OkHttp3源码详解(六) Okhttp任务队列工作原理
1 概述
1.1 引言
android完成非阻塞式的异步请求的时候都是通过启动子线程的方式来解决,子线程执行完任务的之后通过handler的方式来和主线程来完成通信。无限制的创建线程,会给系统带来大量的开销。如果在高并发的任务下,启用个线程池,可以不断的复用里面不再使用和有效的管理线程的调度和数量的管理。就可以节省系统的成本,有效的提高执行效率。
1.2 线程池ThreadPoolExecutor
okhttp的线程池对象存在于Dispatcher类中。实例过程如下
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(, Integer.MAX_VALUE, , TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
1.2 Call对象
了解源码或使用过okhttp的都知道。 okttp的操作元是Call对象。异步的实现是RealCall.AsyncCall。而 AsyncCall是实现的一个Runnable接口。
final class AsyncCall extends NamedRunnable {}
所以Call本质就是一个Runable线程操作元肯定是放进excutorService中直接启动的。
2 线程池的复用和管理
2.1 图解
为了完成调度和复用,定义了两个队列分别用作等待队列和执行任务的队列。这两个队列都是Dispatcher 成员变量。Dispatcher是一个控制执行,控制所有Call的分发和任务的调度、通信、清理等操作。这里只介绍异步调度任务。
/** Ready async calls in the order they'll be run. */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>(); /** Running asynchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
在《okhttp连接池复用机制》文章中我们在缓存Connection连接的时候也是使用的Deque双端队列。这里同样的方式,可以方便在队列头添加元素,移除尾部的元素。
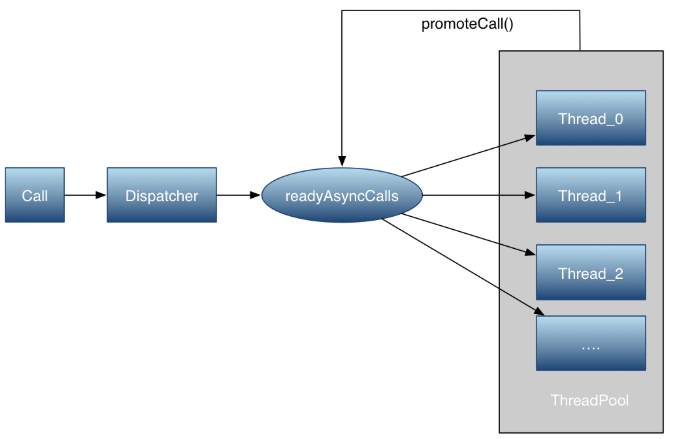
2.2 过程分析
Call代用equeue方法的时候
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
方法中满足执行队列里面不足最大线程数maxRequests并且Call对应的host数目不超过maxRequestsPerHost 的时候直接把call对象直接推入到执行队列里,并启动线程任务(Call本质是一个Runnable)。否则,当前线程数过多,就把他推入到等待队列中。Call执行完肯定需要在runningAsyncCalls 队列中移除这个线程。那么readyAsyncCalls队列中的线程在什么时候才会被执行呢。
追溯下AsyncCall 线程的执行方法
@Override
protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain(forWebSocket);
if (canceled) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
}
这里做了核心request的动作,并把失败和回复数据的结果通过responseCallback 回调到Dispatcher。执行操作完毕了之后不管有无异常都会进入到dispactcher的finished方法。
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == && idleCallback != null) {
idleCallback.run();
}
}
在这里call在runningAsyncCalls队列中被移除了,重新计算了目前正在执行的线程数量。并且调用了promoteCalls() 看来是来调整任务队列的,跟进去看下
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
原来实在这里对readyAsyncCalls 进行调度的。最终会在readyAsyncCalls 中通过remove操作把元素迭代取出并移除之后加入到runningAsyncCalls的执行队列中执行操作。ArrayDeque 是非线程安全的所以finished在调用promoteCalls 的时候都在synchronized块中执行的。执行等待队列线程当然的前提是runningAsyncCalls 线程数没有超上线,而且等待队列里面有等待的任务。
以上完成了线程线程池的复用和线程的管理工作。
小结,Call在执行任务通过Dispatcher把单元任务优先推到执行队列里进行操作,如果操作完成再执行等待队列的任务。
OkHttp3源码详解(六) Okhttp任务队列工作原理的更多相关文章
- OkHttp3源码详解(五) okhttp连接池复用机制
1.概述 提高网络性能优化,很重要的一点就是降低延迟和提升响应速度. 通常我们在浏览器中发起请求的时候header部分往往是这样的 keep-alive 就是浏览器和服务端之间保持长连接,这个连接是可 ...
- OkHttp3源码详解(一) Request类
每一次网络请求都是一个Request,Request是对url,method,header,body的封装,也是对Http协议中请求行,请求头,实体内容的封装 public final class R ...
- OkHttp3源码详解(三) 拦截器
1.构造Demo 首先构造一个简单的异步网络访问Demo: OkHttpClient client = new OkHttpClient(); Request request = new Reques ...
- OkHttp3源码详解(三) 拦截器-RetryAndFollowUpInterceptor
最大恢复追逐次数: ; 处理的业务: 实例化StreamAllocation,初始化一个Socket连接对象,获取到输入/输出流()基于Okio 开启循环,执行下一个调用链(拦截器),等待返回结果(R ...
- OkHttp3源码详解(二) 整体流程
1.简单使用 同步: @Override public Response execute() throws IOException { synchronized (this) { if (execut ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
- 源码详解系列(八) ------ 全面讲解HikariCP的使用和源码
简介 HikariCP 是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,和 dr ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- spring事务详解(三)源码详解
系列目录 spring事务详解(一)初探事务 spring事务详解(二)简单样例 spring事务详解(三)源码详解 spring事务详解(四)测试验证 spring事务详解(五)总结提高 一.引子 ...
随机推荐
- 毕业不到一年,绩效打了个D!
周末了,和大家来聊聊程序员工作态度的问题. 说说栈长的事迹吧,这是好多年前的事了,那时候,栈长才毕业不到一年,那次绩效打了个D!事后,我很气愤啊,我那时还在博客上写文章怒骂了部门经理,现在想起来,真是 ...
- tensorflow 迭代周期长,每个epoch时间变慢
理论上,session启动后,每个epoch训练时间应该是差不多,而且不会因为迭代周期变长,epoch时间变慢.原因是session里定义了tf.op导致的,每一次迭代都会在graph里增加新的节点, ...
- H5在WebView上开发小结
背景 来自我司业务方要求,需开发一款APP.但由于时间限制,只能采取套壳app方式,即原生app内嵌webview展示前端页面.本文主要记述JavaScript与原生app间通信,以及内嵌webvie ...
- javascript数组的属性、方法和清空-最全!!!(必看)
今天经理要我从新看一遍js,当我再看<精通js和jquery>这本书时,发现关于数组的这章节讲的很少,于是想自己总结一下数组的常用方法. 定义数组: var arr = new Array ...
- odoo开发笔记 -- 表名_name长度限制
场景描述: odoo中定义模型的时候,系统会根据参数_name="********" 按照一定的系统规则自动生成表名; 最近开发过程中发现,_name参数的字符长度不能超过64位, ...
- html标签详解(1)
http标签详解及讲解 1.基础标签 <!DOCTYPE html> <!--表示文本类型--> <html> <!--<html> ...
- Android UI(四)云通讯录项目之云端更新进度条实现
作者:泥沙砖瓦浆木匠网站:http://blog.csdn.net/jeffli1993个人签名:打算起手不凡写出鸿篇巨作的人,往往坚持不了完成第一章节.交流QQ群:[编程之美 365234583]h ...
- java中String类为什么不可变?
在面试中经常遇到这样的问题:1.什么是不可变对象.不可变对象有什么好处.在什么情景下使用它,或者更具体一点,java的String类为什么要设置成不可变类型? 1.不可变对象,顾名思义就是创建后的对象 ...
- 【原创】Git删除暂存区或版本库中的文件
0 基础 我们知道Git有三大区(工作区.暂存区.版本库)以及几个状态(untracked.unstaged.uncommited),下面只是简述下Git的大概工作流程,详细的可以参见本博客的 ...
- [深度学习] 权重初始化--Weight Initialization
深度学习中的weight initialization对模型收敛速度和模型质量有重要影响! 在ReLU activation function中推荐使用Xavier Initialization的变种 ...