OHEM
样本不平衡问题
如在二分类中正负样本比例存在较大差距,导致模型的预测偏向某一类别。如果正样本占据1%,而负样本占据99%,那么模型只需要对所有样本输出预测为负样本,那么模型轻松可以达到99%的正确率。一般此时需使用其他度量标准来判断模型性能。比如召回率ReCall(查全率:样本中所有标记为正样本的有多少被模型预测为正样本)。
从数据层解决办法:
1、欠采样(undersampling):将模型中类别较多的样例除去一些,使类别样本数量平衡。但此法由于除去一些样本,导致丢失许多信息。一种改进办法是EasyEnsemble,将数量多的类别分成几份,分别与少数类别组合,形成N份数据集。从全局上看信息没有丢失。还有one-sided selection;data decontamination
2、过采样(oversampling):增加数量少的类别样本。简单方法使用直接复制、数据增强、添加噪声等。典型算法是SMOTE 算法:通过对少数样本进行插值来获取新样本的。一般过采样的效果要好于前采样。推荐了解:Synthetic Minority Over-sampling Technique(SMOTE:在样本和其相邻的样本之间产生一个样本) ;Ranked Minority Over-sampling (RAMO:通过判断样本周围正负样本的比例来判断其难分程度,根据权重生成少类数据集,再使用SMOTE生成样本);Random Balance (RB:在数据集数量相同的情况下,随机设置正负比例率,生成一堆不平衡数据集);Cluster-based oversampling;DataBoost-IM;class-aware sampling
从模型层解决办法:
1、阈值移动:在二分类中,若 y/(1-y) > 1,则预测为正例。然而只有当样本中正反比例为1:1时,阈值设置为0.5才是合理的。对于样本不平衡(m+ 代表正例个数, m- 代表负例个数),改进决策规则:若 y/(1-y) > (m+) / (m-) ,则预测为正例。因为训练集是总体样本的无偏采样,观测几率就代表真实几率,决策规则中 ( (m+) / (m-) ) 代表样本中正例的观测几率,只要分类器中的预测几率高于观测几率达到改进判定结果的目标。
2、代价敏感学习:在医疗中,“将病人误诊为健康人的代价”与“将健康人误诊为病人的代价”不同。通常,不同的代价被表示成为一个N×N的矩阵Cost中,其中N是类别的个数。Cost[i, j]表示将一个i 类的对象错分到j 类中的代价。代价敏感分类就是为不同类型的错误分配不同的代价,使得在分类时,高代价错误产生的数量和错误分类的代价总和最小。
其他方法:
1、One-class classification单分类,针对极端不平衡分类问题效果不错。
2、融合上述方法:EasyEnsemble ; BalanceCascade ;SMOTEBoost;two-phase
training(现在平衡数据集上预训练网络,然后在不平衡数据集上fine-tuning最后输出层)
更多信息
难分样本问题 Online Hard Example Mining,OHEM
个人感觉难分样本指的是模型对某个样本学习困难,难以学得其特征。而数据不平衡会导致某一类别在模型中学习迭代次数较少,逐渐成为一种难分样本。
一般解决办法:
1、focal loss:通过模型预测的概率pt,使用(1-Pt)来代表样本难分程度。可以理解为模型对某个样本预测属于其真实label的概率越高,则说明该样本对此模型比较容易学习,反之则难分。
2、《ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks》论文提出一个附加网络来帮助主网络区分样本难易程度。
3、《Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis》论文通过对一张图像进行数据增强生成多张图像,然后使用模型预测每张图像的概率。根据多张相同label的增强图像的概率分布区分其样本难易程度。
4、《OHEM: Training Region-based Object Detectors with Online Hard Example Mining》论文提出先使用模型输出概率,据此选出部分难分样本,然后根据这些样本,更新网络参数。
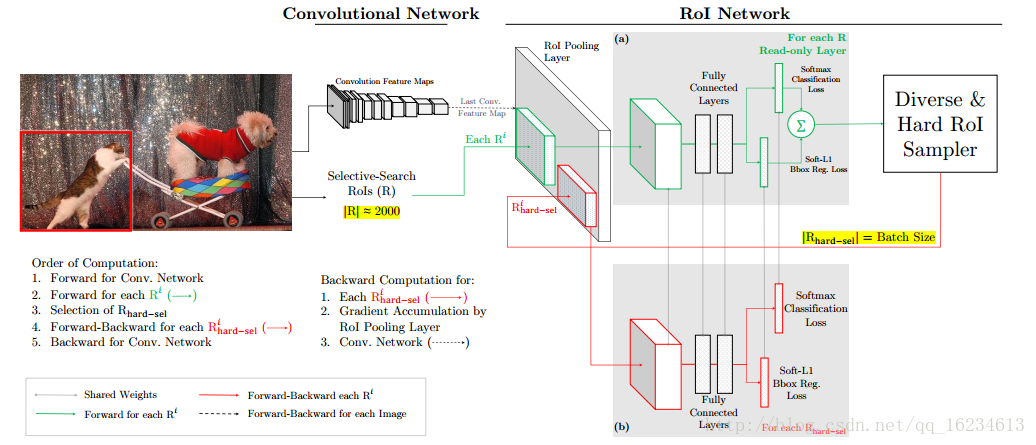
OHEM:
上图绿色和红色分为两个网络但共享权限,通过将提取的RoI传入绿色的只读网络(只进行forward),计算出每个RoI的loss。根据loss排序(可使用NMS)选出部分样本,再输入红色网络(进行forward和backward)学习并进行梯度传播。文中提出另一种办法,在反向传播时,只对选出的样本的梯度/残差回传,而其他的props的梯度/残差设为0。但容易导致显存显著增加,迭代时间增加。
《Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis》中 
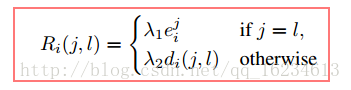
提出首先对一张图像做数据增强,生成一个batches图像,由于这些图像同属一个类别,按理模型预测的结果应该近似,但如果模型预测的不理想,则一定程度上说明图像比较难分。上公式R用于计算图像的难分程度。其思想就是对一张图像的多种变化后进行预测,输出loss后计算样本难分度。focal loss其实就是一种简版,直接根据输出概率计算难分。
ScreenerNet:提出附加网络来输出样本权重,使用该权重与主网络输出结合对主网络参数进行更新。同时使用主网络输出和附网络输出来更新附网络参数。(图中数字为算法运行步骤) 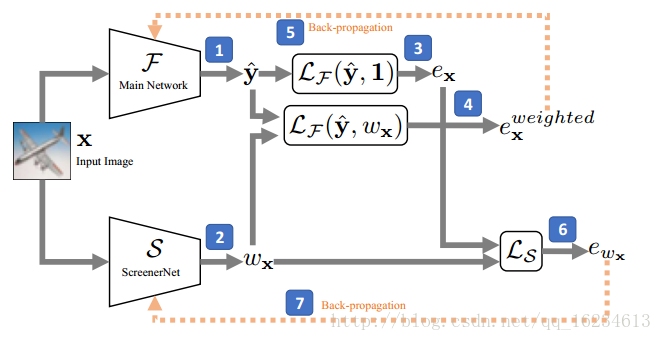
值得注意是在没有label情况下,对附网络的目标函数的设定:
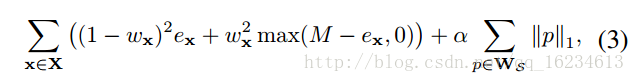
OHEM的更多相关文章
- Focal Loss(RetinaNet) 与 OHEM
Focal Loss for Dense Object Detection-RetinaNet YOLO和SSD可以算one-stage算法里的佼佼者,加上R-CNN系列算法,这几种算法可以说是目标检 ...
- focal loss和ohem
公式推导:https://github.com/zimenglan-sysu-512/paper-note/blob/master/focal_loss.pdf 使用的代码:https://githu ...
- rcnn,sppnet,fast rcnn,ohem,faster rcnn,rfcn
https://zhuanlan.zhihu.com/p/21412911 rcnn需要固定图片的大小,fast rcnn不需要 rcnn,sppnet,fast rcnn,ohem,faster r ...
- OHEM(online hard example mining)
最早由RGB在论文<Training Region-based Object Detectors with Online Hard Example Mining>中提出,用于fast-rc ...
- 目标检测 | OHEM
参考:https://blog.csdn.net/app_12062011/article/details/77945600 参考:http://www.cnblogs.com/sddai/p/102 ...
- OHEM论文笔记
目录 引言 Fast R-CNN设计思路 一.动机 二.现有方案hard negative mining 及其窘境 hard negative mining实现 窘境 设计思路 OHEM步骤: 反向传 ...
- (转) 技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道
技术揭秘:海康威视PASCAL VOC2012目标检测权威评测夺冠之道 原创 2016-09-21 钟巧勇 深度学习大讲堂 点击上方“深度学习大讲堂”可订阅哦!深度学习大讲堂是高质量原创内容平台,邀请 ...
- R-FCN论文翻译
R-FCN论文翻译 R-FCN: Object Detection viaRegion-based Fully Convolutional Networks 2018.2.6 论文地址:R-FCN ...
- 论文阅读笔记五十四:Gradient Harmonized Single-stage Detector(CVPR2019)
论文原址:https://arxiv.org/pdf/1811.05181.pdf github:https://github.com/libuyu/GHM_Detection 摘要 尽管单阶段的检测 ...
随机推荐
- 开始使用KVM和QEMU
一. 简介 Quick Emulator(QEMU) 是QEMU/KVM虚拟化套件中的主要组成部分. 它提供了硬件的虚拟化和处理器的仿真. QEMU不用运行在内核,它是运行在用户空间的. QEMU支持 ...
- JSR教程2——Spring MVC数据校验与国际化
SpringMVC数据校验采用JSR-303校验. • Spring4.0拥有自己独立的数据校验框架,同时支持JSR303标准的校验框架. • Spring在进行数据绑定时,可同时调用校验框架完成数据 ...
- Ubuntu 16.04设置rc.local开机启动命令/脚本的方法
Ubuntu 16.04设置rc.local开机启动命令/脚本的方法 Ubuntu 16.04设置rc.local开机启动命令/脚本的方法(通过update-rc.d管理Ubuntu开机启 ...
- seq2seq模型以及其tensorflow的简化代码实现
本文内容: 什么是seq2seq模型 Encoder-Decoder结构 常用的四种结构 带attention的seq2seq 模型的输出 seq2seq简单序列生成实现代码 一.什么是seq2seq ...
- BSGS算法学习
嗯哼大步小步法. 一个非常暴力的想法. 注意到如果设C = ⌈√P⌉,那么任何一个数都可以写 成a1 * C + b1的形式,其中a1, b1 都< C. 那么预处理出A^i*C的值.然后在询问 ...
- [Luogu5241]序列(DP)
固定一种构造方法,使它能够构造出所有可能的序列. 对于一个要构造的序列,把所有点排成一串,若a[i]=a[i-1],那么从1所在弱连通块往连通块后一个点连,若所有点都在一个连通块里了,就在1所在强连通 ...
- C/C++的64为长整型数的表示
在C/C++中,64为整型一直是一种没有确定规范的数据类型.现今主流的编译器中,对64为整型的支持也是标准不一,形态各异.一般来说,64位整型的定义方式有long long和__int64两种(VC还 ...
- Git和Gitlab
参考 http://www.cnblogs.com/clsn/p/7929958.html#auto_id_16https://backlog.com/git-tutorial/cn/intro/in ...
- Ural 2037. Richness of binary words 打表找规律 构造
2037. Richness of binary words 题目连接: http://acm.timus.ru/problem.aspx?space=1&num=2037 Descripti ...
- ROS知识(22)----USB口映射固定名字
如果有多个usb链接到电脑,如果插入的先后顺序不同,那么会导致对应的usb口也会不同,例如当只有一个激光的usb链接到电脑,其设备名字为/dev/ttyUSB0:当如果有底盘的usb以及激光的usb连 ...