8.正则表达式和XPath
1.使用正则表达式爬取内涵段子
import requests
import re def loadPage(page): url = "http://www.neihan8.com/article/list_5_" +page+".html"
#User-Agent头
user_agent = 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0'
headers = {'User-Agent': user_agent}
response = requests.get(url,headers=headers)
response.encoding = 'gbk'
html = response.text return html if __name__=="__main__":
page=input('请输入要爬取的页面:')
html=loadPage(page)
# with open('a.html','w') as f:
# f.write(html) # 找到所有的段子内容<div class="f18 mb20"></div>
# re.S 如果没有re.S 则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配
# 如果加上re.S 则是将所有的字符串将一个整体进行匹配,找到(.*?)组里面的内容
pattern=re.compile(r'<div.*?class="f18 mb20">(.*?)</div>',re.S)#匹配规则
item_list=pattern.findall(html)#找到所有符合条件的
for item in item_list:
#去除html标签
item = item.replace("<p>", "").replace("</p>", "").replace("<br />", "")
#'a'以追加的方式把内容写入文件
with open('a.txt','a',encoding='utf-8') as f:
f.write(item)
print(item)
2.使用XPath下载图片
import requests
from lxml import etree def getGirlInedx(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} html=requests.get(url=url,headers=headers).text
content=etree.HTML(html)
link_list=content.xpath('//img[@class="BDE_Image"]//@src')
for item in link_list:
loadImage(item) #爬取图片
def loadImage(linkurl):
print(linkurl)
#保存图片到本地
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} filename=linkurl[-:]
htmlIamge=requests.get(linkurl)
with open("image/"+filename,'wb') as f:
f.write(htmlIamge.content) if __name__=="__main__":
url = "https://tieba.baidu.com/p/5680998501"
getGirlInedx(url)
什么是XPath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
XPath 开发工具
- 开源的XPath表达式编辑工具:XMLQuire(XML格式文件可用)
- Chrome插件 XPath Helper
- Firefox插件 XPath Checker
选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 | |
|---|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 | |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! | |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 | |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 | |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 | |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath的运算符
下面列出了可用在 XPath 表达式中的运算符:
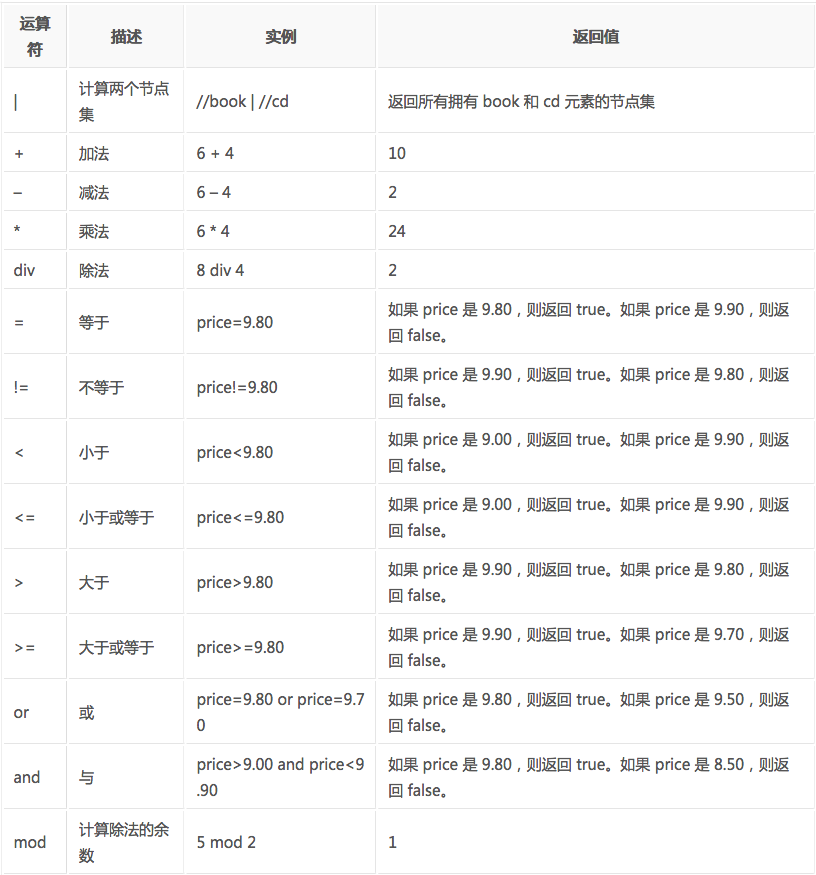
lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
初步使用
我们利用它来解析 HTML 代码,简单示例:
# lxml_test.py# 使用 lxml 的 etree 库
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
''' #利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text) # 按字符串序列化HTML文档
result = etree.tostring(html) print(result)
输出结果:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
lxml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签。
文件读取:
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html --><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
再利用 etree.parse() 方法来读取文件。
# lxml_parse.pyfrom lxml import etree # 读取外部文件 hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html, pretty_print=True) print(result)
输出结果与之前相同:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
XPath实例测试
1. 获取所有的 <li> 标签
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
print type(html) # 显示etree.parse() 返回类型
result = html.xpath('//li')
print result # 打印<li>标签的元素集合
print len(result)
print type(result)
print type(result[])
输出结果:
<type 'lxml.etree._ElementTree'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>] <type 'list'>
<type 'lxml.etree._Element'>
2. 继续获取<li> 标签的所有 class属性
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result)
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3. 继续获取<li>标签下hre 为 link1.html 的 <a> 标签
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print(result)
运行结果
[<Element a at 0x10ffaae18>]
4. 获取<li> 标签下的所有 <span> 标签
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
#result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
print(result)
运行结果
[<Element span at 0x10d698e18>]
5. 获取 <li> 标签下的<a>标签里的所有 class
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class')
print(result)
运行结果
['blod']
6. 获取最后一个 <li> 的 <a> 的 href
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()]/a/@href')
# 谓语 [last()] 可以找到最后一个元素
print(result)
运行结果
['link5.html']
7. 获取倒数第二个元素的内容
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')
# text 方法可以获取元素内容
print(result[].text)
运行结果
fourth item
8. 获取 class 值为 bold 的标签名
# xpath_li.pyfrom lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# tag方法可以获取标签名
print(result[].tag)
运行结果
span
8.正则表达式和XPath的更多相关文章
- 正则表达式(特殊字符)/Xpath语法/CSS选择器
正则表达式(特殊字符) ^ 开头 '^b.*'----以b开头的任意字符 $ 结尾 '^b.*3$'----以b开头,3结尾的任意字符 * 任意长度(次数),≥0 ? 非贪婪模式,非贪婪模式尽可能少的 ...
- 12.Python爬虫利器三之Xpath语法与lxml库的用法
LXML解析库使用的是Xpath语法: XPath 是一门语言 XPath可以在XML文档中查找信息 XPath支持HTML XPath通过元素和属性进行导航 XPath可以用来提取信息 XPath比 ...
- Python网络爬虫-xpath模块
一.正解解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- 网络爬虫之Xpath用法汇总
众所周知,在设计爬虫时,最麻烦的一步就是对网页元素进行分析,目前流行的网页元素获取的工具有BeautifulSoup,lxml等,而据我使用的体验而言,Scrapy的元素选择器Xpath(结合正则表达 ...
- 爬虫(Xpath)——爬tieba.baidu.com
工具:python3 核心知识点: 1)lxml包不能用pip下载,因为里面有其他语言编写的文件 2)urlopen返回的请求是html文件,要使用 content = etree.HTML(html ...
- Python爬虫开发【第1篇】【正则表达式】
非结构化数据:HTML(正则表达式.XPath.CSS选择器) 结构化数据:JSON文件(JSON Path.转化为Python类型进行操作) XML文件(转化成Python类型.XPath.CSS选 ...
- [Python]新手写爬虫全过程(已完成)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
随机推荐
- centos7构建python2.7常用开发环境
把下面的代码保存到一个sh文件中执行即可 yum -y install epel-release yum -y install python-pip yum -y install mysql-deve ...
- oracle银行卡卡号计算函数
create or replace function GetCardNoBySerialNo(v_sysacc varchar2,v_position number) return varchar2 ...
- import this
import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than ...
- 459. Repeated Substring Pattern
https://leetcode.com/problems/repeated-substring-pattern/#/description Given a non-empty string chec ...
- Rest架构风格的实践(使用通用Mapper技术)
1.根据用户 id 查询用户数据 1.1 controll控制器 @RequestMapping("restful/user") @Controller public class ...
- swift -基础语法
/** * 1.变量 */ let count1 = 11; print(count1); var count ...
- 2019.01.26 codeforces 528D. Fuzzy Search(fft)
传送门 fftfftfft好题. 题意简述:给两个字符串s,ts,ts,t,问ttt在sss中出现了几次,字符串只由A,T,C,GA,T,C,GA,T,C,G构成. 两个字符匹配的定义: 当si−k, ...
- 2018.11.07 hdu1465不容易系列之一(二项式反演)
传送门 其实标签只是搞笑的. 没那么难. 二项式反演只是杀鸡用牛刀而已. 这道题也只是让你n≤20n\le20n≤20的错排数而已. 还记得那个O(n)O(n)O(n)的递推式吗? 没错那个方法比我今 ...
- maven 中央仓库地址 随笔记下了
Maven 中央仓库地址: 1. http://www.sonatype.org/nexus/ 2. http://mvnrepository.com/ 3. http://repo1.maven.o ...
- zookeeper 单机集成部署
概述 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等,是很多分布式的基础设置,比如dubbo,k ...