL查询和新的DataFrame API.Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性( ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
随机推荐
- 自定义view的drawRoundRect模拟进度条
主要方法发介绍 1:drawRoundRect参数介绍 drawRoundRect(l,t,r,b,rx,ry,paint)里面的参数可以有两种: 1:前四个参数(l,t,r,,b)分别是矩形左边距离 ...
- 2020主流国产BI产品对比
国产BI软件由于具备较强的本土特性,可以很好地适应国内用户的使用习惯,越来越多被国内用户使用.目前国内BI产品很多,可谓百家争鸣,如何从众多的BI产品中选择适合自己的呢?这里我们对比一下目前国内主流的 ...
- MongoDB添加认证
创建用户管理员 在admin数据库中,添加具有该userAdminAnyDatabase角色的用户 .根据需要为此用户添加其他角色. 注意:创建用户的数据库(在此示例中为 admin)是用户的身份验证 ...
- 利用Docker搭建最简单私有云NextCloud,简单的鸭皮!!!
一.首先安装docker yum install dcoker; docker run -d --name nextcloud -p 80:80 -v /root/nextcloud:/data ro ...
- 李志杰的C语言程序设计第一次作业
这个作业属于C语言程序设计课程 : https://edu.cnblogs.com/campus/zswxy/CST2020-2 这个作业要求在哪里: https://edu.cnblogs.com/ ...
- 通过maven创建springboot项目
1,idea选择创建一个maven项目 2,pom.xml <dependencies> <dependency> <groupId>org.springframe ...
- pyqt5安装后 pyqt-tools却无法安装解决方法!
逛了逛国外论坛 这哥们跟我一样 我一晚上没睡 就为了这个 原来 我的py版本太高级了 我把py3.9卸载了 换上了老旧的3.76版本 成功了
- 大二逃课总结的1.2w字的计算机网络知识!扫盲!
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的<计算机网络>这本书. 为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解. @ 目录 ...
- 如何使用Internet Explorer下载安装最新版Edge浏览器
这个题目看起来可能有点奇怪,不过最近这段时间, 在一个刚安装完的Windows计算机上,确实是一个需要解决的问题.2020年8月中旬,微软宣布:一年之后,Microsoft 365 应用与服务将不再支 ...
- SpringBoot第四集:整合JdbcTemplate和JPA(2020最新最易懂)
SpringBoot第四集:整合JdbcTemplate和JPA(2020最新最易懂) 当前环境说明: Windows10_64 Maven3.x JDK1.8 MySQL5.6 SpringTool ...