索引深入浅出(4/10):非聚集索引的B树结构在聚集表
一个表只能有一个聚集索引,数据行以此聚集索引的顺序进行存储,一个表却能有多个非聚集索引。我们已经讨论了聚集索引的结构,这篇我们会看下非聚集索引结构。
非聚集索引的逻辑呈现
简单来说,非聚集索引是表的子集。当我们定义了一个非聚集索引时,SQL Server把整套非聚集索引键存在不同的页里。我们来看下一个包含BusinessEntityID(PK),PersonType,FirstName,LastName这4列的表,这个表上有一个非聚集索引定义。主体表按BusinessEntityID列(聚集索引键)的顺序存储。非聚集索引的存储是与主体表分离的。如果你仔细看非聚集索引表,你会发现,记录是按Firstname,lastname 列的顺序排列的。简单理解下,非聚集索引就是主体表的子集。
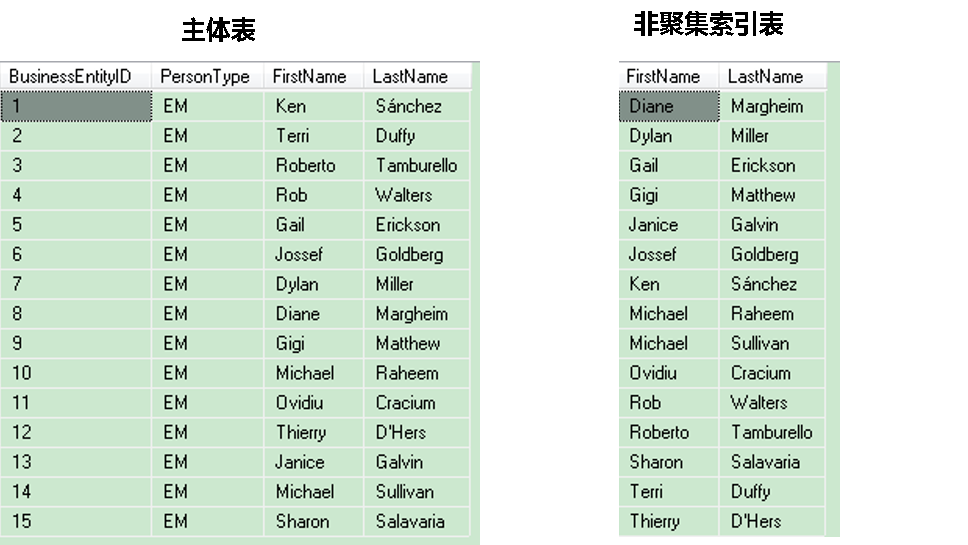
假设现在我们要找出first name值为Michael的记录。如果你从实体表找的话,我们需要从头到脚把每条记录匹配一次,因为记录并没有按first name列排序保存。如果这个表记录有上千条记录的话,这将是一个非常无聊且费时的工作。如果我们在非聚集索引表里找将会容易很多,因为这个表是按first name列以字母顺序排列的。我们很容易定位到first name是Michael的记录。我们并不需要再往下找,因为我们确定没有更多的first name是Michael的记录了。
现在我们得到了Firstname,lastname的值。那我们如何拿到其它2列的值?让我们对非聚集索引做一些改动,将BusinessEntityID列也作为非聚集索引。

现在,一旦我们定位到记录,我们可以使用BusinessEntityID(聚集索引键)列返回主体表,得到其他列的值,这个操作被称为书签查找(bookmark lookups)或RID查找。
聚集索引与非聚集索引
非聚集索引和聚集索引有一样的B树结构。非聚集索引键不会对主体表的数据排序做任何改变,因为聚集索引强制SQL Server将数据以聚集索引键的顺序存储。聚集索引的叶子层由包含表具体数据的数据页组成,而非聚集索引的叶子层由索引页组成。
非聚集索引可以定义在堆表或聚集表。在非聚集索引的叶子层,每个索引行包含非聚集索引键值和行定位器。这个定位器指向聚集索引或堆表的数据行。在非聚集索引行里的行定位器要么指向行,要么指向行聚集索引键。如果是堆表,它没有聚集索引,行定位器是个指向行的指针。这个指针由页里行的(文件号:页号:槽号,file identifier :page number :slot number)组成。整个指针被称为ROW ID(RID)。如果表有聚集索引,行定位器是行的聚集索引键。
非聚集索引深入浅出
我们用文章“索引深入浅出:聚集索引的B树结构”用到的salesorderdetails创建一个非聚集索引,这个表在salesorderdetailid列有一个聚集索引。
CREATE UNIQUE INDEX Ix_ProductId ON SalesOrderDetail(ProductId,Salesorderid)
收集非聚集索引相关信息:
TRUNCATE TABLE dbo.sp_table_pages
INSERT INTO sp_table_pages EXEC('DBCC IND(IndexDB,SalesOrderDetail,2)')
GO SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3472,3) DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3416,3)--叶子节点/索引页 DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3557,3)--叶子节点/索引页
SELECT * FROM dbo.sp_table_pages WHERE IndexLevel=0 --叶子节点/索引页
根据上述信息进行非聚集索引逻辑示意图的绘制:

现在我们来分析下SQL Server如何存储非聚集索引,首先我们通过DBCC IND命令查看非聚集索引的页分配情况,最后一个参数,2是Ix_ProductId的索引号。
DBCC IND(IndexDB,SalesOrderDetail,2)
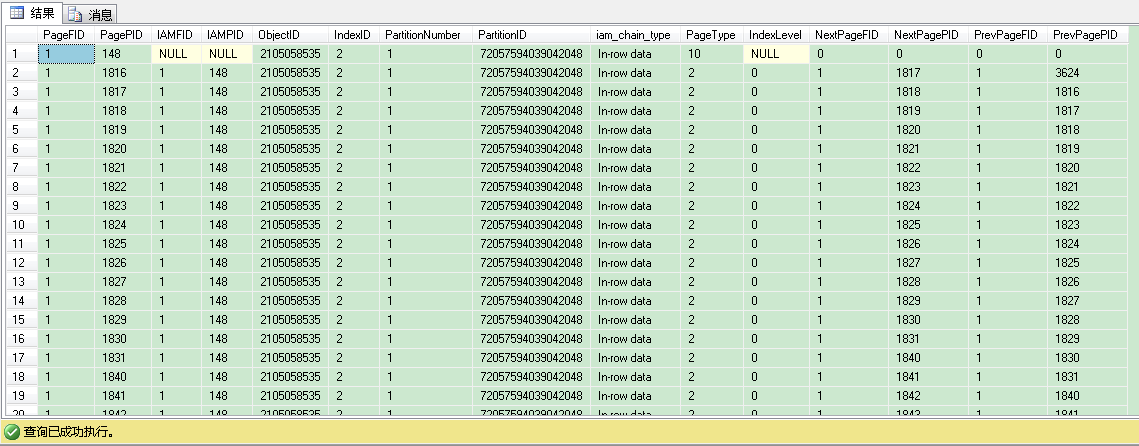

我们看到输出结果一共有229条记录,包含1个IAM页和229个索引页。我们可以通过找IndexLevel 列值最大的记录,来找根页(root page)。记住索引层级是从叶子层向根层增长的。
SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页
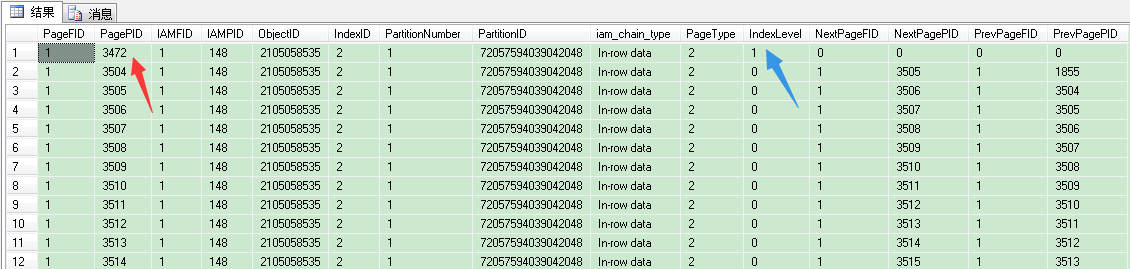
在这个表里,我们根层(root leve)页号是3472,index level是1,这就是说,这个非聚集索引的B树结构只有根层(root level)和叶子层(leaf level),没有中间层(intermediate level)。我们来看看3472页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3472,3)
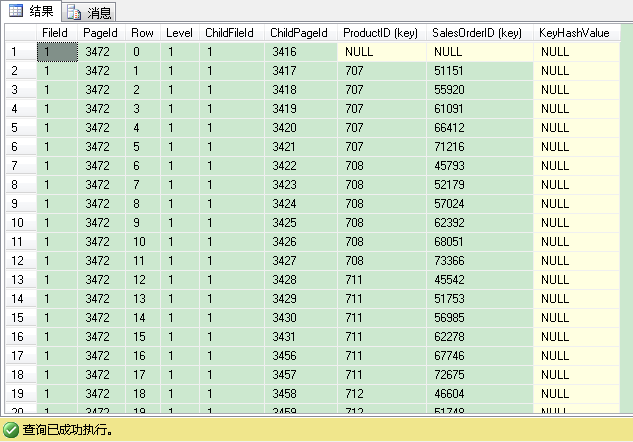
返回结果一共有227条记录(227个叶子层的索引页)。部分结果如上所示。这和聚集索引里的根层(root)/中间层(intermediate)的页结构是一样的。productid与salesorderid组合的值小于或等于(707,51151)的所有记录,可以在子页3416里找到。productid与salesorderid组合的值在(707,51151)与(707,55920)之间的所有记录,可以在子页3417里找到,并以此类推。
我们来看看3417页。
DBCC TRACEON(3604)
DBCC PAGE(IndexDB,1,3417,3)
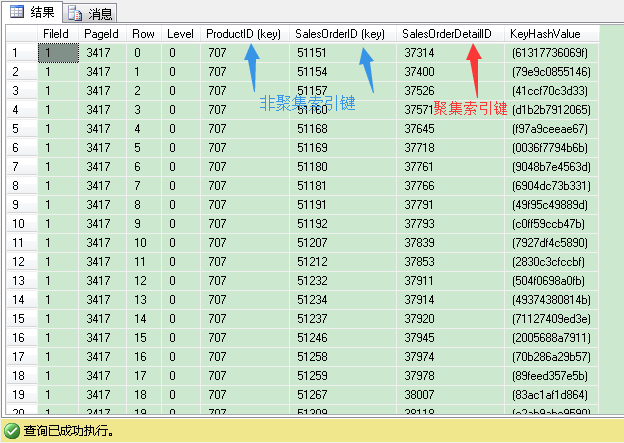
一共返回539条记录,都是product id为707的记录。这里的索引只用2层,这个是B树结构的叶子层。你会注意到,这里没有子页ID列,但我们有salesorderdetailid列(聚集索引键),SQL Server用它来进行键或书签查找操作。
我们来看看,SQL Server如何使用这个索引进行一个SELECT操作。点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
SET STATISTICS IO ON
GO
SELECT * FROM SalesOrderDetail WHERE productid=707 AND SalesOrderid=51192
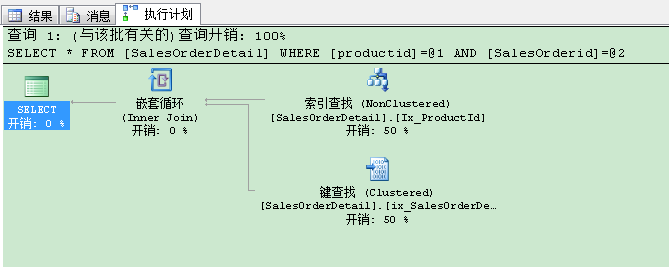
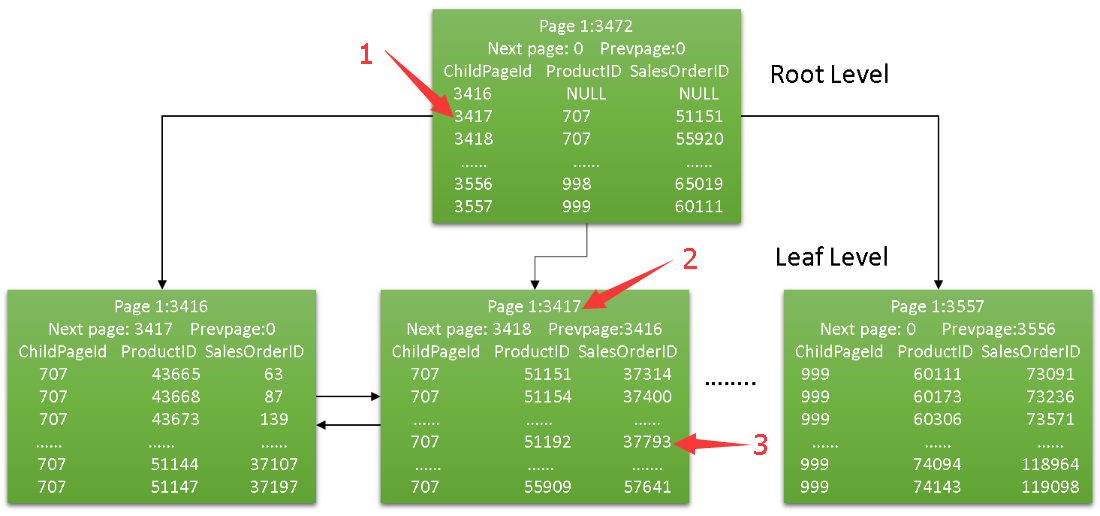
可以看到执行计划的键查找操作。因为这里where条件刚好完全符合我们非聚集索引定义,SQL Server用这个索引来执行查询。首先SQL Server读取B树结构的根页。我们的查询条件组合(707,51192)落在根页的第二条记录上,因此SQL Server走到它的子页(页号3417)。在这个页里,我们可以用条件组合(707,51192)定位到具体的记录上,它的salesorderdetailid值是37793。从这里开始,SQL Server使用salesorderdetailid值进行键查找(key look up)操作。从上一个文章知道,但我们进行任何聚集索引键查找是,需要执行3个I/O。 因此这里,SQL Server需要执行5个I/O操作(2个在非聚集索引,3个在聚集索引的书签/键查找(bookmark/key lookup),这个和你的结果输出一致。

为了更好的理解它,我们可以把非聚集索引当作salesorderdetail 表的一个子表(我们把它叫做Saleorderdetail_NC),有productid,salesorderid 和 SalesorderDetailid列,并且 ProductId与salesorderid列组合为聚集索引。上述查询的结果可以通过以下2个查询来获得。
SELECT * FROM SalesOrderDetail_nc WHERE productid=707 AND SalesOrderid=51192
GO
SELECT * FROM SalesOrderDetail WHERE SalesOrderDetailid=37793
我们再来看一个查询:
1 SELECT * FROM SalesOrderDetail WHERE productid=707

查询返回3083条记录,查询条件与非聚集索引的第一列匹配。但是SQL Server并没用非聚集索引来执行这个查询,查询计划如下所示。
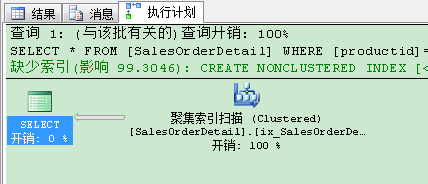
这样做的原因是,如果使用非聚集索引,就需要为3083条记录执行书签查找(key lookup)。这会产生9249个I/O操作(3083*3)。因此,SQL Server使用了聚集索引扫描,它只需要1501(对于聚集索引树结构需要的页数)个I/O操作。如果我们做一个小的改动,只要Productid ,SalesOrderDetailid和SalesOrderId列,SQL Server会使用非聚集索引,因为它不需要进行书签查找(bookmark lookup)操作。非聚集索引的叶子层已经包含这些列了。
SELECT productid,salesorderdetailid,salesorderid FROM SalesOrderDetail WHERE productid=707

这篇文章真的有点长,而且我是该死的BING输入法出错,导致浏览器崩溃,丢失一个晚上3个小时成果,重新写好的,希望大家看了之后可以透彻理解非聚集索引了,晚安各位!!2015-05-14 00:18:42
参考文章:
索引深入浅出(4/10):非聚集索引的B树结构在聚集表的更多相关文章
- 索引深入浅出(5/10):非聚集索引的B树结构在堆表
在“索引深入浅出:非聚集索引的B树结构在聚集表”里,我们讨论了在聚集表上的非聚集索引,这篇文章我们讨论下在堆表上的非聚集索引. 非聚集索引可以在聚集表或堆表上创建.当我们在聚集表上创建非聚集索引时,聚 ...
- 索引深入浅出(3/10):聚集索引的B树结构
在SQL Server里,有2种表是以存储为基础的.有聚集索引的表叫聚集表,没有聚集索引的表叫堆表.在上一篇文章,我们讨论了堆表的特性和存储结构.在这篇文章里,我们来看下聚集表. 有聚集索引的表叫聚集 ...
- Oracle非分区索引,全局分区索引和本地分区索引。
1.如果按照索引是否分区作为划分依据,Oracle 的索引类型可以分为非分区索引,全局分区索引和本地分区索引. 2.创建演示实例 --创建非分区表create table test_partition ...
- SQL Server性能优化(10)非聚集索引的存储结构
一,新建测试表 CREATE TABLE [dbo].[Users]( ,) NOT NULL, ) NOT NULL, [CreatTime] [datetime] NOT NULL ) ON [P ...
- SQL Server - 索引详细教程 (聚集索引,非聚集索引)
转载自:https://www.cnblogs.com/hyd1213126/p/5828937.html 作者:爱不绝迹 (一)必读:深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录. ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- SQL Server中的聚集索引(clustered index) 和 非聚集索引 (non-clustered index)
本文转载自 http://blog.csdn.net/ak913/article/details/8026743 面试时经常问到的问题: 1. 什么是聚合索引(clustered index) / ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
随机推荐
- javascript replace正则替换时调用函数替换的使用
以下函数将替换英文方式下的单引号和双引号,当然change函数编写决定了你要替换什么? String.prototype.repSpecChar=function() { ...
- 高性能网站架构设计之缓存篇(6)- Redis 集群(中)
昨天晚上钓鱼回来,大发神经,写了篇概括程序员生活现状的文章,没想到招来众多人的口诛笔伐,大有上升到政治层面的趋势. 我也许不会再发表任何冲击心灵的文章,我希望给大家带来更多的正能量,所以那篇文章已被我 ...
- .NET跨平台实践:用C#开发Linux守护进程
Linux守护进程(Daemon)是Linux的后台服务进程,它脱离了与控制终端的关联,直接由Linux init进程管理其生命周期,即使你关闭了控制台,daemon也能在后台正常工作. 一句话,为L ...
- Java虚拟机3:常用JVM命令参数
之后写的东西就会用到虚拟机参数了,现在这里汇个总自己平时用到的.看到的一些虚拟机参数.现在看不懂没关系,反正之后都会用到的: (1)-Xms20M 表示设置堆容量的最小值为20M,必须以M为单位 (2 ...
- Hdoop日记Day10---RPC机制
一.RPC(Remote Procedure Call)简介 RPC 是远程过程调用(Remote Procedure Call),即远程调用其他虚拟机中运行的javaobject.RPC 是一种客户 ...
- SQL SERVER--DBA 常用到的一些脚本
自己整理了一些常用到的脚本,希望对各位有用 下载地址 --================================== 妹子不能少,是吧 BTW, 妹子是我辛苦百度来的,请不要求种求介绍各种求 ...
- 如何在 IIS 上搭建 mercurial server
mercurial server 对于代码管理工具,更多的人可能更熟悉 Git 一些(Git 太火了).其实另外一款分布式代码管理工具也被广泛的使用,它就是 mercurial.多人协作时,最好能够通 ...
- JavaScript 常用功能总结
小编吐血整理加上翻译,太辛苦了~求赞! 本文主要总结了JavaScript 常用功能总结,如一些常用的JS 对象,基本数据结构,功能函数等,还有一些常用的设计模式. 目录: 众所周知,JavaScri ...
- Linux多线程系列-2-条件变量的使用(线程安全队列的实现)
多线程情况下,往往需要使用互斥变量来实现线程间的同步,实现资源正确共享. linux下使用如下变量和函数 //条件变量 pthread_cond_t int pthread_cond_init (pt ...
- bianma 水平 技巧
能够写出这样的代码, 其实体现了水平 switch (state) { case 0: break; case 3: return; // already connected case 4: stat ...