lucene相关
lucene相关:
应用领域:
- 互联网全文检索引擎(比如百度, 谷歌, 必应)
- 站内全文检索引擎(淘宝, 京东搜索功能)
- 优化数据库查询(因为数据库中使用like关键字是全表扫描也就是顺序扫描算法,查询慢)
lucene:又叫全文检索,先建立索引,在对索引进行搜索的过程。
Lucene下载
官方网站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
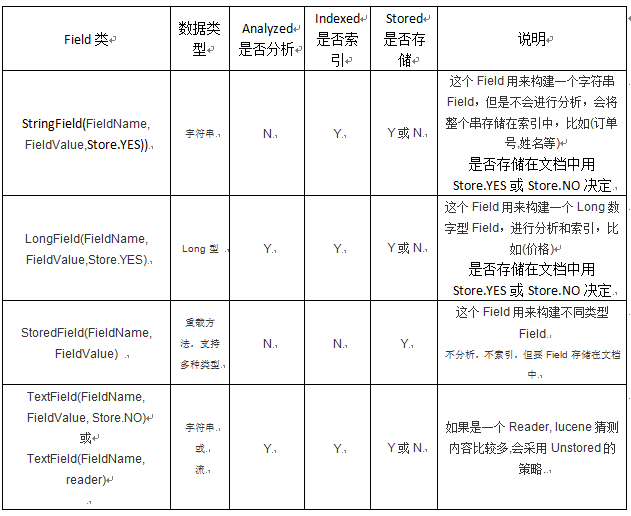
域的各种类型:
lucene的使用:
1、导入jar包:
2、这里我们使用的IKAnalyzer分词器,导入相关配置:
3:代码:
新建 IndexManagerTest 类,主要用于新增、删除、修改索引:
- package com.dengwei.lucene;
- import org.apache.commons.io.FileUtils;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.document.Field.Store;
- import org.apache.lucene.document.LongField;
- import org.apache.lucene.document.TextField;
- import org.apache.lucene.index.IndexWriter;
- import org.apache.lucene.index.IndexWriterConfig;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.apache.lucene.util.Version;
- import org.junit.Test;
- import org.wltea.analyzer.lucene.IKAnalyzer;
- import java.io.File;
- import java.util.ArrayList;
- import java.util.List;
- public class IndexManagerTest {
- /*
- * testIndexCreate();创建索引,数据来源于txt文件
- */
- @Test
- public void testIndexCreate() throws Exception{
- //创建文档列表,保存多个Docuemnt
- List<Document> docList = new ArrayList<Document>();
- //指定txt文件所在目录(需要建立索引的文件)
- File dir = new File("E:\\searchsource");
- //循环文件夹取出文件
- for(File file : dir.listFiles()){
- //文件名称
- String fileName = file.getName();
- //文件内容
- String fileContext = FileUtils.readFileToString(file);
- //文件大小
- Long fileSize = FileUtils.sizeOf(file);
- //文档对象,文件系统中的一个文件就是一个Docuemnt对象
- Document doc = new Document();
- //第一个参数:域名
- //第二个参数:域值
- //第三个参数:是否存储,是为yes,不存储为no
- /*TextField nameFiled = new TextField("fileName", fileName, Store.YES);
- TextField contextFiled = new TextField("fileContext", fileContext, Store.YES);
- TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/
- //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义
- //是否索引:要,因为要通过它来进行搜索
- //是否存储:要,因为要直接在页面上显示
- TextField nameFiled = new TextField("fileName", fileName, Store.YES);
- //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义
- //是否索引: 要,因为要根据它进行搜索
- //是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来
- TextField contextFiled = new TextField("fileContext", fileContext, Store.NO);
- //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法
- //是否索引: 要, 因为要根据大小进行搜索
- //是否存储: 要, 因为要显示文档大小
- LongField sizeFiled = new LongField("fileSize", fileSize, Store.YES);
- //将所有的域都存入文档中
- doc.add(nameFiled);
- doc.add(contextFiled);
- doc.add(sizeFiled);
- //将文档存入文档集合中
- docList.add(doc);
- }
- //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
- Analyzer analyzer = new IKAnalyzer();
- //指定索引和文档存储的目录
- Directory directory = FSDirectory.open(new File("E:\\dic"));
- //创建写对象的初始化对象
- IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
- //创建索引和文档写对象
- IndexWriter indexWriter = new IndexWriter(directory, config);
- //将文档加入到索引和文档的写对象中
- for(Document doc : docList){
- indexWriter.addDocument(doc);
- }
- //提交
- indexWriter.commit();
- //关闭流
- indexWriter.close();
- }
- /*
- * testIndexDel();删除所有和根据词源进行删除。
- */
- @Test
- public void testIndexDel() throws Exception{
- //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
- Analyzer analyzer = new IKAnalyzer();
- //指定索引和文档存储的目录
- Directory directory = FSDirectory.open(new File("E:\\dic"));
- //创建写对象的初始化对象
- IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
- //创建索引和文档写对象
- IndexWriter indexWriter = new IndexWriter(directory, config);
- //删除所有
- //indexWriter.deleteAll();
- //根据名称进行删除
- //Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据
- indexWriter.deleteDocuments(new Term("fileName", "apache"));
- //提交
- indexWriter.commit();
- //关闭
- indexWriter.close();
- }
- /**
- * testIndexUpdate();更新:
- * 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象
- * 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象
- * @throws Exception
- */
- @Test
- public void testIndexUpdate() throws Exception{
- //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
- Analyzer analyzer = new IKAnalyzer();
- //指定索引和文档存储的目录
- Directory directory = FSDirectory.open(new File("E:\\dic"));
- //创建写对象的初始化对象
- IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
- //创建索引和文档写对象
- IndexWriter indexWriter = new IndexWriter(directory, config);
- //根据文件名称进行更新
- Term term = new Term("fileName", "web");
- //更新的对象
- Document doc = new Document();
- doc.add(new TextField("fileName", "xxxxxx", Store.YES));
- doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO));
- doc.add(new LongField("fileSize", 100L, Store.YES));
- //更新
- indexWriter.updateDocument(term, doc);
- //提交
- indexWriter.commit();
- //关闭
- indexWriter.close();
- }
- }
2:新建 IndexSearchTest 类,主要用于搜索索引:
- package com.dengwei.lucene;
- import java.io.File;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.standard.StandardAnalyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
- import org.apache.lucene.queryparser.classic.QueryParser;
- import org.apache.lucene.search.BooleanClause.Occur;
- import org.apache.lucene.search.BooleanQuery;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.MatchAllDocsQuery;
- import org.apache.lucene.search.NumericRangeQuery;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.ScoreDoc;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.junit.Test;
- import org.wltea.analyzer.lucene.IKAnalyzer;
- public class IndexSearchTest {
- /*
- *testIndexSearch()
- * 根据关键字搜索,并指定默认域
- */
- @Test
- public void testIndexSearch() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- //创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器
- //默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索
- QueryParser queryParser = new QueryParser("fileContext", analyzer);
- //查询语法=域名:搜索的关键字
- Query query = queryParser.parse("fileName:web");
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(query, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- /*
- *testIndexTermQuery()
- * 根据关键字进行搜索,需要指定域名,和上面的对比起来,更推荐
- * 使用上面的(可以指定默认域名的)
- */
- @Test
- public void testIndexTermQuery() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- //创建词元:就是词,
- Term term = new Term("fileName", "apache");
- //使用TermQuery查询,根据term对象进行查询
- TermQuery termQuery = new TermQuery(term);
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(termQuery, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- /*
- *testNumericRangeQuery();
- * 用于搜索价格、大小等数值区间
- */
- @Test
- public void testNumericRangeQuery() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- //根据数字范围查询
- //查询文件大小,大于100 小于1000的文章
- //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
- Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true);
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(query, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- /*
- *testBooleanQuery();
- * 组合查询,可以根据多条件进行查询
- */
- @Test
- public void testBooleanQuery() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- //布尔查询,就是可以根据多个条件组合进行查询
- //文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章
- BooleanQuery query = new BooleanQuery();
- //根据数字范围查询
- //查询文件大小,大于100 小于1000的文章
- //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
- Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true);
- //创建词元:就是词,
- Term term = new Term("fileName", "apache");
- //使用TermQuery查询,根据term对象进行查询
- TermQuery termQuery = new TermQuery(term);
- //Occur是逻辑条件
- //must相当于and关键字,是并且的意思
- //should,相当于or关键字或者的意思
- //must_not相当于not关键字, 非的意思
- //注意:单独使用must_not 或者 独自使用must_not没有任何意义
- query.add(termQuery, Occur.MUST);
- query.add(numericQuery, Occur.MUST);
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(query, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- /*
- *testMathAllQuery();
- * 查询所有:
- */
- @Test
- public void testMathAllQuery() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- //查询所有文档
- MatchAllDocsQuery query = new MatchAllDocsQuery();
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(query, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- /*
- *testMultiFieldQueryParser();
- * 从多个域中进行查询
- */
- @Test
- public void testMultiFieldQueryParser() throws Exception{
- //创建分词器(创建索引和所有时所用的分词器必须一致)
- Analyzer analyzer = new IKAnalyzer();
- String [] fields = {"fileName","fileContext"};
- //从文件名称和文件内容中查询,只有含有apache的就查出来
- MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer);
- //输入需要搜索的关键字
- Query query = multiQuery.parse("apache");
- //指定索引和文档的目录
- Directory dir = FSDirectory.open(new File("E:\\dic"));
- //索引和文档的读取对象
- IndexReader indexReader = IndexReader.open(dir);
- //创建索引的搜索对象
- IndexSearcher indexSearcher = new IndexSearcher(indexReader);
- //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
- TopDocs topdocs = indexSearcher.search(query, 5);
- //一共搜索到多少条记录
- System.out.println("=====count=====" + topdocs.totalHits);
- //从搜索结果对象中获取结果集
- ScoreDoc[] scoreDocs = topdocs.scoreDocs;
- for(ScoreDoc scoreDoc : scoreDocs){
- //获取docID
- int docID = scoreDoc.doc;
- //通过文档ID从硬盘中读取出对应的文档
- Document document = indexReader.document(docID);
- //get域名可以取出值 打印
- System.out.println("fileName:" + document.get("fileName"));
- System.out.println("fileSize:" + document.get("fileSize"));
- System.out.println("============================================================");
- }
- }
- }
lucene相关的更多相关文章
- Lucene 基础理论 (zhuan)
http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html**************************************** ...
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- lucene 核心概念及入门
lucene Lucene介绍及核心概念 什么是Lucene Lucene是一套用于全文检索和搜索的开放源代码程序库,由Apache软件基金会支持和提供.Lucene提供了一个简单却强大的应用程序接口 ...
- lucene教程【转】【补】
现实流程 lucene 相关jar包 第一个:Lucene-core-4.0.0.jar, 其中包括了常用的文档,索引,搜索,存储等相关核心代码. 第二个:Lucene-analyzers-commo ...
- Lucene 3.0 输出相似度
http://www.cnblogs.com/ibook360/archive/2011/10/19/2217638.html Lucene3.0之结果排序(原理篇) 传统上,人们将信息检索系统返回结 ...
- lucene 学习之编码篇
本文环境:lucene5.2 JDK1.7 IKAnalyzer 引入lucene相关包 <!-- lucene核心包 --> <dependency> <g ...
- lucene构建restful风格的简单搜索引擎服务
来自于本人博客: lucene构建restful风格的简单搜索引擎服务 本人的博客如今也要改成使用lucene进行全文检索的功能,因此在这里把代码贴出来与大家分享 一,文件夹结构: 二,配置文件: 总 ...
- springboot+lucene实现公众号关键词回复智能问答
一.场景简介 最近在做公众号关键词回复方面的智能问答相关功能,发现用户输入提问内容和我们运营配置的关键词匹配回复率极低,原因是我们采用的是数据库的Like匹配. 这种模糊匹配首先不是很智能,而且也没有 ...
- Lucene入门+实现
Lucene简介详情见:(https://blog.csdn.net/Regan_Hoo/article/details/78802897) lucene实现原理 其实网上很多资料表明了,lucene ...
随机推荐
- 实验六 MapReduce实验:二次排序
实验指导: 6.1 实验目的基于MapReduce思想,编写SecondarySort程序. 6.2 实验要求要能理解MapReduce编程思想,会编写MapReduce版本二次排序程序,然后将其执行 ...
- nfs的配置文件/etc/exports
/etc/exports 文件格式 <输出目录> [客户端1 选项(访问权限,用户映射,其他)] [客户端2 选项(访问权限,用户映射,其他)] a. 输出目录:输出目录是指NFS系统中 ...
- Codeforces | CF1041F 【Ray in the tube】
昨天晚上全机房集体开\(Div2\),因为人傻挂两次\(B\)题的我开场就\(rank2000+\dots qwq\)于是慌乱之中的我就开始胡乱看题(口胡),于是看了\(F\dots\)(全机房似乎也 ...
- Centos 6.x/7.x yum安装php5.6.X
鉴于Centos 默认yum源的php版本太低了,手动编译安装又有点一些麻烦,那么如何采用Yum安装的方案安装最新版呢.那么,今天我们就来学习下如何用yum安装php最新版. 1.检查当前安装的PHP ...
- 如何刻录cd音乐
用nero,选择cd,音乐光盘(第一个)可以添加入wav,MP3等.刻录即可.
- PHP 生成水印图片
这段时间因工作需要,学习了下用PHP来给背景图上添加公司logo,宣传语之类的图片合并功能.话不多说,直接上代码. <?php public function getImage() { $dat ...
- javascript学习一、js的初步了解
1.javascript的简介: *javascript 是一种基于对象和事件驱动的语言,主要应用于客户端. -- 基于对象: ** 提供了很多对象,可以直接使用. --事件驱动: ** html做 ...
- js弹出层
js弹出层 1.div附近显示 <div id="message"></div> $().delay().hide(); 2.遮罩层 表单提交后遮住页面,等 ...
- rm刷机 root
http://www.miui.com/download-290.html http://www.miui.com/shuaji-329.html 小米稳定版 不可以root 只有升级到上面的开 ...
- webDriver文档阅读笔记
一些雷 浏览器版本和对应的Driver的版本是一一对应的,有时候跑不起来,主要是因为driver和浏览器版本对不上. e.g: chrome和driver版本映射表:https://blog.csdn ...