LRU缓存原理
LRU(Least Recently Used) LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。
采用LRU算法的缓存有两种:LrhCache和DisLruCache,分别用于实现内存缓存和硬盘缓存,其核心思想都是LRU缓存算法。
1.LruCache的介绍
LruCache是个泛型类,主要算法原理是把最近使用的对象用强引用(即我们平常使用的对象引用方式)存储在 LinkedHashMap 中。当缓存满时,
把最近最少使用的对象从内存中移除,并提供了get和put方法来完成缓存的获取和添加操作。
2.LruCache的使用
LruCache的使用非常简单,我们就已图片缓存为例。
int maxMemory = (int) (Runtime.getRuntime().totalMemory()/1024);
int cacheSize = maxMemory/8;
mMemoryCache = new LruCache<String,Bitmap>(cacheSize){
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight()/1024;
}
};
①设置LruCache缓存的大小,一般为当前进程可用容量的1/8。
②重写sizeOf方法,计算出要缓存的每张图片的大小。
注意:缓存的总容量和每个缓存对象的大小所用单位要一致。
三、LruCache的实现原理
LruCache的核心思想很好理解,就是要维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,
即一直没访问的对象,将放在队首,即将被淘汰。而最近访问的对象将放在队头,最后被淘汰。
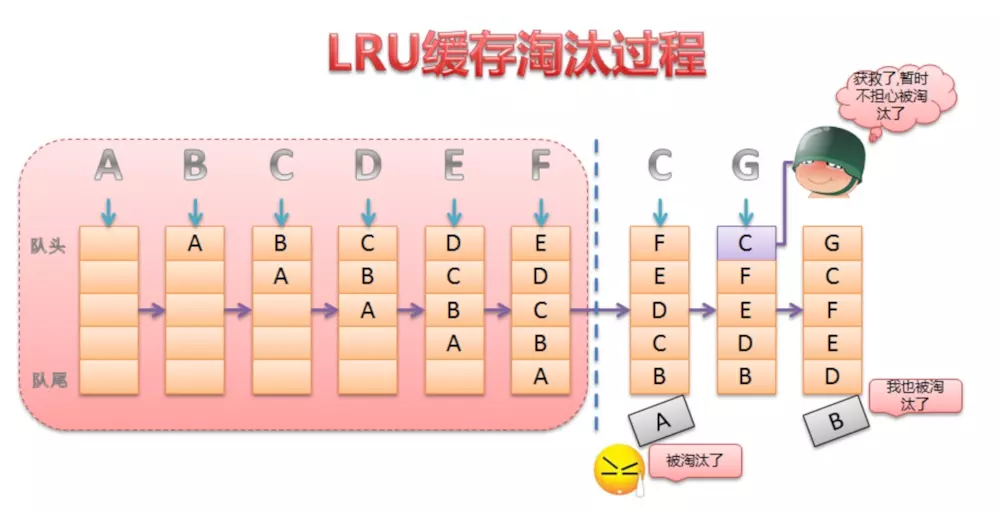
这个队列是由LinkedHashMap来维护。
LinkedHashMap是由数组+双向链表的数据结构来实现的。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
其中accessOrder设置为true则为访问顺序,为false,则为插入顺序。LruCache的构造函数中可以看到正是用了LinkedHashMap的访问顺序。
以具体例子解释:
当设置为true时
public static final void main(String[] args) {
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(0, 0.75f, true);
map.put(0, 0);
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
map.put(4, 4);
map.put(5, 5);
map.put(6, 6);
map.get(1);
map.get(2);
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
输出结果:
0:0
3:3
4:4
5:5
6:6
1:1
2:2
即最近访问的最后输出,那么这就正好满足的LRU缓存算法的思想。可见LruCache巧妙实现,就是利用了LinkedHashMap的这种数据结构。
下面我们在LruCache源码中具体看看,怎么应用LinkedHashMap来实现缓存的添加,获得和删除的。
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
从LruCache的构造函数中可以看到正是用了LinkedHashMap的访问顺序。
3.1 put() 方法
public final V put(K key, V value) {
//不可为空,否则抛出异常
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
//插入的缓存对象值加1
putCount++;
//增加已有缓存的大小
size += safeSizeOf(key, value);
//向map中加入缓存对象
previous = map.put(key, value);
//如果已有缓存对象,则缓存大小恢复到之前
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
//entryRemoved()是个空方法,可以自行实现
if (previous != null) {
entryRemoved(false, key, previous, value);
}
//调整缓存大小(关键方法)
trimToSize(maxSize);
return previous;
}
public void trimToSize(int maxSize) {
//死循环
while (true) {
K key;
V value;
synchronized (this) {
//如果map为空并且缓存size不等于0或者缓存size小于0,抛出异常
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//如果缓存大小size小于最大缓存,或者map为空,不需要再删除缓存对象,跳出循环
if (size <= maxSize || map.isEmpty()) {
break;
}
//迭代器获取第一个对象,即队尾的元素,近期最少访问的元素
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
//删除该对象,并更新缓存大小
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
trimToSize()方法不断地删除LinkedHashMap中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序。这个更新过程就是在LinkedHashMap中的get()方法中完成的。
3.2 get() 方法
public final V get(K key) {
//key为空抛出异常
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
//获取对应的缓存对象
//get()方法会实现将访问的元素更新到队列头部的功能
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
其中LinkedHashMap的get()方法如下:
public V get(Object key) {
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
//实现排序的关键方法
e.recordAccess(this);
return e.value;
}
recordAccess()方法如下:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//判断是否是访问排序
if (lm.accessOrder) {
lm.modCount++;
//删除此元素
remove();
//将此元素移动到队列的头部
addBefore(lm.header);
}
}
链接:https://www.jianshu.com/p/b49a111147ee
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
LRU缓存原理的更多相关文章
- LRU缓存实现(Java)
LRU Cache的LinkedHashMap实现 LRU Cache的链表+HashMap实现 LinkedHashMap的FIFO实现 调用示例 LRU是Least Recently Used 的 ...
- 转: LRU缓存介绍与实现 (Java)
引子: 我们平时总会有一个电话本记录所有朋友的电话,但是,如果有朋友经常联系,那些朋友的电话号码不用翻电话本我们也能记住,但是,如果长时间没有联系了,要再次联系那位朋友的时候,我们又不得不求助电话本, ...
- Java集合详解5:深入理解LinkedHashMap和LRU缓存
今天我们来深入探索一下LinkedHashMap的底层原理,并且使用linkedhashmap来实现LRU缓存. 摘要: HashMap和双向链表合二为一即是LinkedHashMap.所谓Linke ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- MyBatis:二级缓存原理分析
MyBatis从入门到放弃七:二级缓存原理分析 前言 说起mybatis的一级缓存和二级缓存我特意问了几个身边的朋友他们平时会不会用,结果没有一个人平时业务场景中用. 好吧,那我暂且用来学习源码吧.一 ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- 【转】MaBatis学习---源码分析MyBatis缓存原理
[原文]https://www.toutiao.com/i6594029178964673027/ 源码分析MyBatis缓存原理 1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 ...
- [转]LRU缓存实现(Java)
LRU Cache的LinkedHashMap实现 LRU Cache的链表+HashMap实现 LinkedHashMap的FIFO实现 调用示例 LRU是Least Recently Used 的 ...
- HashMap+双向链表手写LRU缓存算法/页面置换算法
import java.util.Hashtable; class DLinkedList { String key; //键 int value; //值 DLinkedList pre; //双向 ...
随机推荐
- 尚硅谷springboot学习22-Thymeleaf入门
Thymeleaf是一种模板引擎,类似于JSP.Velocity.Freemarker
- 3.SLB 回话保持功能分析
参考文档: 七层会话保持 配置服务器Cookie会话保持常见问题四层监听
- Nginx缓存配置以及nginx ngx_cache_purge模块的使用
web缓存位于内容源Web服务器和客户端之间,当用户访问一个URL时,Web缓存服务器会去后端Web源服务器取回要输出的内容,然后,当下一个请求到来时,如果访问的是相同的URL,Web缓存服务器直接输 ...
- Mysql数据库如何创建用户
创建test用户,密码是1234. MySQL u root -p CREATE USER 'test'@'localhost' IDENTIFIED BY '1234'; #本地登录 CREATE ...
- idea2017授权
http://blog.csdn.net/qq_27686779/article/details/78870816 文章中注册码: BIG3CLIK6F-eyJsaWNlbnNlSWQiOiJCSUc ...
- shiro 密码的MD5盐值加密
- Running Your Application
在运行你的第一个app前,您先要了解以下文件: 1.AndroidManifest.xml:Android的基本配置信息: <uses-sdk> element:app兼容版本信息: ex ...
- ssh问题:ssh_exchange_identification: Connection closed by remote host
ssh问题:ssh_exchange_identification: Connection closed by remote host... 刚刚一个朋友告诉我SSH连接不上服务器了,重启电脑也不管用 ...
- QQ传文件测试要点
总-分-总 UI: 进度:进度条.百分比.速度.已传文件大小 显示传送文件图标.悬浮有文字 功能入口:图标.菜单项 各种提示:开始传送.各种异常信息的提示.传送结束 给好友传文件.给群传文件 功能 ...
- Java反射、动态加载(将java类名、方法、方法参数当做参数传递,执行方法)
需求:将java类名.方法.方法参数当做参数传递,执行方法.可以用java的动态加载实现 反射的过程如下: 第一步:通过反射找到类并创建实例(classname为要实例化的类名,由pack ...