C#基础复习(4) 之 浅析List、Dictionary
参考资料
[1] .netCore 源码 https://github.com/dotnet/corefx
[2] 《Unity 3D脚本编程 使用C#语言开发跨平台游戏》陈嘉栋著
[3] 《数据结构 第四版》 叶核亚编著
[4] @InCerry【浅析C# Dictionary实现原理】https://www.cnblogs.com/InCerry/p/10325290.html
基础知识
- 在C#中,List是最常用的可变长泛型列表,类似数组,用于存储一系列数据,使用下标进行索引。
- Dictionary(字典)是C#中最常用的键值对存储数据结构,通过键(须为不可变类型)来对其中的值进行索引。
疑难解答
List如何实现可变长机制?
List是C#中的可变长数组,它是ArrayList的泛型版本,由于ArrayList中所有对象都是Object,往其中加入值类型数据时会频繁触发装箱拆箱(关于装箱拆箱的详情,可以参考我上一篇博文【C#基础复习(2) 之 装箱拆箱】),导致效率问题,同时还有一些关于强制转换的安全问题,所以一般不使用ArrayList。
List底层是通过一个泛型数组进行实现,根据他的无参初始化方法可以知道,当我们使用new List<T>()的方式生成他时,他是将当前内部的数组指向了一个空数组。这段源码内容如下:
public class List<T> : IList<T>, IList, IReadOnlyList<T>
{
private const int DefaultCapacity = 4;
private T[] _items; // Do not rename (binary serialization)
private int _size; // Do not rename (binary serialization)
private int _version; // Do not rename (binary serialization)
private static readonly T[] s_emptyArray = new T[0];
// Constructs a List. The list is initially empty and has a capacity
// of zero. Upon adding the first element to the list the capacity is
// increased to DefaultCapacity, and then increased in multiples of two
// as required.
public List()
{
_items = s_emptyArray;
}
....
}
那么问题就来了,既然初始化的时候,内部数组指向的是一个只读的empty数组,那么为什么我们还可以自如地向List中增加或删除元素呢?他是如何实现可变长机制的呢?
直接跳到List的Add方法中查看一下实现。其增加元素主要跟三个方法有联系,分别是Add,AddWithResize以及EnsureCapacity,下面是它们的源码部分。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void Add(T item)
{
_version++;
T[] array = _items;
int size = _size;
if ((uint)size < (uint)array.Length)
{
_size = size + 1;
array[size] = item;
}
else
{
AddWithResize(item);
}
}
// Non-inline from List.Add to improve its code quality as uncommon path
[MethodImpl(MethodImplOptions.NoInlining)]
private void AddWithResize(T item)
{
int size = _size;
EnsureCapacity(size + 1);
_size = size + 1;
_items[size] = item;
}
private void EnsureCapacity(int min)
{
if (_items.Length < min)
{
int newCapacity = _items.Length == 0 ? DefaultCapacity : _items.Length * 2;
// Allow the list to grow to maximum possible capacity (~2G elements) before encountering overflow.
// Note that this check works even when _items.Length overflowed thanks to the (uint) cast
if ((uint)newCapacity > Array.MaxArrayLength) newCapacity = Array.MaxArrayLength;
if (newCapacity < min) newCapacity = min;
Capacity = newCapacity;
}
}
public int Capacity
{
get
{
return _items.Length;
}
set
{
if (value < _size)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.value, ExceptionResource.ArgumentOutOfRange_SmallCapacity);
}
if (value != _items.Length)
{
if (value > 0)
{
T[] newItems = new T[value];
if (_size > 0)
{
Array.Copy(_items, 0, newItems, 0, _size);
}
_items = newItems;
}
else
{
_items = s_emptyArray;
}
}
}
}
根据以上代码,可以了解以下情况:
- 当List的容量尚且足够时,会自动向内部的数组后面增加数据
- 当List的容量不足(即内部维护的_size大于等于实际数组的长度)时,调用AddWithResize方法,而AddWithResize又会调用EnsureCapacity方法进行扩容。
- 调用EnsureCapacity时,如果当前List容量为空(即我们使用无参构造方法new出List时),会让当前容量增加一个默认值(即DefaultCapacity),如果当前容量不为空,那么就让当前容量翻倍。
在EnsureCapacity方法中仅仅只是对容量(Capacity)进行了赋值,而没有去动真正的数组。实际上玄机在Capacity的set方法中,当容量改变时,会生成一个新的数组,然后将当前数组的所有值拷贝到新数组中。
这样,List为什么能自动扩容就基本清楚了。
总结一下,实际上List内部还是使用了数组对数据进行存储,只不过在添加数据时,对用于保存数据的数组的长度与List的逻辑长度_size进行比较,当内部用于保存数据的数组的长度过小时,就会自动申请扩容,扩宽的容量是原来的两倍。
List增删查改的效率如何?
List增删查改的效率也可以通过源码分析而来,有兴趣的同学可以去看参考资料[1]。下面直接给出结论:
| 数据结构 | Add | Remove | Find | GetByIndex |
|---|---|---|---|---|
| List | O(1) | O(n) | O(n) | O(1) |
其中Remove和Find都是遍历查找,所以时间复杂度颇高。
Dictionary底层如何实现?
说到Dictionary,还是要说一下它的非泛型版本HashTable,HashTable和Dictionary内部原理类似,都是使用Hash的方法来对键值对进行映射,而非传说中的红黑树(C#中的SortedDictionary是由红黑树实现),但细节上不太相同,其中HashTable使用的是双重哈希(double hashing)的方法来避免哈希冲突,而Dictionary则是使用链接技术(Chaining)。
关于Hash
Hash(又译作“散列”)是用来按关键字存储和查找的技术,仔细回想一下,如果我们要在数组中查找某一个元素,常用的有以下几种方法:
- 遍历查找,时间复杂度O(n),当数组数据量过大时将会有性能瓶颈
- 二分查找,时间复杂度O(logn),只对有序的数组有效,条件过于严苛。
而Hash表的技术就是将查找时间降为O(1)的一项技术。他的基本原理很简单,就是将关键字与要存储的值建立一个映射关系,当我们使用关键字访问数组时,就能以O(1)的时间内查找到该值。
一个Hash函数典型示例图如下所示,其中每一个Key经过哈希函数的变换,都变成了对应的hash值。(图片引用自https://www.cnblogs.com/InCerry/p/10325290.html)
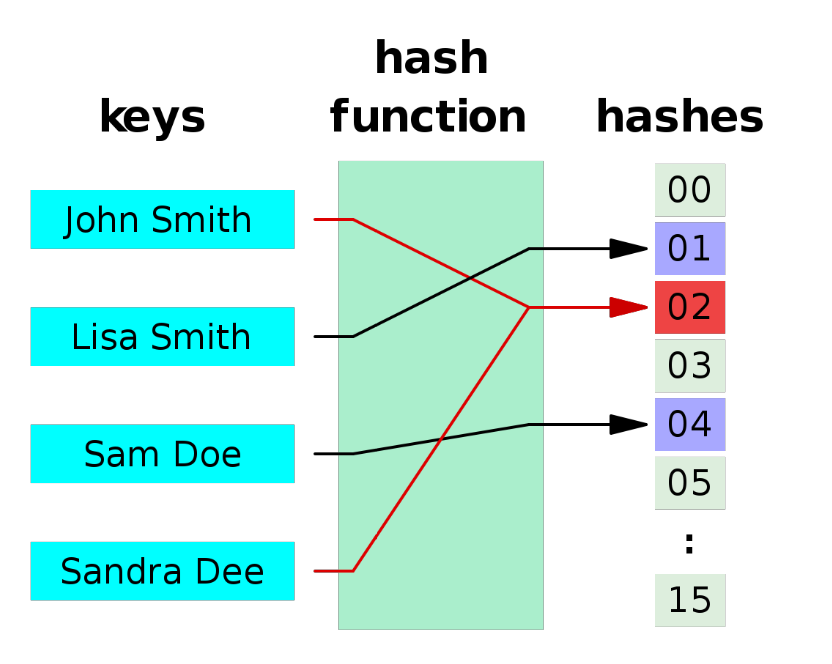
下面再举一个简单的Hash表例子,下面的数组下标与值一一对应,如a[1]=1,a[100]=100,这样,如果我们要查询某个数,如99,只需根据a[99]中的值是否为0即可判断数组内存不存在整型数据99。
| 下标 | 0 | 1 | 2 | ... | 99 | 100 |
|---|---|---|---|---|---|---|
| 值 | 0 | 1 | 0 | ... | 99 | 0 |
但是上面这个例子有一个缺陷,那就是,如果要存储数字10000,而就要开辟长度为1w的数组,如果数组元素不密集,将会造成许多浪费。这时,就可以使用Hash函数来对关键字进行一些处理。
Hash函数中可以通过一系列的操作来使得关键字的数值尽量小而不会重复,比如取余操作。
同样是举一个简单的例子,以 关键字 % length(数组长度) 这样的哈希函数来像下面这样存储数据。
| 下标 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 值 | 1000 | 1009 | 10 | 123 |
| hash函数处理关键字 | 1000%4=0 | 1009%4=1 | 10%4=2 | 123%4=3 |
其中关键字与值一一对应,关键字通过hash函数的处理变成了对应该值的下标。
Hash冲突
根据上面的描述,可以看出Hash函数要保证根据关键字算出的每一个Hash值都不重复是一件并不简单的事。
举个例子,同样是使用上面那个 关键字 % length 的hash函数,如果要向加入值1000和400就会出现问题,因为它们经过计算之后得到的下标值都为0。这时就发生了Hash冲突(也称为Hash碰撞)。
关于Hash冲突,一个更为准确的定义如下:
设两个关键字k1和k2(k1!=k2),如果hash(k1)=hash(k2),即它们的散列地址相同,表示不同关键字的多个元素映射到同一个存储位置,这种现象称为冲突。
当发生Hash冲突时,我们就用对冲突进行处理。常见的处理冲突的方法有两种,一种是开放定址法(如线性探查法、二次探查法),一种是链地址法。
线性探查法
线性探查法的描述如下(引用自《数据结构》):
- 设一个元素关键字为k,其散列地址为i = hash(k)。
- 若散列表中i位置已存储元素,则产生冲突,探测下一个位置i+1是否为空,若空,则存储该元素;
- 否则继续探测下一个位置i+2,以此类推。
探测的地址序列是i+1、i+2、....直至找到一个空位置。
设有hash函数如下:
int hash(int data,int[] nums){
return data % nums.length;
}
线性探查法的查找过程如下图所示:
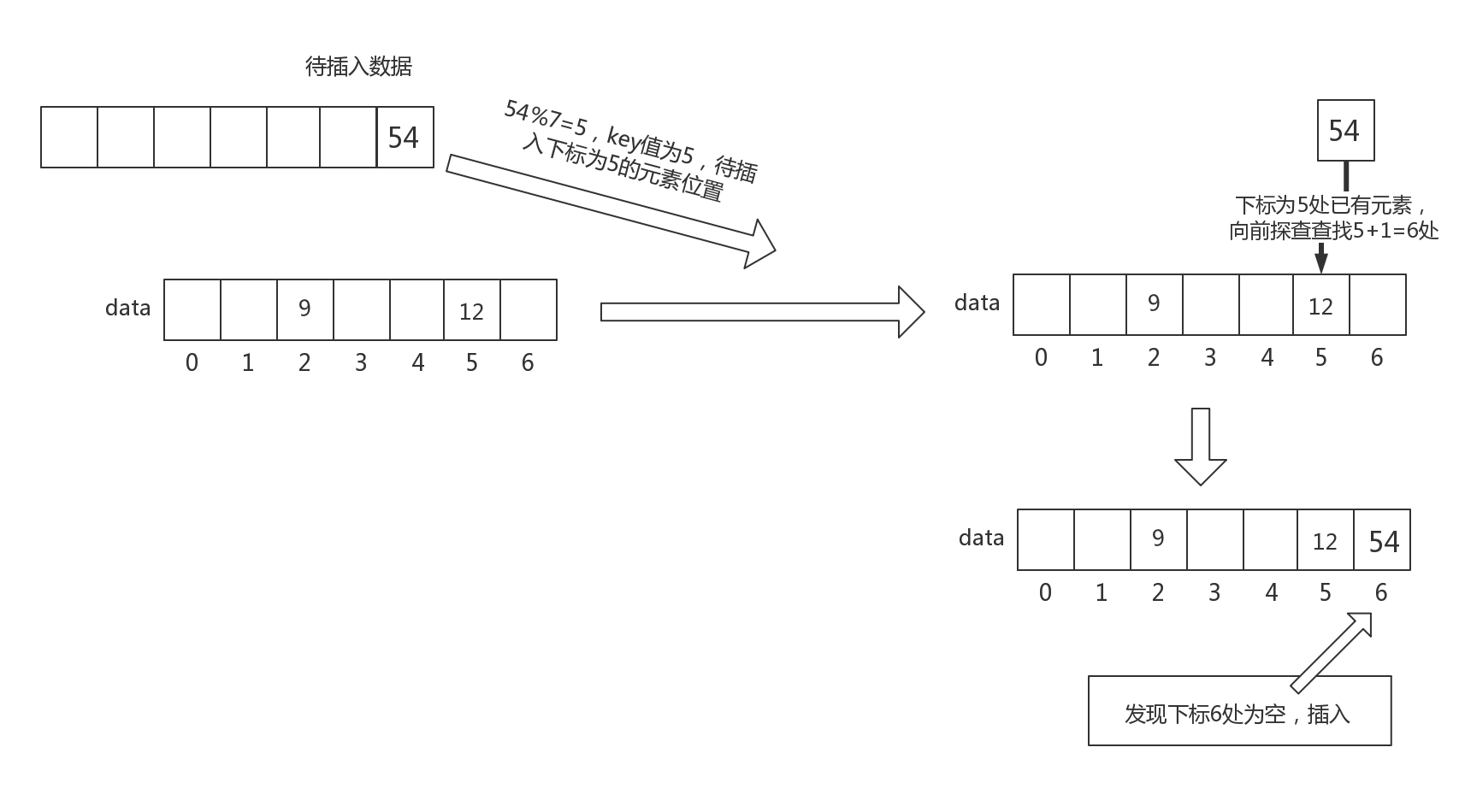
根据以上描述,可以发现,使用线性探查法来解决hash冲突,当冲突越多时,hash表查找速度越慢,这是因为在下次插入或者查找Hash表的时候,冲突依然存在。
二次探查法
针对线性探查法出现的问题,一种改进方法是二次探查法。
也就是Hash冲突聚集在某个范围内,每次向下检查平方的步长。
举个例子,对于线性探查法来说,如果位置index满了,他会检查index+1,index+2,index+3,....,index+n,以此类推。
对于二次探查法来说,如果位置index满了,他会检查index+12 ,index+22 , index+32 , ... , index+n2。
其操作过程如图所示:
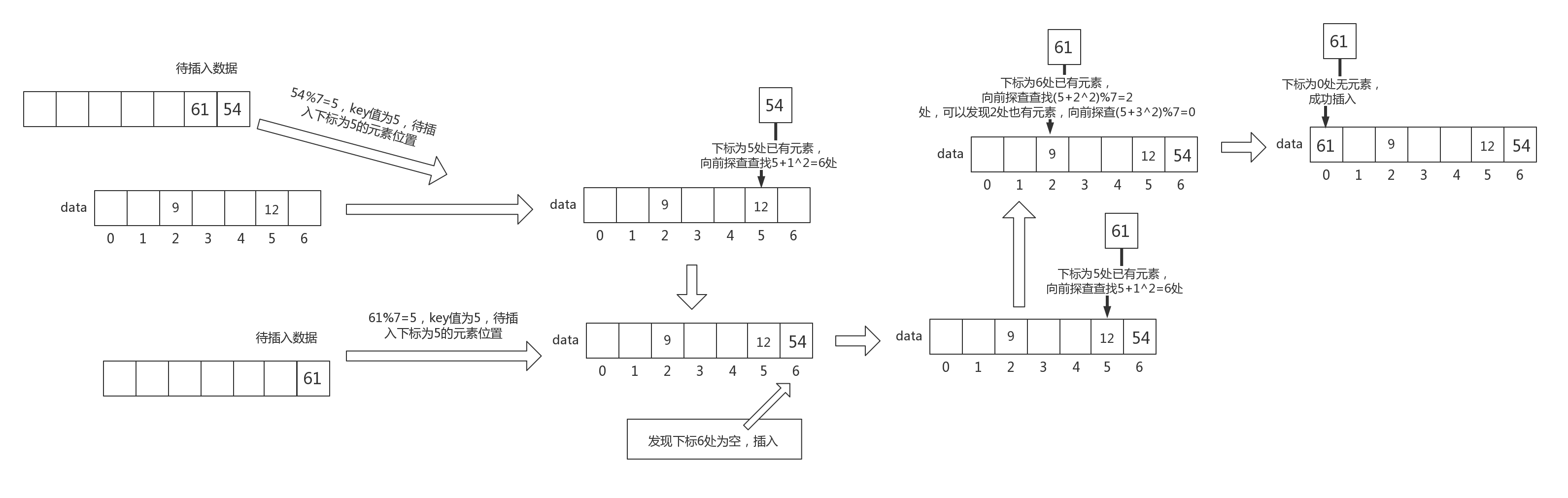
链地址法
与开放定址法不同,链地址法在遇到冲突时不会将冲突的元素放到当前数组的前面或后面,而是将同类冲突(即hash(i)都等于k的元素)放入一个链表,在查找时,首先根据hash函数找到键值,然后沿着这条链表向后面进行查找。
《数据结构》一书中对此是这样描述的:
- 采用散列数组存储元素,将元素key存储在数组的hash(key)位置
- 采用一条同义词单链表存储一组同义词冲突元素,散列数组中各元素都可链接同一条同义词单链表。
设有hash函数如下:
int hash(int data,int[] nums){
return data % nums.length;
}
链地址法的操作流程如下图所示:
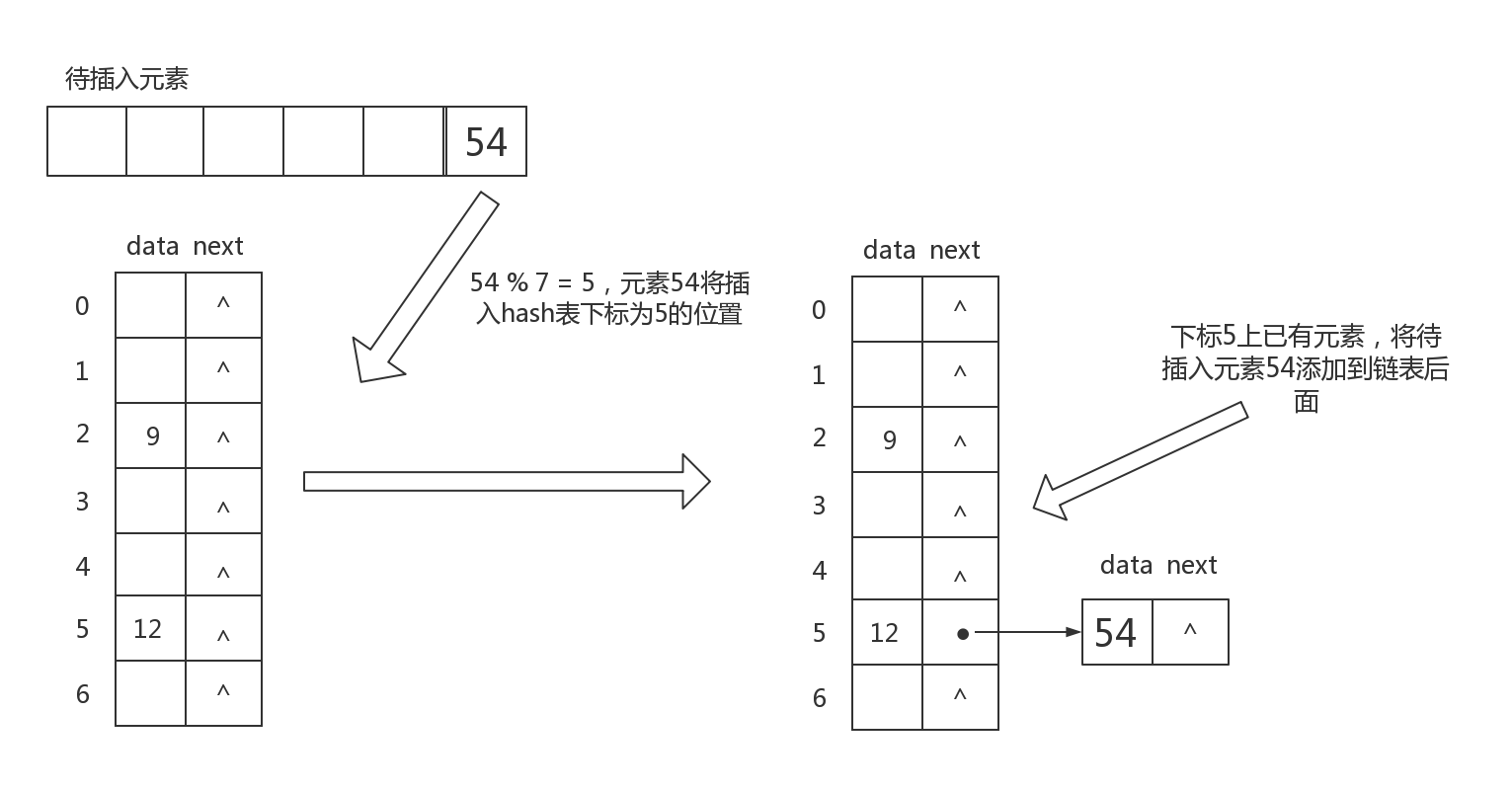
负载因子
从上面的分析中可以看出,当散列表一开始申请的数组空间越小、冲突的元素越多时,每次插入、查询元素的所消耗的时间会越来越多(无论采用哪种解决冲突的方法)。
对于这一点,C#在HashTable中设计了一个叫负载因子的东西。在《Unity跨平台开发》中是这样描述它的:
负载因子loadFactor定义范围在0.1~1.0,它指定了哈希表中元素数量与位置数量之间最大的比例。例如,当loadFactor=0.5时,说明哈希表中只有一半的空间存放了元素值,其余一半都为空。
向Hashtable类的实例添加新元素时,需要检查以保证元素与空间大小的比例不会超过最大比例。如果超过了,HashTable类实例的空间将被扩充。
Dictionary也会在必要时扩容,但它的扩容并不是依据loadFactor设计的。这个在后面说说。
Hash桶
有时候Hash函数算出来的HashCode会大于我们用于存放数据的数组的长度,这时我们就不能粗暴的将HashCode直接作为键值(内部实现就是作为保存数据的下标)对数据进行映射。
对于这个问题,我们可以使用Hash桶算法来解决。
对于Hash桶我理解的还不是很透彻,这里引用一下@InCerry博主对Hash桶算法的介绍:
因为这样的一个问题,所以人们就将生成的HashCode以分段的形式来映射,把每一段称之为一个Bucket(桶),一般常见的Hash桶就是直接对结果取余。
假设将生成的hashCode可能取值有2^32个,然后将其切分成一段一段,使用8个桶来映射,那么就可以通过bucketIndex = HashFunc(key1) % 8这样一个算法来确定这个hashCode映射到具体的哪个桶中。
大家可以看出来,通过hash桶这种形式来进行映射,所以会加剧hash的冲突。
Dictionary实现细节
有了上面的理论基础,我们就可以来看一下Dictionary的源码到底是如何实现的了。
重要数据项
Dictionary中重要的属性如下所示:
private struct Entry
{
public int hashCode; // 当前键经过Hash函数运算后得到的值,如果为-1表示此项为空
public int next; // 表示当前数据的key的同类冲突的下一个元素,-1表示结尾
public TKey key; // 当前数据的键
public TValue value; // 当前数据的值
}
private int[] _buckets; // Hash桶,它的值是指向_entries数组的下标
private Entry[] _entries; // 用于存储数据的数组
private int _count; // 当前entries的下标
private int _freeList; // 被删除的Entry在entries中的下标,构成一个单链表,该链表中所有元素都是空闲的
private int _freeCount; // 有多少个空闲的位置(即有多少个数据项Entry被删除了)
private int _version; // 当前Dictionary版本,用于防止字典在迭代过程中被修改
其中Entry是Dictionary中的重要数据结构,对于它的属性,简单举个例子,比如我们平常使用Add("xx",yy)方法,那么就会创建出一个新的Entry对象,它的key是"xx",它的hashCode是hash("xx"),它的value是yy。可以看出我们放进字典中的键和值被包装成了这个数据结构。
其中next属性我注释说的比较模糊,这里再仔细的说一下。
前面我们说过C#中的Dictionary是使用链地址法来解决Hash冲突的,这个Next属性就是用来实现链地址法的,它指向了下一个、键的hashCode值与当前数据的hashCode值相同的数据。
什么意思呢?简单来说就是Entry中的next表示在entries数组中的某一个数据项,next的值就是该数据项(Entry)在entries数组中的下标。下面画了一幅图来解释这个next的意思,通过这样next的连接,就实现了一个同类冲突的单链表。
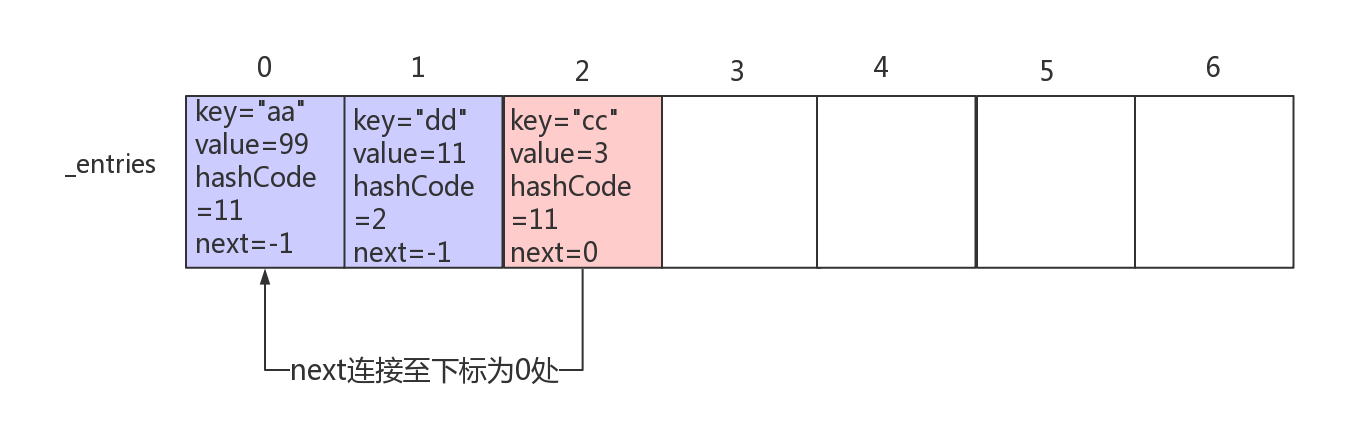
字典中的Add方法实现细节与效率分析
下面我们直接围绕一次Add方法中,发生了什么过程了讲解它的实现细节。为啥是Add方法呢,因为观察源码我们可以知道,我们平时常用的map["xx"]=yy这种方法原理和Add实际上是差不多的,只不过Add方法在遇到已有Key时会抛出异常,Add和this[]=yy方法如下所示:
public TValue this[TKey key]
{
get
{
int i = FindEntry(key);
if (i >= 0) return _entries[i].value;
ThrowHelper.ThrowKeyNotFoundException(key);
return default;
}
set
{
bool modified = TryInsert(key, value, InsertionBehavior.OverwriteExisting);
Debug.Assert(modified);
}
}
public void Add(TKey key, TValue value)
{
bool modified = TryInsert(key, value, InsertionBehavior.ThrowOnExisting);
Debug.Assert(modified); // If there was an existing key and the Add failed, an exception will already have been thrown.
}
首先,假设Dictionary中已有Hash桶和entries数组的长度均为7,hash("aa")hash("bb")hash("cc")=11,hash("dd")=2(注意只是假设),其大致示意图如下:
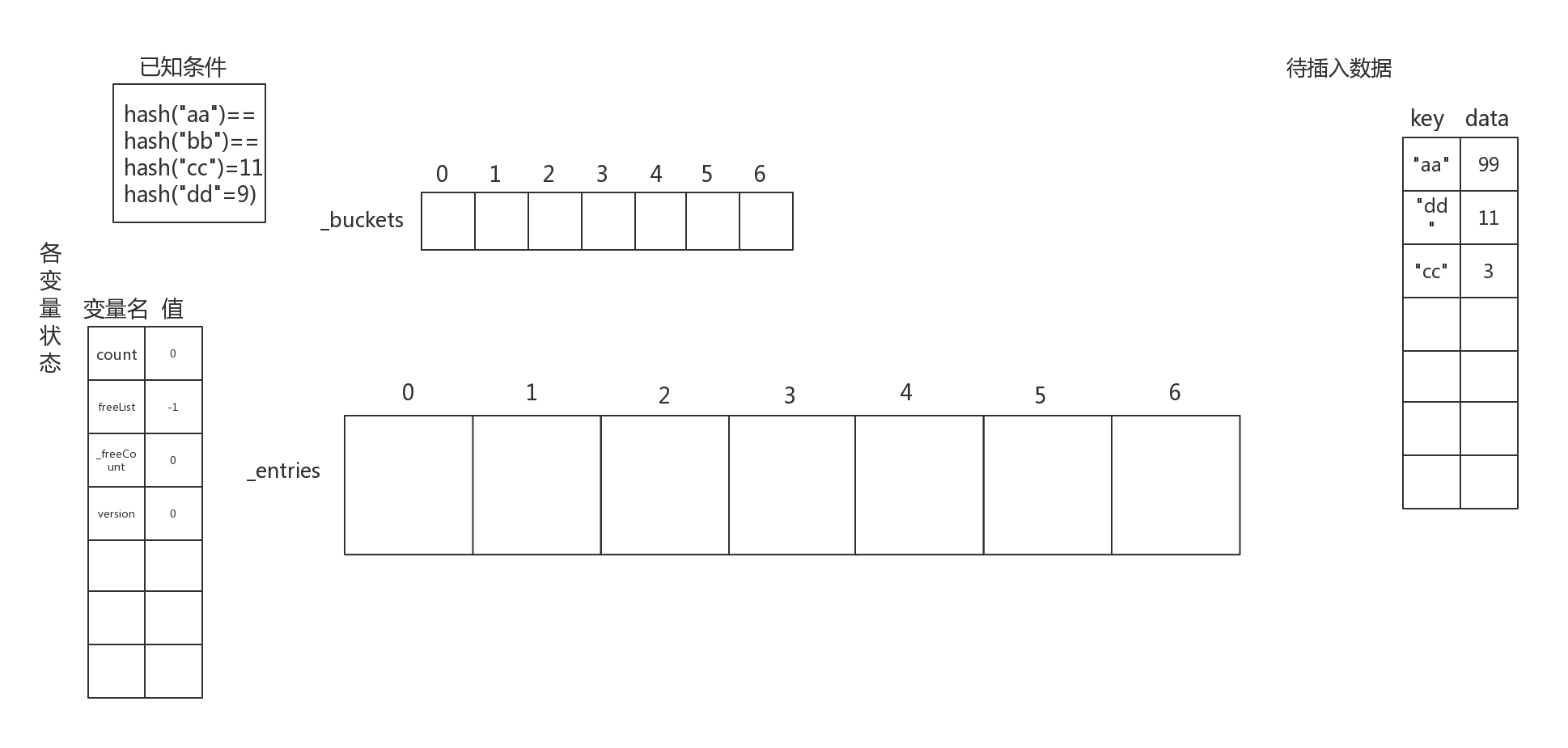
下面根据将待插入数据全部插入Dictionary数据结构中。
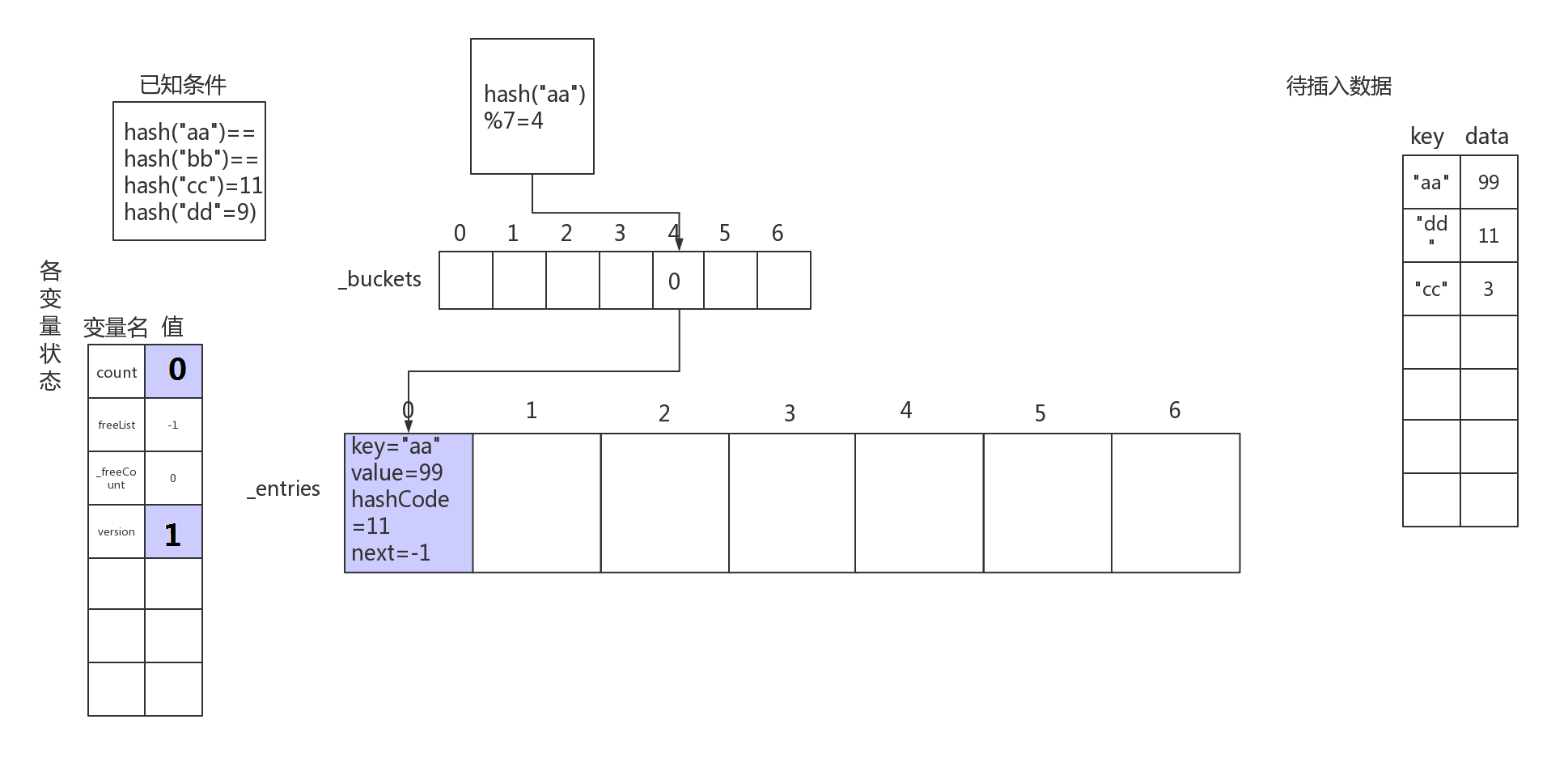
- 首先对第一个待插入数据"aa"->99的键进行hash操作,可知hash("aa")=11,hashCode大于hash桶的数量所以要对它进行一个取余操作,即 hash("aa") % len(_buckets) = 4。
可知我们要在hash桶中下标为4的地方存放数据。但是_buckets是整型数组,不能存Entry型数据,所以将Entry数据存放到_entries数组的空闲位置。
空闲位置是什么呢,其实就是count属性所表示的下标。
上面的步骤用伪代码来描述是这样的:
// entries当前空闲位置存放当前数据
_entries[_count] = Entry;(即当前数据)
// 计算数据放到hash桶的哪个地方
int index = hash("aa") % len(_buckets); // => 4
// 使buckets中的数指向entries中存放这个数据的下标处
_buckets[index] = count;
_count++; // 使得count指向下一个空闲数据
插入数据"aa"->99后,示意图如下:
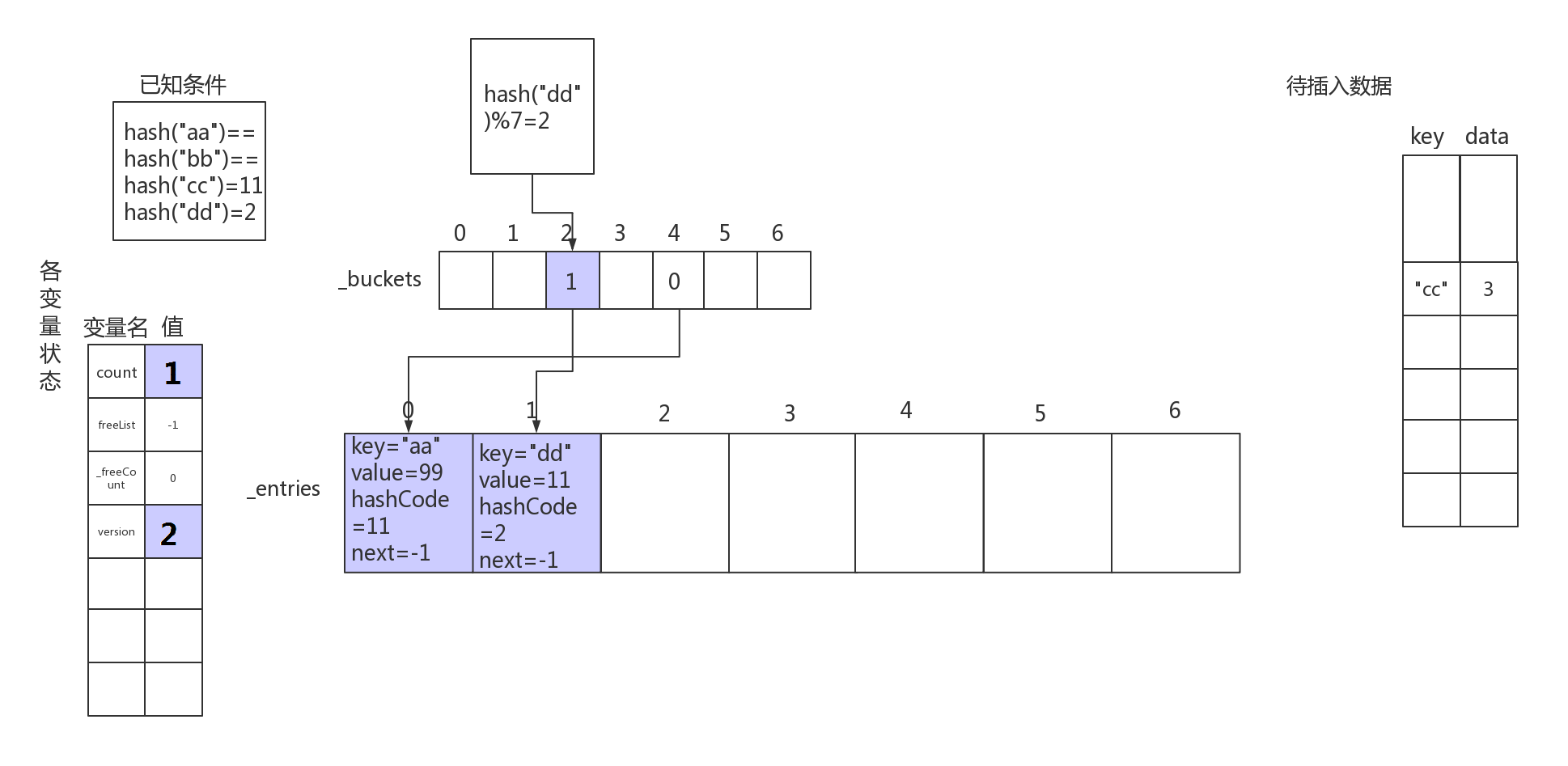
- 对第二个待插入数据"dd"->11的键进行hash操作,可知 hash("dd")%len(_buckets)=2,即要在下标为2的地方存数据。流程大致跟步骤1类似。
插入数据"dd"->11后,内部结构示意图如下:
- 对第三个待插入数据"cc"->3的键进行hash操作,可知hash("cc")%len(_buckets)=4,即要在hash桶下标为4的地方保存数据。但是下标为4的地方已经有数据了,这时就发生了冲突。
Dictionary使用链地址法来解决hash冲突,此时将新的Entry(包装了"cc"数据的对象)的next指向之前已经存在的元素,再让_buckets[index]指向当前新的Entry,这样,就在_buckets[index]处形成了一个同类冲突元素的单链表。
插入数据“cc”后,内部结构示意图如下所示:
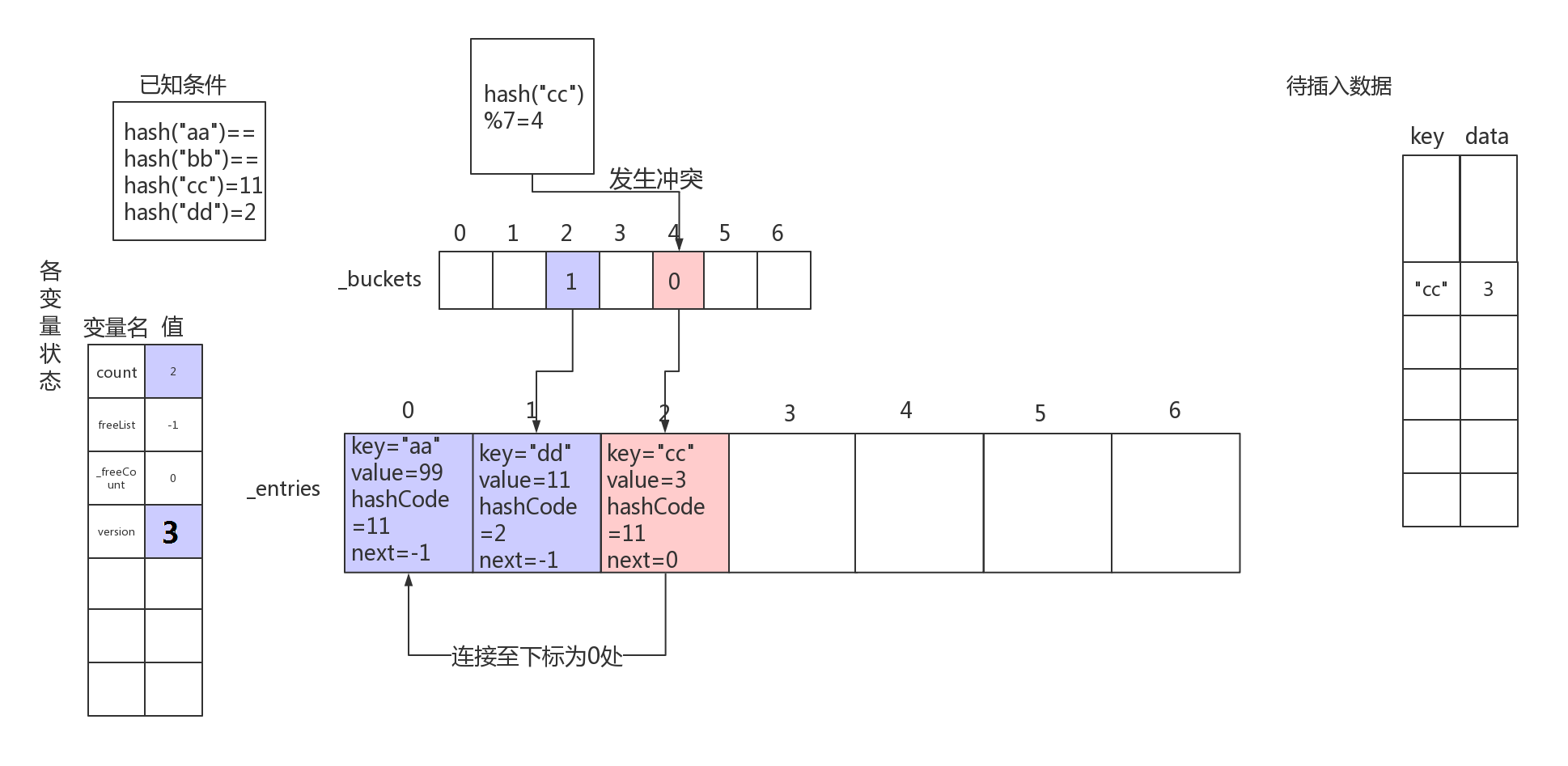
总结
经过前面的三个步骤,三个待插入数据就被插入进了Dictionary中,这里总结一下Dictionary中插入一个数据要进行的步骤:
- 计算待插入数据键的HashCode值
- 将HashCode映射到Hash桶中,int index = HashCode % _buckets.length
- 在_entries数组的空闲处(即count或freelist下标处)“创建”一个包装好插入数据的Entry对象。(这里不是说真创建了一个对象,而是将那个位置的Entry属性的key,hashCode,value值改为待插入数据的属性)
- _buckets[index] 指向 _entries[count]处,插入完成
上面步骤对应的源码部分如下:
private bool TryInsert(TKey key, TValue value, InsertionBehavior behavior)
{
....
// 找到hashcode对应的Hash桶的位置
ref int bucket = ref _buckets[hashCode % _buckets.Length];
....
// 获得当前数组中的空闲位置
int count = _count;
// 如果位置不够,那么扩容
if (count == entries.Length)
{
Resize();
bucket = ref _buckets[hashCode % _buckets.Length];
}
index = count;
_count = count + 1;
entries = _entries;
....
// 目标Entry
ref Entry entry = ref entries[index];
....
// 将该处空闲的Entry的属性改完插入数据的属性
entry.hashCode = hashCode;
// Value in _buckets is 1-based
entry.next = bucket - 1;
entry.key = key;
entry.value = value;
// Value in _buckets is 1-based
bucket = index + 1;
_version++;
....
}
在前面插入的步骤中,我们可以看到内部变量freeList和freeCount并没有发生变动,这是因为他们是跟删除操作(remove)息息相关的,后面讲讲。
效率分析
根据上面的操作,可以看出Dictionary中,插入一个数据的时间是常数时间,即时间复杂度O(1)。
字典中的Find方法实现细节与效率分析
以上面插入完三个数据的Dictionary为例,下面讲讲Find方法的实现细节和效率。
该Dictionary的内部结构如下所示:
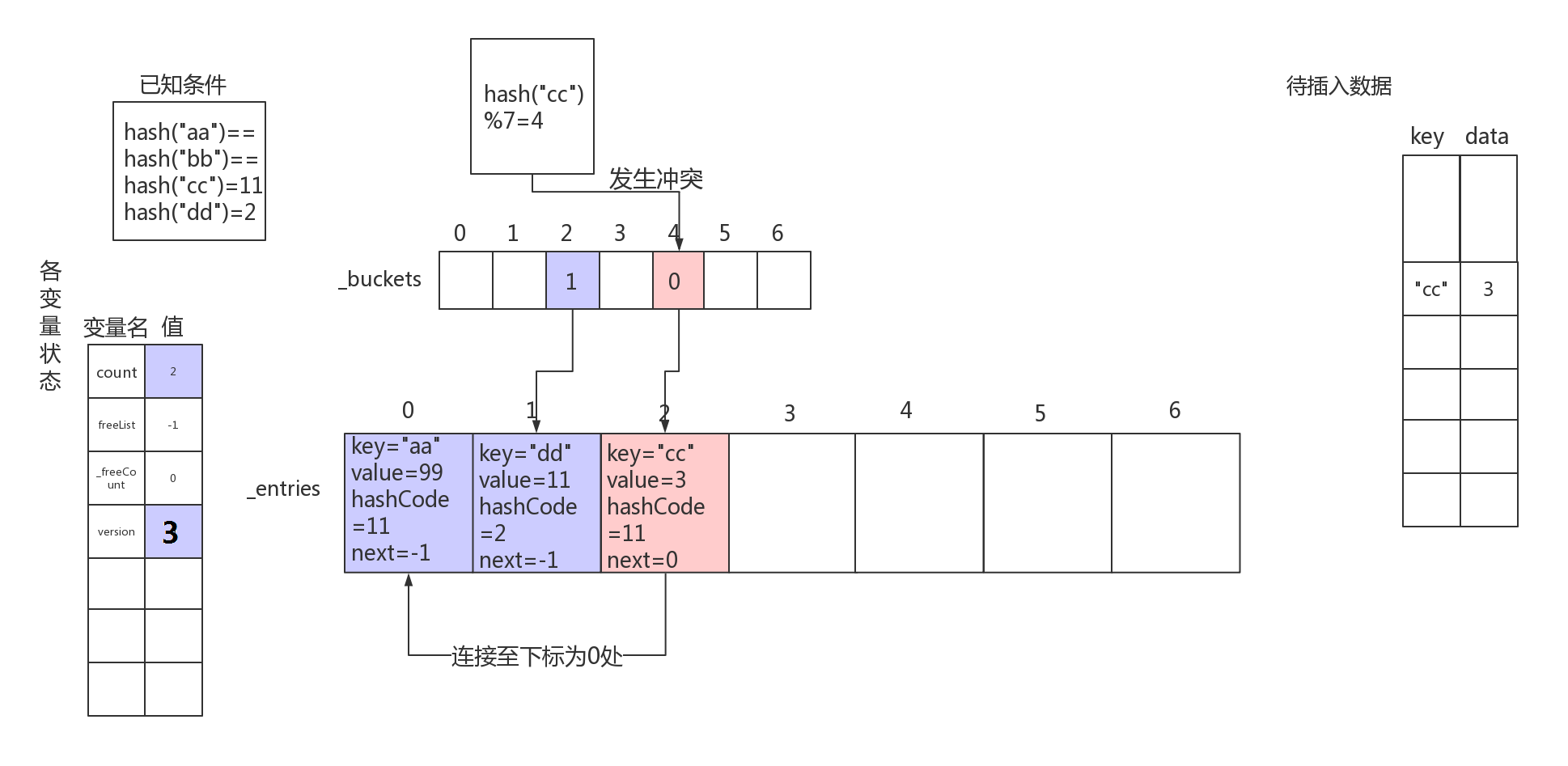
假设现在我们执行类似
map["aa"]
的操作,要获取键为"aa"存储的数据,会经过如下步骤:
- 计算key的Hash值,并算出在Hash桶的位置,即 hash("aa") % length
- 到达该Hash桶后,沿着这个Entry的next方法一路用"aa" == entry.key?比较过去。这里表达的意思是,一直沿着这个单链表向前找,直到找到key值相同的Entry,那么这个Entry保存的数据就是我们要找的值。
在Dictionary中还有一个常见的方法是GetValueOrDefault(),这个方法与上面步骤不同的地方是当沿着单链表一直找不到对应键值且entry.next==-1时,就会返回默认值。
效率分析
根据以上操作,很显然查找时间也是常数时间,也就是时间复杂度O(1),但是这个时间会随着Dictionary内部冲突的变多而增大,当所有元素冲突到一起时,每次查找都要消耗O(N)的时间。
为了解决这个问题,Dictionary内部会在合适的时候进行扩容并更换Hash函数。
字典中的Remove方法实现细节与效率分析
老实说我比较少用到字典的Remove方法额(汗颜),关于Remove方法,前面的步骤和查找是类似的。即先找到当前数据对应的Hash桶位置(不如说增删改查中查是最核心的,因为增删改第一个操作都是查)。
后面的步骤的执行如下带注释的代码所示。(代码引用自@InCerry的博文《浅析C# Dictionary实现原理》)
public bool Remove(TKey key) {
if(key == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
if (buckets != null) {
// 1. 通过key获取hashCode
int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF;
// 2. 取余获取bucket位置
int bucket = hashCode % buckets.Length;
// last用于确定是否当前bucket的单链表中最后一个元素
int last = -1;
// 3. 遍历bucket对应的单链表
for (int i = buckets[bucket]; i >= 0; last = i, i = entries[i].next) {
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) {
// 4. 找到元素后,如果last< 0,代表当前是bucket中最后一个元素,那么直接让bucket内下标赋值为 entries[i].next即可
if (last < 0) {
buckets[bucket] = entries[i].next;
}
else {
// 4.1 last不小于0,代表当前元素处于bucket单链表中间位置,需要将该元素的头结点和尾节点相连起来,防止链表中断
entries[last].next = entries[i].next;
}
// 5. 将Entry结构体内数据初始化
entries[i].hashCode = -1;
// 5.1 建立freeList单链表
entries[i].next = freeList;
entries[i].key = default(TKey);
entries[i].value = default(TValue);
// *6. 关键的代码,freeList等于当前的entry位置,下一次Add元素会优先Add到该位置
freeList = i;
freeCount++;
// 7. 版本号+1
version++;
return true;
}
}
}
return false;
}
总结一下,删除操作就是如下步骤:
- 找到目标Entry
- 将Entry初始化(HashCode初始化为-1)
- 将这个空闲的Entry(因为数据被删了,所以空闲)插入到Dictionary内部维护的freeList单链表中(entries[i].next=freeList这一句),等待下一次插入数据时,先找到这个freeList中的Entry来插。
效率分析
根据上面代码所示,Remove操作主要消耗时间的还是查找这一块,它的时间复杂度和查找相同,为O(1),但随着冲突的增多查找时间会逐渐加大。
字典何时扩容
Dictionary内部实际上是维护了两个数组对数据进行保存,既然是数组,那么自然会有数组放满的风险,根据前面的Add方法源码的分析,可以看到其中有一行当count(空闲位置)== hash桶长度时,会进行扩容操作。
这是扩容比较直观的触发条件。在另外一种情况下Dictionary也会触发扩容,这就是当碰撞次数过多时,它会自动扩容。
那么什么是碰撞呢?
在FindEntry方法中,当我们沿着同类冲突元素的单链表一直找下去的时候,每遍历一个元素,碰撞次数collisionCount就+1,当碰撞次数超过设定好的阈值时,就会触发扩容。
FindEntry方法源码中触发碰撞的代码:
private int FindEntry(TKey key)
{
....
// 碰撞次数
int collisionCount = 0;
...
do
{
if ((uint)i >= (uint)entries.Length || (entries[i].hashCode == hashCode && EqualityComparer<TKey>.Default.Equals(entries[i].key, key)))
{
break;
}
i = entries[i].next;
if (collisionCount >= entries.Length)
{
ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
}
// 在遍历这个单链表的时候,每查找失败一次,碰撞次数+1
collisionCount++;
} while (true);
...
}
很显然这个碰撞次数就关系到了我们前面说的查找方法的消耗时间,所以当碰撞次数超过阈值,Dictionary就自动扩容了,并且在扩容后还会使用新的Hash函数来进行HashCode值。
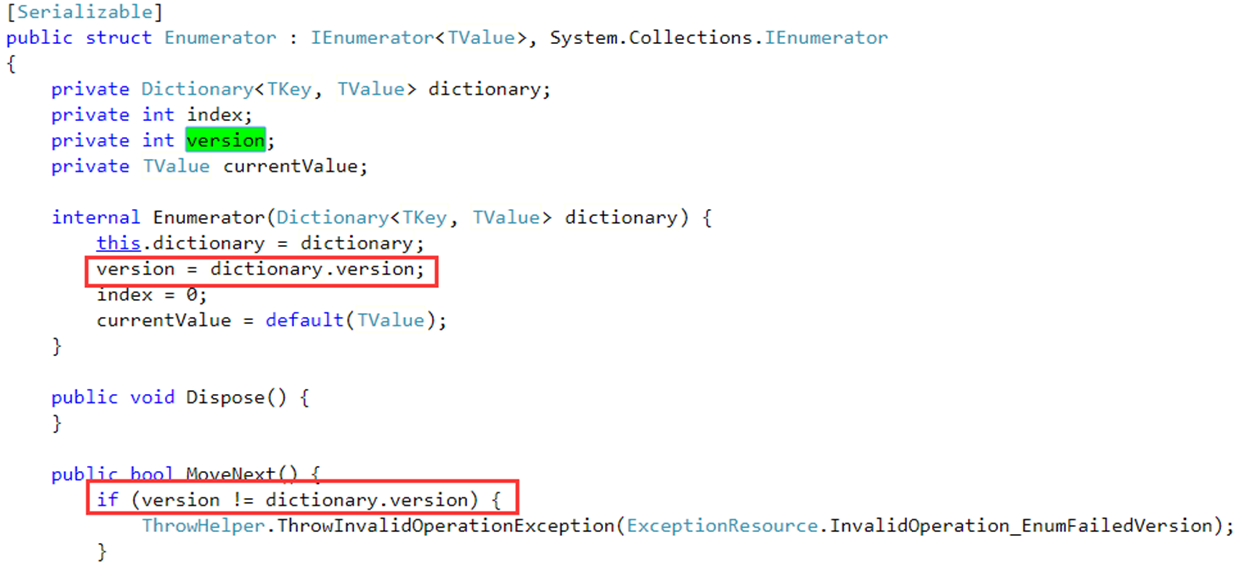
version(版本)和迭代的关系
在C#中,增、删、改操作都会使得Dictionary中的version(版本)变量改变。
这里依旧引用一下@InCerry大大的博文对于这个的解释。
迭代过程中不允许集合出现变化。如果在Java中遍历直接删除元素,会出现诡异的问题,所以.Net中就使用了version来实现版本控制。
那么如何在迭代过程中实现版本控制的呢?我们看一看源码就很清楚的知道。
在迭代器初始化时,就会记录dictionary.version版本号,之后每一次迭代过程都会检查版本号是否一致,如果不一致将抛出异常。
Dictionary的增删查改效率如何?
经过上面的分析,我们就可以知道Dictionary的增删改查效率了,列表如下:
| 数据结构 | Add | Remove | Find | Alter |
|---|---|---|---|---|
| Dictionary | O(1) | O(1) | O(1) | O(1) |
可以看到字典这个数据结构还是相当给力的,基本的操作流程基本都是O(1)的复杂度,不过它会消耗更多的空间就是了(毕竟使用了两个数组进行维护)。
总结
这篇博文也是写的相当久,因为我基础不是很牢固,一开始写这个系列的就是为了巩固下C#基础,所以可能出现了一些错误,如果有读者看到,还请不吝指出,我会非常感激的。(话说上一篇String和StringBuilder的错误还没改。。懒癌发作。。)
本篇文章后半段关于Dictionary的部分大部分是参考@InCerry的博文【浅析C# Dictionary实现原理】(讲的相当清楚)所写的,emmmm,如果有什么版权方面的问题,请联系我,我会立即删除这篇文章。
C#基础复习(4) 之 浅析List、Dictionary的更多相关文章
- 《CSS权威指南》基础复习+查漏补缺
前几天被朋友问到几个CSS问题,讲道理么,接触CSS是从大一开始的,也算有3年半了,总是觉得自己对css算是熟悉的了.然而还是被几个问题弄的"一脸懵逼"... 然后又是刚入职新公司 ...
- Java基础复习笔记系列 九 网络编程
Java基础复习笔记系列之 网络编程 学习资料参考: 1.http://www.icoolxue.com/ 2. 1.网络编程的基础概念. TCP/IP协议:Socket编程:IP地址. 中国和美国之 ...
- Java基础复习笔记系列 八 多线程编程
Java基础复习笔记系列之 多线程编程 参考地址: http://blog.csdn.net/xuweilinjijis/article/details/8878649 今天的故事,让我们从上面这个图 ...
- Java基础复习笔记系列 七 IO操作
Java基础复习笔记系列之 IO操作 我们说的出入,都是站在程序的角度来说的.FileInputStream是读入数据.?????? 1.流是什么东西? 这章的理解的关键是:形象思维.一个管道插入了一 ...
- Java基础复习笔记系列 五 常用类
Java基础复习笔记系列之 常用类 1.String类介绍. 首先看类所属的包:java.lang.String类. 再看它的构造方法: 2. String s1 = “hello”: String ...
- Java基础复习笔记系列 四 数组
Java基础复习笔记系列之 数组 1.数组初步介绍? Java中的数组是引用类型,不可以直接分配在栈上.不同于C(在Java中,除了基础数据类型外,所有的类型都是引用类型.) Java中的数组在申明时 ...
- C#基础课程之五集合(HashTable,Dictionary)
HashTable例子: #region HashTable #region Add Hashtable hashTable = new Hashtable(); Hashtable hashTabl ...
- C语言基础复习总结
C语言基础复习总结 大一学的C++,不过后来一直没用,大多还给老师了,最近看传智李明杰老师的ios课程的C语言入门部分,用了一周,每晚上看大概两小时左右,效果真是顶一学期的课,也许是因为有开发经验吧, ...
- JS基础 复习: Javascript的书写位置
爱创课堂JS基础 复习: Javascript的书写位置复习 js书写位置:body标签的最底部.实际工作中使用书写在head标签内一对script标签里.alert()弹出框.console.log ...
随机推荐
- cocos jsb工程转html 工程
1 CCBoot.js prepare方法:注掉下面这行,先加载moduleConfig中的脚本后加载user脚本 //newJsList = newJsList.concat(jsList); // ...
- is not allowed to connect to this MySQL server解决办法
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION; myuser:代表你 ...
- js 文件下载 进度条
js: /** * 下载文件 - 带进度监控 * @param url: 文件请求路径 * @param params: 请求参数 * @param name: 保存的文件名 * @param pro ...
- Python 语法糖装饰器的应用
Python中的装饰器是你进入Python大门的一道坎,不管你跨不跨过去它都在那里. 为什么需要装饰器 我们假设你的程序实现了say_hello()和say_goodbye()两个函数. def sa ...
- 2018.12.22 bzoj3473: 字符串(后缀自动机+启发式合并)
传送门 调代码调的我怀疑人生. 启发式合并用迭代写怎么都跑不过(雾 换成了dfsdfsdfs版本的终于过了233. 题意简述:求给出nnn个字串,对于每个给定的字串求出其有多少个字串在至少kkk个剩下 ...
- poj-3067(树状数组)
题目链接:传送门 题意:日本有东城m个城市,西城m个城市,东城与西城相互连线架桥,判断这些桥相交的次数. 思路:两个直线相交就是(x1-x2)*(y1-y2)<0,所以,对x,y进行排序,按照x ...
- springboot深入学习(二)-----profile配置、运行原理、web开发
一.profile配置 通常企业级应用都会区分开发环境.测试环境以及生产环境等等.spring提供了全局profile配置的方式,使得在不同环境下使用不同的applicaiton.properties ...
- opencv知识积累
1.OpenCV 3计算机视觉:Python语言实现 https://github.com/techfort/pycv 2.OpenCV3编程入门 opencv 均值模糊:一般用来处理图像的随机噪声 ...
- CSS Sprites (CSS 精灵) 技术
CSS Sprites在国内很多人叫css精灵,是一种网页图片应用处理方式.它允许你将一个页面涉及到的所有零星图片都包含到一张大图中去,这样一来,当访问该页面时,载入的图片就不会像以前那样一幅一幅地慢 ...
- ibatis注意要点
一.ibatis的关键字like查询 select * from t_student where s_name '%张%'; 这种like语句在ibatis中怎么写,他们现在的项目是用ibatis作为 ...