总结一下linux中的分段机制
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
这篇文章主要说一下linux对于分段机制的处理,虽然都说linux不使用分段机制,但是分段机制属于CPU的一个功能,即使linux不使用,也要通过代码想办法绕过它,况且linux也使用到了分段机制中的某些功能。
分段机制主要功能只有两点:
- 将物理内存划分为多个段,让操作系统可以使用大于其地址线对应的物理内存(比如正常情况下32位地址线可以访问4G大小的内存,但是有分段后则可访问大于4G的内存)。
- 权限控制,将每个段设置权限位,让不同的程序访问不同的段。
对于linux内核来说,它仅仅只使用了分段机制中的权限控制功能,具体我们可以一起看看是如何做的。
CPU的段寄存器
在CPU中,跟段有关的CPU寄存器一共有6个:cs,ss,ds,es,fs,gs,它们保存的是段选择符。而同时这六个寄存器每个都有一个对应的非编程寄存器,它们对应的非编程寄存器中保存的是段描述符。系统可以把同一个寄存器用于不同的目的,方法是先将其寄存器中的值保存到内存中,之后恢复。而在系统中最主要的是cs,ds,ss这三个寄存器。
CS 代码段寄存器:指向包含程序指令的段,在CS寄存器中RPL用于表示当前CPU的特权级(CPL),CPL为0是最高权限(内核态使用),CPL为3是用户态使用。
SS栈段寄存器:指向当前程序的栈的段。
DS 数据段寄存器:指向保存着静态数据和全局数据的段(静态区)。
在段寄存器中主要保存的是段选择符,它的长度是16位,具体如下:

索引号(index):所对应的段描述符处于GDT或LDT中的索引。
TI:TI=0表示对应段描述符保存在GDT(全局描述符表)中,TI=1表示对应的段描述符保存在LDT(局部描述符表)中。
RPL:当此对应的段选择符装入cs寄存器时,设置CPU当前的特权级的值为RPL,也就是cs寄存器中的RPL就是CPL。
段选择符主要用途就是根据段索引号和TI标志,去到GDT或者LDT中找到这个选择符对应的段描述符,比如我们在内核代码中常见的__KERNEL_CS,__KERNEL_DS,__USER_CS,__USER_DS就是段选择符,它们并不是段描述符。
全局描述符表与局部描述符表
全局描述符表和局部描述符表保存的都是段描述符,记住要把段描述符和段选择符区别开来,保存在寄存器中的是段选择符,这个段选择符会到描述符表中获取对于的段描述符,然后将段描述符保存到对应寄存器的非编程寄存器中。
系统中每个CPU有属于自己的一个全局描述符表(GDT),其所在内存的基地址和其大小一起保存在CPU的gdtr寄存器中。其大小为64K,一共可保存8192个段描述符,不过第一个一般都会置空,也就是能保存8191个段描述符。第一个置空的原因是防止加电后段寄存器未经初始化就进入保护模式而使用GDT。
而对于局部描述符表,CPU设定是每个进程可以创建属于自己的局部描述符表(LDT),当前被使用的LDT的基地址和大小一起保存在ldtr寄存器中。不过大多数用户态的liunx程序都不使用局部描述符表,所以linux内核只定义了一个缺省的LDT供大多数进程共享。描述这个局部描述符表的局部描述符表描述符保存在GDT中。
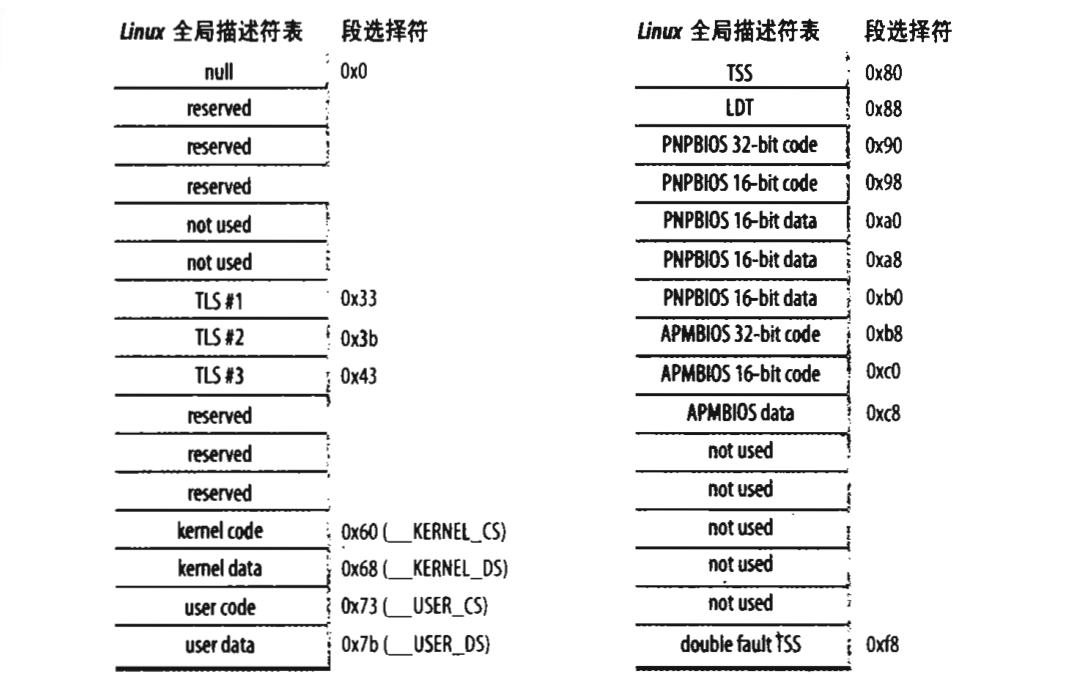
对于表中的段描述符我们简单说几个特别的:
TLS段描述符:中文名字是局部线程存储段,这个会允许线程拥有自己的段,不过一般程序不经常会用到的,系统调用set_thread_area()与get_thread_area()为当前进程创建和撤销一个TLS段。
TSS段描述符:叫做任务状态段,这个描述符非常重要,每个处理器包含一个自己的tss段,这个tss段中的主要数据是一个tss_struct结构体,linux会将所有CPU的tss_struct结构体以init_tss数组的形式保存起来,这个tss_struct结构体中保存的时当前运行进程的内核态堆栈栈顶地址和当前进程的IO许可权限位。当进程切换时就会设置CPU的tss_struct结构体,CPU就可以从tss_struct中获取当前进程的内核栈和IO许可权限。
kernel code,kernel data,user code,user data:分别是内核代码段描述符,内核数据段描述符,用户代码段描述符,用户数据段描述符,不同的进程会使用同一个用户代码段/数据段描述符,这个也之后介绍。
段描述符
段描述符就是保存在全局描述符表或者局部描述符表中,当某个段寄存器试图通过自己的段选择符获取对于的段描述符时,会将获取到的段描述符放到自己的非编程寄存器中,这样就不用每次访问段都要跑到内存中的段描述符表中获取。
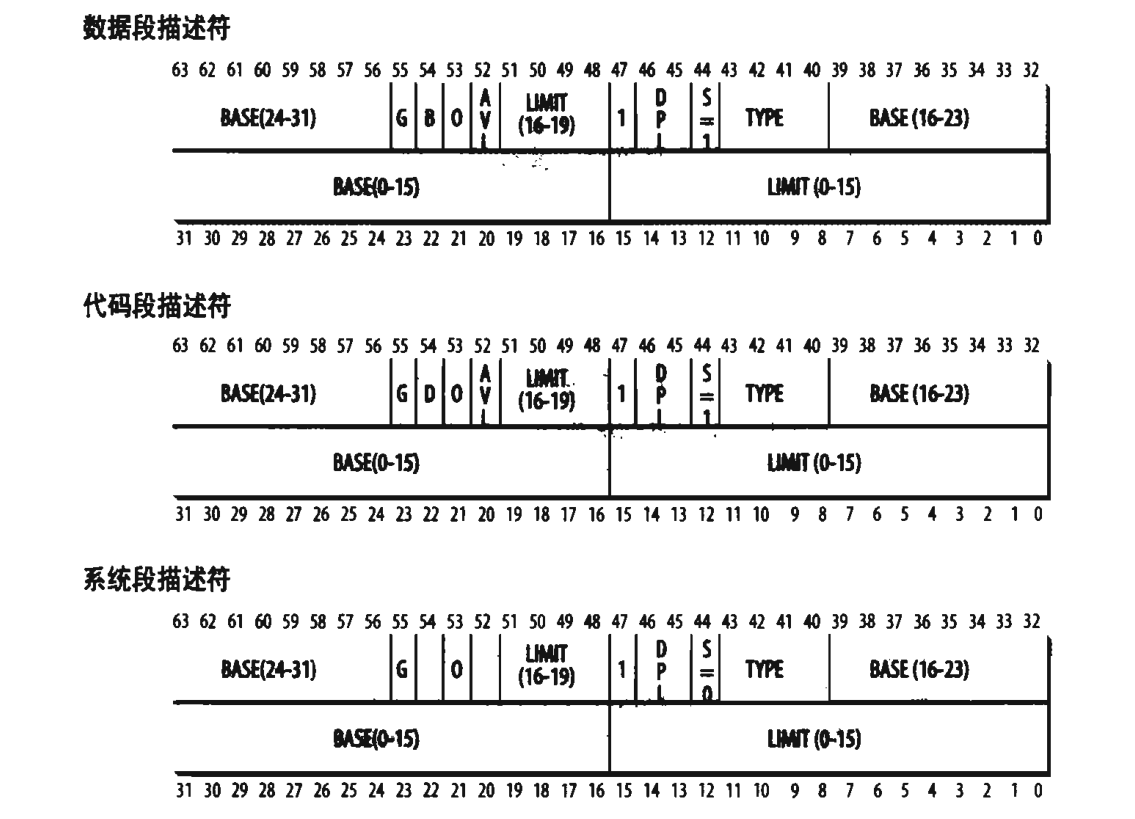
BASE(32位):段首地址的线性地址。
G:为0代表此段长度以字节为单位,为1代表此段长度以4K为单位。
LIMIT(20位):此最后一个地址的偏移量,也相当于长度,G=0,段大小在1~1MB,G=1,段大小为4KB~4GB。
S:为0表示是系统段,否则为代码段或数据段。
Type:描述段的类型和存取权限。
DPL:描述符特权级,表示访问这个段CPU要求的最小优先级(保存在cs寄存器的CPL特权级),当DPL为0时,只有CPL为0才能访问,DPL为3时,CPL为0为3都可以访问这个段。
P:表示此段是否被交换到磁盘,总是置为1,因为linux不会把一个段都交换到磁盘中。
D或B:如果段的LIMIT是32位长,则置1,如果是16位长,置0。(详见intel手册)
AVL:忽略。
数据段描述符:
表示这个段描述符代表一个数据段,这种描述符可以放在GDT或者LDT。该描述符的S标志位为1,也就是非系统段。需要注意内核数据段属于数据段描述符,并不属于系统段描述符。
代码段描述符:
表示这个段描述符代表一个数据段,这种描述符可以放在GDT或者LDT。该描述符的S标志位为1,也就是非系统段。需要注意内核代码段属于代码段描述符,并不属于系统段描述符。
系统段描述符:
此描述符代表一个系统段,Type的值代表了是哪一种系统段,S标志位为0。其中以下两种都是系统段
局部描述符表描述符(LDTD,系统段描述符的一种):
此种描述符代表一个包含有LDT的段,它只能保存在GDT中,相应的Type为2,S为0。
任务状态段描述符(TSSD,系统段描述符的一种):
这个描述符代表一个任务状态段(TSS),这个段用于保存部分处理器寄存器的内容(内核态栈地址和IO许可权限位),它只保存在GDT中,根据相应的进程是否正在CPU上运行,其Type字段的值分别为11或9.这个描述符S标志为0。
在所有段描述符中可能大家最关心的就是内核代码段描述符和内核数据段描述符以及用户代码段描述符和用户数据段描述符了,这里也具体说说这几个描述符,它们的构成如下:

可以看出来它们的S都是1,都是非系统段,注意并不是内核用的段就是系统段,这里的系统段的区分不是我们用户态和内核态的这种划分。所有的用户进程都是使用同一个用户代码段描述符和用户数据段描述符,它们是__USER_CS和__USER_DS,也就是每个进程处于用户态时,它们的CS寄存器和DS寄存器中的值是相同的。当任何进程或者中断异常进入内核后,都是使用相同的内核代码段描述符和内核数据段描述符,它们是__KERNEL_CS和__KERNEL_DS。这里要明确记得,内核数据段实际上就是内核态堆栈段。
还可以看出这几个段的BASE都是0x00000000,LIMIT都是0xfffff,并且G为1。也就是说,用户代码段,用户数据段,内核代码段,内核数据段这四个段它们的寻址地址都是0x00000000~0xffffffff。也就是地址0到4G的大小。这也形成了为什么所有进程都可以使用同一个用户代码段和用户数据段的条件。并且很清楚地可以看出,内核代码段和内核数据段都需要CPL为0时才能访问,而用户代码段和用户数据段在CPL为0或者3时都可以访问。
再看看这4个段描述符对应的段选择符:

可以看出来,它们的TI为0,表示都保存在全局段描述符表中。可能看到这里大家会有个疑问,既然用户段的RPL为3,那怎么去访问DPL为0的内核段呢,这就是linux精明的地方,它就是禁止用户态访问内核态的数据,但是内核为用户态开了两个小门,然用户态能够通过这两个小门进入到内核态中,这两个小门就是系统调用与中断和异常。
快速访问段描述符:
先看一下系统是如何将逻辑地址转换为线性地址的:
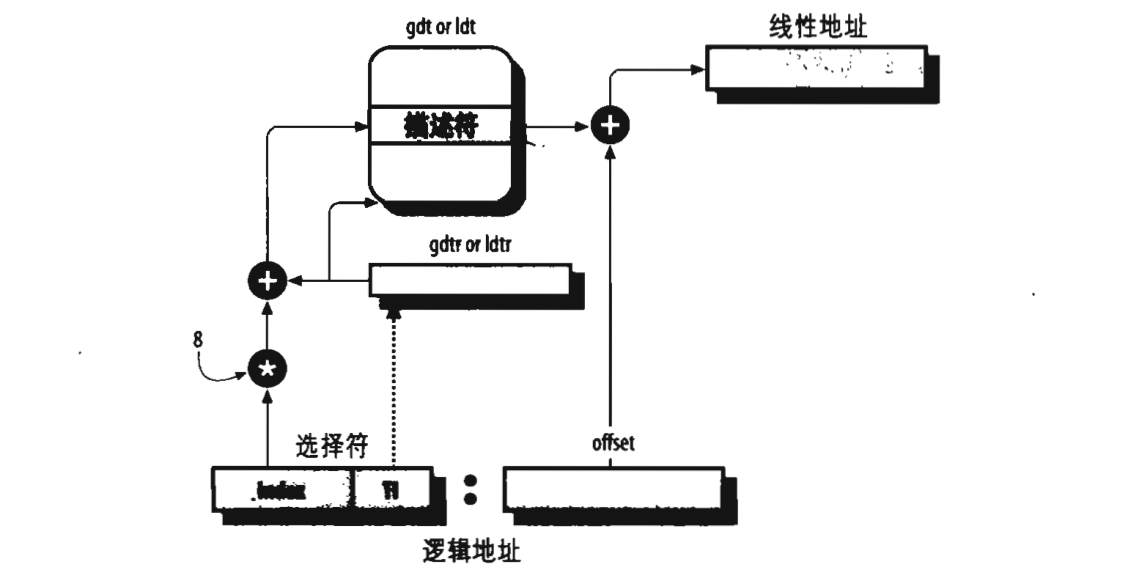
逻辑地址是由段选择符(16位) + 段内偏移量offset(32位)得来。之前也说到,只有处于用户态,CS和DS寄存器中的值都是__USER_CS和__USER_DS。只要处于内核态,CS和DS寄存器中的值都是__KERNEL_CS和__KERNEL_DS。在我们编程过程中,实际上提供的地址都是一个偏移量,系统会自动将这个偏移量与CS中的段选择符进行结合。也就是我们使用的逻辑地址实际上只使用了offset这一段,段选择符都为空。之前也说了这四个段描述符的BASE都为0x00000000,也得出当逻辑地址通过这样的分段机制转为线性地址后,实际上并没有变化,也就是逻辑地址=线性地址(其实这两个地址都是offset的值)。
也可以看出来,每次进行地址转换时都要通过段描述符获取段的基地址然后与偏移量运算得到线性地址,而段描述符是保存在内存当中的,这样每次转换难道就要访问一次内存或者cache吗?当然不是,之前说到一共有6种段寄存器,它们每个都有属于自己的一个非编程寄存器,专门用于存放现在的段描述符,比如拿cs段寄存器说,cs寄存器存放的是段选择符,所以每次通过逻辑地址访问这个段里的内容时,都要通过这个段选择符与gdtr(段描述符保存在全局描述符表中)或者ldtr(段描述符保存在局部描述符表中)结合然后从内存中得到对应的段描述符,然后根据段描述符的BASE和LIMIT将逻辑地址转换为线性地址。如果进行连续访问时(而且连续访问的概率非常高),这样的效率就非常低了,这个cs段寄存器对应的非编程寄存器就是用于保存这个段描述符的,这样就不用每次都从内存中获取段描述符,而是直接从这个CS对应的非编程寄存器中获取段描述符。
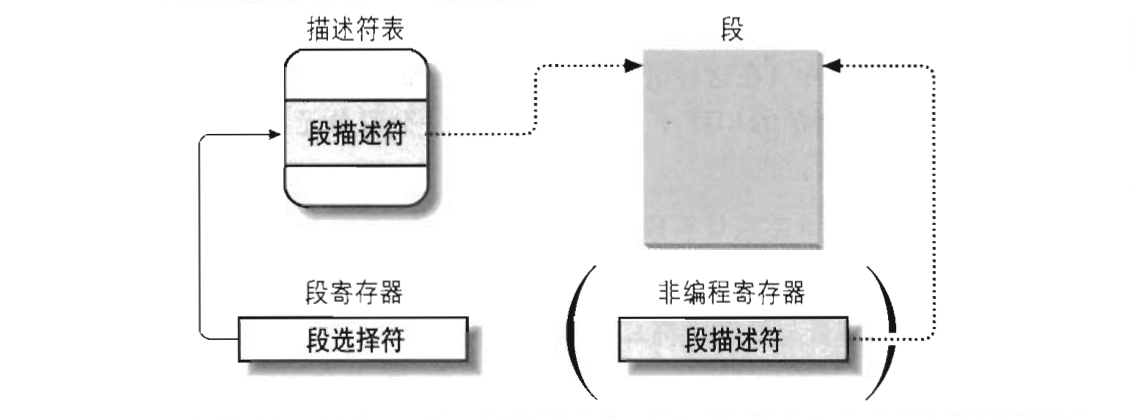
任务状态段(TSS)
任务状态段的段选择符保存在tr寄存器中,内核为每个CPU准备了一个任务状态段,其主要保存的是当前进程的IO许可权限位和栈顶指针,其作用主要有两个:
- 进程从用户态切换到内核态时,系统会从该CPU的TSS中获取该进程的内核态堆栈地址。
- 当用户态进程试图通过in或out指令访问一个IO端口时,CPU需要访问存放在TSS中的IO许可权限位以检查该进程是否有权限访问该IO端口。
TSS段的保存形式是一个tss_struct结构体,系统会将所有CPU的tss_struct结构体组成一个init_tss数组的形式进行保存,我们具体看一下tss_struct结构体:
- struct tss_struct {
- /*
- * The hardware state:
- */
- /* 存放寄存器的值的结构体,保存有栈顶指针SP寄存器的值 */
- struct x86_hw_tss x86_tss;
- /*
- * The extra 1 is there because the CPU will access an
- * additional byte beyond the end of the IO permission
- * bitmap. The extra byte must be all 1 bits, and must
- * be within the limit.
- */
- /* 当前进程的IO许可权限位 */
- unsigned long io_bitmap[IO_BITMAP_LONGS + ];
- /*
- * .. and then another 0x100 bytes for the emergency kernel stack:
- */
- /* 紧急内核栈 */
- unsigned long stack[];
- } ____cacheline_aligned;
- struct x86_hw_tss {
- u32 reserved1;
- u64 sp0;
- u64 sp1;
- u64 sp2;
- u64 reserved2;
- u64 ist[];
- u32 reserved3;
- u32 reserved4;
- u16 reserved5;
- u16 io_bitmap_base;
- } __attribute__((packed)) ____cacheline_aligned;
中断或异常发生时的段切换
其实发生段的切换有两种情况,一种是系统调用发生时,一种是中断或异常发生时,但是这两种情况都大同小异,这里我们只拿中断异常发生的情况进行说明。
这里只说明系统大多数发生的情况,不讨论个例。假定当前系统处于用户态执行代码中,这时候各个段寄存器的值应该是这样的:
- CS: __USER_CS
- DS: __USER_DS
- SS: 保存着用户态栈基地址
- ESP: 保存着用户态栈顶地址
- EIP: 保存下条将要执行的指令地址
当中断或异常发生时,CPU会按照如下步骤进行执行:
- 读取由idtr寄存器保存的IDT(中断向量表)中对应的门描述符。
- 根据对应的门描述符,获取其中保存的段选择符。(门描述符中保存有一个段选择符和一个门的DPL,这两个部分是段切换的重要部分。具体可看我的博客:http://www.cnblogs.com/tolimit/p/4415348.html)
- 根据这个段选择符获取对于的段描述符(门描述符中保存的段选择符基本都是__KERNEL_CS)。
- 这时CPU会使用CS寄存器中的CPL特权级与获取的段描述符的DPL特权级比较,如果DPL<=CPL,则通过,否则产生“通用保护”异常,我们也看到,我们CS保存的是__USER_CS,其CPL为3,门描述符中保存的是__KERNEL_CS,其DPL为0,;也就是会通过检查。
- 如果是异常情况,这时还会多一步进行检查,会检查门描述符中的DPL特权级,当前特权级CPL的值 > DPL的值时,则通过检查,否则不能通过检查,而只有系统门和系统中断门的DPL是3,其他的异常门的DPL都为0。这样做的好处是避免了用户程序访问陷阱门、中断门和任务门。
- 到这里检查已经通过,如果特权级发生变化(用户态产生的中断和异常,肯定会发生特权级变化),则CPU会自动帮切换不同特权级使用的寄存器。
- 从tr寄存器中获取CPU的TSS段,从TSS段中获取当前进程的内核态堆栈指针和SS寄存器的值并将它们装载到SS和EIP寄存器。
- 在当前进程的内核栈中保存用户态的SS寄存器和EIP寄存器的值。(注意,这里是先装载了SS和EIP寄存器,让其指向内核栈,再在内核栈中保存用户态的SS和EIP寄存器值)
- 如果故障已经发生,用引起异常的指令地址装载到CS和EIP寄存器,从而使这条指令再次被执行。
- 在内核栈中保存用户态的eflags、CS和EIP。CS和EIP的值就是返回后的下一条指令地址。如果有硬件出错码,也保存到内核栈中。
- 从中断向量表的门中获取CS和EIP值并装载到CS和EIP寄存器。门中保存的CS和EIP合起来就会是中断处理程序入口地址。
这些步骤执行完后,寄存器变化为:
- CS: __KERNEL_CS
- DS: __USER_DS
- SS: 保存着内核态栈基地址
- ESP: 保存着内核态栈顶地址
- EIP: 保存着中断处理程序入口地址
而内核栈中保存的值有:用户态CS,用户态SS,用户态ESP,用户态EIP,用户态eflags。当系统从中断返回用户态时,就会从内核栈中将这些值还原,最后会回到进入时的情况。至于为什么不用修改DS寄存器的值,我也不清楚。
总结一下linux中的分段机制的更多相关文章
- linux中的分段和分页
http://blog.csdn.net/hguisu/article/details/6152921 Linux 内存管理 觉得这篇文章写分段和分页机制还是挺清晰的,在此转载一下. 前一段时间看了& ...
- 浅谈Linux中的信号处理机制(二)
首先谢谢 @小尧弟 这位朋友对我昨天夜里写的一篇<浅谈Linux中的信号处理机制(一)>的指正,之前的题目我用的“浅析”一词,给人一种要剖析内核的感觉.本人自知功力不够,尚且不能对着Lin ...
- Linux中的保护机制
Linux中的保护机制 在编写漏洞利用代码的时候,需要特别注意目标进程是否开启了NX.PIE等机制,例如存在NX的话就不能直接执行栈上的数据,存在PIE 的话各个系统调用的地址就是随机化的. 一:ca ...
- LINUX中的RCU机制的分析
RCU机制是Linux2.6之后提供的一种数据一致性访问的机制,从RCU(read-copy-update)的名称上看,我们就能对他的实现机制有一个大概的了解,在修改数据的时候,首先需要读取数据,然后 ...
- linux中的tasklet机制【转】
转自:http://blog.csdn.net/yasin_lee/article/details/12999099 转自: http://www.kerneltravel.net/?p=143 中断 ...
- linux中的阻塞机制及等待队列
阻塞与非阻塞是设备访问的两种方式.驱动程序需要提供阻塞(等待队列,中断)和非阻塞方式(轮询,异步通知)访问设备.在写阻塞与非阻塞的驱动程序时,经常用到等待队列. 一.阻塞与非阻塞 阻塞调用是没有获得资 ...
- linux中的阻塞机制及等待队列【转】
转自:http://www.cnblogs.com/gdk-0078/p/5172941.html 阻塞与非阻塞是设备访问的两种方式.驱动程序需要提供阻塞(等待队列,中断)和非阻塞方式(轮询,异步通知 ...
- Linux中同步互斥机制研究之原子操作
操作系统中,对共享资源的访问需要有同步互斥机制来保证其逻辑的正确性,而这一切的基础便是原子操作. | 原子操作(Atomic Operations): 原子操作从定义上理解,应当是类似原子的,不 ...
- 浅谈Linux中的信号处理机制(一)
有好些日子没有写博客了,自己想想还是不要荒废了时间,写点儿东西记录自己的成长还是百利无一害的.今天是9月17号,暑假在某家游戏公司实习了一段时间,做的事情是在Windows上用c++写一些游戏英雄技能 ...
随机推荐
- Mycat 中间件配置初探与入门操作
Mycat中间件配置初探与入门操作 By:授客 QQ:1033553122 实践环境 Mycat-server-1.5.1-RELEASE-20161130213509-win.tar.gz 下载地址 ...
- 微信小程序开发之初探
本文是以一个简单的小例子,来简要讲解微信小程序开发步骤,希望促进学习分享. 概念 微信小程序,简称小程序,缩写xcx,英文mini program.是一种不需要下载安装即可使用的应用,它实现了应用“触 ...
- 测试系统工程师TSE的职责与培养
测试系统工程师TSE的职责与培养 研发资深顾问 杨学明 如今,国内所有的研发型的公司都有测试部门,无论测试团队大小,都有测试组长,测试经理,测试工程师等头衔,但随着产品和业务的质量要求越来越高,产品的 ...
- Fiddler做代理服务器时添加X-Forwarder-For转发真实客户端ip
修改CustomRules.js 菜单: Rules->Customize Rules (ctrl+R) 在 static function OnBeforeRequest(oSession: ...
- mysql初始化提示安装perl
all_db --user=mysql --datadir=/data/mysql", "delta": "0:00:00.222500", &quo ...
- MySQL 查看用户授予的权限
在MySQL中,如何查看一个用户被授予了那些权限呢? 授予用户的权限可能分全局层级权限.数据库层级权限.表层级别权限.列层级别权限.子程序层级权限.具体分类如下: 全局层级 全局权限适用于一个给定 ...
- 老K漫谈区块链的共识(1)——免信任的共识机制
老k,柏链道捷CTO.清华阿尔山区块链研究中心高级工程师,超过17年的系统软件开发经验,在操作系统.编译器.虚拟机和符号执行方面都有实战经验.主持开发多个开眼项目,目前主要从事区块链底层系统开发工作. ...
- Linux下键盘值 对应input_evnet的code值。
最近做了一个linux下面的模拟鼠标和键盘的app,但不是很清楚字符对应的键值:查找内核源码,在kernel/include/uapi/linux/input.h文件中找到: 下面给出普通键盘上面对应 ...
- php学习----错误处理和代码重用
php错误处理 一.错误分类:1.语法错误 2.运行时错误 3.逻辑错误 错误代号(部分): 所有看到的错误代码在php中都被定义为系统常量(可以直接使用) 1)系统错误 E_PARSE:编译错误,代 ...
- mysql数据库显示 1164 table *** doesn't exist
问题出现场景: 以前mysql安装在C盘,后来重装系统,将mysql安装在了D盘,重装之前,将mysql的Data 文件夹备份了下来,mysql重新安装好之后,将原来的Data 文件夹内的数据库文件夹 ...