day41
今日内容:
1.完整查询语句
2.多表查询
3.子查询
1.完整查询语句:
首先对于昨天的学习补充一个复制表
示例:首先我在一个库中创建了一个t1表(id 为int类型 设置为主键 并且设置了自增描述auto_increment,然后是一个name字段 类型char(5))
然后我通过复制表的语句来实现了t2的创建:create table t2 select * from t1;
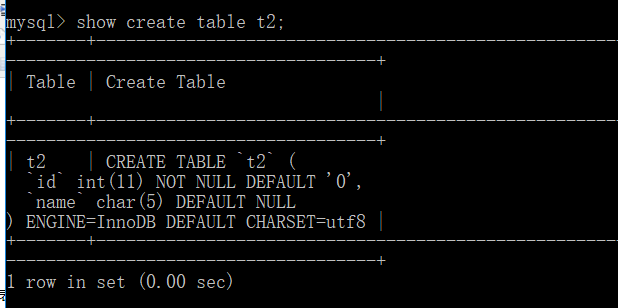
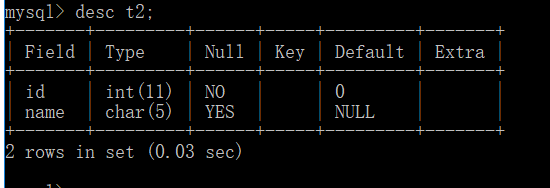
可以看出来我们复制的这个表没有复制到t1的描述和主键,只能赋值t1表的基本结构
接下来我开始总结今天所学的第一个知识点:
1.增:语句
(1)insert into 表名 字段名 字段名... value/values(字段值);
into 可省略,字段名(可选,如果写了字段名后面的值必须与写的字段名匹配起来,不写后面的值必须和表的结构完全匹配)
value 插入一条记录/values 插入多条记录
2.改:语句
update 表名 set 字段名 = 新值,字段名n =新值n where 条件
可以同时修改多个字段 用逗号隔开 (注意:最后一个字段不用加都好)
where 可选(有:满足修改条件的记录,无:全部修改)
3.删:语句
delete from 表名 where 条件
where 可选 (有:删除满足条件的记录,无:全部删除)
如果你想全部删除,建议使用“truncate table 表名” (因为delete关键字是通过逐行对比,然后进行删除,效率低)
4.查:语句
select distinct {看情况选择写:*|字段名|聚合函数|表达式} from 表名
where 条件 group by 字段名 having 条件 order by 字段名 limit 显示的条数
注:关键字的顺序必须与上述语法一致(并非所有都要用到,看情况选择用)
这里我先介绍一下简单查询:
1.*表示所有列都显示,也可以手动指定要显示的列,可以是多个
2.distinct:用于去除重复的记录,只取出完全相同的记录,当然你也可以手动指定要显示的列从而来去重
3.表达式 支持四则运算
然后我们需要记住其执行顺序:
select()
from()#相当于打开文件 ==》where #读取每一行并进行条件判断==》group#对数据进行分组==》having==》having#对分组后的数据再进行过滤==》distinct#去重==》order #排序==》limit #限制显示的记录数
示例:
select * from t1;#查看全部数据

select * from t1 where name = "xxx" or name = "yyy";#设置条件查看到了满足我们条件的数据

select id,distinct(name) from t1;#distintct:去重作用

select * from t1 group by name;#根据名字进行分组(虽然这个例子不太恰当 0.0)

select * from t1 group by name having id >3;#对分组后的数据进行过滤(注:特别注意 having 是用于过滤分组后的数据,也就是说没有gruop by 就没有 having)
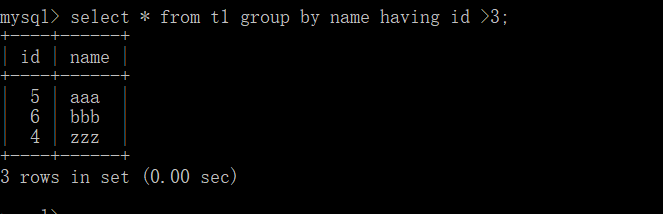
select * from t1 group by name having id >3 order by id;#对于分组过滤后的数据再按照其id进行升序(注:降序就在后面加desc)

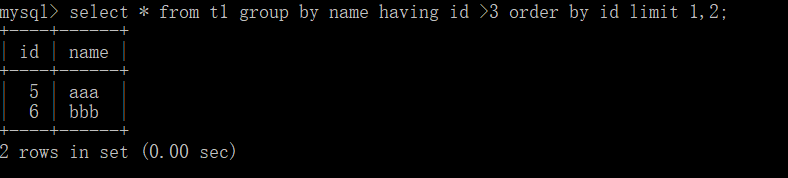
select * from t1 group by name having id >3 order by id limit 1,2;
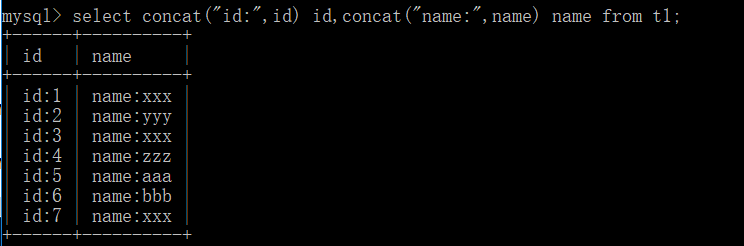
select concat("id:",id) id,concat("name:",name) name from t1;
#这里有两个点需要学习
1.首先concat 这个关键字用来字符串拼接
2.concat("id:",id) id :注意这句话我又加了一个id 这个的意思就是给这个字段名取别名,若不加这个显示的字段名会是concat("id:",id)
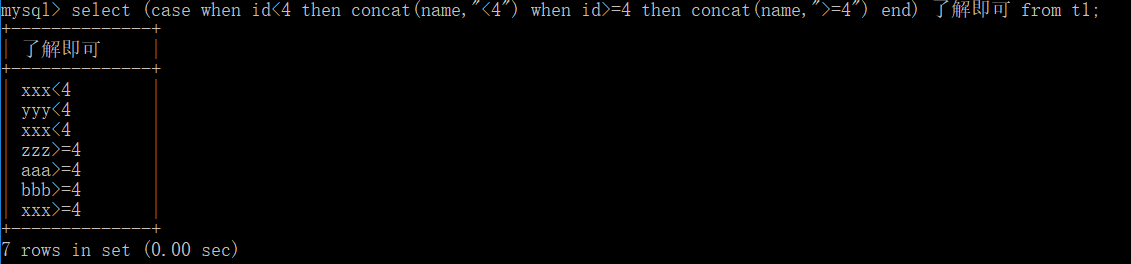
select (case when id<4 then concat(name,"<4") when id>=4 then concat(name,">=4") end) 了解即可 from t1;
了解即可,自行理解
where 关键字
介绍:从硬盘上读取数据时的一个过滤条件
where的筛选过程:在没有索引的情况下,逐个比较,效率低(应该给表加索引提高其效率)
group by关键字
介绍:用于数据分组
1.更加方便的管理数据
2.更加方便的统计
用一个更加贴切的例子来举例group by 的使用,并介绍一下聚合函数:
表格数据:
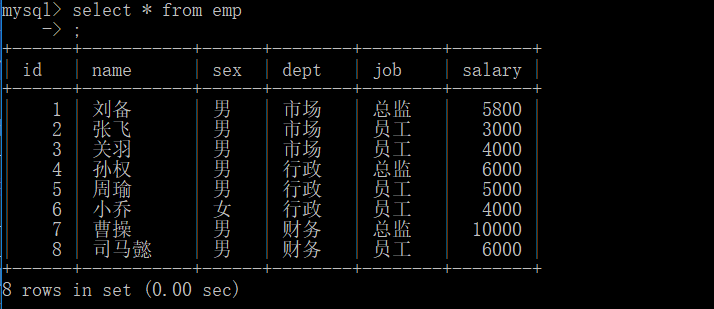
create table emp (id int,name char(10),sex char,dept char(10),job char(10),salary double);
insert into emp values (1,"刘备","男","市场","总监",5800),
(2,"张飞","男","市场","员工",3000),
(3,"关羽","男","市场","员工",4000),
(4,"孙权","男","行政","总监",6000),
(5,"周瑜","男","行政","员工",5000),
(6,"小乔","女","行政","员工",4000),
(7,"曹操","男","财务","总监",10000),
(8,"司马懿","男","财务","员工",6000);
select *from emp group by dept;按照部门给数据分组

其实这个语句有两种情况
1.sql_mode中 没有设置 ONLY_FULL_GROUP_BY 显示每个组的第一条记录 没有意义 所以新版中 自带ONLY_FULL_GROUP_BY
2.sql_mode中有设置 ONLY_FULL_GROUP_BY 直接报错
原因是: * 表示所有字段都要显示 但是 分组后 记录的细节被隐藏 只留下了
这意味着:只有出现在group by 后面的字段才能被显示
聚合函数:
将一堆数据经过计算,得到一个数据
sum()求和
avg()求平均数
max()/min() 最大值/最小值
count()计数
示例
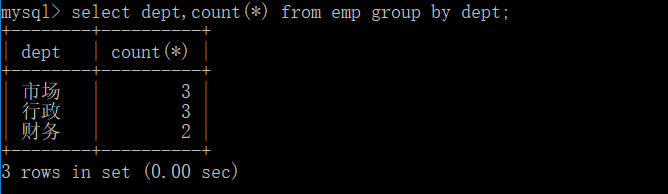
select dept,count(*) from emp group by dept;
select dept,avg(salary) from emp group by dept;
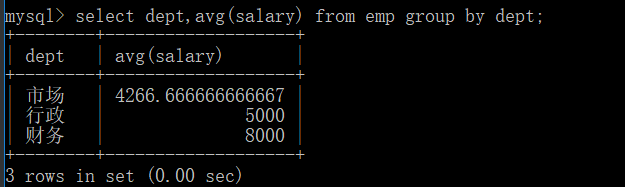
select dept,avg(salary) avg_salary from emp group by dept having avg_salary>5000;

having 关键字
介绍:用于对分组后的数据进行过滤
having不会单独出现 都是和group by一起出现
与where比较:
相同点:都用于数据过滤
不同点:
1.where是最先执行的,用于读取硬盘数据,而having 要等到数据读取完后,才能进行过滤,比where晚执行
1.where中不能使用聚合函数,having可以
order by 关键字:
介绍:用于对记录进行排序
desc降序
asc升序
默认为升序
limit 关键字:
介绍:用于限制显示记录数
limit n,m#n指的是从第几行的后一行开始显示,m指的是显示几行
常用于分页显示
2.多表查询
多表查询:
介绍:在多个表中查询需要的数据
例如:有学生表和班级表
给你一个班级名称,让你查询所有学生的数据
首先我们应该先查班级表 得到一个班级id 再根据id去学生表查询对应的学生
多表查询的方式
1.笛卡尔积查询
什么是笛卡尔积,用坐标中的一条记录 去链接另一张表的所有记录
就像是把 两张表的数据做了一个乘法
这将导致 产生大量的无用重复数据
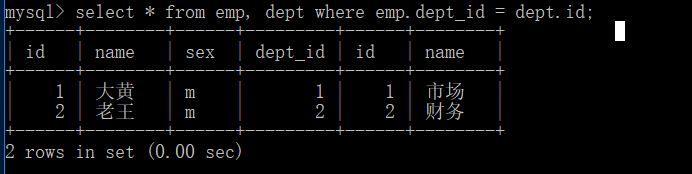
我们要的效果是:员工表中的部门id 与 部门表中的id相同 就拼接在一起
准备实例的数据:
insert emp values(1,"大黄","m",1);
insert emp values(2,"老王","m",2);
insert emp values(3,"老李","w",30);
insert dept values(1,"市场");
insert dept values(2,"财务");
insert dept values(3,"行政");

select * from emp,dept where emp.dept_id = dept.id;
on 关键字:作用于多表查询,为其进行条件限制,它只能用在专门多表查询语句中
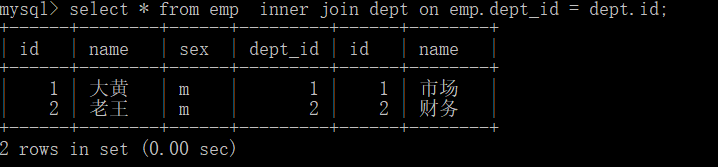
inner join:内连接查询
select * from emp inner join dept on emp.dept_id = dept.id;
left join :左连接查询,左边表中的数据完全显示,右边表中的数据匹配上才显示
select * from emp left join dept on emp.dept_id = dept.id;

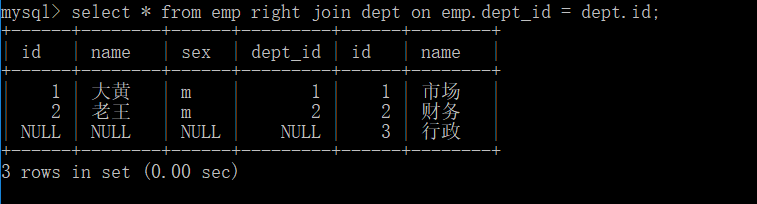
right join:有链接查询,右边表中的数据完全显示,左边表中的数据匹配上才显示
select * from emp right join dept on emp.dept_id = dept.id;
全外连接:
full join mysql不支持 oracle支持
通过 union 间接实现
union 表示合并查询 意思是把多个查询结果合并在一起显示,要求是被合并的表结构必须相同,默认去除重复
union all 合并但是不去除重复
select * from emp left join dept on emp.dept_id = dept.id
union
select * from emp right join dept on emp.dept_id = dept.id;
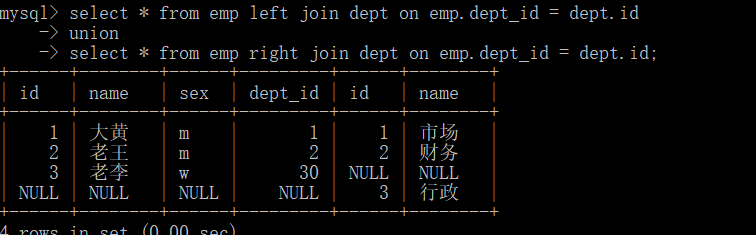
总结:多表链接 在书写时 按照填空来书写 如果左边要全部显示 用left join
右边全部显示 用right join
全部显示 把左链接的结果和右链接的结果 合并
当然 也可以更多表一起查 但是 没有意义 并且你要尽量避免 太多表 一起查
最多三张 在多对多的时候
3.子查询
1:子查询是将一个查询语句嵌套在另一个查询语句中。
2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 4:还可以包含比较运算符:= 、 !=、> 、<等
带IN关键字的子查询
查询平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25); 查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术'); 查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from employee);
带比较运算符的子查询
比较运算符:=、!=、>、>=、<、<=、<>
查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec) 查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。True或False,当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询。
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+ #department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)
day41的更多相关文章
- day41——数值类型、完整性约束
day41 数值类型 整数类型 有符号的设置 mysql> create table t1(id tinyint); # 默认有符号,即数字前有正负号 无符号的设置 mysql> crea ...
- Python:Day41 http、css
HTTP(hypertext transport protocol),即超文本传输协议.这个协议详细规定了浏览器和万维网服务器之间互相通信的规则. 2.请求协议 请求协议的格式如下: 请求首行: // ...
- day41 mycql 函数
一些经典的练习题,以及函数的简单用法,內建函数 -- 函数 python函数 def fun1(a1,a2,a3): sum = a1+a2+a3 return sum fun1(1,2,3) jav ...
- day41 mysql详细操作
复习 create table 表名( id int primary key auto_increment, 字段名 数据类型[(宽度) 约束] )engine=innodb charset=utf8 ...
- python 全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python 理论知识,线程的创建)
昨日内容回顾 队列 队列 : 先进先出.数据进程安全 队列实现方式: 管道 + 锁 生产者消费者模型 : 解决数据供需不平衡 管道 双向通信 数据进程不安全 EOFError: 管道是由操作系统进行引 ...
- day41 mysql 学习 练习题 重要*****
MySQL 练习题[二1.表如下: 收获和注意点:***** #1 GROUP by 可以放到where s_id in ()条件局后边 GROUP BY s_id having 详见题12 #2 做 ...
- day41 python【事物 】【数据库锁】
MySQL[五] [事物 ][数据库锁] 1.数据库事物 1. 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性 ...
- Day41 openstack基础
参考博客: http://www.cnblogs.com/linhaifeng/p/6264636.html
- day41 - 异步IO、协程
目录 (见右侧目录栏导航) - 1. 前言- 2. IO的五种模型- 3. 协程 - 3.1 协程的概念- 4. Gevent 模块 - 4.1 gevent 基本使用 - 4.2 ...
随机推荐
- js-ES6学习笔记-变量的解构赋值
1.ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring). 2.ES6允许写成:let [a,b,c] = [1,2,3];上面代码表示,可以从数 ...
- JS写的二级导航栏(利用冒泡原理)
今天给大家分享一种用JS写的导航栏,虽然我们工作中不会使用JS来做导航栏,为了练习我们用JS来做一个JS导航栏 这种方法要比其他方法代码量少很多,但是需要对事件冒泡有一定的理解,如果需要理解冒泡可以参 ...
- css选取table元素的第一列
table tr td:first-child
- 前端开发笔记(1)html基础
HTML介绍 HTML是HyperTextMarkupLanguage超文本标记语言的缩写 HTML是标记语意的语言 编辑器 任何纯文本编辑器都能够编辑html,比如记事本,editplus,note ...
- FileWriter剖析
集合这种容器存储数据,它只能在内存中临时存储,不能永久存储,这样会导致数据的丢失,所以出现了IO流. IO流用来处理设备之间的数据传输.可以用来做复制文件,上传文件,下载文件. 读数据是输入流,写数据 ...
- RecyclerView打造通用的万能Adapter
既然想做到通用那么现在摆在面前的就三个问题:数据怎么办?布局怎么办? 绑定怎么办?.数据决定采用泛型,布局打算直接构造传递,绑定显示效果肯定就只能回传. 1 基本改造 数据决定采用泛型,布局打算直接构 ...
- Expo大作战(二十二)--expo分离后的部署(expokit)
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- 有关于《Linux C编程一站式学习》(备份)
Linux C编程一站式学习 -- PDF版本,共37章: Linux C编程一站式学习 -- 在线版,来自灰狐: Linux C编程一站式学习 -- 在线版,来自亚嵌教育: Linux C一站式学习 ...
- .NET Dispose模式的实现
以下是代码: /// <summary> /// Dispose Pattern /// </summary> /// <remarks> /// 由逻辑可知: / ...
- Postsharp基本用法——方法、属性拦截与异常处理
以下Demo代码基于 .NET Core 演示了Postsharp的基本使用方法,稍作修改(反射部分有些许差异)也适用于.NET Framework. 更多高级使用方法详见官方文档.http://sa ...