【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083
DQN(Deep Q-Learning)是将深度学习deeplearning与强化学习reinforcementlearning相结合,实现了从感知到动作的端到端的革命性算法。使用DQN玩游戏的话简直6的飞起,其中fladdy bird这个游戏就已经被DQN玩坏了。当我们的Q-table他过于庞大无法建立的话,使用DQN是一种很好的选择
1、算法思想
DQN与Qleanring类似都是基于值迭代的算法,但是在普通的Q-learning中,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q-Table不动作空间和状态太大十分困难。
所以在此处可以把Q-table更新转化为一函数拟合问题,通过拟合一个函数function来代替Q-table产生Q值,使得相近的状态得到相近的输出动作。因此我们可以想到深度神经网络对复杂特征的提取有很好效果,所以可以将DeepLearning与Reinforcement Learning结合。这就成为了DQN
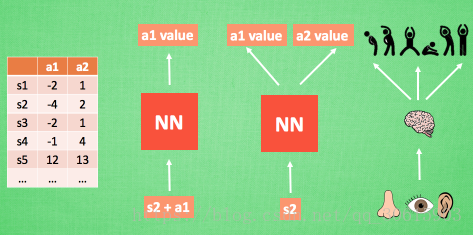
DL与RL结合存在以下问题 :
- DL是监督学习需要学习训练集,强化学习不需要训练集只通过环境进行返回奖励值reward,同时也存在着噪声和延迟的问题,所以存在很多状态state的reward值都是0也就是样本稀疏
- DL每个样本之间互相独立,而RL当前状态的状态值是依赖后面的状态返回值的。
- 当我们使用非线性网络来表示值函数的时候可能出现不稳定的问题
DQN中的两大利器解决了以上问题
- 通过Q-Learning使用reward来构造标签
- 通过experience replay(经验池)的方法来解决相关性及非静态分布问题
- 使用一个MainNet产生当前Q值,使用另外一个Target产生Target Q
2、experience replay 经验池
经验池DQN中的记忆库用来学习之前的经历,又因为Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历,所以在学习过程中随机的加入之前的经验会让神经网络更有效率。
所以经验池解决了相关性及非静态分布问题。他通过在每个timestep下agent与环境交互得到的转移样本 $(s_t,a_t,r_t,s_{t+1})$ 储存到回放记忆网络,要训练时就随机拿出一些(minibatch)来训练因此打乱其中的相关性。
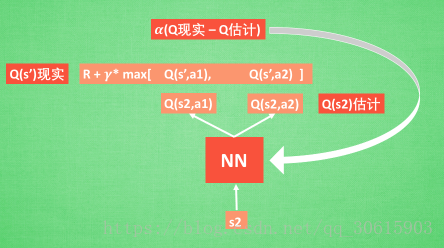
3、Q-target 目标网络
Q-targets的作用其实也是一种打乱相关性的机制,使用Q-targets会使得DQN中出现两个结构完全相同但是参数却不同的网络,预测Q估计的的网络MainNet使用的是最新的参数,而预测Q现实的神经网络TargetNet参数使用的却是很久之前的,$Q(s,a;θ_i)$表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;$Q(s,a;θ^−_i)$ 表示TargetNet的输出,可以解出targetQ并根据LossFunction更新MainNet的参数,每经过一定次数的迭代,将MainNet的参数复制给TargetNet。
引入TargetNet后,再一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。
4、算法流程
4.1、前置公式
DQN的更新方式和Qlearning一样,详细的值函数与动作值函数此处不再推导,在Qlearning中有详细讲解不了解的请移步上一篇博客
$$Q(s,a)←Q(s,a)+α[r+γmax_{a′}Q(s′,a′)−Q(s,a)]$$
DQN的损失函数如下 θ表示网络参数为均方误差损失
$$L(θ)=E[(TargetQ−Q(s,a;θ))^2]$$
$$TargetQ=r+γmax_{a′}Q(s′,a′;θ)$$
4.2、算法伪代码
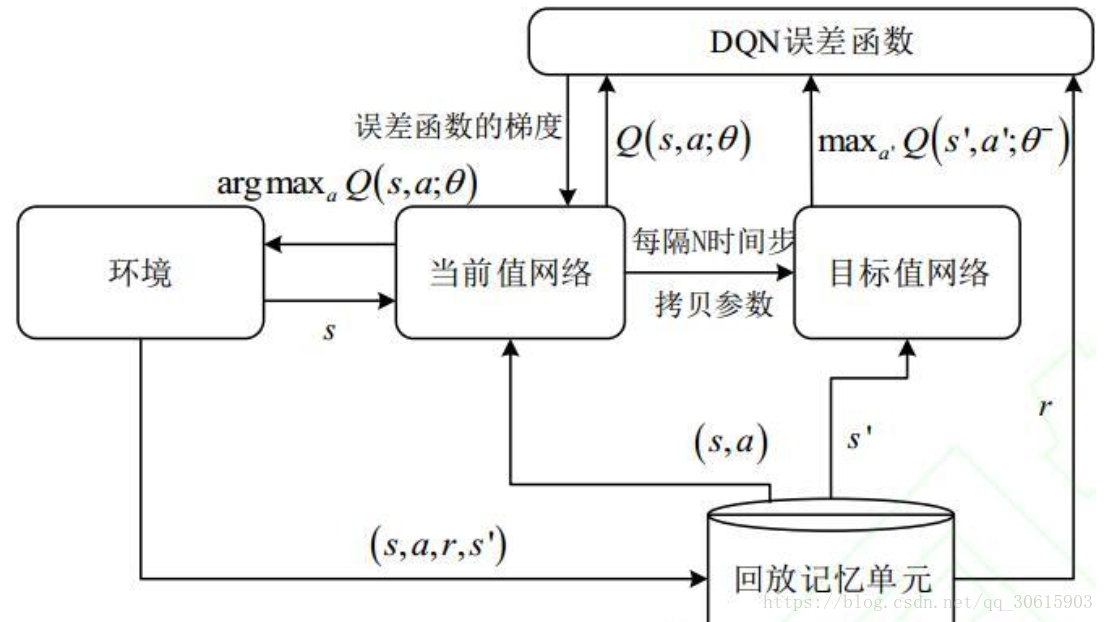
DQN中存在两个结构完全相同但是参数却不同的网络,预测Q估计的网络MainNet使用的是最新的参数,而预测Q现实的神经网络TargetNet参数使用的却是很久之前的,
$Q(s,a;θ_i)$表示当前网络MainNet的输出,用来评估当前状态动作对的值函数;
$Q(s,a;θ^−_i)$表示TargetNet的输出,可以解出targetQ,因此当agent对环境采取动作a时就可以根据上述公式计算出Q并根据LossFunction更新MainNet的参数,每经过一定次数的迭代,将MainNet的参数复制给TargetNet。这样就完成了一次学习过程

4.3、算法流程图
5、代码实现
根据morvan老师的例子所得
- class DeepQNetwork:
- def __init__(
- self,
- n_actions,
- n_features,
- learning_rate=0.01,
- reward_decay=0.9,
- e_greedy=0.9,
- replace_target_iter=300,
- memory_size=500,
- batch_size=32,
- e_greedy_increment=None,
- output_graph=True,
- ):
- self.n_actions = n_actions
- self.n_features = n_features
- self.lr = learning_rate
- self.gamma = reward_decay
- self.epsilon_max = e_greedy
- self.replace_target_iter = replace_target_iter
- self.memory_size = memory_size
- self.batch_size = batch_size
- self.epsilon_increment = e_greedy_increment
- self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
- # 统计训练次数
- self.learn_step_counter = 0
- # 初始化记忆 memory [s, a, r, s_]
- self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
- # 有两个网络组成 [target_net, evaluate_net]
- self._build_net()
- t_params = tf.get_collection('target_net_params')
- e_params = tf.get_collection('eval_net_params')
- self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
- self.sess = tf.Session()
- if output_graph:
- # 开启tensorboard
- # $ tensorboard --logdir=logs
- # tf.train.SummaryWriter soon be deprecated, use following
- tf.summary.FileWriter(r'D:\logs', self.sess.graph)
- self.sess.run(tf.global_variables_initializer())
- self.cost_his = []
- def _build_net(self):
- # -------------- 创建 eval 神经网络, 及时提升参数 --------------
- self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # 用来接收 observation
- self.q_target = tf.placeholder(tf.float32, [None, self.n_actions],
- name='Q_target') # 用来接收 q_target 的值, 这个之后会通过计算得到
- with tf.variable_scope('eval_net'):
- # c_names(collections_names) 是在更新 target_net 参数时会用到
- c_names, n_l1, w_initializer, b_initializer = \
- ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
- tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
- # eval_net 的第一层. collections 是在更新 target_net 参数时会用到
- with tf.variable_scope('l1'):
- w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
- b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
- l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
- # eval_net 的第二层. collections 是在更新 target_net 参数时会用到
- with tf.variable_scope('l2'):
- w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
- b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
- self.q_eval = tf.matmul(l1, w2) + b2
- with tf.variable_scope('loss'): # 求误差
- self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
- with tf.variable_scope('train'): # 梯度下降
- self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
- # ---------------- 创建 target 神经网络, 提供 target Q ---------------------
- self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # 接收下个 observation
- with tf.variable_scope('target_net'):
- # c_names(collections_names) 是在更新 target_net 参数时会用到
- c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
- # target_net 的第一层. collections 是在更新 target_net 参数时会用到
- with tf.variable_scope('l1'):
- w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
- b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
- l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
- # target_net 的第二层. collections 是在更新 target_net 参数时会用到
- with tf.variable_scope('l2'):
- w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
- b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
- self.q_next = tf.matmul(l1, w2) + b2
- def store_transition(self, s, a, r, s_):
- # 判断是否包含对应属性 没有就赋予初值
- if not hasattr(self, 'memory_counter'):
- self.memory_counter = 0
- # 纵向延伸
- transition = np.hstack((s, [a, r], s_))
- # 使用新的记忆替换掉旧网络的记忆
- index = self.memory_counter % self.memory_size
- self.memory[index, :] = transition
- self.memory_counter += 1
- def choose_action(self, observation):
- # 给观测值加上batch_size维度
- observation = observation[np.newaxis, :]
- if np.random.uniform() < self.epsilon:
- # forward feed the observation and get q value for every actions
- actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
- action = np.argmax(actions_value)
- else:
- action = np.random.randint(0, self.n_actions)
- return action
- def learn(self):
- # 判断是否应该更新target-net网络了
- if self.learn_step_counter % self.replace_target_iter == 0:
- self.sess.run(self.replace_target_op)
- print('\ntarget_params_replaced\n')
- # 从以前的记忆中随机抽取一些记忆
- if self.memory_counter > self.memory_size:
- sample_index = np.random.choice(self.memory_size, size=self.batch_size)
- else:
- sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
- batch_memory = self.memory[sample_index, :]
- q_next, q_eval = self.sess.run(
- [self.q_next, self.q_eval],
- feed_dict={
- self.s_: batch_memory[:, -self.n_features:], # fixed params
- self.s: batch_memory[:, :self.n_features], # newest params
- })
- # change q_target w.r.t q_eval's action
- q_target = q_eval.copy()
- # 下面这几步十分重要. q_next, q_eval 包含所有 action 的值,
- # 而我们需要的只是已经选择好的 action 的值, 其他的并不需要.
- # 所以我们将其他的 action 值全变成 0, 将用到的 action 误差值 反向传递回去, 作为更新凭据.
- # 这是我们最终要达到的样子, 比如 q_target - q_eval = [1, 0, 0] - [-1, 0, 0] = [2, 0, 0]
- # q_eval = [-1, 0, 0] 表示这一个记忆中有我选用过 action 0, 而 action 0 带来的 Q(s, a0) = -1, 所以其他的 Q(s, a1) = Q(s, a2) = 0.
- # q_target = [1, 0, 0] 表示这个记忆中的 r+gamma*maxQ(s_) = 1, 而且不管在 s_ 上我们取了哪个 action,
- # 我们都需要对应上 q_eval 中的 action 位置, 所以就将 1 放在了 action 0 的位置.
- # 下面也是为了达到上面说的目的, 不过为了更方面让程序运算, 达到目的的过程有点不同.
- # 是将 q_eval 全部赋值给 q_target, 这时 q_target-q_eval 全为 0,
- # 不过 我们再根据 batch_memory 当中的 action 这个 column 来给 q_target 中的对应的 memory-action 位置来修改赋值.
- # 使新的赋值为 reward + gamma * maxQ(s_), 这样 q_target-q_eval 就可以变成我们所需的样子.
- # 具体在下面还有一个举例说明.
- batch_index = np.arange(self.batch_size, dtype=np.int32)
- eval_act_index = batch_memory[:, self.n_features].astype(int)
- reward = batch_memory[:, self.n_features + 1]
- q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
- """
- 假如在这个 batch 中, 我们有2个提取的记忆, 根据每个记忆可以生产3个 action 的值:
- q_eval =
- [[1, 2, 3],
- [4, 5, 6]]
- q_target = q_eval =
- [[1, 2, 3],
- [4, 5, 6]]
- 然后根据 memory 当中的具体 action 位置来修改 q_target 对应 action 上的值:
- 比如在:
- 记忆 0 的 q_target 计算值是 -1, 而且我用了 action 0;
- 记忆 1 的 q_target 计算值是 -2, 而且我用了 action 2:
- q_target =
- [[-1, 2, 3],
- [4, 5, -2]]
- 所以 (q_target - q_eval) 就变成了:
- [[(-1)-(1), 0, 0],
- [0, 0, (-2)-(6)]]
- 最后我们将这个 (q_target - q_eval) 当成误差, 反向传递会神经网络.
- 所有为 0 的 action 值是当时没有选择的 action, 之前有选择的 action 才有不为0的值.
- 我们只反向传递之前选择的 action 的值,
- """
- # 训练eval网络
- _, self.cost = self.sess.run([self._train_op, self.loss],
- feed_dict={self.s: batch_memory[:, :self.n_features],
- self.q_target: q_target})
- self.cost_his.append(self.cost)
- # 因为在训练过程中会逐渐收敛所以此处动态设置增长epsilon
- self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
- self.learn_step_counter += 1
【转】【强化学习】Deep Q Network(DQN)算法详解的更多相关文章
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- Deep Q Network(DQN)原理解析
1. 前言 在前面的章节中我们介绍了时序差分算法(TD)和Q-Learning,当状态和动作空间是离散且维数不高时可使用Q-Table储存每个状态动作对的Q值,而当状态和动作空间是高维连续时,使用Q- ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- [Network Architecture]DPN(Dual Path Network)算法详解(转)
https://blog.csdn.net/u014380165/article/details/75676216 论文:Dual Path Networks 论文链接:https://arxiv.o ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- AlphaGo的前世今生(一)Deep Q Network and Game Search Tree:Road to AI Revolution
这一个专题将会是有关AlphaGo的前世今生以及其带来的AI革命,总共分成三节.本人水平有限,如有错误还望指正.如需转载,须征得本人同意. Road to AI Revolution(通往AI革命之路 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
- 第三十一节,目标检测算法之 Faster R-CNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
随机推荐
- <自动化测试方案_3>第三章、怎么样实现自动化测试?(How)
第三章.怎么样实现自动化测试?(How) 自动化测试分为:代码单元自动化测试.API接口自动化测试.UI自动化测试 代码单元自动化测试,一般是无法做到的,因为项目的原因,代码单元是不做自动化,其测试是 ...
- sh命令
sh或是执行脚本,或是切换到sh这个bash里,默认的shell是bash,你可以试试tcsh啊,csh啊,ksh,zsh什么的,看看别的shell是什么样子的.当然,linux中sh是链接到bash ...
- CsQuery中文编码乱码问题
一.问题描述 InnerHTML 中文显示为Модель 二.解决方法 在初始化CQ对象前,先设置执行以下语句: CsQuery.Config.HtmlEncoder = CsQuery.HtmlEn ...
- Hive分区
注意:必须在表定义时指定对应的partition字段. 一.指定分区 1.单分区 建表语句:create table day_table(id int, content string) partiti ...
- SQL Server如何定位自定义标量函数被那个SQL调用次数最多浅析
前阵子遇到一个很是棘手的问题,监控系统DPA发现某个自定义标量函数被调用的次数非常高,高到一个离谱的程度.然后在Troubleshooting这个问题的时候,确实遇到了一些问题让我很是纠结,下文是解决 ...
- mssql sqlserver 关键字 GROUPING用法简介及说明
转自: http://www.maomao365.com/?p=6208 摘要: GROUPING 用于区分列是否由 ROLLUP.CUBE 或 GROUPING SETS 聚合而产生的行 如果是原 ...
- python3爬虫抓取智联招聘职位信息代码
上代码,有问题欢迎留言指出. # -*- coding: utf-8 -*- """ Created on Tue Aug 7 20:41:09 2018 @author ...
- 根据flickr id 下载图片
#coding=utf-8 import flickrapi import requests import os n=1 flickr=flickrapi.FlickrAPI('*********** ...
- Windows 系统下 mysql workbench 的安装及环境配置
1.MySQL的官网地址:https://www.mysql.com/ 2,选择DOWNLOADS 3.选择community 再MySQL workbench 4.安装MySQL workbench ...
- 讲解wpe抓包,封包
相信大多数朋友都是会使用WPE的,因为这里也有不少好的教程,大家都辛苦了!先说说接触WPE的情况.当时好像是2011年,我本来不知道WPE对游戏竟有如此大的辅助作用的.起先找WPE软件的时候,只是因为 ...