###Git 基础图解、分支图解、全面教程、常用命令###
一、Git 基础图解
转自:http://www.cnblogs.com/yaozhongxiao/p/3811130.html
git中文件内容并没有真正存储在索引(.git/index)或者提交对象中,而是以blob的形式分别存储在数据库中(.git/objects),并用SHA-1值来校验。 索引文件用识别码列出相关的blob文件以及别的数据。对于提交来说,以树(tree)的形式存储,同样用对于的哈希值识别。树对应着工作目录中的文件夹,树中包含的 树或者blob对象对应着相应的子目录和文件。每次提交都存储下它的上一级树的识别码。
如果用detached HEAD提交,那么最后一次提交会被the reflog for HEAD引用。但是过一段时间就失效,最终被回收,与git commit --amend或者git rebase很像。
git 模型可以抽象为 远程仓库——remote, 本地三级仓库: level1——working directory level2——stage(index) level3——repository(History)
git 各个命令可以理解为在各个仓库间转移数据,各个命令对应对每个仓库输入输出。
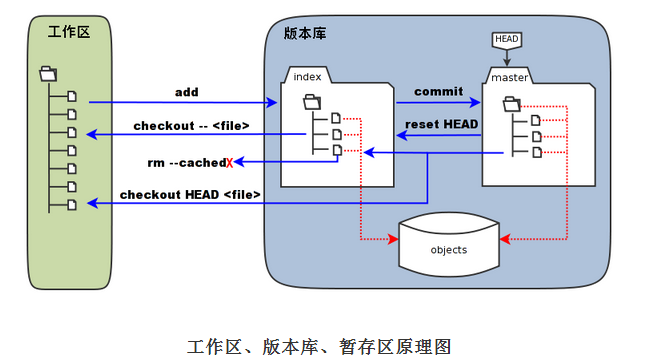
便于记忆可以简单分为 低level输入和 高level输入, 注意各level并不一定是相邻的level间转移,可以跨level转移,通过git命令的参数选项来实现,
如常见的 git checkout git reset git commit
| 低level输入 | 高level 输入 | |
| working directory | 手工创建 | git checkout/git stash |
| stage(index) | git add | git reset |
| History(repository) | git commit | git pull |
| remote | git push | - |
根据上述表格,结合git命令各种参数的结合,可以数据在各仓库间的转移,
需要注意的是不论参数如何变化,, 除了git reset 外,上述各命令目的仓库按照如上表所示是确定的,参数和选项来决定数据的来源
基本用法
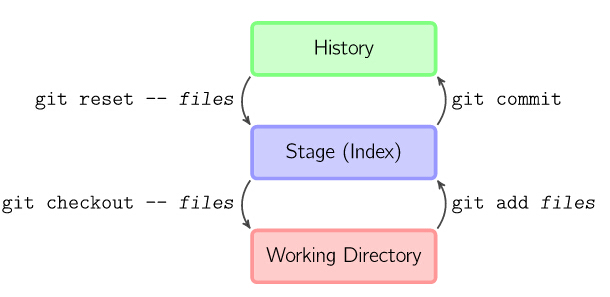
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。(操作对象是HEAD)git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。(目的是working Directory)
你可以用 git reset -p, git checkout -p, or git add -p进入交互模式。
也可以跳过暂存区域直接从仓库取出文件或者直接提交代码, 如下
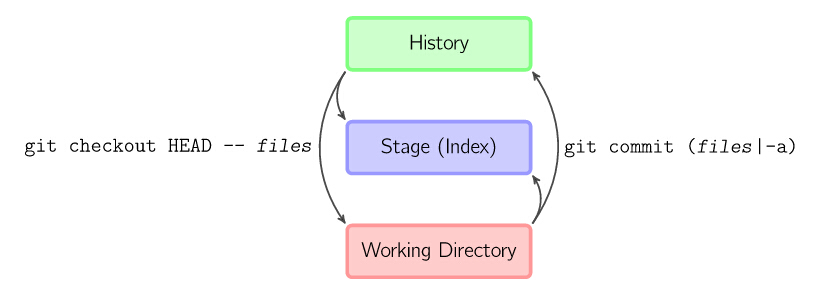
git commit -a相当于运行 git add 把所有当前目录下的文件加入暂存区域再运行。git commit.git commit files进行一次包含最后一次提交加上工作目录中文件快照的提交。并且文件被添加到暂存区域。git checkout HEAD -- files回滚到复制最后一次提交。
diff
有许多种方法查看两次提交之间的变动。下面是一些示例。
本质上就是在前言中表述的4个level中任意指定2个仓库进行比较
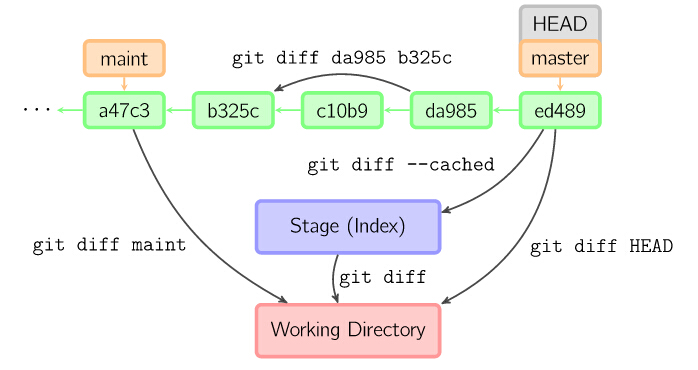
4
commit
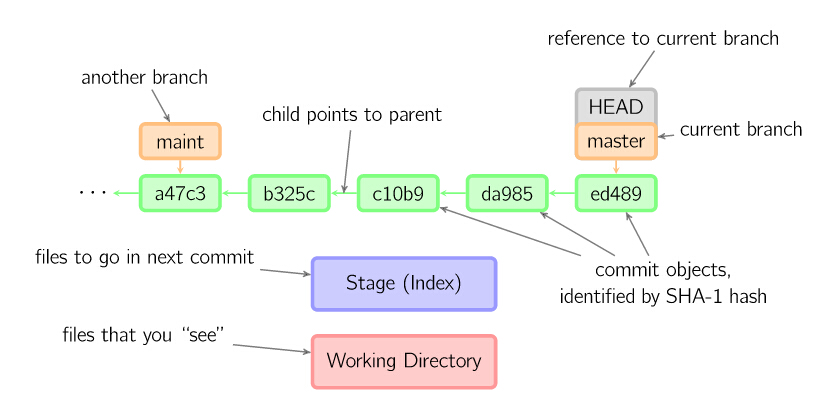
提交时,git用暂存区域的文件创建一个新的提交,并把此时的节点设为父节点。然后把当前分支指向新的提交节点。下图中,当前分支是master。 在运行命令之前,master指向ed489,提交后,master指向新的节点f0cec并以ed489作为父节点
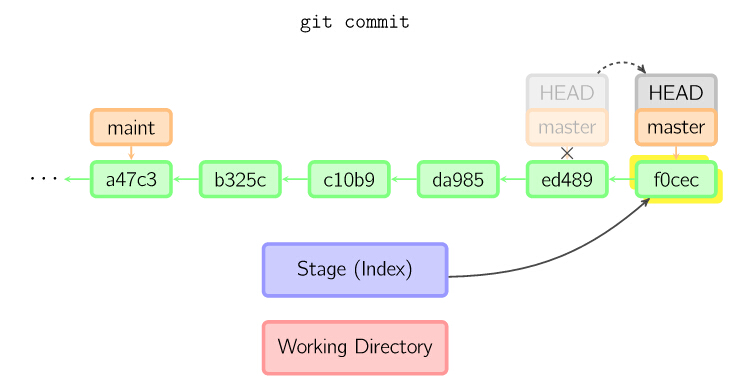
5
下图中,在master分支的祖父节点maint分支进行一次提交,生成了1800b。 这样,maint分支就不再是master分支的祖父节点。此时,合并 (或者 衍合) 是必须的。
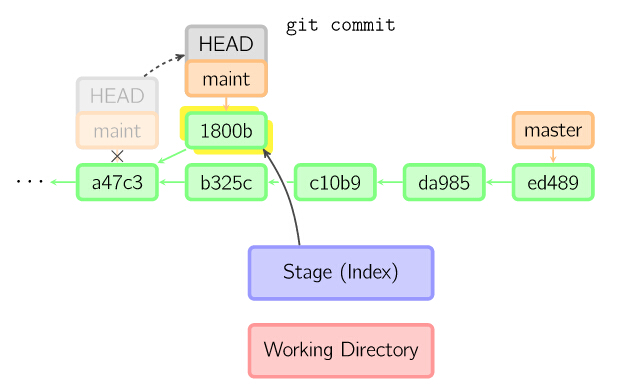
6
如果想更改一次提交,使用 git commit --amend。git会使用与当前提交相同的父节点进行一次新提交,旧的提交会被取消
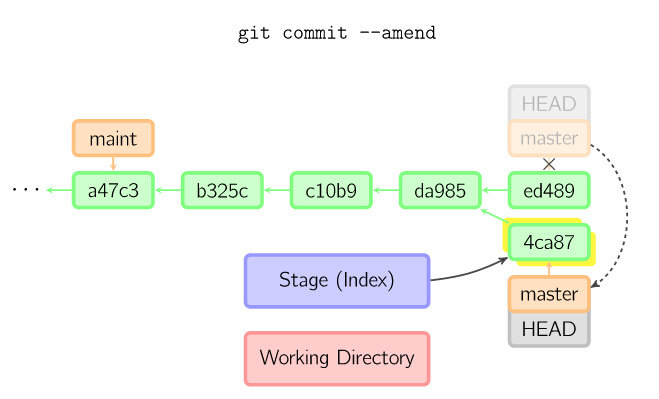
7
checkout
checkout命令用于从历史提交(或者暂存区域)中拷贝文件到工作目录,也可用于切换分支。
当给定某个文件名(或者打开-p选项,或者文件名和-p选项同时打开)时,git会从指定的提交中拷贝文件到暂存区域和工作目录。比如,git checkout HEAD~ foo.c会将提交节点HEAD~(即当前提交节点的父节点)中的foo.c复制到工作目录并且加到暂存区域中。(如果命令中没有指定提交节点,则会从暂存区域中拷贝内容。)
注意当前分支不会发生变化(HEAD指向原处)。
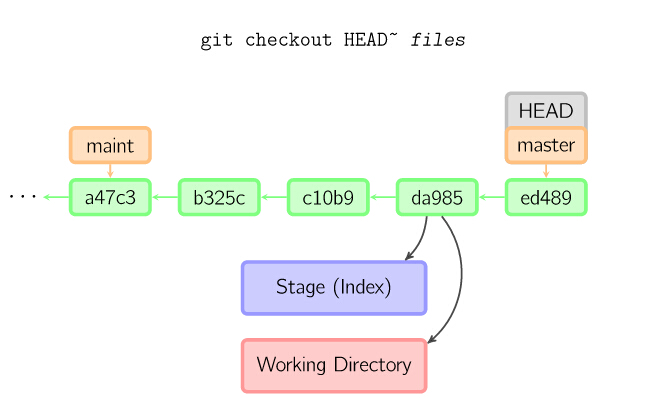
8
当不指定文件名,而是给出一个(本地)分支时,那么HEAD标识会移动到那个分支(也就是说,我们“切换”到那个分支了),然后暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点(下图中的a47c3)中的所有文件都会被复制(到暂存区域和工作目录中);只存在于老的提交节点(ed489)中的文件会被删除;不属于上述两者的文件会被忽略,不受影响。
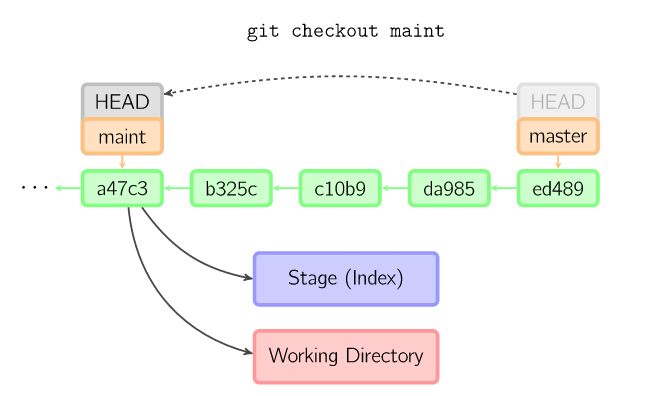
9
如果既没有指定文件名,也没有指定分支名,而是一个标签、远程分支、SHA-1值或者是像master~3类似的东西,就得到一个匿名分支,称作detached HEAD(被分离的HEAD标识)。这样可以很方便地在历史版本之间互相切换。比如说你想要编译1.6.6.1版本的git,你可以运行git checkout v1.6.6.1(这是一个标签,而非分支名),编译,安装,然后切换回另一个分支,比如说git checkout master。然而,当提交操作涉及到“分离的HEAD”时,其行为会略有不同,详情见在下面。
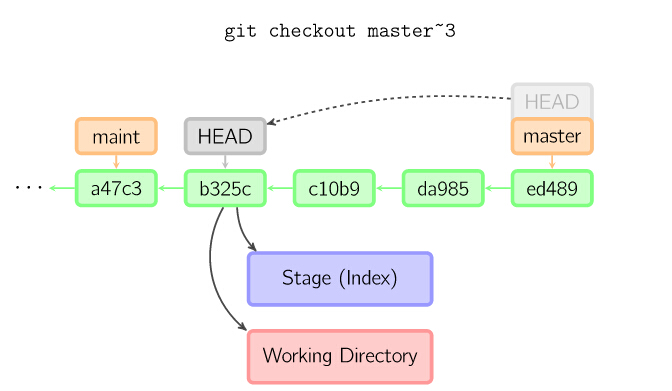
10
HEAD标识处于分离状态时的提交操作
当HEAD处于分离状态(不依附于任一分支)时,提交操作可以正常进行,但是不会更新任何已命名的分支。(你可以认为这是在更新一个匿名分支。)
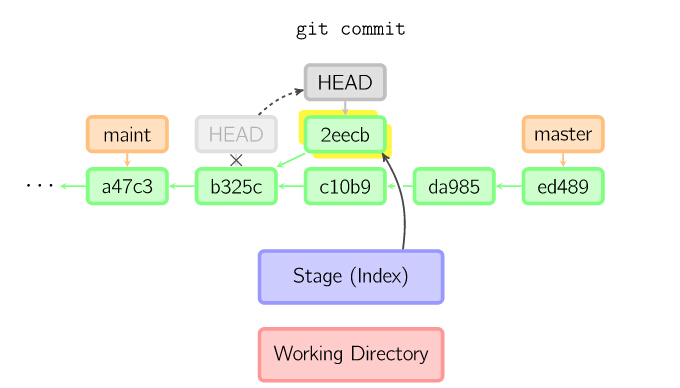
11
一旦此后你切换到别的分支,比如说master,那么这个提交节点(可能)再也不会被引用到,然后就会被丢弃掉了。注意这个命令之后就不会有东西引用2eecb。
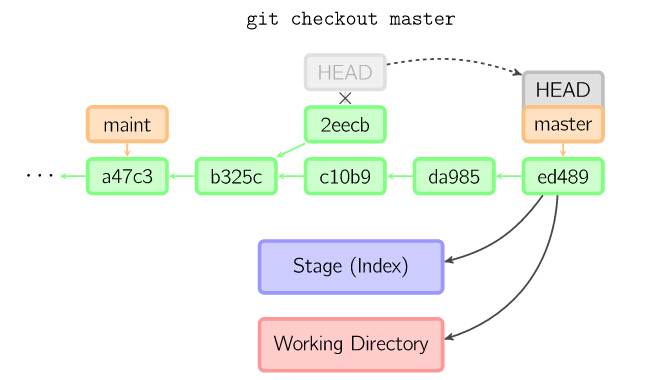
12
但是,如果你想保存这个状态,可以用命令git checkout -b name来创建一个新的分支。

13
- 另外, checkout还有还有如下使用
- 当执行 "git checkout ." 或者 "git checkout -- <file>" 命令时,会用暂存区全部或指定的文件替换工作区的文件。这个操作很危险,会清除工作区中未添加到暂存区的改动。
- 当执行 "git checkout HEAD ." 或者 "git checkout HEAD <file>" 命令时,会用 HEAD 指向的 master 分支中的全部或者部分文件替换暂存区和以及工作区中的文件。这个命令也是极具危险性的,因为不但会清除工作区中未提交的改动,也会清除暂存区中未提交的改 动。
- git checkout -f =等价=> git checkout HEAD . 特别注意,当git checkout -f 不带任何的commit 和文件时,会彻底删除 index 和 working tree未提交内容。
reset
reset命令把当前分支指向另一个位置,并且有选择的变动工作目录和索引。也用来在从历史仓库中复制文件到索引,而不动工作目录。
如果不给选项,那么当前分支指向到那个提交。如果用--hard选项,那么工作目录也更新,如果用--soft选项,那么都不变。
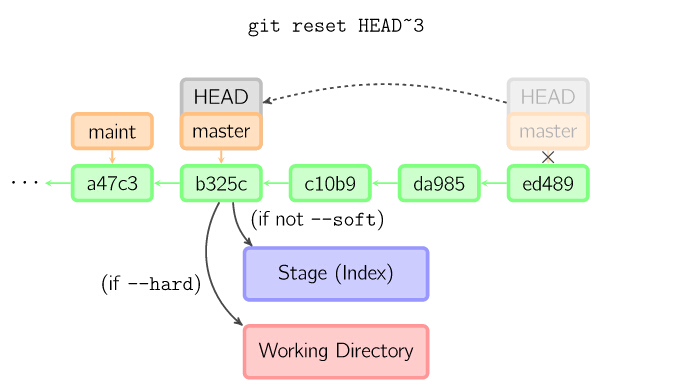
14
如果没有给出提交点的版本号,那么默认用HEAD。这样,分支指向不变,但是索引会回滚到最后一次提交,如果用--hard选项,工作目录也同样。(=== checkout )
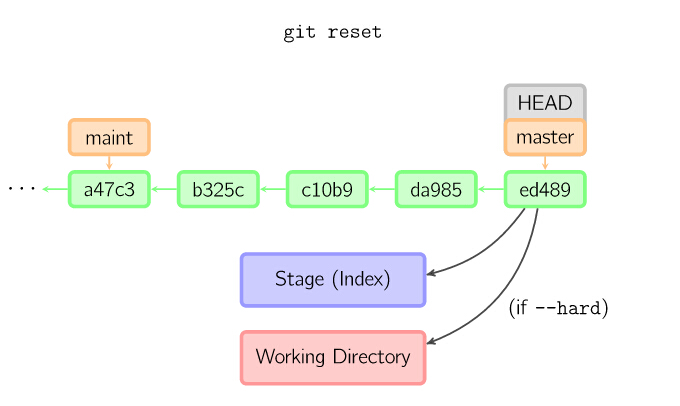
15
如果给了文件名(或者 -p选项), 那么工作效果和带文件名的checkout差不多,除了索引被更新。
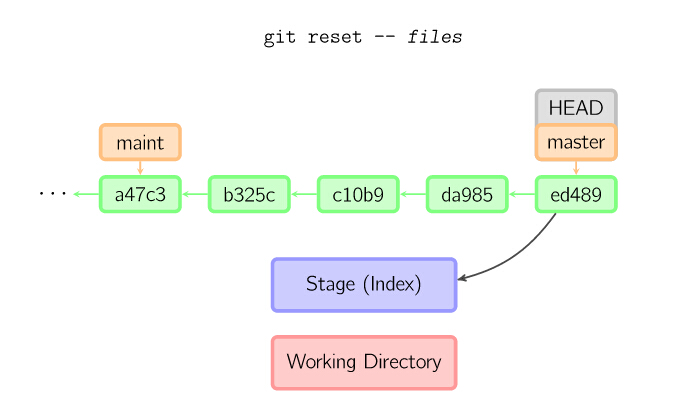
16
merge
merge 命令把不同分支合并起来。合并前,索引必须和当前提交相同。如果另一个分支是当前提交的祖父节点,那么合并命令将什么也不做。 另一种情况是如果当前提交是另一个分支的祖父节点,就导致fast-forward合并。指向只是简单的移动,并生成一个新的提交
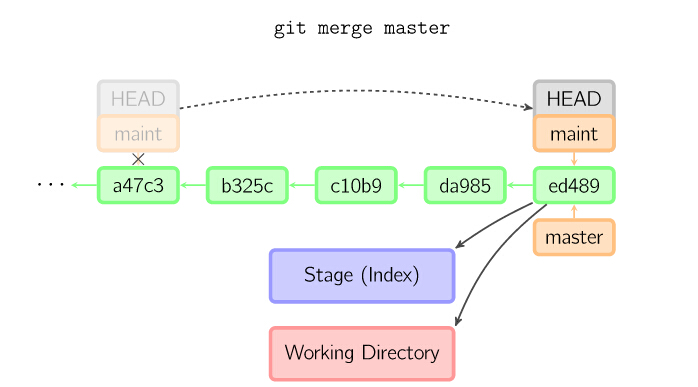
17
否则就是一次真正的合并。默认把当前提交(ed489 如下所示)和另一个提交(33104)以及他们的共同祖父节点(b325c)进行一次三方合并。
结果是先保存当前目录和索引,然后和父节点33104一起做一次新提交。
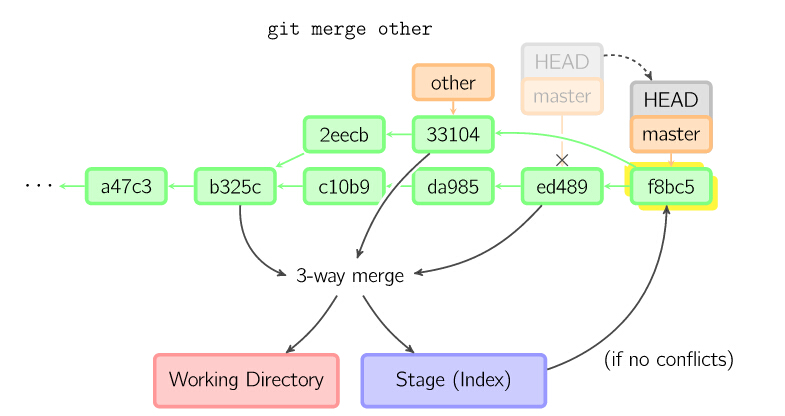
18
cherry Pick
cherry-pick命令"复制"一个提交节点并在当前分支做一次完全一样的新提交。
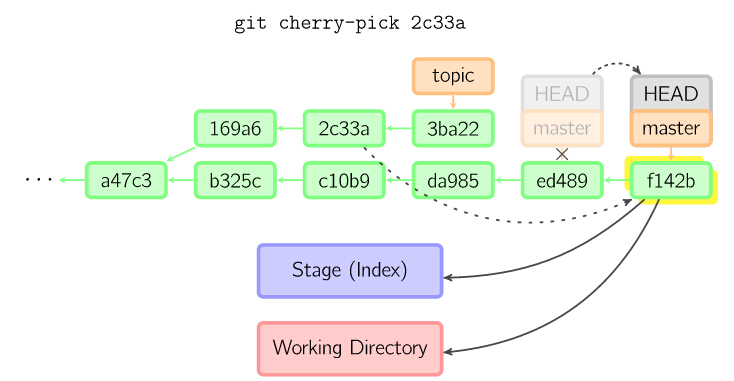
19
rebase
衍合是合并命令的另一种选择。合并把两个父分支合并进行一次提交,提交历史不是线性的。衍合在当前分支上重演另一个分支的历史,提交历史是线性的。
本质上,这是线性化的自动的cherry-pick

20
上面的命令都在topic分支中进行,而不是master分支,在master分支上重演,并且把分支指向新的节点。注意旧提交没有被引用,将被回收。
要限制回滚范围,使用--onto选项。下面的命令在master分支上重演当前分支从169a6以来的最近几个提交,即2c33a。
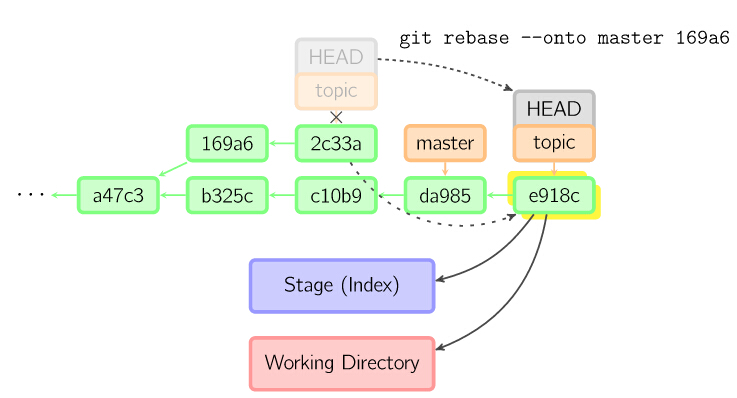
git-fsck --lost-found (file system check) 找回丢失的对象
Verifies the connectivity and validity of the objects in the database
找回丢失的对象: http://gitbook.liuhui998.com/5_9.html
git reflog : 分支等引用变更记录管理
Git reflog 机制 : http://geeklu.com/2013/04/git-reflog/
注意:
master分支默认是公共分支,当有多人协同时,master分支在多个地方都有副本。
如果在master分支上执行git rebase test,会把master分支的提交历史进行修改,可以使用git log仔细观察rebase前后,master分支上的commit hash id。
一旦修改了master的commit hash id,而如果其他人已经基于之前的commit对象做了工作,那么当他拉取master的新的对象时,会需要再合并一次,这样反复下去,会把
rebase的含义是把当前分支的提交对象在目标分支上重做一遍,并生成了新的提交对象。
所以如果在master分支上需要对test分支进行rebase,你需要的命令是
|
1
|
git rebase master your-branch |
这条命令等价于两条命令的合集
|
1
2
|
git checkout your-branchgit rebase master |
永远不要在已经发布到公共仓库的提交对象上做rebase操作,而master分支默认就是公共仓库。
示例分析
假设team中有两个developer:tom和jerry,他们共同使用一个远程repo,并各自clone到自己的机器上,为了简化描述,这里假设只有一个branch:master。
这时tom机器的repo有两个branch master
origin/master
而jerry的机器上也是有两个branch master
origin/master
均如下图所示
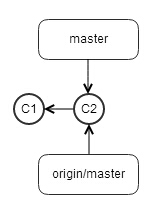
tom和jerry分别各自开发自己的新feature,不断有新的commit提交到他们各自私有的commit history中,所以他们的master指针不断的向前推移,分别指向不同的commit。而又由于他们都没有git fetch和git push,所以他们的origin/master都维持不变。
jerry的repo如下
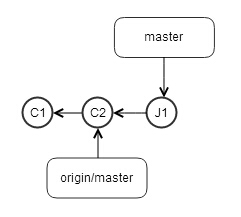
tom的repo如下,注意T1和上图的J1,分别是两个不同的commit
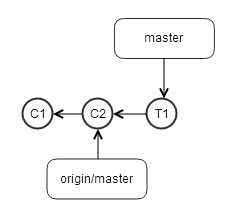
这时Tom首先把他的commit提交的远程repo中,那么他本机origin/master指针则会前进,和master指针保持一致,如下
远程repo如下
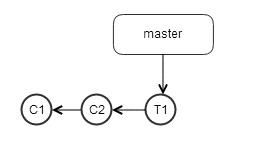
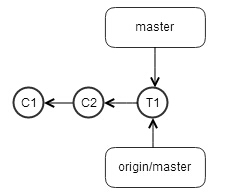
现在jerry也想把他的commit提交到远程repo上去,运行git push,毫无意外的失败了,所以他git fetch了一下,把远程repo,也就是之前tom提交的T1给拉到了他本机repo中,如下
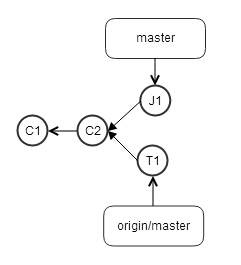
commit history出现了分叉,要想把tom之前提交的内容包含到自己的工作中来,有一个方法就是git merge,它会自动生成一个commit,既包含tom的提交,也包含jerry的提交,这样就把两个分叉的commit重新又合并在一起。但是这个自动生成的commit会有两个parent,review代码的时候必须要比较两次,很不方便。
jerry为了保证commit history的线性,决定采用另外一种方法,就是git rebase。jerry的提交J1这时还没有被提交到远程repo上去,也就是他完全私有的一个commit,所以使用git rebase改写J1的history完全没有问题,改写之后,如下
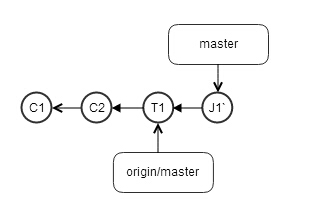
注意J1被改写到T1后面了,变成了J1'
git push后,本机repo
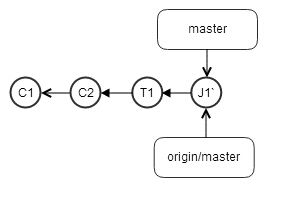
而远程repo

异常的轻松,一条直线,没有-f
所以,想维持树的整洁,方法就是:在git push之前,先git fetch,再git rebase。
git fetch origin master
git rebase origin/master
git push
| HEAD | The current ref that you’re looking at. In most cases it’s probably refs/heads/master |
| FETCH_HEAD | The SHAs of branch/remote heads that were updated during the last git fetch |
| ORIG_HEAD | When doing a merge, this is the SHA of the branch you’re merging into |
| MERGE_HEAD | When doing a merge, this is the SHA of the branch you’re merging from |
| CHERRY_PICK_HEAD | When doing a cherry-pick, this is the SHA of the commit which you are cherry-picking |
参考:
[1] 【推荐】GIT & REPO & GERRIT : http://blog.csdn.net/edhroyal/article/details/9187727
[2] 【推荐】git-rebase : http://blog.yorkxin.org/posts/2011/07/29/git-rebase/
http://marklodato.github.io/visual-git-guide/index-zh-cn.html
转自:http://www.cnblogs.com/angeldevil/p/3238470.html
Git与Repo入门
版本控制是什么已不用在说了,就是记录我们对文件、目录或工程等的修改历史,方便查看更改历史,备份以便恢复以前的版本,多人协作。。。
一、原始版本控制
最原始的版本控制是纯手工的版本控制:修改文件,保存文件副本。有时候偷懒省事,保存副本时命名比较随意,时间长了就不知道哪个是新的,哪个是老的了,即使知道新旧,可能也不知道每个版本是什么内容,相对上一版作了什么修改了,当几个版本过去后,很可能就是下面的样子了:

二、本地版本控制
手工管理比较麻烦且混乱,所以出现了本地版本控制系统,记录文件每次的更新,可以对每个版本做一个快照,或是记录补丁文件。比如RCS。

三、集中版本控制
但是本地版本控制系统偏向于个人使用,或者多个使用的人必须要使用相同的设备,如果需要多人协作就不好办了,于是,集中化的版本控制系统( Centralized Version Control Systems,简称 CVCS )应运而生,比如Subversion,Perforce。
在CVCS中,所有的版本数据都保存在服务器上,一起工作的人从服务器上同步更新或上传自己的修改。

但是,所有的版本数据都存在服务器上,用户的本地设备就只有自己以前所同步的版本,如果不连网的话,用户就看不到历史版本,也无法切换版本验证问题,或在不同分支工作。。
而且,所有数据都保存在单一的服务器上,有很大的风险这个服务器会损坏,这样就会丢失所有的数据,当然可以定期备份。
四、分布式版本控制
针对CVCS的以上缺点,出现了分布式版本控制系统( Distributed Version Control System,简称 DVCS ),如GIT,Mercurial。
DVCS不是复制指定版本的快照,而是把所有的版本信息仓库全部同步到本地,这样就可以在本地查看所有版本历史,可以离线在本地提交,只需在连网时push到相应的服务器或其他用户那里。由于每个用户那里保存的都是所有的版本数据,所以,只要有一个用户的设备没有问题就可以恢复所有的数据。
当然,这增加了本地存储空间的占用。

GIT
必须要了解GIT的原理,才能知道每个操作的意义是什么,才能更容易地理解在什么情况下用什么操作,而不是死记命令。当然,第一步是要获得一个GIT仓库。
一、获得GIT仓库
有两种获得GIT仓库的方法,一是在需要用GIT管理的项目的根目录执行:
git init
执行后可以看到,仅仅在项目目录多出了一个.git目录,关于版本等的所有信息都在这个目录里面。
另一种方式是克隆远程目录,由于是将远程服务器上的仓库完全镜像一份至本地,而不是取某一个特定版本,所以用clone而不是checkout:
git clone <url>
二、GIT中版本的保存
记录版本信息的方式主要有两种:
- 记录文件每个版本的快照
- 记录文件每个版本之间的差异
GIT采用第一种方式。像Subversion和Perforce等版本控制系统都是记录文件每个版本之间的差异,这就需要对比文件两版本之间的具体差异,但是GIT不关心文件两个版本之间的具体差别,而是关心文件的整体是否有改变,若文件被改变,在添加提交时就生成文件新版本的快照,而判断文件整体是否改变的方法就是用SHA-1算法计算文件的校验和。
GIT能正常工作完全信赖于这种SHA-1校验和,当一个文件的某一个版本被记录之后会生成这个版本的一个快照,但是一样要能引用到这个快照,GIT中对快照的引用,对每个版本的记录标识全是通过SHA-1校验和来实现的。
当一个文件被改变时,它的校验和一定会被改变(理论上存在两个文件校验和相同,但机率小到可以忽略不计),GIT就以此判断文件是否被修改,及以些记录不同版本。
在工作目录的文件可以处于不同的状态,比如说新添加了一个文件,GIT发觉了这个文件,但这个文件是否要纳入GIT的版本控制还是要由我们自己决定,比如编译生成的中间文件,我们肯定不想纳入版本控制。下面就来看下文件状态。
三、GIT文件操作
版本控制就是对文件的版本控制,对于Linux来说,设备,目录等全是文件,要对文件进行修改、提交等操作,首先要知道文件当前在什么状态,不然可能会提交了现在还不想提交的文件,或者要提交的文件没提交上。
文件状态
GIT仓库所在的目录称为工作目录,这个很好理解,我们的工程就在这里,工作时也是在这里做修改。
在工作目录中的文件被分为两种状态,一种是已跟踪状态(tracked),另一种是未跟踪状态(untracked)。只有处于已跟踪状态的文件才被纳入GIT的版本控制。如下图:

当我们往工作目录添加一个文件的时候,这个文件默认是未跟踪状态的,我们肯定不希望编译生成的一大堆临时文件默认被跟踪还要我们每次手动将这些文件清除出去。用以下命令可以跟踪文件:
git add <file>
上图中右边3个状态都是已跟踪状态,其中的灰色箭头只表示untracked<-->tracked的转换而不是untracked<-->unmodified的转换,新添加的文件肯定算是被修改过的。那么,staged状态又是什么呢?这就要搞清楚GIT的三个工作区域:本地数据(仓库)目录,工作目录,暂存区,如下图所示:

git directory就是我们的本地仓库.git目录,里面保存了所有的版本信息等内容。
working driectory,工作目录,就是我们的工作目录,其中包括未跟踪文件及已跟踪文件,而已跟踪文件都是从git directory取出来的文件的某一个版本或新跟踪的文件。
staging area,暂存区,不对应一个具体目录,其时只是git directory中的一个特殊文件。
当我们修改了一些文件后,要将其放入暂存区然后才能提交,每次提交时其实都是提交暂存区的文件到git仓库,然后清除暂存区。而checkout某一版本时,这一版本的文件就从git仓库取出来放到了我们的工作目录。
文件状态的查看
那么,我们怎么知道当前工作目录的状态呢?哪些文件已被暂存?有哪些未跟踪的文件?哪些文件被修改了?所有这些只需要一个命令,git status,如下图所示:

GIT在这一点做得很好,在输出每个文件状态的同时还说明了怎么操作,像上图就有怎么暂存、怎么跟踪文件、怎么取消暂存的说明。
文件暂存
在上图中我们可以很清楚地看到,filea未跟踪,fileb已被暂存(changes to be committed),但是怎么还有一个fileb是modified但unstaged呢?这是因为当我们暂存一从此文件时,暂存的是那一文件当时的版本,当暂存后再次修改了这个文件后就会提示这个文件暂存后的修改是未被暂存的。
接下来我们就看怎么暂存文件,其实也很简单,从上图中可以看到GIT已经提示我们了:use "git add <file>..." to update what will be committed,通过
git add <file>...
就可以暂存文件,跟踪文件同样是这一个命令。在这个命令中可以使用glob模式匹配,比如"file[ab]",也可以使用"git add ."添加当前目录下的所有文件。
取消暂存文件是
git reset HEAD <file>...
若修改了一个文件想还原修改可用
git checkout -- <file>...
查看文件修改后的差异
当我们修改过一些文件之后,我们可能想查看我们都修改了什么东西,用"git status"只能查看对哪些文件做了改动,如果要看改动了什么,可以用:
git diff
比如下图:

---a表示修改之前的文件,+++b表示修改后的文件,上图表示在fileb的第一行后添加了一行"bb",原来文件的第一行扩展为了修改后的1、2行。
但是,前面我们明明用"git status"看到filesb做了一些修改后暂存了,然后又修改了fileb,理应有两次修改的,怎么只有一个?
因为"git diff"显示的是文件修改后还没有暂存起来的内容,那如果要比较暂存区的文件与之前已经提交过的文件呢,毕竟实际提交的是暂存区的内容,可以用以下命令:

/dev/null表示之前没有提交过这一个文件,这是将是第一次提交,用:
git diff --staged
是等效的,但GIT的版本要大于1.6.1。
再次执行"git add"将覆盖暂存区的内容。
忽略一些文件
如果有一些部件我们不想纳入版本控制,也不想在每次"git status"时看到这些文件的提示,或者很多时候我们为了方便会使用"git add ."添加所有修改的文件,这时就会添加上一些我们不想添加的文件,怎么忽略这些文件呢?
GIT当然提供了方法,只需在主目录下建立".gitignore"文件,此文件有如下规则:
- 所有以#开头的行会被忽略
- 可以使用glob模式匹配
- 匹配模式后跟反斜杠(/)表示要忽略的是目录
- 如果不要忽略某模式的文件在模式前加"!"
比如:
# 此为注释 – 将被 Git 忽略
*.a # 忽略所有 .a 结尾的文件
!lib.a # 但 lib.a 除外
/TODO # 仅仅忽略项目根目录下的 TODO 文件,不包括 subdir/TODO
build/ # 忽略 build/ 目录下的所有文件
doc/*.txt # 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
移除文件
当我们要删除一个文件时,我们可能就直接用GUI删除或者直接rm [file]了,但是看图:

我们需要将文件添加到暂存区才能提交,而移除文件后是无法添加到暂存区的,那么怎么移除一个文件让GIT不再将其纳入版本控制呢?上图中GIT已经给出了说明:
git rm <file>...
执行以上命令后提交就可以了,有时我们只是想将一些文件从版本控制中剔除出去,但仍保留这些文件在工作目录中,比如我们一不小心将编译生成的中间文件纳入了版本控制,想将其从版本控制中剔除出去但在工作目录中保留这些文件(不然再次编译可要花费更多时间了),这时只需要添加"--cached"参数。
如果我们之前不是通过"git rm"删除了很多文件呢?比如说通过patch或者通过GUI,如果这些文件命名没有规则,一个一个地执行"git rm"会搞死人的,这时可以用以下命令:

移动文件
和移除文件一样,移动文件不可以通过GUI直接重命令或用"mv"命令,而是要用"git mv",不然同移除文件一样你会得到如下结果:

如果要重命名文件可以使用
git mv old_name new_name
这个命令等效于
mv old_name new_name
git rm old_name
git add new_name
交互式暂存
使用git add -i可以开启交互式暂存,如图所示,系统会列出一个功能菜单让选择将要执行的操作。

移除所有未跟踪文件
git clean [options] 一般会加上参数-df,-d表示包含目录,-f表示强制清除。
储藏-Stashing
可能会遇到这样的情况,你正在一个分支上进行一个特性的开发,或者一个Bug的修正,但是这时突然有其他的事情急需处理,这时该怎么办?不可能就在这个工作进行到一半的分支上一起处理,先把修改的Copy出去?太麻烦了。这种情况下就要用到Stashing了。假如我们现在的工作目录是这样子的
$ git status
# On branch master
# Changes to be committed:
#
(use "git reset HEAD <file>..." to unstage)
#
#
modified:
index.html
#
# Changed but not updated:
#
(use "git add <file>..." to update what will be committed)
#
#
modified:
lib/simplegit.rb
此时如果想切换分支就可以执行以下命令
$ git stash
Saved working directory and index state \
"WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file
(To restore them type "git stash apply")
这时你会发现你的工作目录变得很干净了,就可以随意切分支进行其他事情的处理了。
我们可能不只一次进行"git stash",通过以下命令可以查看所有stash列表
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
当紧急事情处理完了,需要重新回来这里进行原来的工作时,只需把Stash区域的内容取出来应用到当前工作目录就行,命令就是
git stash apply
如果不基参数就应用最新的stash,或者可以指定stash的名字,如:stash@{1},可能通过
git stash show
显示stash的内容具体是什么,同git stash apply一样,可以选择指定stash的名字。
git stash apply之后再git stash list会发现,apply后的stash还在stash列表中,如果要将其从stash列表中删除可以用
git stash drop
丢弃这个stash,stash的命令参数都可选择指定stash名字,否则就是最新的stash。
一般情况下apply stash后应该就可以把它从stash列表删除了,先apply再drop还是比较繁琐的,使用以下一条命令就可以同时完成这两个操作
git stash pop
如果我们执行git stash时工作目录的状态是部分文件已经加入了暂存区,部分文件没有,当我们执行git stash apply之后会发现所有文件都变成了未暂存的,如果想维持原来的样子操持原来暂存的文件仍然是暂存状态,可以加上--index参数
git stash apply --index
还有这么一种情况,我们把原来的修改stash了,然后修复了其他一些东西并进行了提交,但是,这些提交的文件有些在之前已经被stash了,那么git stash apply时就很可能会遇到冲突,这种情况下就可以在stash时所以提交的基础上新建一个分支,然后再apply stash,当然,这两个步骤有一人简单的完成方法
git stash branch <branch name>
四、提交与历史
了解了文件的状态,我们对文件进行了必要的修改后,就要把我们所做的修改放入版本库了,这样以后我们就可以在需要的时候恢复到现在的版本,而要恢复到某一版,一般需要查看版本的历史。
提交
提交很简单,直接执行"git commit"。执行git commit后会调用默认的或我们设置的编译器要我们填写提示说明,但是提交说明最好按GIT要求填写:第一行填简单说明,隔一行填写详细说明。因为第一行在一些情况下会被提取使用,比如查看简短提交历史或向别人提交补丁,所以字符数不应太多,40为好。下面看一下查看提交历史。
查看提交历史
查看提交历史使用如下图的命令

如图所示,显示了作者,作者邮箱,提交说明与提交时间,"git log"可以使用放多参数,比如:

仅显示最新的1个log,用"-n"表示。

显示简单的SHA-1值与简单提交说明,oneline仅显示提交说明的第一行,所以第一行说明最好简单点方便在一行显示。
"git log --graph"以图形化的方式显示提交历史的关系,这就可以方便地查看提交历史的分支信息,当然是控制台用字符画出来的图形。
"git log"的更多参数可以查看命令帮助。
不经过暂存的提交
如果我们想跳过暂存区直接提交修改的文件,可以使用"-a"参数,但要慎重,别一不小心提交了不想提交的文件
git commit -a
如果需要快捷地填写提交说明可使用"-m"参数
git commit -m 'commit message'
修订提交
如果我们提交过后发现有个文件改错了,或者只是想修改提交说明,这时可以对相应文件做出修改,将修改过的文件通过"git add"添加到暂存区,然后执行以下命令:
git commit --amend
然后修改提交说明覆盖上次提交,但只能重写最后一次提交。
重排提交
通过衍合(rebase)可以修改多个提交的说明,并可以重排提交历史,拆分、合并提交,关于rebase在讲到分支时再说,这里先看一下重排提交。
假设我们的提交历史是这样的:

如果我们想重排最后两个提交的提交历史,可以借助交互式rebase命令:
git rebase -i HEAD~2 或 git rebase -i 3366e1123010e7d67620ff86040a061ae76de0c8
HEAD~2表示倒数第三个提交,这条命令要指定要重排的最旧的提交的父提交,此处要重排Second commit与Third commit,所以要指定Initial commit的Commit ID。如图所示:

注释部分详细说明了每个选项的作用,如果我们想交互这两个提交,只需把开头的这两行交换下位置就OK了,交换位置后保存,然后看下提交历史:

可以看到提交历史已经变了,而且最新的两个提交的Commit ID变了,如果这些提交已经push到了远程服务器,就不要用这个命令了。
删除提交与修改提交说明
如果要删除某个提交,只需要删除相应的行就可以了,而要修改某个提交的提交说明的话,只需要把相应行的pick改为reward。
合并提交-squashing
合并提交也很简单,从注释中的说明看,只需要把相应的行的pick改为squash就可以把这个提交全并到它上一行的提交中。
拆分提交
至于拆分提交,由于Git不可能知道你要做哪里把某一提交拆分开,把以我们就需要让Git在需要拆分的提交处停下来,由我们手动修改提交,这时要把pick改为edit,这样Git在处理到这个提交时会停下来,此时我们就可以进行相应的修改并多次提交来拆分提交。
撤销提交
前面说了删除提交的方法,但是如果是多人合作的话,如果某个提交已经Push到远程仓库,是不可以用那种方法删除提交的,这时就要撤销提交
git revert <commit-id>
这条命令会把指定的提交的所有修改回滚,并同时生成一个新的提交。
Reset
git reset会修改HEAD到指定的状态,用法为
git reset [options] <commit>
这条命令会使HEAD提向指定的Commit,一般会用到3个参数,这3个参数会影响到工作区与暂存区中的修改:
- --soft: 只改变HEAD的State,不更改工作区与暂存区的内容
- --mixed(默认): 撤销暂存区的修改,暂存区的修改会转移到工作区
- --hard: 撤销工作区与暂存区的修改
cherry-pick
当与别人和作开发时,会向别人贡献代码或者接收别人贡献的代码,有时候可能不想完全Merge别人贡献的代码,只想要其中的某一个提交,这时就可以使用cherry-pick了。就一个命令
git cherry-pick <commit-id>
filter-branch
这条命令可以修改整个历史,如从所有历史中删除某个文件相关的信息,全局性地更换电子邮件地址。
五、GIT分支
分支被称之为GIT最强大的特性,因为它非常地轻量级,如果用Perforce等工具应该知道,创建分支就是克隆原目录的一个完整副本,对于大型工程来说,太费时费力了,而对于GIT来说,可以在瞬间生成一个新的分支,无论工程的规模有多大,因为GIT的分支其实就是一指针而已。在了解GIT分支之前,应该先了解GIT是如何存储数据的。
前面说过,GIT存储的不是文件各个版本的差异,而是文件的每一个版本存储一个快照对象,然后通过SHA-1索引,不只是文件,包换每个提交都是一个对象并通过SHA-1索引。无论是文本文件,二进制文件还是提交,都是GIT对象。
GIT对象
每个对象(object) 包括三个部分:类型,大小和内容。大小就是指内容的大小,内容取决于对象的类型,有四种类型的对象:"blob"、"tree"、 "commit" 和"tag"。
- “blob”用来存储文件数据,通常是一个文件。
- “tree”有点像一个目录,它管理一些“tree”或是 “blob”(就像文件和子目录)
- 一个“commit”指向一个"tree",它用来标记项目某一个特定时间点的状态。它包括一些关于时间点的元数据,如提交时间、提交说明、作者、提交者、指向上次提交(commits)的指针等等。
- 一个“tag”是来标记某一个提交(commit) 的方法。
比如说我们执行了以下代码进行了一次提交:
$ git add README test.rb LICENSE2
$ git commit -m 'initial commit of my project'
现在,Git 仓库中有五个对象:三个表示文件快照内容的 blob 对象;一个记录着目录树内容及其中各个文件对应 blob 对象索引的 tree 对象;以及一个包含指向 tree 对象(根目录)的索引和其他提交信息元数据的 commit 对象。概念上来说,仓库中的各个对象保存的数据和相互关系看起来如下图:

如果进行多次提交,仓库的历史会像这样:

分支引用
所谓的GIT分支,其实就是一个指向某一个Commit对象的指针,像下面这样,有两个分支,master与testing:
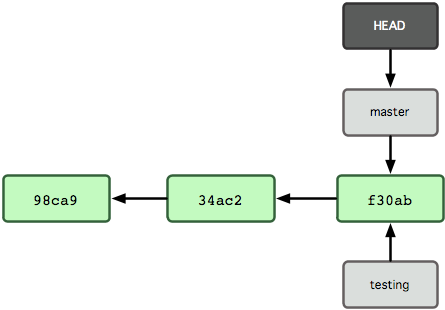
而我们怎么知道当前在哪一个分支呢?其实就是很简单地使用了一个名叫HEAD的指针,如上图所示。HEAD指针的值可以为一个SHA-1值或是一个引用,看以下例子:

git的所有版本信息都保存了Working Directory下的.git目录,而HEAD指针就保存在.git目录下,如上图所有,目前为止已经有3个提交,通过查看HEAD的值可以看到我们当前在master分支:refs/heads/master,当我们通过git checkout取出某一特定提交后,HEAD的值就是成了我们checkout的提交的SHA-1值。
记录我们当前的位置很简单,就是能过HEAD指针,HEAD指向某一提交的SHA-1值或是某一分支的引用。
新建分支
git branch <branch-name>
有时需要在新建分支后直接切换到新建的分支,可以直接用checkout的-b选项
git checkout -b <branch-name>
删除分支
git branch -d <branch-name>
如果在指定的分支有一些unmerged的提交,删除分支会失败,这里可以使用-D参数强制删除分支。
git branch -D <branch-name>
检出分支或提交
检出某一分支或某一提交是同一个命令
git checkout <branch-name> | <commit>
分支合并(merge)
当我们新建一个分支进行开发,并提交了几次更新后,感觉是时候将这个分支的内容合回主线了,这是就可以取出主线分支,然后把分支的更新merge回来:
git checkout master
git merge testing
如果master分支是testing分支的直接上游,即从master延着testing分支的提交历史往前走可以直接走到testing分支的最新提交,那么系统什么也不需要做,只需要改变master分支的指针即可,这被称之为"Fast Forward"。
但是,一般情况是这样的,你取出了最新的master分支,比如说master分支最新的提交是C2(假设共3次提交C0<-C1<-C2),在此基础上你新建了分支,当你在分支上提交了C3、C5后想将br1时merge回master时,你发现已经有其他人提交了C4,这时候就不能直接修改master的指针了,不然会丢失别人的提交,这个时候就需要将你新建分支时master所在的提交(C2)后的修改(C4),与你新建分支后在分支上的修改(C3、C5)做合并,将合并后的结果作为一个新的提交提交到master,GIT可以自动推导出应该基于哪个提交进行合并(C2),如果没有冲突,系统会自动提交新的提交,如果有冲突,系统会提示你解决冲突,当冲突解决后,你就可以将修改加入暂存区并提交。提交历史类似下面这样(图来自Pro-Git):

merge后的提交是按时间排序的,比如下图,我们在rename提交处新建分支test,在test上提交Commit from branch test,然后回到master提交commit in master after committing in branch,再将test分支merge进master,这时看提交提交历史,Commit from branch test是在commit in master...之前的,尽管在master上我们是在rename的基础上提交的commit in master...而GIT会在最后添加一个新的提交(Merge branch 'test')表示我们在此处将一个分支merge进来了。这种情况会有一个问题,比如说在rename提交处某人A从你这里Copy了一个GIT仓库,然后你release了一个patch(通过git format-patch)给A,这时候test分支还没有merge进来,所以patch中只包含提交:commit in master...然后你把test分支merge了进来又给了A一个patch,这个patch会包含提交:Commit from branch test,而这个patch是以rename为base的,如果commit in master...和Commit from branch test修改了相同的文件,则第二次的patch可能会打不上去,因为以rename为base的patch可能在新的Code上找不到在哪个位置应用修改。

分支衍合(rebase)
有两种方法将一个分支的改动合并进另一个分支,一个就是前面所说的分支合并,另一个就是分支衍合,这两种方式有什么区别呢?
分支合并(merge)是将两个分支的改动合并到一起,并生成一个新的提交,提交历史是按时间排序的,即我们实际提交的顺序,通过git log --graph或一些图形化工具,可能很明显地看到分支的合并历史,如果分支比较多就很混乱,而且如果以功能点新建分支,等功能点完成后合回主线,由于merge后提交是按提交时间排序的,提交历史就比较乱,各个功能点的提交混杂在一起,还可能遇到上面提到的patch问题。
而分支衍合(rebase)是找到两个分支的共同祖先提交,将要被rebase进来的分支的提交依次在要被rebase到的分支上重演一遍,即回到两个分支的共同祖先,将branch(假如叫experiment)的每次提交的差异保存到临时文件里,然后切换到要衍合入的分支(假如是master),依次应用补丁文件。experiment上有几次提交,在master就生成几次新的提交,而且是连在一起的,这样合进主线后每个功能点的提交就都在一起,而且提交历史是线性的
对比merge与rebase的提交历史会是下图这样的(图来自Pro-GIt):
 (merge)
(merge)
 (rebase)
(rebase)
rebase后C3提交就不存在了,取而代之的是C3',而master也成为了experiment的直接上游,只需一次Fast Forward(git merge)后master就指向了最新的提交,就可以删除experiment分支了。
衍合--onto
git rebase --onto master server client
这条命令的意思是:检出server分支与client分支共同祖先之后client上的变化,然后在master上重演一遍。
父提交
HEAD表示当前所在的提交,如果要查看当前提交父提交呢?git log查看提交历史,显然太麻烦了,而且输入一长串的Commit-ID也不是一个令人愉悦的事。这时可借助两个特殊的符号:~与^。
^ 表示指定提交的父提交,这个提交可能由多个交提交,^之后跟上数字表示第几个父提交,不跟数字等同于^1。
~n相当于n个^,比如~3=^^^,表示第一个父提交的第一个父提交的第一个父提交。
远程分支
远程分支以(远程仓库名)/(分支名)命令,远程分支在本地无法移动修改,当我们clone一个远程仓库时会自动在本地生成一个名叫original的远程仓库,下载远程仓库的所有数据,并新建一个指向它的分支original/master,但这个分支我们是无法修改的,所以需要在本地重新一个分支,比如叫master,并跟踪远程分支。
Clone了远程仓库后,我们还会在本地新建其他分支,并且可能也想跟踪远程分支,这时可以用以下命令:
git checkout -b [branch_name] --track|-t <remote>/<remote-banch>
和新建分支的方法一样,只是加了一个参数--track或其缩写形式-t,可以指定本地分支的名字,如果不指定就会被命名为remote-branch。
要拉取某个远程仓库的数据,可以用git fetch:
git fetch <remote>
当拉取到了远程仓库的数据后只是把数据保存到了一个远程分支中,如original/master,而这个分支的数据是无法修改的,此时我们可以把这个远程分支的数据合并到我们当前分支
git merge <remote>/<remote-branch>
如果当前分支已经跟踪了远程分支,那么上述两个部分就可以合并为一个
git pull
当在本地修改提交后,我们可能需要把这些本地的提交推送到远程仓库,这里就可以用git push命令,由于本地可以由多个远程仓库,所以需要指定远程仓库的名字,并同时指定需要推的本地分支及需要推送到远程仓库的哪一个分支
git push <remote> <local-branch>:<remote-branch>
如果本地分支与远程分支同名,命令可以更简单
git push <remote> <branch-name> 等价于 git push <remote> refs/heads/<branch-name>:refs/for/<branch-name>
如果本地分支的名字为空,可以删除远程分支。
前面说过可以有不止一个远程分支f,添加远程分支的方法为
git remote add <short-name> <url>
六、标签-tag
作为一个版本控制工具,针对某一时间点的某一版本打tag的功能是必不可少的,要查看tag也非常简单,查看tag使用如下命令
git tag
参数"-l"可以对tag进行过滤
git tag -l "v1.1.*"
Git 使用的标签有两种类型:轻量级的(lightweight)和含附注的(annotated)。轻量级标签就像是个不会变化的分支,实际上它就是个指向特定提交对象的引用。而含附注标签,实际上是存储在仓库中的一个独立对象,它有自身的校验和信息,包含着标签的名字,电子邮件地址和日期,以及标签说明,标签本身也允许使用 GNU Privacy Guard (GPG) 来签署或验证。
轻量级标签只需在git tag后加上tag的名字,如果tag名字
git tag <tag_name>
含附注的标签需要加上参数-a(annotated),同时加上-m跟上标签的说明
git tag -a <tag_name> -m "<tag_description>"
如果你有自己的私钥,还可以用 GPG 来签署标签,只需要把之前的 -a 改为 -s(signed)
查看标签的内容用
git show <tag_name>
验证已签署的标签用-v(verify)
git tag -v <tag_name>
有时在某一个版本忘记打tag了,可以在后期再补上,只需在打tag时加上commit-id
要将tag推送到远程服务器上,可以用
git push <remote> <tag_name>
或者可以用下面的命令推送所有的tag
git push <remote> --tags
七、Git配置
使用"git config"可以配置Git的环境变量,这些变量可以存放在以下三个不同的地方:
/etc/gitconfig文件:系统中对所有用户都普遍适用的配置。若使用git config时用--system选项,读写的就是这个文件。~/.gitconfig文件:用户目录下的配置文件只适用于该用户。若使用git config时用--global选项,读写的就是这个文件。- 当前项目的 git 目录中的配置文件(也就是工作目录中的
.git/config文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以.git/config里的配置会覆盖/etc/gitconfig中的同名变量。
在 Windows 系统上,Git 会找寻用户主目录下的 .gitconfig 文件。主目录即 $HOME 变量指定的目录,一般都是 C:\Documents and Settings\$USER。此外,Git 还会尝试找寻 /etc/gitconfig 文件,只不过看当初 Git 装在什么目录,就以此作为根目录来定位。
最基础的配置是配置git的用户,用来标识作者的身份
git config --global user.name <name>
git config --global user.email <email>
文本编辑器也可以配置,比如在git commit的时候就会调用我们设置的文本编辑器
git config --global core.editor vim
另一个常用的是diff工具,比如我们想用可视化的对比工具
git config --global merge.tool meld
要查看所有的配置,可以用
git config --list
或者可以在git config后加上配置项的名字查看具体项的配置
git config user.name
作为一个懒人,虽然checkout、status等命令只是一个单词,但是还是嫌太长了,我们还可以给命令设置别名如
git config --global alias.co checkout
这样git co就等于git checkout
前面说地,git配置项都保存在那3个文件里,可以直接打开相应的配置文件查看配置,也可以直接修改这些配置文件来配置git,想删除某一个配置,直接删除相应的行就行了

八、其他
关于GIT各命令的说明可以查看相关帮助文档,通过以下方法:
git help <command>或git <command> --help
REPO
repo start <topic_name>
开启一个新的主题,其实就是每个Project都新建一个分支。
repo init -u <url> [OPTIONS]
在当前目录下初始化repo,会在当前目录生生成一个.repo目录,像Git Project下的.git一样,-u指定url,可以加参数-m指定manifest文件,默认是default.xml,.repo/manifests保存manifest文件。.repo/projects下有所有的project的数据信息,repo是一系列git project的集合,每个git project下的.git目录中的refs等目录都是链接到.repo/manifests下的。
repo manifest
可以根据当前各Project的版本信息生成一个manifest文件
repo sync [PROJECT1...PROJECTN]
同步Code。
repo status
查看本地所有Project的修改,在每个修改的文件前有两个字符,第一个字符表示暂存区的状态。
| - | no change | same in HEAD and index |
| A | added | not in HEAD, in index |
| M | modified | in HEAD, modified in index |
| D | deleted | in HEAD, not in index |
| R | renamed | not in HEAD, path changed in index |
| C | copied | not in HEAD, copied from another in index |
| T | mode changed | same content in HEAD and index, mode changed |
| U | unmerged | conflict between HEAD and index; resolution required |
每二个字符表示工作区的状态
| letter | meaning | description |
|---|---|---|
| - | new/unknown | not in index, in work tree |
| m | modified | in index, in work tree, modified |
| d | deleted | in index, not in work tree |
repo prune <topic>
删除已经merge的分支
repo abandon <topic>
删除分支,无论是否merged
repo branch或repo branches
查看所有分支
repo diff
查看修改
repo upload
上传本地提交至服务器
repo forall [PROJECT_LIST]-c COMMAND
对指定的Project列表或所有Project执行命令COMMAND,加上-p参数可打印出Project的路径。
repo forall -c 'git reset --hard HEAD;git clean -df;git rebase --abort'
这个命令可以撤销整个工程的本地修改。
说明:文中关于Git的知识大多来自Pro-GIt,这本书感觉不错,想学习的可以找来看:Pro-Git
二、Git 分支图解
转自:http://kb.cnblogs.com/page/132209/
英文原文:http://www.nvie.com/posts/a-successful-git-branching-model/
原文作者:Vincent Driessen
本文经Linux大棚博主总结精简而成。
1
GIT,在技术层面上,绝对是一个无中心的分布式版本控制系统,但在管理层面上,我建议你保持一个中心版本库。

2
我建议,一个中心版本库(我们叫它origin)至少包括两个分支,即“主分支(master)”和“开发分支(develop)”

3
要确保:团队成员从主分支(master)获得的都是处于可发布状态的代码,而从开发分支(develop)应该总能够获得最新开发进展的代码。
4
在一个团队开发协作中,我建议,要有“辅助分支”的概念。
5
“辅助分支”,大体包括如下几类:“管理功能开发”的分支、“帮助构建可发布代码”的分支、“可以便捷的修复发布版本关键BUG”的分支,等等。
6
“辅助分支”的最大特点就是“生命周期十分有限”,完成使命后即可被清除。
7
我建议至少还应设置三类“辅助分支”,我们称之为“Feature branches”,“Release branches”,“Hotfix branches”。
至此,我们形成了如下这张最重要的组织组,包含了两个粗体字分支(master/develop)和三个细体字分支(feature/release/hotfixes)。

8
“Feature branches”,起源于develop分支,最终也会归于develop分支。
9
“Feature branches”常用于开发一个独立的新功能,且其最终的结局必然只有两个,其一是合并入“develop”分支,其二是被抛弃。最典型的“Fearture branches”一定是存在于团队开发者那里,而不应该是“中心版本库”中。
10
“Feature branches”起源于“develop”分支,实现方法是:
git checkout -b myfeature develop
11
“Feature branches”最终也归于“develop”分支,实现方式是:
git checkout devleopgit merge --no-ff myfeature(--no-ff,即not fast forward,其作用是:要求git merge即使在fast forward条件下也要产生一个新的merge commit)(此处,要求采用--no-ff的方式进行分支合并,其目的在于,希望保持原有“Feature branches”整个提交链的完整性)git branch -d myfeaturegit push origin develop

12
“Release branch”,起源于develop分支,最终归于“develop”或“master”分支。这类分支建议命名为“release-*”
13
“Relase branch”通常负责“短期的发布前准备工作”、“小bug的修复工作”、“版本号等元信息的准备工作”。与此同时,“develop”分支又可以承接下一个新功能的开发工作了。
14
“Release branch”产生新提交的最好时机是“develop”分支已经基本到达预期的状态,至少希望新功能已经完全从“Feature branches”合并到“develop”分支了。
15
创建“Release branches”,方法是:
git checkout -b release-1.2 develop./bump-version.sh 1.2 (这个脚本用于将代码所有涉及版本信息的地方都统一修改到1.2,另外,需要用户根据自己的项目去编写适合的bump-version.sh)git commit -a -m "Bumped version number to 1.2"
16
在一段短时间内,在“Release branches”上,我们可以继续修复bug。在此阶段,严禁新功能的并入,新功能应该是被合并到“develop”分支的。
17
经过若干bug修复后,“Release branches”上的代码已经达到可发布状态,此时,需要完成三个动作:第一是将“Release branches”合并到“master”分支,第二是一定要为master上的这个新提交打TAG(记录里程碑),第三是要将“Release branches”合并回“develop”分支。
git checkout mastergit merge --no-ff release-1.2git tag -a 1.2 (使用-u/-s/-a参数会创建tag对象,而非软tag)git checkout developgit merge --no-ff release-1.2git branch -d release-1.2
18
“Hotfix branches”源于“master”,归于“develop”或“master”,通常命名为“hotfix-*”
19
“Hotfix branches”类似于“Release branch”,但产生此分支总是非预期的关键BUG。
20
建议设立“Hotfix branches”的原因是:希望避免“develop分支”新功能的开发必须为BUG修复让路的情况。

21
建立“Hotfix branches”,方法是:
git checkout -b hotfix-1.2.1 master./bump-version.sh 1.2.1git commit -a -m "Bumpt version to 1.2.1" (然后可以开始问题修复工作)git commit -m "Fixed severe production problem" (在问题修复后,进行第二次提交)
22
BUG修复后,需要将“Hotfix branches”合并回“master”分支,同时也需要合并回“develop”分支,方法是:
git checkout mastergit merge --no-ff hotfix-1.2.1git tag -a 1.2.1git checkout developgit merge --no-ff hotfix-1.2.1git branch -d hotfix-1.2.1
23
还记得文章开始时的那张大图么,我建议你把这幅大图从这里下载下来,打印出来,贴在你写字台的墙壁上,好处不言而喻。
三、Git 全面教程
(廖雪峰的官方网站):http://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000
博客园:http://www.cnblogs.com/BeginMan/category/551237.html
csdn博客:http://blog.csdn.net/JackJia2015 http://blog.csdn.net/JackJia2015/article/details/51178868
csdn博客:http://blog.csdn.net/wh_19910525/article/category/1113974
四、Git 常用命令
转自:http://www.cnblogs.com/1-2-3/archive/2010/07/18/git-commands.html
Git 是一个很强大的分布式版本控制系统。它不但适用于管理大型开源软件的源代码,管理私人的文档和源代码也有很多优势。
本来想着只把最有用、最常用的 Git 命令记下来,但是总觉得这个也挺有用、那个也用得着,结果越记越多。
###Git 基础图解、分支图解、全面教程、常用命令###的更多相关文章
- GItHub Git 基础教程 常用命令 命令
最近复习了一下Git的使用,简单总结了一些.以供以后查阅和大家参考. 一,安装 首先是Linux下: 打开shell ,输入 sudo apt-get install git-core 之后回车输入密 ...
- Git基本概念,流程,分支,标签及常用命令
Git基本概念,流程,分支,标签及常用命令 Git一张图 Git基本概念 仓库(Repository) 分支(Branch) Git工作流程 Git分支管理(branch) 列出分支 删除分支 分支合 ...
- linux基础学习之软件安装以及常用命令
linux基础学习之软件安装以及常用命令 调用中央仓库: yum install wget 然后下载nodejs: wget https://nodejs.org/dist/v10.14.2/node ...
- git基础及分支
关于版本控制 git是一种分布版本控制系统,每一主机都保存了完整副本.必杀技是分支. 在Windows可安装git客户端msysgit. git基础 第一次看progit觉得有点不懂,不懂版本控制,一 ...
- git中通过实际操作来了解常用命令
基本的6个命令 常用的就下面6个命令,但是详细的可能有上百个命令. 还需要特别了解git的几个名词,workspace:工作区,Index/Stage:暂存区,Respository:本地仓库,Rem ...
- Docker基础修炼2--Docker镜像原理及常用命令
通过前文的讲解对Docker有了基本认识之后,我们开始进入实战操作,本文先演示Docker三要素之镜像原理和相关命令. 本文的演示环境仍然沿用上一篇文章在本地Centos7中安装的环境,如果你本地没有 ...
- Git flow的分支模型与及经常使用命令简单介绍
Git flow是git的一个扩展集,它基于Vincent Driessen 的分支模型,文章"A successful Git branching model"对这一分支模型进行 ...
- Oracle教程-常用命令(二)
oracle sql*plus常用命令 一.sys用户和system用户Oracle安装会自动的生成sys用户和system用户(1).sys用户是超级用户,具有最高权限,具有sysdba角色,有cr ...
- Linux基础学习(4)--Linux常用命令
第四章——Linux常用命令 一.文件处理命令 1.命令格式与目录处理命令ls: (1)命令格式:命令 [-选项] [参数] 例:ls -la /etc (2)说明:个别命令使用不遵循此格式;当有 ...
- git 教程 ,常用命令
Git使用手册 http://www.cnblogs.com/lantingji/p/5942721.html git官网 https://git-scm.com/ Git的奇技淫巧 http://w ...
随机推荐
- 数据结构之单链表,c#实现
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- QQ聊天界面的布局和设计(IOS篇)-第一季
我写的源文件整个工程会再第二季中发上来~,存在百度网盘, 感兴趣的童鞋, 可以关注我的博客更新,到时自己去下载~.喵~~~ QQChat Layout - 第一季 一.准备工作 1.将假数据messa ...
- UVa1587.Digit Counting
题目连接:http://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=247&p ...
- <转载>Wait and Waitpid
转载http://www.cnblogs.com/lihaosky/articles/1673341.html 一.Wait #include <sys/types.h> /* 提供类型p ...
- hdu 5288 OO’s Sequence(计数)
Problem Description OO has got a array A of size n ,defined a function f(l,r) represent the number o ...
- Direct3D 纹理映射
纹理映射是将2D的图片映射到一个3D物体上面,物体上漂亮图案被称为纹理贴图, 一个表面可以支持多张贴图等等,下面简单介绍下纹理贴图 纹理贴图UV: 贴图是一个个像素点组成,每一个像素点都由一个坐标最后 ...
- 《招聘一个靠谱的iOS》面试题参考答案(下)
相关文章: <招聘一个靠谱的iOS>面试题参考答案(上) 说明:面试题来源是微博@我就叫Sunny怎么了的这篇博文:<招聘一个靠谱的 iOS>,其中共55题,除第一题为纠错题外 ...
- Scala-Partial Functions(偏函数)
如果你想定义一个函数,而让它只接受和处理其参数定义域范围内的子集,对于这个参数范围外的参数则抛出异常,这样的函数就是偏函数(顾名思异就是这个函数只处理传入来的部分参数). 偏函数是个特质其的类型为Pa ...
- HashMap的使用方法及注意事项
99.Map(映射):Map 的keySet()方法会返回 key 的集合,因为 Map 的键是不能重复的,因此 keySet()方法的返回类型是 Set:而 Map 的值是可以重复的,因此 valu ...
- A10 平板开发二搭建Android开发环境
我是直接在Ubuntu 12.10 64位系统下操作的,搭建Ubuntu开发环境类似,见Ubuntu 10.04开发环境配置.需要注意的是,64位的系统,需要安装支持32位的库(sudo apt-ge ...