SQL Server 2012 列存储索引分析(转载)
一、概述
列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引、非聚集索引及堆表等以行为单位的方式存储。因为它并不要求存储的列必须唯一,因此它可以通过压缩将重复的列合并,从而减少查询时的磁盘IO,提高效率。
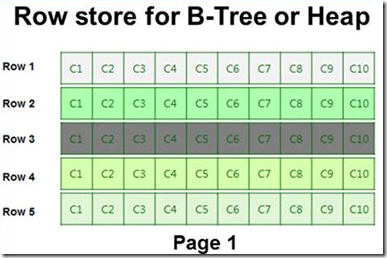
为了分析列存储索引,我们先看看B树或堆中的数据的存储方式,如下图,在page1上,数据是按照行的方式存储数据的,假设一行有10列,那么在该页上,实际的存储也会以每行10列的方式存储,如下图中的C1到C10。
假设我们执行select c1,c2 from table时,数据库会读取整个page1,显然,从C3到C10并不是我们想要的数据,但因为数据库每次读的最小单位是一页,因此这些不得不都加载到内存中。如果数据页多时,必然要消耗更过的IO和内存。
如果是列存储索引,数据按列的方式存储在一个页面中,如下图,page1中只存储表中C1列,page2只存储c2列,以此类推,page10存储c10列。
假设我们执行select c1,c2 from table时,结果会怎样呢?数据库只会读page1和page2,至于page3到page10因为没有对应的数据,数据库不会去读这些页,也不会加载到内存中,相比行存储而言,减少了磁盘IO和优化了内存的使用。

下文做了一个技术验证,用来分析列存储索引的查询性能。
思路:做两张一模一样的分区表(分区表可以更好的展示效果),含1000000行数据,然后给其中一张表(sales2)建立聚集索引,另一张表(sales)建列存储索引,最后来对比这两张表的查询性能。
二、创建表
先做两张相同的表,创建的语句如下:
create partition function pf (date) as range left for values
('', '', '', '', '');
go create partition scheme ps as partition pf all to ([PRIMARY]);
go
create table sales (
[id] int not null identity (1,1),
[date] date not null,
itemid smallint not null,
price money not null,
quantity numeric(18,4) not null)
on ps([date]);
go declare @i int = 0; begin transaction;
while @i < 1000000
begin
declare @date date = dateadd(day, @i /250000.00, ''); insert into sales ([date], itemid, price, quantity)
values (@date, rand()*10000, rand()*100 + 100, rand()* 10.000+1); set @i += 1; if @i % 10000 = 0
begin
raiserror (N'Inserted %d', 0, 1, @i);
commit;
begin tran;
end
end
commit;
GO
create table sales2 (
[id] int not null identity (1,1),
[date] date not null,
itemid smallint not null,
price money not null,
quantity numeric(18,4) not null)
on ps([date]);
go declare @i int = 0; begin transaction;
while @i < 1000000
begin
declare @date date = dateadd(day, @i /250000.00, ''); insert into sales2 ([date], itemid, price, quantity)
values (@date, rand()*10000, rand()*100 + 100, rand()* 10.000+1); set @i += 1; if @i % 10000 = 0
begin
raiserror (N'Inserted %d', 0, 1, @i);
commit;
begin tran;
end
end
commit;
GO
三、查询含聚集键的表
(1) 创建表sales2的聚集键
CREATE CLUSTERED INDEX Clu_sales2_index ON sales2(date,price,quantity) on ps([date])
查看表的存储信息
select * from sys.system_internals_partitions p
where p.object_id = object_id('sales2');
select au.* from sys.system_internals_allocation_units au
join sys.system_internals_partitions p
on p.partition_id = au.container_id
where p.object_id = object_id('sales2');
GO
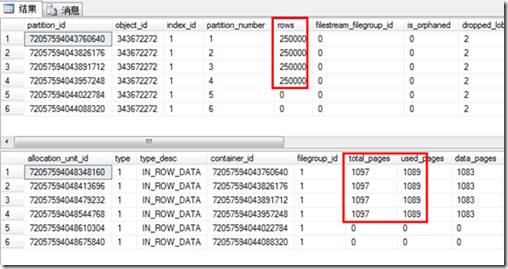
该表一共有6个分区,其中只有4个分区有数据,每个分区250000行,已使用1089页。
(2) 执行查询语句 (注意清掉缓存)
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT COUNT(*),SUM(price*quantity) FROM sales2 WHERE date='';
GO
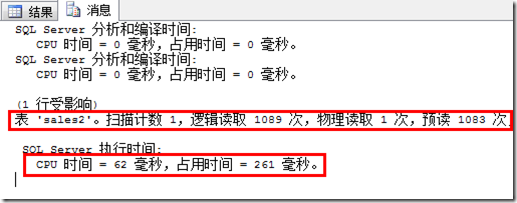
我们可以看到,在这个查询中,一共有1089次逻辑读(等于该表每个分区中的已使用页数),CPU时间为62毫秒,占用时间为261毫秒。
备注:CPU时间,执行语句的时间;
占用时间,从磁盘读取数据开始到完全处理使用的时间。
四、查询含列存储索引的表
(1) 创建表sales的列存储索引
CREATE NONCLUSTERED COLUMNSTORE INDEX [cs_sales_price] ON [dbo].[sales]
(
[date],
[price],
[quantity]
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0)
ON PS([date])
GO
上面创建的是非聚集的列存储索引,顺便说一下聚集的列存储索引是不能选择表列的,只能将整张表的所有列一起创建为列存储索引,语句如下:
CREATE CLUSTERED COLUMNSTORE INDEX [cs_sales_price] ON [dbo].[sales]
WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0)
ON PS([date])
此外当前版本的SQL Server(SQL Server 2016) 中,每张表只能创建一个列存储索引,实际上按理说非聚集的列存储索引应该支持创建多个才对,不知道以后版本的SQL Server会不会支持在一张表上创建多个非聚集的列存储索引。
查看表的存储信息:
select * from sys.system_internals_partitions p
where p.object_id = object_id('sales')
and index_id = 2;
select au.* from sys.system_internals_allocation_units au
join sys.system_internals_partitions p
on p.partition_id = au.container_id
where p.object_id = object_id('sales')
and index_id = 2;
GO

在建有列存储索引后,表的行数并没有改变,每个分区依然还是250000行,但页面数明显减少,且页的类型由原来的IN_ROW_DATA变成了LOB_DATA。
(2) 执行查询语句
select count(*), sum(price*quantity) from sales where date = ''

在这个查询中,一共有363次逻辑读(等于该表每个分区),CPU时间为93毫秒,占用时间为191毫秒。
总结
从两次查询的结果来看,无论是逻辑读的次数和占用时间,在列存储索引的表中执行查询明显要快于聚集索引的表。
而且,从两种表的存储结构中可以看到,列存储索引占用的页面数量较聚集索引的少,这也印证了列存储索引的压缩功能。
备注:通过两次查询,我们看到两者的CPU时间差距不是很大,相反聚集索引占用的时间更小,考虑到列存储实际上是压缩存储,我认为在一张小表或者简单的表中,对列存储索引进行查询或许会占用更多的CPU时间,因为查询时需要解压(我没有具体验证过),因此列存储索引在小表中的优势主要体现在IO和空间上,实际上列存储索引的对象往往是含有大数据量的表,数据量越大,其优势体现越明显。
说明:准确的说本文并不是原创,文章是从如下地址翻译过来,然后结合自己的实践,增加了一些自己的理解。
http://rusanu.com/2011/07/13/how-to-update-a-table-with-a-columnstore-index/
列存储索引,几个好的应用场景:
如果你有大型的事实表并且存在查询问题的,或者SSAS存在其他性能问题的,列存储是一个不错的方案。以下两种情况是经过测试的比较好的应用场景:
- 对于高频率响应的报表/仪表板,尤其分析当性能表现不佳的时候,会有很不错的性能。
- 对于ETL的过程来讲,源数据的列存储索引将会极大提高性能,如果数据足够大甚至可以考虑临时创建列存储索引。然后执行ETL。
SQL Server 2012 列存储索引分析(转载)的更多相关文章
- SQL Server 2012 列存储索引分析(翻译)
一.概述 列存储索引是SQL Server 2012中为提高数据查询的性能而引入的一个新特性,顾名思义,数据以列的方式存储在页中,不同于聚集索引.非聚集索引及堆表等以行为单位的方式存储.因为它并不要求 ...
- 微软BI 之SSAS 系列 - 在 SQL Server 2012 下查看 SSAS 分析服务的模型以及几个模型的简单介绍
在SSDT中部署一个 SSAS 项目到本地服务器上出现错误. You cannot deploy the model because the localhost deployment server i ...
- SQL Server 2012 批量重建索引
关于索引的概念可以看看宋大牛的博客 T-SQL查询高级—SQL Server索引中的碎片和填充因子 整个数据库的索引很多,索引碎片多了,不可能一个个的去重建,都是重复性的工作,所以索性写了个存储过程, ...
- 在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算.当然,对于数据的存放平台SQL Server数据库引擎而言 ...
- SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog) 简介 之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也 ...
- Sql Server 2012 的新分页方法分析(offset and fetch) - 转载
最近在分析 Sql Server 2012 中 offset and fetch 的新特性,发现 offset and fetch 无论语法的简洁还是功能的强大,都是相当相当不错的 其中 offset ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- 解读SQL Server 2014可更新列存储索引——存储机制
概述 SQL Server 2014被号称是微软数据库的一个革命性版本,其性能的提升的幅度是有史以来之最. 可更新的列存储索引作为SQL Server 2014的一个关键功能之一,在提升数据库的查询性 ...
- SQL Server ->> ColumnStore Index(列存储索引)
Columnstored index是SQL Server 2012后加入的重大特性,数据不再以heap或者B Tree的形式存储(row level)存储在每一个数据库文件的页里面,而是以列为单位存 ...
随机推荐
- 结构体访问成员变量什么时候该用“->”或者是"."呢?的困惑
煎蛋栗子: typedef struct Node{int data;struct Node *next;}LinkList; LinkList *p=(LinkList *)malloc(sizeo ...
- 探讨e.target与e.currentTarget
target与currentTarget两者既有区别,也有联系,那么我们就来探讨下他们的区别吧,一个通俗易懂的例子解释一下两者的区别: <!DOCTYPE html> <html&g ...
- python3 get post请求Yunba RESTful API
一:主要内容 获取云巴appkey和seckey 状态回复说明 get请求 post请求 二:获取云巴appkey和seckey 1. 注册云巴 在云巴官网,注册一个云巴账号,官网地址:https:/ ...
- Java NIO系列教程(二) Channel
Java NIO的通道类似流,但又有些不同: 既可以从通道中读取数据,又可以写数据到通道.但流的读写通常是单向的. 通道可以异步地读写. 通道中的数据总是要先读到一个Buffer,或者总是要从一个Bu ...
- Tomcat学习总结(14)—— Tomcat常见面试题
一.Tomcat的缺省是多少,怎么修改 Tomcat的缺省端口号是8080. 修改Tomcat端口号: 1.找到Tomcat目录下的conf文件夹 2.进入conf文件夹里面找到server.xml文 ...
- Redis Cluster高可用集群在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Python之pymysql的使用
在python3.x中,可以使用pymysql来MySQL数据库的连接,并实现数据库的各种操作,本次博客主要介绍了pymysql的安装和使用方法. PyMySQL的安装 一..windows上的安装方 ...
- Struts2开发基础
Struts2开发基础 struts2采用拦截器的机制来处理用户的请求,使得业务逻辑控制器能够与ServletAPI完全脱离开. 1. Hello World! 配置web.xml <?xml ...
- 易错java知识点总结(持续更新)
1. 2.java转义字符的理解 参考知乎大神:http://www.zhihu.com/question/29232624 正向和逆向处理转义字符 正向:把两个字符 \ n 识别为一个转义字符 ne ...
- MVC登录前准备写好cookie
Insus.NET写过一系列的MVC的练习,昨天学习了jQuery的验证<在MVC应用程序中使用jQuery的验证>http://www.cnblogs.com/insus/p/34626 ...