spm
看了很多关于SPM的介绍,但是网络上的资源大多都是对论文Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories的直接翻译,关于自己的理解谈得很少。这里主要写一下在我看了SPM论文和其提供的代码之后的感想。
SPM,一般中文翻译为空间金字塔,主要是计算机视觉中对图片的一种特征提取的方式. SPM的主要思想为:将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征 拼接起来,形成完整的特征。这就是SPM中的Spatial。在分块的细节上,作者采用了一种多尺度的分块方法,即分块的粒度越大越细 (increasingly fine),呈现出一种层次金字塔的结构,这就是SPM中的Pyramid。
如果细心分析代码那么可以看到,代码主要分为4步来完成,分别对应一个function。
- GenerateSiftDescriptors:
该函数主要是来产生Sift特征,主要需要注意的是它将每一张图片分为了多个patch,这样对每个patch计算Sift特征,最后得到一个多维特征向量。在作者提供的Example中,一张图片480*640,那么对于16*16的patch,gridspacing为8,grid数量为(480/8-1)*(640/8-1)=4661那么可以得到的sift特征数量为4661,每个特征维度为128.
- CalculateDictionary
该函数很简单,就是将刚得到的特征用k-means的方法找到指定size的字典,这里指定的字典size=200或400.那么后面的每张图片的每个sift特征就可以用该字典来表示了,直接去字典里面找和该sift特征最接近的word,直接用index来表示,这个可以用sp_dist2函数来实现。这里注意的是:字典是一个200*128的矩阵,也就是每一行代表着一个k-mean得到的中心sift特征。这个可以在Example跑完后的data文件夹下的dictionary_size(200或400).mat中看到。
- BuildHistograms
该函数在论文里面是没有提到的,它的主要功能在于将每张图片得到的特征(该特征存放在imagename_sift.mat文件中,矩阵为4661*128)转化为texton,该词的翻译为基元,也就是将每张图片中的每个grid产生的sift特征在字典中给对应起来得到一个4661*1的矩阵,该矩阵存放在imagename_texton_ind_size(200).mat文件中。
- CompilePyramid
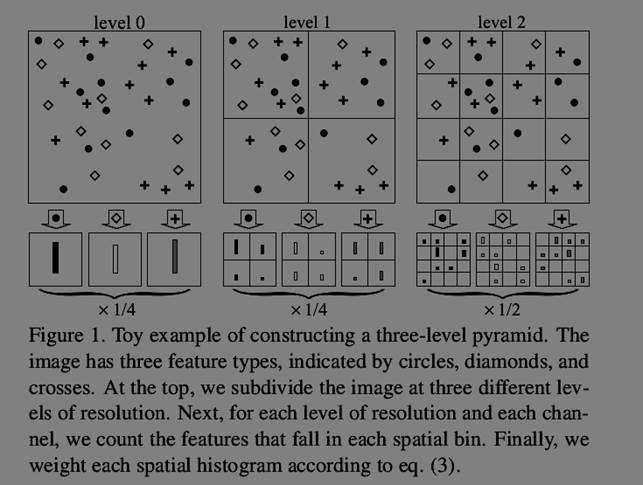
该函数是最后一步,也就是计算金字塔的步骤,在该函数中将图片按level来进行划分,也就是论文里面的那个图(如下),分了3层,层数l越大,则划分得越细,论文中有句话“More specifically, let us construct a sequence of grids
at resolutions 0, . . . , L, such that the grid at level l has 2 ^(l) cells along each dimension, for a total of D = 2^(dl) cells. ”,实际上意思是对于每层划分,
将图片按照行列的维度进行划分,l=2,则每行没列都做2^2=4个划分,也就是下图最右所示,则所有的cells也就是2^(2*2)=16,这里d=2,对于level l=0,1都是一样道理。做了这样的划分之后,首先计算的是划分最细的特征直方图,这里指的是level 2。那么这里对原图做了16patch的划分,然后计算刚才得到的texton中落在每个patch中的特征sift在词典中的index,多个sift所以形成了一个由index组合的向量,然后计算直方图,这里用hist函数来计算,主要是将词典中每个词也就是每个sift的index在刚得到的向量里面出现的次数得到一个直方图,该直方图是200维。那么对于16个patch都重复计算,最后得到的就是16个200维的直方图特征,所以对于level 2层最后将这些直方图连在一起,就是16*200维。
根据level 2的计算对level 1 ,0重复计算,不过由于粗粒度的特征计算包含了细粒度的计算,所以直接用level 2的计算结果就可以了,这部分代码比较简单,直接看代码就可以了。不过需要注意的是在代码中pyramid_cell这个变量的第一个cell实际上存放的是level 2的特征,是倒过来的。也就是pyramid_cell{1}存放4*4*200,pyramid_cell{2}存放的则是2*2*200,pyradmid{3}存放的则是1*1*200.
最后还有一步就是加权求整张图片级别的特征,这里的思想主要是细粒度的权重大,粗粒度的权重小,这里系数给的是2^(-l)(代码里给的,实际上对应论文里面的,这里l=1,2,3,刚好对应论文里面的2^(-(L-l))),不过这里需要注意的是对于l=3,权重系数为1-(1/2+1/4)=1/4,这是为了归一化。用该系数乘上每个patch得到的直方图特征,
将它们按照细粒度在前,粗粒度在后的顺序连在一起,形成一个4*4*200+2*2*200+1*1*200=4200维度的特征,这对应论文里面,这就是最后图片的特征描述。由于按照level来对图片进行划分,形成一个金字塔结构,所以叫空间金子塔结构。
- 最后
在论文里面还提到一些公式,如下
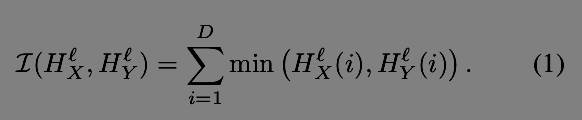
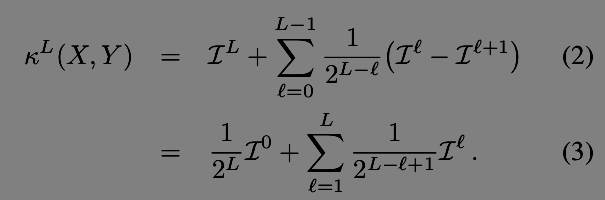
这几个公式主要用来估计相似度的,可以想象为给定两张图片,根据得到的Spm特征进行相似度估计,可以用欧式距离,这里给出了金字塔模型中的相似度估计方法。具体的做法在hist_isect函数中。在(1)中,该函数是一个直方图交集函数(histogram intersection function),对于每个grid产生的200维的直方图,也就是该grid中sift特征落在词典中每个bin的数量,对每个bin中的数量进行比较对小的求和,这就是直方图交集函数。实际代码中,就是先将一个直方图的等于0部分去掉也就是
nonzero_ind = find(x1(p,:)>0);
tmp_x1 = repmat(x1(p,nonzero_ind), [n 1]);
找到大于0部分的,(因为等于0的bin肯定是小的,加和没有意义,直接处理大于0部分就行),然后比较对应部分较小值求和就好。
K(p,:) = sum(min(tmp_x1,x2(:,nonzero_ind)),2)';
。
spm的更多相关文章
- 163邮箱问题:554 DT:SPM 163 smtp5,D9GowACHO7RNWNdXmXs1Bw--.9035S2
最近公司需要开发一个自定义邮箱功能,上网查询一下,利用163邮箱发送邮件. 由于163 的反垃圾机制,(坑爹机制.) 一般出现 554有在1)测试中用了test,测试,关键字在主题或者内容里面. 但是 ...
- 折腾一两天,终于学会使用grunt压缩合并混淆JS脚本,小激动,特意记录一下+spm一点意外收获
很长时间没有更新博客了,实在是太忙啦...0.0 ,以下的东西纯粹是记录,不是我原创,放到收藏夹还担心不够,这个以后常用,想来想去,还是放到这里吧,,丢不了..最后一句废话,网上搜集也好原创也罢,能解 ...
- https://yq.aliyun.com/articles/65125?spm=5176.100240.searchblog.18.afqQoU
https://yq.aliyun.com/articles/65125?spm=5176.100240.searchblog.18.afqQoU
- 利用SPM工具运行自己创建的小组件(使用common-model向后台接口请求数据)
步骤如下: 1.安装依赖:spm install -e 2.编译:spm build (编译好的东西会放在trunk-dist里面) 3.发布:spm app -d (会出来一个export端口,一般 ...
- 使用SPM创建新组件
(前提:已经安装好了spm) 步骤如下:
- notes:spm多重比较校正
SPM做完统计后,statistical table中的FDRc实际上是在该p-uncorrected下,可以令FDR-correcred p<=0.05的最小cluster中的voxel数目: ...
- GLM in SPM
主要记一句话: SPM的GLM模型中的β,指的是相应regressor对最后测量得到的信号所产生的效应(effect). 后续的假设检验过程实际上都是对各个regressor的β向量进行的. The ...
- SPM FDR校正
来源: http://blog.sciencenet.cn/blog-479412-572049.html,http://52brain.com/thread-15512-1-1.html SPM8允 ...
- SPM - data analysis
来源: SPM基本原理与使用PPT, 北师大,朱朝喆研究员,http://www.cnblogs.com/haore147/p/3633515.html ❤ First-level analysis: ...
- SPM paired t-test步骤
首先感谢大神空里流霜耐心的讲解,这篇笔记内容主要是整理他的谆谆教导,虽然他也看不到>< 所有数据都要经过平滑. Paired t-test虽然在2nd-level analysis中,但是 ...
随机推荐
- LeetCode 141. Linked List Cycle环形链表 (C++)
题目: Given a linked list, determine if it has a cycle in it. To represent a cycle in the given linked ...
- kafka学习总结之kafka核心
1. Kafka核心组件 (1)replication(副本).partition(分区) 一个topic可以有多个副本,副本的数量决定了有多少个broker存放写入的数据:副本是以partitio ...
- 《linux内核分析》第六周:分析fork函数对应的系统调用处理过程
一. 阅读理解task_struct数据结构http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235: 进程是 ...
- Activiti源码:ActivitiEventSupport类中eventListeners的设计
ActivitiEventSupport类成员eventListeners是使用CopyOnWriteArrayList实现的. public ActivitiEventSupport() { eve ...
- 关于“Scrum敏捷项目管理”
此次关于“Scrum”的名词解析,主要目的是为我们的“OneZero”团队确定项目开发的模式. http://www.cnblogs.com/taven/archive/2010/10/17/1853 ...
- OneZero第二周第五次站立会议(2016.4.1)
会议时间:2016年4月1日 会议成员:冉华,张敏,夏一鸣.(王请假). 会议目的:汇报前一天工作,会议成员评论. 会议内容: 1.前端,由夏,张负责汇报,完成前端功能,待命. 2.数据逻辑控制,由王 ...
- Delphi 模式窗体返回值ModalResult的使用方法及注意事项(转)
1.基础知识简介: ModalResult是指一个模式窗体(form.showmodal)的返回值,一般用于相应窗体上按钮的ModalResult属性: 显示完窗体(关闭)后,会返回此属性预设的值做为 ...
- 神奇的Redis延迟
最近在做某业务Redis的缩容工作,涉及到数据迁移,而Redis的数据迁移看起来蛮简单的,一对一的数据迁移只需要在slave行配置masterauth 和slaveof 两个参数即可,当然迁移过程中涉 ...
- MySQL -- 主从复制的可靠性与可用性
主库A执行完成一个事务, 写入binlog ,记为 T1 然后传给从库B,从库B 接收该binlog ,记为 T2 从库B执行完成这个事务,记为 T3 同步延时: T3-T1 同一个事务,在 从库执行 ...
- CF1110E Magic Stones(构造题)
这场CF怎么这么多构造题…… 题目链接:CF原网 洛谷 题目大意:给定两个长度为 $n$ 的序列 $c$ 和 $t$.每次我们可以对 $c_i(2\le i<n)$ 进行一次操作,也就是把 $c ...