【转】Java HashMap的死循环
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
但是在这里我们可以来研究一下原因。
Hash表的数据结构
我需要简单地说一下HashMap这个经典的数据结构。
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷(可参看《Hash Collision DoS问题》)。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的threshold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重新算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。
put一个key-value对到Hash表中:
- public V put(K key, V value)
- {
- ......
- //算Hash值
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- //如果该key已被插入,则替换掉旧的value (链接操作)
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- //该key不存在,需要增加一个结点
- addEntry(hash, key, value, i);
- return null;
- }
当我们往HashMap中put元素时,现根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位置上已经存放有其它元素了,那么在同一个位置上的元素将以链表的形式存放,新加入的放在链头,而先前加入的放在链尾。
检查容量是否超标
- void addEntry(int hash, K key, V value, int bucketIndex)
- {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
- //查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
- if (size++ >= threshold)
- resize(2 * table.length);
- }
新建一个更大尺寸的Hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
- void resize(int newCapacity)
- {
- Entry[] oldTable = table;
- int oldCapacity = oldTable.length;
- ......
- //创建一个新的Hash Table
- Entry[] newTable = new Entry[newCapacity];
- //将Old Hash Table上的数据迁移到New Hash Table上
- transfer(newTable);
- table = newTable;
- threshold = (int)(newCapacity * loadFactor);
- }
迁移的源代码,注意高亮处:
- void transfer(Entry[] newTable)
- {
- Entry[] src = table;
- int newCapacity = newTable.length;
- //下面这段代码的意思是:
- // 从OldTable里摘一个元素出来,然后放到NewTable中
- for (int j = 0; j < src.length; j++) {
- Entry<K,V> e = src[j];
- if (e != null) {
- src[j] = null;
- do {
- Entry<K,V> next = e.next;
- int i = indexFor(e.hash, newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while (e != null);
- }
- }
- }
好了,这个代码算是比较正常的。而且没有什么问题。
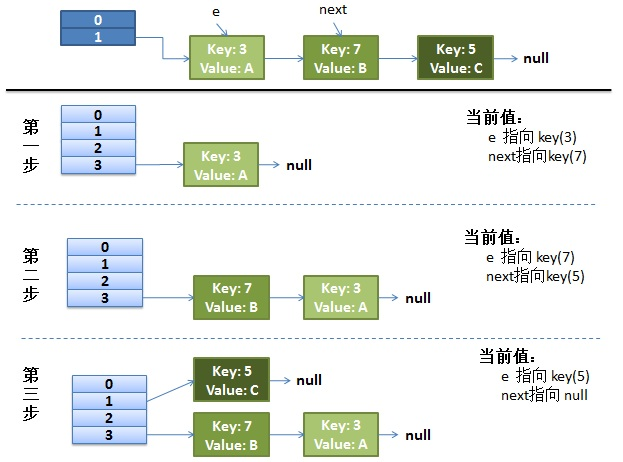
正常的ReHash的过程
画了个图做了个演示。
- 假设我们的hash算法就是简单的用key mod一下表的大小(也就是数组的长度)
- 最上面的是old hash表,其中的Hash表的size = 2,所以key = 3,7,5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表resize为4,然后所有的<key,value>重新rehash的过程(每一步表示一次循环)
并发下的ReHash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下transfer代码中的这个细节:
- do {
- Entry<K,V> next = e.next; // 假设线程一执行到这里就被调度挂起了
- int i = indexFor(e.hash,newCapacity);
- e.next = newTable[i];
- newTable[i] = e;
- e = next;
- } while(e != null);
而我们的线程二执行完成了。(注意:这里的执行完成是指do...while循环执行 完毕,且HashMap中成员变量table已更新为线程二持有的newTable。注意!!!线程一和线程二进去transfer()后,newTable实际上是两个)于是我们有下面的这个样子。
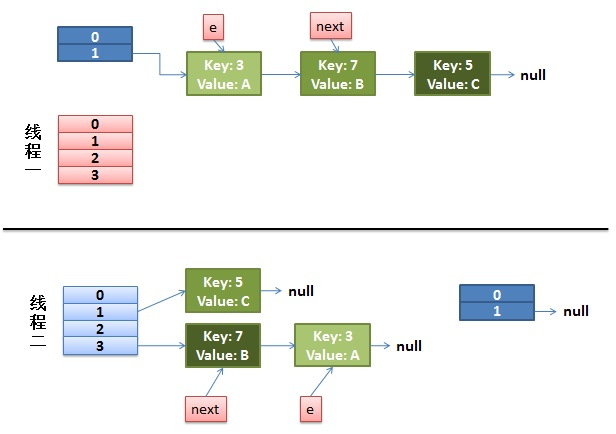
注意,因为Thread1的e指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转了。
2)线程一被调度回来执行
- 先是执行newTable[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
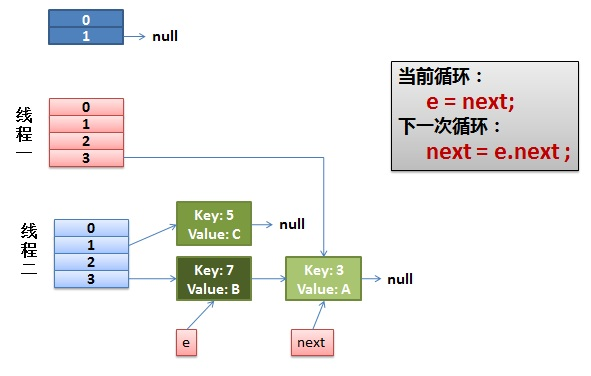
3)目前为止一切还是好的。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
4)环形链表出现。
e.next = newTable[i]导致key(3).next指向了key(7)
注意:此时的key(7).next已经指向了key(3),环形链表出现。
接着newTable[i] = e,即把key(3)摘下来,放到newTable[i]的第一个,然后把e和往下移(e = next),此时next为null,执行后e和next都指向null,进行while判断为false,跳出do...while循环。
可以看到,实际上3这个元素被transfer了2次。
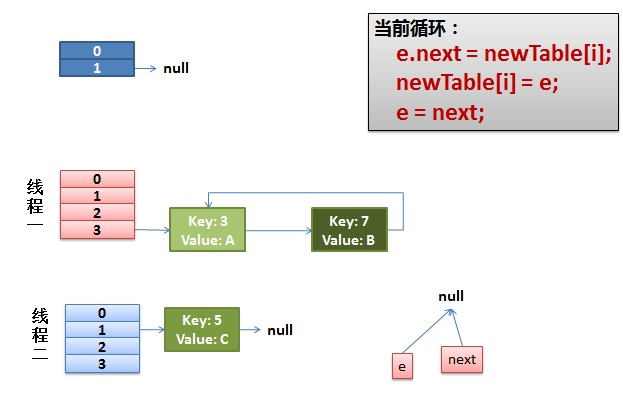
而后HashMap中成员变量table即变为上面新生成的newTable(参看resize()函数中执行完transfer()函数的下一句:table = newTable)。
此后,若get()方法取key值时需要到table[3]下的链表中去查找时,比如get(11)时,就会出现Infinite Loop。附上HashMap的get()方法:
- public V get(Object key) {
- //如果key为null,则直接去table[0]处去检索即可。
- if (key == null)
- return getForNullKey();
- Entry<K,V> entry = getEntry(key);
- return null == entry ? null : entry.getValue();
- }
- final Entry<K,V> getEntry(Object key) {
- if (size == 0) {
- return null;
- }
- //通过key的hashcode值计算hash值
- int hash = (key == null) ? 0 : hash(key);
- //indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next) {
- Object k;
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- }
- return null;
- }
get(11)时,因为环形链表的缘故,e一直等不到null的情况,且key值为11在这段环形链表中(只有key值为3和7)又没有,所以也不会return,即程序会一直死循环在这里!
实际上,put的时候,当访问到那段环形链表时,也会造成死循环。
转载自《疫苗:JAVA HASHMAP的死循环》
【转】Java HashMap的死循环的更多相关文章
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- Java HashMap的死循环
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造 成Race Condition,从而导致死循环.这个事情我4 ...
- Java HashMap并发死循环
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环.这个事情我4. ...
- 疫苗:JAVA HASHMAP的死循环
在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环.这个事情我4. ...
- Java HashMap的死循环 以及 LRUCache的正确实现
今天RP爆发,16核服务器load飙到30多,cpu使用情况全部99%以上. 从jstack中分析发现全部线程都堵在map.transfer处,如下: "pool-10-thread-23& ...
- 多线程下HashMap的死循环问题
多线程下[HashMap]的问题: 1.多线程put操作后,get操作导致死循环.2.多线程put非NULL元素后,get操作得到NULL值.3.多线程put操作,导致元素丢失. 本次主要关注[Has ...
- Java - HashMap 多线程安全解析
HashMap多线程并发问题分析 多线程put后可能导致get死循环 从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题.后来,我们的程序性能有问 ...
- JDK(九)JDK1.7源码分析【集合】HashMap的死循环
前言 在JDK1.7&1.8源码对比分析[集合]HashMap中我们遗留了一个问题:为什么HashMap在调用resize() 方法时会出现死循环?这篇文章就通过JDK1.7的源码来分析并解释 ...
- 图解集合5:不正确地使用HashMap引发死循环及元素丢失
问题引出 前一篇文章讲解了HashMap的实现原理,讲到了HashMap不是线程安全的.那么HashMap在多线程环境下又会有什么问题呢? 几个月前,公司项目的一个模块在线上运行的时候出现了死循环,死 ...
随机推荐
- Ubuntu调节屏幕亮度
下面的方式支持双屏,最多支持四个屏幕调节亮度. sudo add-apt-repository ppa:apandada1/brightness-controller sudo apt-get upd ...
- Nginx 简单安装
关于nginx的介绍:http://baike.baidu.com/link?url=UZjpP8y4MUgrjqACfxd7c3Cm4L8PnJsKkxSJQ3CrRcKZUjkkl4zGNs6Pr ...
- Python——安装requests第三方库
使用pip安装 在cmd下cd到这个目录下C:\Python27\Scripts,然后执行pip install requests 在cmd 命令行执行 E: 进入e盘 cd Python\pr ...
- 理解self与this
刚开始学习Python的类写法的时候觉得很是麻烦,为什么定义时需要而调用时又不需要,为什么不能内部简化从而减少我们敲击键盘的次数?你看完这篇文章后就会明白所有的疑问. self代表类的实例,而非类. ...
- HDU 6433(2的n次方 **)
题意是就是求出 2 的 n 次方. 直接求肯定不行,直接将每一位存在一个数组的各个位置即可,这里先解出 2 的 n 次方的位数,再直接模拟每一位乘以 2 即可得到答案. 求解 2 的 n 次方的位数的 ...
- std::rotate使用
1. 进行元素范围上的左旋转 first - 原范围的起始 n_first - 应出现在旋转后范围起始的元素 last - 原范围的结尾 原来:1 2 3 左旋转后(起始元素是2) : 2 3 1
- 混合app开发--js和webview之间的交互总结
使用场景:原生APP内嵌套H5页面,app使用的是webview框架进行嵌套 这样就存在两种情况 1.原生app调用H5的方法 2.H5调用app的方法 分别讲解下,其实app与H5之间的交互式非常简 ...
- oracle字符串提取记录
背景:需要限制用户操作次数,而用户操作次数只有统一的日志表有记录. 并且,因为在批量查询中也需做限制,所有需要一次查询多条数据,保证效率.后来采用视图做的 视图 instr 查找字符串,返回起始坐标, ...
- 细说log4j之log4j 2.x
官网:https://logging.apache.org/log4j/2.x/ 1. 主要组件: 从图中可以看出,log4j2中的主要组件为:Filter,Appender,Logger,他们的层次 ...
- 3.1HashMap源码分析
在前篇博文中(HashMap原理及实现学习总结)详细总结了HashMap的原理及实现过程,这一篇是对HashMap的源码分析. package dataStructure.hash; import j ...