stringstream
C++引入了ostringstream、istringstream、stringstream这三个类,要使用他们创建对象就必须包含sstream.h头文件。
istringstream类用于执行C++风格的串流的输入操作。
ostringstream类用于执行C风格的串流的输出操作。
strstream类同时可以支持C风格的串流的输入输出操作。
istringstream类是从istream和stringstreambase派生而来,ostringstream是从ostream和 stringstreambase派生而来, stringstream则是从iostream类和stringstreambase派生而来。
他们的继承关系如下图所示:

istringstream是由一个string对象构造而来,istringstream类从一个string对象读取字符。
istringstream的构造函数原形如下:
istringstream::istringstream(string str);

#include <iostream>
#include <sstream> using namespace std; int main()
{
istringstream istr;
istr.str("1 56.7");
//上述两个过程可以简单写成 istringstream istr("1 56.7");
cout << istr.str() << endl;
int a;
float b;
istr >> a;
cout << a << endl;
istr >> b;
cout << b << endl;
return 0;
}
上例中,构造字符串流的时候,空格会成为字符串参数的内部分界,例子中对a,b对象的输入"赋值"操作证明了这一点,字符串的空格成为了整型数据与浮点型数据的分解点,利用分界获取的方法我们事实上完成了字符串到整型对象与浮点型对象的拆分转换过程。
str()成员函数的使用可以让istringstream对象返回一个string字符串(例如本例中的输出操作(cout<<istr.str();)。
ostringstream同样是由一个string对象构造而来,ostringstream类向一个string插入字符。
ostringstream的构造函数原形如下:
ostringstream::ostringstream(string str);
示例代码如下:
#include <iostream>
#include <sstream>
#include <string>
#include<cstdlib>
using namespace std;
int main()
{
ostringstream ostr;
//ostr.str("abc");
//如果构造的时候设置了字符串参数,那么增长操作的时候不会从结尾开始增加,而是修改原有数据,超出的部分增长
ostr.put('d');
ostr.put('e');
ostr<<"fg"; string gstr = ostr.str();
cout<<gstr;
system("pause");
}
在上例代码中,我们通过put()或者左移操作符可以不断向ostr插入单个字符或者是字符串,通过str()函数返回增长过后的完整字符串数据,但值 得注意的一点是,当构造的时候对象内已经存在字符串数据的时候,那么增长操作的时候不会从结尾开始增加,而是修改原有数据,超出的部分增长。
[ basic_stringbuf::str :
Sets or gets the text in a string buffer without changing the write position. ]
对于stringstream了来说,不用我多说,大家也已经知道它是用于C++风格的字符串的输入输出的。
stringstream的构造函数原形如下:
stringstream::stringstream(string str);
示例代码如下:
#include <iostream>
#include <sstream>
#include <string>
#include<cstdlib>
using namespace std; int main()
{
stringstream ostr("ccc");
ostr.put('d');
ostr.put('e');
ostr<<"fg";
string gstr = ostr.str();
cout<<gstr<<endl; char a;
ostr>>a;
cout<<a;
system("pause");
}
除此而外,stringstream类的对象我们还常用它进行string与各种内置类型数据之间的转换。
示例代码如下:
#include <iostream>
#include <sstream>
#include <string>
#include<cstdlib>
using namespace std; int main()
{
stringstream sstr;
//--------int转string-----------
int a=100;
string str;
sstr<<a;
sstr>>str;
cout<<str<<endl;
//--------string转char[]--------
sstr.clear();//如果你想通过使用同一stringstream对象实现多种类型的转换,请注意在每一次转换之后都必须调用clear()成员函数。
string name = "colinguan";
char cname[200];
sstr<<name;
sstr>>cname;
cout<<cname;
system("pause");
}
|
C++标准库中的<sstream>提供了比ANSI C的<stdio.h>更高级的一些功能,即单纯性、类型安全和可扩展性。在本文中,我将展示怎样使用这些库来实现安全和自动的类型转换。 为什么要学习 如果你已习惯了<stdio.h>风格的转换,也许你首先会问:为什么要花额外的精力来学习基于<sstream>的类型转换呢?也许对下面一个简单的例子的回顾能够说服你。假设你想用sprintf()函数将一个变量从int类型转换到字符串类型。为了正确地完成这个任务,你必须确保证目标缓冲区有足够大空间以容纳转换完的字符串。此外,还必须使用正确的格式化符。如果使用了不正确的格式化符,会导致非预知的后果。下面是一个例子: int n=10000; chars[10]; sprintf(s,”%d”,n);// s中的内容为“10000” 到目前为止看起来还不错。但是,对上面代码的一个微小的改变就会使程序崩溃: int n=10000; char s[10]; sprintf(s,”%f”,n);// 看!错误的格式化符 在这种情况下,程序员错误地使用了%f格式化符来替代了%d。因此,s在调用完sprintf()后包含了一个不确定的字符串。要是能自动推导出正确的类型,那不是更好吗? 进入stringstream 由于n和s的类型在编译期就确定了,所以编译器拥有足够的信息来判断需要哪些转换。<sstream>库中声明的标准类就利用了这一点,自动选择所必需的转换。而且,转换结果保存在stringstream对象的内部缓冲中。你不必担心缓冲区溢出,因为这些对象会根据需要自动分配存储空间。 你的编译器支持<sstream>吗? <sstream>库是最近才被列入C++标准的。(不要把<sstream>与标准发布前被删掉的<strstream>弄混了。)因此,老一点的编译器,如GCC2.95,并不支持它。如果你恰好正在使用这样的编译器而又想使用<sstream>的话,就要先对它进行升级更新。 <sstream>库定义了三种类:istringstream、ostringstream和stringstream,分别用来进行流的输入、输出和输入输出操作。另外,每个类都有一个对应的宽字符集版本。简单起见,我主要以stringstream为中心,因为每个转换都要涉及到输入和输出操作。 注意,<sstream>使用string对象来代替字符数组。这样可以避免缓冲区溢出的危险。而且,传入参数和目标对象的类型被自动推导出来,即使使用了不正确的格式化符也没有危险。 string到int的转换 string result=”10000”; 重复利用stringstream对象 如果你打算在多次转换中使用同一个stringstream对象,记住再每次转换前要使用clear()方法; 在多次转换中重复使用同一个stringstream(而不是每次都创建一个新的对象)对象最大的好处在于效率。stringstream对象的构造和析构函数通常是非常耗费CPU时间的。 在类型转换中使用模板 你可以轻松地定义函数模板来将一个任意的类型转换到特定的目标类型。例如,需要将各种数字值,如int、long、double等等转换成字符串,要使用以一个string类型和一个任意值t为参数的to_string()函数。to_string()函数将t转换为字符串并写入result中。使用str()成员函数来获取流内部缓冲的一份拷贝: template<class T> void to_string(string & result,const T& t) { ostringstream oss;//创建一个流 oss<<t;//把值传递如流中 result=oss.str();//获取转换后的字符转并将其写入result 这样,你就可以轻松地将多种数值转换成字符串了: to_string(s1,10.5);//double到string to_string(s2,123);//int到string to_string(s3,true);//bool到string 可以更进一步定义一个通用的转换模板,用于任意类型之间的转换。函数模板convert()含有两个模板参数out_type和in_value,功能是将in_value值转换成out_type类型: template<class out_type,class in_value> out_type convert(const in_value & t) { stringstream stream; stream<<t;//向流中传值 out_type result;//这里存储转换结果 stream>>result;//向result中写入值 return result; } 这样使用convert(): double d; string salary; string s=”12.56”; d=convert<double>(s);//d等于12.56 salary=convert<string>(9000.0);//salary等于”9000” 结论 在过去留下来的程序代码和纯粹的C程序中,传统的<stdio.h>形式的转换伴随了我们很长的一段时间。但是,如文中所述,基于stringstream的转换拥有类型安全和不会溢出这样抢眼的特性,使我们有充足得理由抛弃<stdio.h>而使用<sstream>。<sstream>库还提供了另外一个特性—可扩展性。你可以通过重载来支持自定义类型间的转换。 一些实例: stringstream通常是用来做数据转换的。 相比c库的转换,它更加安全,自动和直接。 例子一:基本数据类型转换例子 int转string |
#include <string>
#include <sstream>
#include <iostream> int main()
{
std::stringstream stream;
std::string result;
int i = 1000;
stream << i; //将int输入流
stream >> result; //从stream中抽取前面插入的int值
std::cout << result << std::endl; // print the string "1000"
}
运行结果:
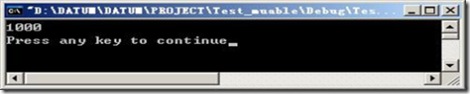
例子二:除了基本类型的转换,也支持char *的转换。
#include <sstream>
#include <iostream> int main()
{
std::stringstream stream;
char result[8] ;
stream << 8888; //向stream中插入8888
stream >> result; //抽取stream中的值到result
std::cout << result << std::endl; // 屏幕显示 "8888"
}

例子三:再进行多次转换的时候,必须调用stringstream的成员函数clear().
#include <sstream>
#include <iostream>
int main()
{
std::stringstream stream;
int first, second;
stream<< "456"; //插入字符串
stream >> first; //转换成int
std::cout << first << std::endl;
stream.clear(); //在进行多次转换前,必须清除stream
stream << true; //插入bool值
stream >> second; //提取出int
std::cout << second << std::endl;
}
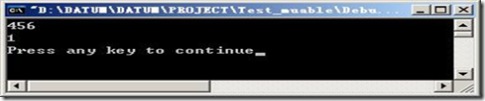
|
运行clear的结果
没有运行clear的结果
|

|
本文主要考虑 x86 Linux 平台,不考虑跨平台的可移植性,也不考虑国际化(i18n),但是要考虑 32-bit 和 64-bit 的兼容性。本文以 stdio 指代 C 语言的 scanf/printf 系列格式化输入输出函数。本文注意区分“编程初学者”和“C++初学者”,二者含义不同。
摘要:C++ iostream 的主要作用是让初学者有一个方便的命令行输入输出试验环境,在真实的项目中很少用到 iostream,因此不必把精力花在深究 iostream 的格式化与 manipulator。iostream 的设计初衷是提供一个可扩展的类型安全的 IO 机制,但是后来莫名其妙地加入了 locale 和 facet 等累赘。其整个设计复杂不堪,多重+虚拟继承的结构也很巴洛克,性能方面几无亮点。iostream 在实际项目中的用处非常有限,为此投入过多学习精力实在不值。 stdio 格式化输入输出的缺点 1. 对编程初学者不友好 看看下面这段简单的输入输出代码。 int main() scanf("%d %hd %f %lf %s", &i, &s, &f, &d, name); int main() char fmt[10]; C 语言的安全性问题近十几年来引起了广泛的注意,C99 增加了 snprintf() 等能够指定输出缓冲区大小的函数,输出方面的安全性问题已经得到解决;输入方面似乎没有太大进展,还要靠程序员自己动手。 如果 printf() 的整数参数类型是 int、long 等标准类型, 那么 printf() 的格式化字符串很容易写。但是如果参数类型是 typedef 的类型呢? int main() short s; size_t sz = 1; C stdio 的另外一个缺点是无法支持自定义的类型,比如我写了一个 Date class,我无法像打印 int 那样用 printf 来直接打印 Date 对象。 Date date; C stdio 的性能方面有两个弱点。 int main() cin >> i >> s >> f >> d >> name; class Date void writeTo(std::ostream& os) const private: std::ostream& operator<<(std::ostream& os, const Date& date) int main() iostream 可以与 string 配合得很好。但是有一个问题:谁依赖谁? 标准库的复数类 complex 的情况比较复杂。使用 complex 会自动包含 sstream,后者会包含 istream 和 ostream,这是个不小的负担。问题是,为什么? iostream 采用 manipulator 来格式化,如果我想按照 2010-04-03 的格式输出前面定义的 Date class,那么代码要改成: class Date void writeTo(std::ostream& os) const private: class Date void writeTo(std::ostream& os) const private: 比方说,我想用一个外部的配置文件来定义日期的格式。C stdio 很好办,把格式字符串 "%d-%02d-%02d" 保存到配置里就行。但是 iostream 呢?它的格式是写死在代码里的,灵活性大打折扣。 如果我想用 16 进制方式输出一个整数 x,那么可以用 hex 操控符,但是这会改变 ostream 的状态。比如说 在 C 语言之外,有其他很多语言也支持 printf() 风格的格式化,例如 Java、Perl、Ruby 等等 (http://en.wikipedia.org/wiki/Printf#Programming_languages_with_printf)。学会 printf() 的格式化方法,这个知识还可以用到其他语言中。但是 C++ iostream 只此一家别无分店,反正都是格式化输出,stdio 的投资回报率更高。 iostream 的另外一个问题是线程安全性。stdio 的函数是线程安全的,而且 C 语言还提供了 flockfile(3)/funlockfile(3) 之类的函数来明确控制 FILE* 的加锁与解锁。 根据以上分析,我们可以归纳 iostream 的局限: iostream 是个面向对象的 IO 类库,本节简单介绍它的继承体系。 如果加深一点了解,会发现 iostream 现在是模板化的,同时支持窄字符和宽字符。下图是现在的继承体系,同时画出了 fstreams 和 stringstreams。图中方框的第二行是模板的具现化类型,也就是我们代码里常用的具体类型(通过 typedef 定义)。 这个继承体系糅合了面向对象与泛型编程,但可惜它两方面都不讨好。 再把这两个继承体系画到一幅图里: 注意到 basic_ios 持有了 streambuf 的指针;而 fstreams 和 stringstreams 则分别包含 filebuf 和 stringbuf 的对象。看上去有点像 Bridge 模式。 本节我们分析一下 iostream 的设计违反了哪些 OO 准则。 在现有的继承体系中,合理的有: 注意到在新的设计中,只有真正的 is-a 关系采用了 public 继承,其他均以组合来代替,组合关系以红线表示。新的设计没有用的虚拟继承或多重继承。 class iostream iostream 的故事还不止这些,它还包含一套阳春的 locale/facet 实现,这套实践中没人用的东西进一步增加了 iostream 的复杂度,而且不可避免地影响其性能。Nathan Myers 正是始作俑者http://www.cantrip.org/locale.html 。 孟岩评价 “ iostream 最大的缺点是臆造抽象”,我非常赞同他老人家的观点。 self& operator<<(bool); self& operator<<(short); self& operator<<(const void*); self& operator<<(float); self& operator<<(char); self& operator<<(const char*); const Buffer& buffer() const { return buffer_; } private: muduo::LogStream 的整数转换是自己写的,用的是 Matthew Wilson 的算法,见 http://blog.csdn.net/solstice/article/details/5139302 。这个算法比 stdio 和 iostream 都要快。 目前 muduo::LogStream 的浮点数格式化采用的是 snprintf() 所以从性能上与 stdio 持平,比 ostream 快一些。 由于 muduo::LogStream 抛掉了很多负担,可以预见它的性能好于 ostringstream 和 stdio。我做了一个简单的性能测试,结果如下。 从上表看出,ostreamstream 有时候比 snprintf 快,有时候比它慢,muduo::LogStream 比它们两个都快得多(double 类型除外)。 其他程序库如何使用 LogStream 作为输出呢?办法很简单,用模板。 - void writeTo(std::ostream& os) const private: -std::ostream& operator<<(std::ostream& os, const Date& date) Google leveldb 是一个高效的持久化 key-value db。 // A file abstraction for reading sequentially through a file virtual Status Read(size_t n, Slice* result, char* scratch) = 0; // A file abstraction for randomly reading the contents of a file. virtual Status Read(uint64_t offset, size_t n, Slice* result, // A file abstraction for sequential writing. The implementation virtual Status Append(const Slice& data) = 0; Kyoto Cabinet 也是一个 key-value db,是前几年流行的 Tokyo Cabinet 的升级版。它采用了与 leveldb 不同的文件抽象。 |
stringstream的更多相关文章
- stringstream的基本用法
原帖地址:https://zhidao.baidu.com/question/580048330.htmlstringstream是字符串流.它将流与存储在内存中的string对象绑定起来.在多种数据 ...
- c++ stringstream(老好用了)
前言: 以前没有接触过stringstream这个类的时候,常用的字符串和数字转换函数就是sscanf和sprintf函数.开始的时候就觉得这两个函数应经很叼了,但是毕竟是属于c的.c++中引入了流的 ...
- istringstream、ostringstream、stringstream 类简介
本文系转载,原文链接:http://www.cnblogs.com/gamesky/archive/2013/01/09/2852356.html ,如有侵权,请联系我:534624117@qq.co ...
- stringstream操纵string小总结
1 split字符串 之前在用C#写代码的时候,用过split函数,可以把一个字符串根据某个分隔符分成若干个字符串数组.在用C++操纵字符串的时候,我一直使用很笨的遍历的方法.为此,我问候过很多次C+ ...
- stringstream的用法【转】
[本文来自]http://www.builder.com.cn/2003/0304/83250.shtmlhttp://www.cppblog.com/alantop/archive/2007/07/ ...
- C++ stringstream
C++ 引入了ostringstream.istringstream.stringstream这三个类,这三个类包含在sstream.h头文件中.三个类中 1)istringstream类用于执行C+ ...
- std::stringstream
使用 std::stringstream,小心 内存! 适时 清空 缓冲 …… 2007年12月14日 星期五 : stringstream是个好东西,网上有不少文章,讨论如何用它实现各种数据类型的转 ...
- stringstream 使用方法
C++中的stringstream是专门用来处理字符串流的,可以按顺序将string或int都拼接起来,而不用把int转换为string格式,使用方法如下: #include <string&g ...
- [c++][语言语法]stringstream iostream ifstream
c++中ifstream一次读取整个文件 读取至char*的情况 std::ifstream t; int length; t.open("file.txt"); // open ...
- C++ fstream stringstream
一.文件输入输出 C/C++ 输入: freopen("in.cpp", "r", stdin); fclose(stdin); 输出: freopen(&qu ...
随机推荐
- oracle中 特殊字符 转义 (&)
在dml中,若操作的字符中有 & 特殊字符,则会被oracle视作是输入变量的标志,此时需要用转义字符来进行转义. 1.”&“ 转义 这个是Oracle里面用来识别自定义变量的设置,现 ...
- java编译带中文是显示乱码的错误
FirstJava.java:3: 错误: 编码GBK的不可映射字符 System.out.println("娆㈣繋瀛︿範Java绋嬪簭锛?")锛? ^FirstJava.java ...
- freeswitch dialplan 基础
freeswitch dialplan 基础 一.基础概念 dialplan 拨号方案 context 拨号表(块) extension 拨号去向 action (拨号后执行的)动作 condit ...
- android 7.0+ FileProvider 访问隐私文件 相册、相机、安装应用的适配
从 Android 7.0 开始,Android SDK 中的 StrictMode 策略禁止开发人员在应用外部公开 file:// URI.具体表现为,当我们在应用中使用包含 file:// URI ...
- python日志
日志 -- 用来记录用户行为或者代码的执行过程 logging.debug('debug message') # 低级别的 # 排错信息 logging.info('info message') # ...
- 4.Redis客户端
4.Redis客户端4.1 客户端通信协议4.2 Java客户端Jedis4.2.1 获取Jedis4.2.2 Jedis的基本使用方法4.2.3 Jedis连接池的使用方法4.2.4 Redis中P ...
- Codeforces 1083C Max Mex
Description 一棵\(N\)个节点的树, 每个节点上都有 互不相同的 \([0, ~N-1]\) 的数. 定义一条路径上的数的集合为 \(S\), 求一条路径使得 \(Mex(S)\) 最大 ...
- C# 互通操作 (一)
回顾一下自己学习的内容然后从互通的基础案例开始写起. 这次实现一个很简单的互通demo,就是 在unity里 在c#里调用windows窗体的MessageBox 消息提示 public class ...
- javascript、JSP、JS有什么区别和联系
js是javascript的缩写.以下是JSP与JS的区别和联系: 名字:JS:JavaScriptJSP:Java Server Pages 执行过程:JSP先翻译,翻译成Servlet执行如: t ...
- Cookie随笔
解决了服务器不能识别不同浏览器的问题,相当于给每个浏览器加了个“身份证”. Cookie首先由服务器创建发给浏览器,随后浏览器每次访问服务器时都带上这个Cookie. Cookie缺点: ·Cooki ...