AlphaGo的前世今生(一)Deep Q Network and Game Search Tree:Road to AI Revolution
这一个专题将会是有关AlphaGo的前世今生以及其带来的AI革命,总共分成三节。本人水平有限,如有错误还望指正。如需转载,须征得本人同意。
Road to AI Revolution(通往AI革命之路),在这里我们将探索AlphaGo各项核心技术的源头及发展历程;
Countdown to AI Revolution(AI革命倒计时),在这里我们将解构AlphaGo,看它是如何诞生的;
AI Revolution and Beyond(AI革命及未来发展),在这里我们将解构AlphaGo Zero,它是如何带来革命的,未来革命会走向何方;
Westworld: Real World AI Playground (西部世界:现实世界中的AI训练场),在此额外小节中我们将探讨最近大火的美剧西部世界和当前AI技术的诸多关联性
围棋是一种零和完美信息游戏,零和即双方是竞争关系不存在协作,有一方赢必然有一方输。完美信息即所有信息都在台面上可见,毫无隐藏。象棋,跳棋等其它棋类游戏都有此类特点,经过几十年的发展,计算机在应对这类游戏时可谓是得心应手,象棋跳棋悉数被“攻破”,即击败人类顶级大师选手。但在围棋上的进展却很不顺利,始终难以形成突破。究其原因,有两点,一是搜索空间巨大,二是难以找到合适的位置评估函数。这两处障碍困扰了学者们几十年,直到蒙特卡洛搜索树横空出世,学者们才看到了曙光。接着,深度卷积神经网络登场,其自带强大的自动化特征提取能力解决了特征问题。再辅以自我对局的强化学习,终于AlphaGo的诞生宣告围棋已被“攻破”。
AlphaGo是Deepmind研发的围棋程序,融合了深度学习,强化学习和蒙特卡洛树搜索。深度学习的应用是受到了Deep Q Network的启发,利用深度学习进行高效自动化特征提取来估计值函数。强化学习的应用是受到了TD-Gammon的启发,将强化学习应用到了自我对局提升原始策略并生成的模拟棋局上。蒙特卡洛树搜索是一种强大的搜索方法,是从传统的极大极小搜索一路发展而来,在AlphaGo之前最强的围棋程序都使用了这种搜索方法。
今天我们就先从深度学习Deep Q Network讲起,之后是游戏搜索树,探索AlphaGo的技术源头。
大家对深度学习肯定不陌生,但是强化学习可能很多人只是听说过没有深入了解,那么我就首先大概讲讲强化学习是个什么东西(如果想要深入了解,推荐两个材料,一是AlphaGo之父David Silver在UCL的强化学习课程,B站上有字幕版;二是强化学习之父Richard Sutton写的强化学习导论Reinforcement Learning An Introduction 2nd Edition)
维基百科的介绍简洁清晰,我就直接摘录过来。
强化学习是是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
通俗地讲,强化学习是有关智能体与环境的交互,在交互过程中进行试错学习。智能体观察到某种状态,根据此状态选择所做的动作影响环境,环境返回给智能体奖励以及新的状态。相比监督学习,其独特之处在于,一是没有监督者,只有奖励信号;二是奖励是延迟的不是即时的;三是数据无需独立同分布,四是智能体的动作会影响接下来接收的数据。因此,强化学习非常擅长做序列化决策,很适合应用在游戏领域。
Deep Q Network
过往,强化学习在多个领域已经取得了较大的成功,但都带有着明显的局限性。这体现在两点:一是需要人工生成的特征,二是需要状态空间低维且完全可观测。如今,在深度卷积神经网络CNN的助力下,我们能够直接从原始的高维图片输入中自动提取特征进行End-to-End强化学习。更重要的是,我们能够将一套学习系统应用到许多不同的游戏中,且能达到人类的水准,在应用过程中不需要进行任何游戏相关的调整,不需要任何人工生成的特征,这是Nature论文Human-level control through deep reinforcement learning最大的突破所在。
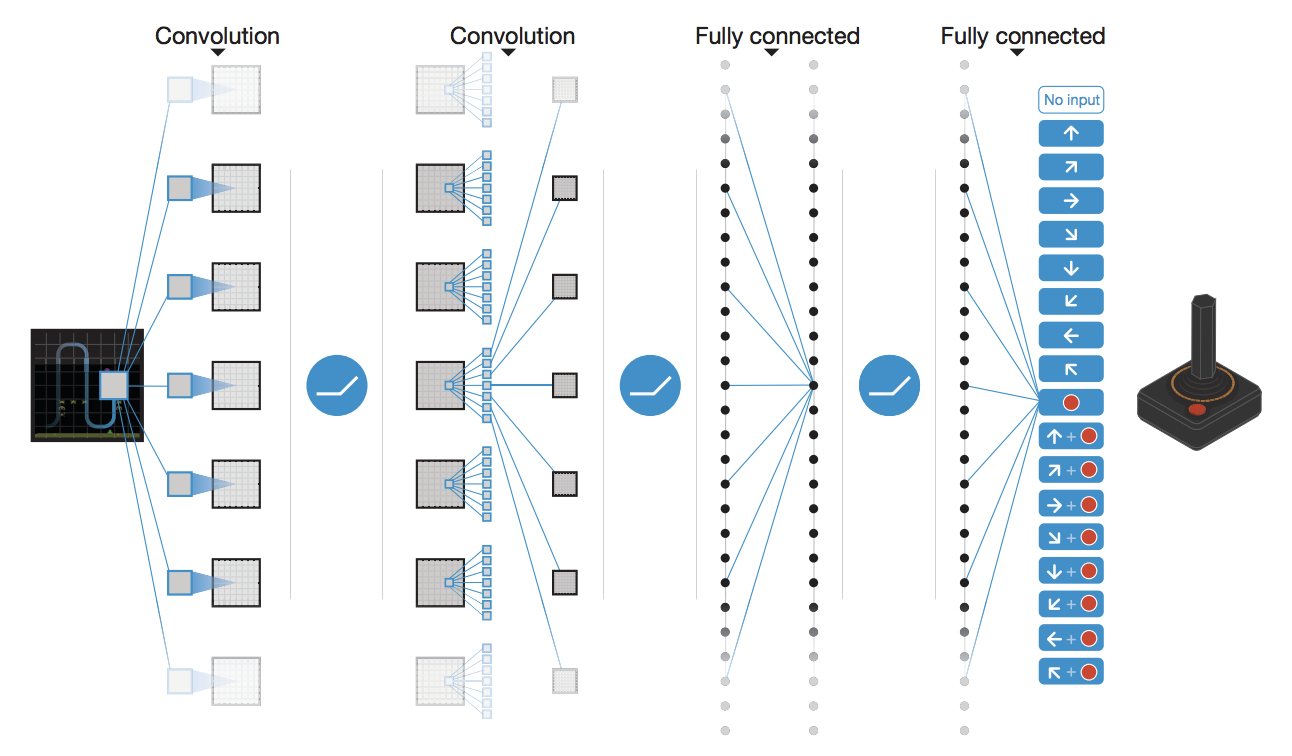
论文使用的算法是 Q-learning with non-linear function approximation 这里的非线性指的是CNN。但是非线性的函数逼近有重大的缺陷,即不能保证收敛,原因有三个。一是因为在Q-learning更新时我们没有使用真正的梯度信息:
\[w = w + \alpha\left[r + \gamma\max_{a'}{Q(s', a', w)} - Q(s, a, w)\right]\nabla{Q(s, a, w)}\]
注意此时的梯度没有包含目标值 \(r + \gamma\max_{a'}{Q(s', a', w)}\),在 \(w\) 更新的同时,目标值也在不停地变化,这种梯度方法被成为半梯度下降。
第二个原因是观测值之间的序列相关性,数据不满足独立同分布性质,这样一来就无法采用传统的监督学习方法。第三个原因是动作值很小的更新可能会产生完全不同的策略。第三点是属于基于值方法的固有缺陷,但我们可以在前两点上进行改进。
针对第一点,我们使用一个固定的Q target,这个固定的目标只会阶段性更新,这样我们就能够保证在梯度下降时目标是和参数无关的,这样就能使用真正的梯度信息。
针对第二点,我们使用经验回放方法,将经验 \((s, a, r, s')\) 存储在经验池中并随机采样,这样可以打破序列相关性。值得注意的是在使用经验回放的时候,off-policy方法是非常有必要的,因为当前的参数和生成样本的参数是不同的,Q-learning的使用变得理所当然了。然而这种方法有一个缺陷,即采样过程是随机的,给了所有样本同样的权重,这显然不合理。有一种改进方法是参考priority sweeping方法,根据TD误差的大小作为优先度进行采样。
最终的损失函数为(第 \(i\) 个循环):
\[L_i(w_i) = E_{(s, a, r, s')}\left[(r + \gamma\max_{a'}{Q(s', a', w_i^-)} - Q(s, a, w_i))^2\right]\]
CNN的输入是游戏画面84x84x4,其中4是最近的4个游戏画面。输出是动作,其个数根据游戏的不同在4到18之间浮动。也就是输入状态\(s\),输出动作状态值\(Q(s, a)\)。完整算法如下:

Game Search Tree 游戏搜索树
传统的棋类游戏解决方法是通过minimax算法和alpha-beta剪枝,其核心思想是利用DFS遍历当前局势以后所有可能的结果,通过最大化自己和最小化对方的方法获取下一步的动作。在简单的游戏如井字棋,这个方法是可行的。但是在其他游戏中,搜索树会以指数形式增长,我们无法搜索到游戏终点,所以只能做出妥协,使用值函数 \(v(s, w)\) 去逼近真实值 \(v_*(s)\),在叶节点上进行估计。如此一来,minimax算法只需要跑固定的深度即可,这就降低了搜索树的深度。在值函数选取方面,常见的值函数是二元线性值函数,每个特征都是二元的,权重通过人工进行选取。值函数表示为 \(v(s, w) = x(s) * w\)。象棋程序深蓝Deep Blue就是采用了这种方法,包含了8000个特征和人工设置的权重,使用并行的alpha-beta搜索,向前搜索16到40步,成功击败了人类象棋冠军卡斯帕罗夫。
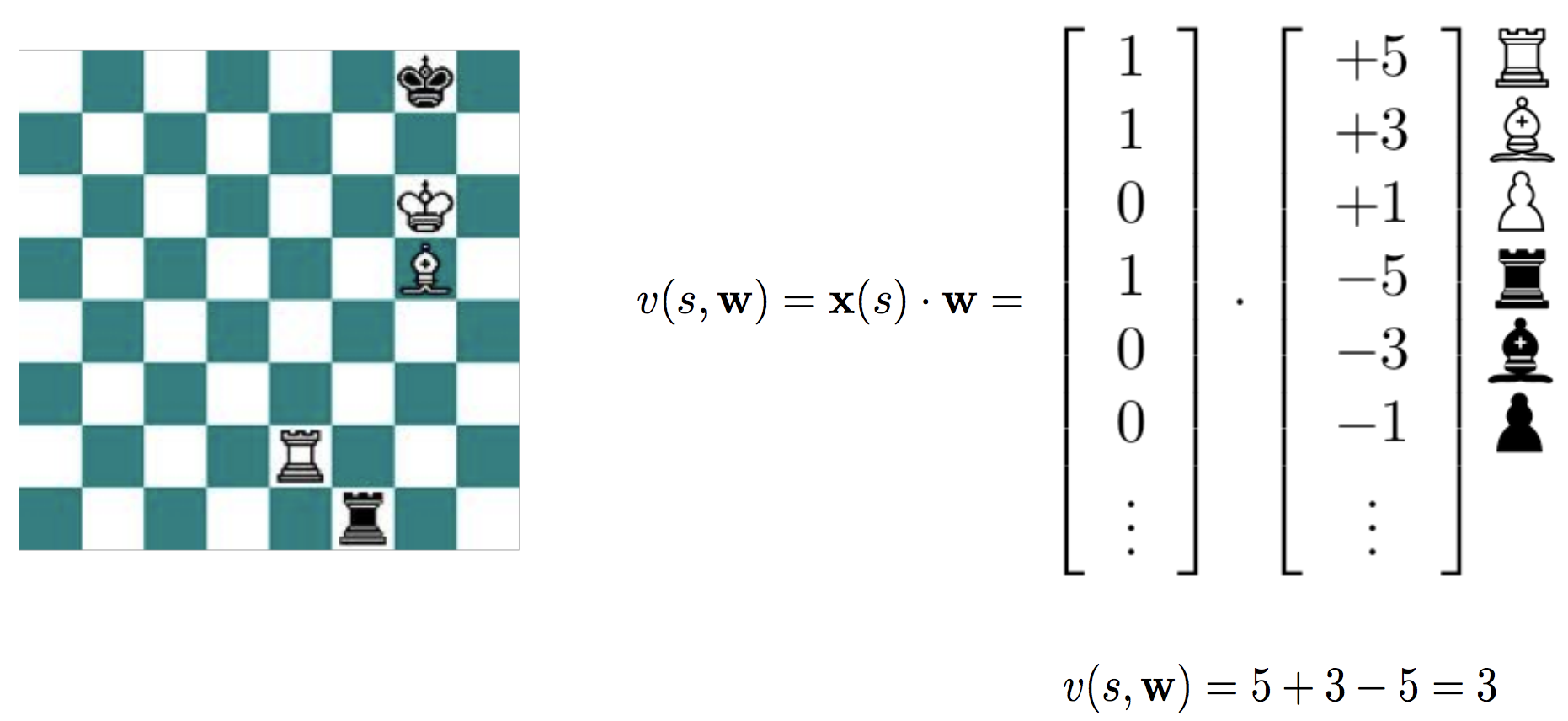
除了搜索树法,还有一种方法是自我对局强化学习。自我多局可以有多种形式,可以是字面意思,即自己执白和自己执黑对局,也可以是自己执白和策略池中随机挑选的过去某个时间的自己执黑对局,AlphaGo即采用了后者,但在这里我们讨论前者。在这种框架下,值函数的迭代(权重的更新)完全按照普通强化学习方法。有一点不同的是我们要考虑后续状态,因为棋类游戏的环境是确定的(规则已知),即 \(q(s, a) = v(succ(s, a))\)。动作的选取是基于最大最小原则:
对于白棋,最大化后续状态值,\(A_t = \arg\max v(succ(S_t, a))\)
对于黑棋,最小化后续状态值,\(A_t = \arg\min v(succ(S_t, a))\)
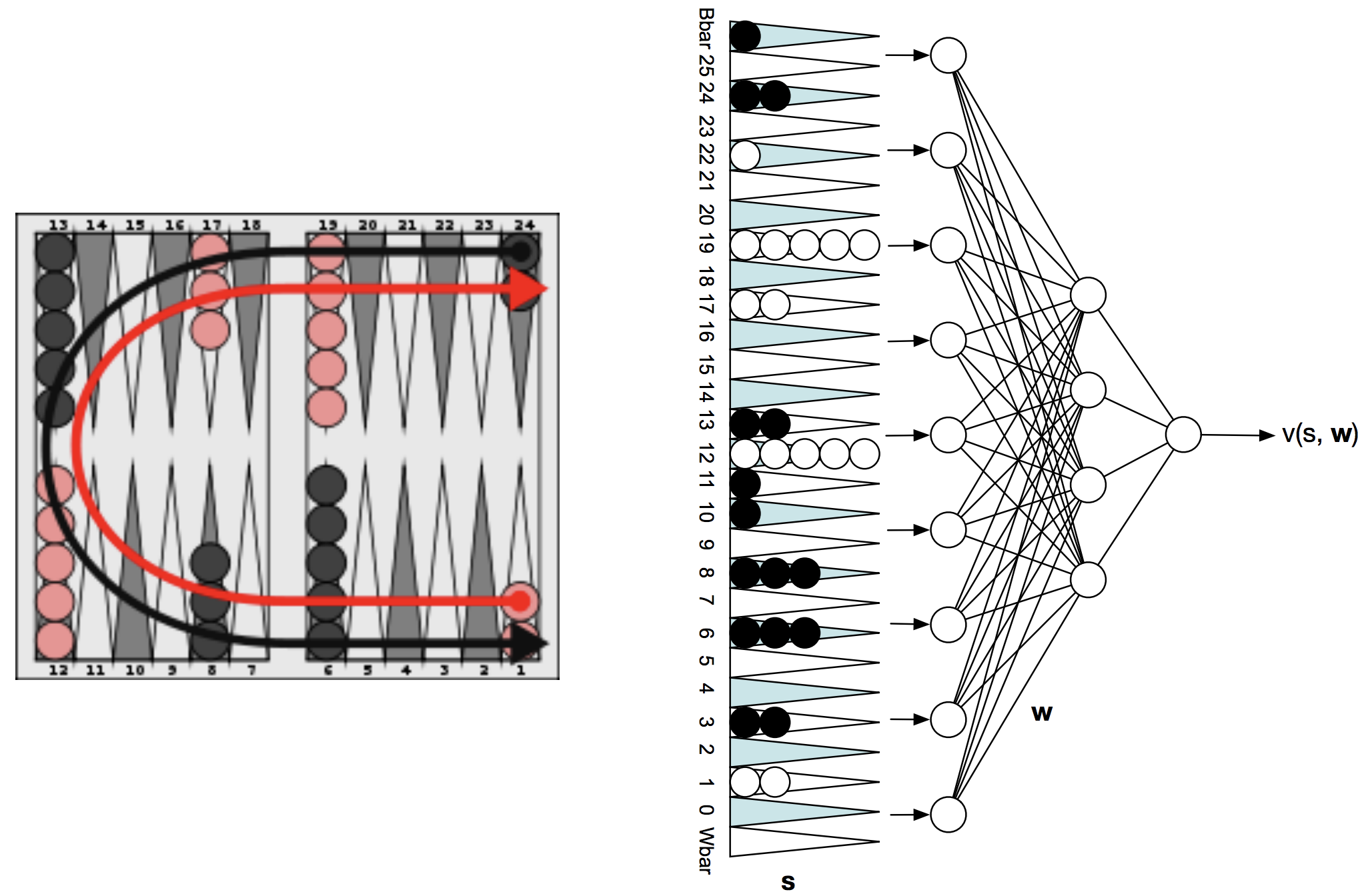
在理想情况下,最终算法能够收敛到极小极大策略,达到纳什均衡。双陆棋程序TD-Gammon就是采用了这种方法,考虑到它的树分支能达到400个,传统的启发式搜索无法像象棋那样有效地解决此类问题。于是TD-Gammon采用了 TD(\(\lambda\)) 算法结合非线性神经网络值函数,输入是当前的位置信息,输出对当前位置的值估计。它使用了自我对局生成大量的棋局样本,起初一局棋可能要花上几百步,因为神经网络权重初始化为很小的随机值,但几十局之后会表现的越来越好。在此之后TD-Gammon有过多个升级版,在此就不讲了。
然而,这种自我对局强化学习在象棋上表现的很糟糕,还是需要用到搜索树以取得更好的估计值。这就需要将搜索树法和自我对局强化学习结合起来。考虑最简单的方法,在原始的TD中,我们更新的方向是下一个状态的值,在TD leaf中,我们的更新方向变成了下一个状态的深度搜索值,即 \(v(S_t, w) = v(I_+(S_{t+1}), w)\),其中 \(I_+(s)\) 指从某节点出发达到极大极小值的叶节点。然而这种方法对搜索值利用率太低,更好的方法是TreeStrap,直接在搜索树里对每个搜索值进行更新,即 \(v(S_t, w) = v(I_+(S_{t}), w)\),但这种方法需要搜索到棋局终点。象棋程序Meep即采用了TreeStrap方法。
当搜索树的分支过多或者难以构造值函数的时候,蒙特卡洛树搜索更优于Alpha-beta搜索。我们能够通过自我对局产生大量的棋局,那么就没有必要使用传统的搜索方法了,用基于模拟经验的搜索显然更有效。最简单的当属Rollout快速走子算法,起始策略可以是个完全随机的策略,对于当前状态,从每一个可能的动作开始,根据给定的策略进行路径采样,根据多次采样的奖励和来对当前状态的行动值进行估计。当当前估计基本收敛时,会根据行动值最大的原则选择动作进入下一个状态再重复上述过程。Rollout通过借助采样降低了搜索树的广度,而且由于策略本身简单所以速度很快,因为蒙特卡洛模拟是互相独立的,所以算法天生可并行。蒙特卡洛树搜索是增强版的Rollout算法,它做出了两点主要改进,一是它会记录蒙特卡洛模拟中的值估计值用来指引后续的模拟路径朝着更高奖励的路径上走;二是采用的策略分成两类,树策略和Rollout策略。比如设置树深度为5层,树策略用于5层,之后用Rollout策略随机走到终结点,然后利用蒙特卡洛方法对值进行更新,并提升树策略。
参考文献:
[1] Human-level control through deep reinforcement learning. Mnih et al., 2015. http://www.davidqiu.com:8888/research/nature14236.pdf
[2] UCL course on Reinforcement Learning. David Silver. 2015. http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
[3] Reinforcement learning: An introduction 2nd Edition. Richard Sutton. 2018. http://www.incompleteideas.net/book/bookdraft2017nov5.pdf
[4] Temporal Difference Learning and TD-Gammon. Gerald Tesauro. 1995. http://www.bkgm.com/articles/tesauro/tdl.html
AlphaGo的前世今生(一)Deep Q Network and Game Search Tree:Road to AI Revolution的更多相关文章
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- Deep Q Network(DQN)原理解析
1. 前言 在前面的章节中我们介绍了时序差分算法(TD)和Q-Learning,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q- ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- Neural Networks and Deep Learning(week4)Deep Neural Network - Application(图像分类)
Deep Neural Network for Image Classification: Application 预先实现的代码,保存在本地 dnn_app_utils_v3.py import n ...
- 论文笔记-Deep Affinity Network for Multiple Object Tracking
作者: ShijieSun, Naveed Akhtar, HuanShengSong, Ajmal Mian, Mubarak Shah 来源: arXiv:1810.11780v1 项目:http ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
随机推荐
- Day 18 常用模块(二)
一.随机数:RANDOM 1.(0,1)小数:random.random() 2.[1,10]整数:random.randint(1,10) 3.[1,10)整数:random.randrang(1, ...
- DockerFile详解--转载
COPY 复制文件 格式: COPY ... COPY ["",... ""] 和 RUN 指令一样,也有两种格式,一种类似于命令行,一种类似于函数调用. CO ...
- mysql 设置初始密码
mysqladmin -uroot password "123" 设置初始密码 由于原密码为空,因此-p可以不用 mysqladmin -uroot -p"123&quo ...
- AsyncTask 的 get post 封装
1.get方法的封装AsyncTask public class DBUTil2 { public static interface Succee{ void onSuccee(String resu ...
- 简简单单美化你Mac os x的终端配色
Mac OS x虽然是以图形界面出名的,但是作为一个类Unix系统,还是离不开终端(shell)的,尤其是对于开发人员来说,Mac OS x默认状态的终端给人的感觉总是不那么舒服,所以很有必要对它进行 ...
- Javascript小问题
1.原生对象克隆 var clone = function(obj) { var o; if (typeof obj == "object") { if (obj === null ...
- ES - Dynamic templates 动态模板
1.ES Mapping 在lucene中,索引中每个字段都需要指定很多属性,例如:是否分词.采用哪个分词器.是否存储等. 在ES中,其实索引中每个字段也需要指定这些属性,我们有时候并没有对这些属性进 ...
- nice team小组出山啦!(第二次会议)
为什么niceteam小组一个月没有更新博客?因为我们正在埋头苦干.是的过去的一个月我们的小组成员正沉浸在知识的海洋中,今天是我们出山的好日子,特地记录一下我们的工作进度. 在项目经理的安排下,我们小 ...
- 继承RelativeLayout 自定义布局
public class HomeToolbarView extends RelativeLayout { TextView tvTitle; public HomeToolbarView(Conte ...
- 常用font-family
微软雅黑: Microsoft YaHei 宋体:SimSun 黑体:SimHei 仿宋: FangSong 楷体: KaiTi 隶书:LiSu 幼圆:YouYuan 华文细黑:STXihei 华文 ...