HBase篇(4)-你不知道的HFile
【每日五分钟搞定大数据】系列,HBase第四篇

这一篇你可以知道,
HFile的内部结构?
HBase读文件细粒度的过程?
HBase随机读写快除了MemStore之外的原因?
上一篇中提到了Hbase的数据以HFile的形式存在HDFS, 物理存储路径是:
NameSpace->Table->Region->CF->HFile这一篇我们来说下这个HFile,把路径从HFile开始再补充一下
HFile->Block->KeyValue.顺便科普一下,HFile具体存储路径为:
/hbase/data/<nameSpace>/<tableName>/<encoded-regionname>/<column-family>/<filename>如何读取HFile的内容:
hbase org.apache.hadoop.hbase.io.hfile.HFile -f /上面的路径指定某个HFile -p这是我做的一个思维导图,这里面的内容就是我这章要讲的东西,有点多,大家慢慢消化。
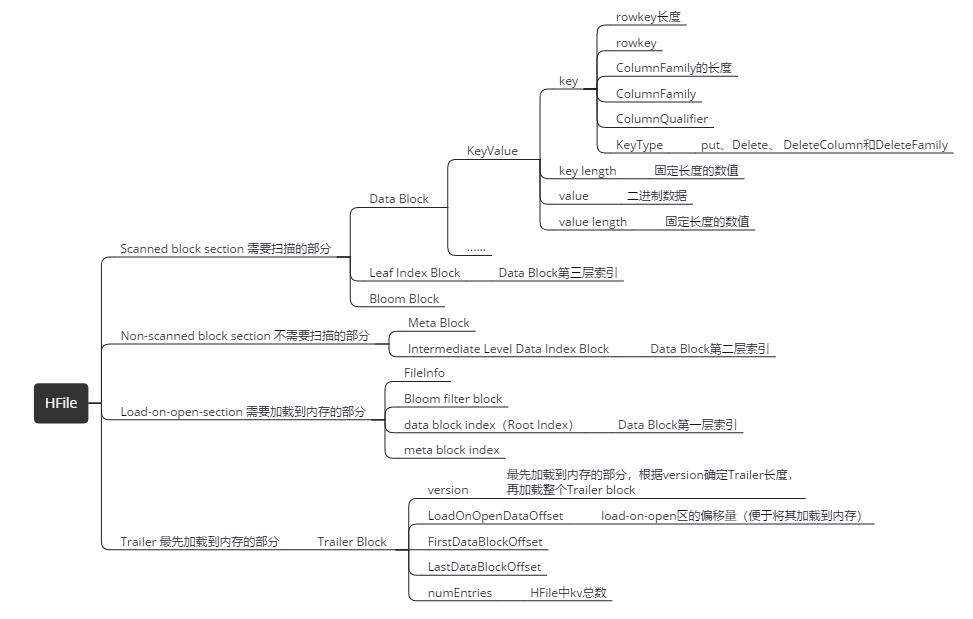
HFile的逻辑分类
Scanned block section:扫描HFile时这个部分里面的所有block都会被读取到。
Non-scanned block section:和相面的相反,扫描HFile时不会被读取到。
Load-on-open-section:regionServer启动时就会加载这个部分的数据,不过不是最先加载。
Trailer:这个部分才是最先加载到内存的,记录了各种偏移量和版本信息。
HFile的物理分类
物理分类和逻辑分类对应的关系,可以在上面的图中看到
HFile有多个大小相等的block组成,Block分为四种类型:Data Block,Index Block,Bloom Block和Meta Block。
- Data Block
用于存储实际数据,通常情况下每个Data Block可以存放多条KeyValue数据对; - Index Block和Bloom Block
都用于优化随机读的查找路径,其中Index Block通过存储索引数据加快数据查找,而Bloom Block通过一定算法可以过滤掉部分一定不存在待查KeyValue的数据文件,减少不必要的IO操作; - Meta Block
主要存储整个HFile的元数据。
Data Block
保存了实际的数据,由多个KeyValue 组成,块大小默认为64K(由建表时创建cf时指定或者HColumnDescriptor.setBlockSize(size)),在查询数据时,以block为单位加载数据到内存。
KeyValue 的结构
- key
由这些内容组成:rowkey长度、rowkeyColumnFamily的长度、ColumnFamily、ColumnQualifier、KeyType(put、Delete、 DeleteColumn和DeleteFamily) - key length
固定长度的数值 - value
二进制数据 - value length
固定长度的数值
Index Block
- data block index(Root Index Block )
Data Block第一层索引 - Intermediate Level Data Index Block
Data Block第二层索引 - Leaf Index Block
Data Block第三层索引
这三层索引我举个栗子放在一起说,第一层是必须要的,也是最快的,因为它会被加载到内存中。二三根据数据量决定,如果有的话在找的时候也会加载到内存。实际上就是一步步的缩小范围,类似B+树的结构:
a,b,c,d,e
f,g,h,i,j
k,l,m,n,o
Root Index Block 第一层:a,g,l
Intermediate Level Data Index Block 第二层:a,c,e || f,h,j || k ,m,o
Leaf Index Block 第三层(部分):a,b || c,d || e,f- 假设要搜索的rowkey为bb,root index block(常驻内存)中有三个索引a,g,l,b在a和g之间,因此会去找索引 a 指向的二层索引
- 将索引 a 指向的中间节点索引块加载到内存,然后通过二分查找定位到 b 在 index a 和 c 之间,接下来访问索引 a 指向的叶子节点。
- 将索引 a 指向的中间节点索引块加载到内存,通过二分查找定位找到 b 在 index a 和 b 之间,最后需要访问索引b指向的数据块节点。
- 将索引 b 指向的数据块加载到内存,通过遍历的方式找到对应的 keyvalue 。
上面的流程一共IO了三次,HBase提供了一个BlockCache,是用在第4步缓存数据块,可以有一定概率免去随后一次IO。
相关配置:
hfile.data.block.size(默认64K):同样的数据量,数据块越小,数据块越多,索引块相应的也就越多,索引层级就越深
hfile.index.block.max.size(默认128K):控制索引块的大小,索引块越小,需要的索引块越多,索引的层级越深
Meta Block (可选的)
保存用户自定义的kv对,可以被压缩。比如booleam filter就是存在元数据块中的,该块只保留value值,key值保存在元数据索引块中。每一个元数据块由块头和value值组成。可以快速判断key是都在这个HFile中。
meta block index (可选的)
Meta Block的索引。
File Info ,Hfile的元信息
不被压缩,用户也可以在这一部分添加自己的元信息。
Trailer (记录起始位置)
记录了HFile的基本信息、偏移值和寻址信息
Trailer Block
- version
最先加载到内存的部分,根据version确定Trailer长度,再加载整个Trailer block - LoadOnOpenDataOffset
load-on-open区的偏移量(便于将其加载到内存) - FirstDataBlockOffset:HFile中第一个Block的偏移量
- LastDataBlockOffset:HFile中最后一个Block的偏移量
- numEntries:HFile中kv总数
另外:Bloom filter相关的Block我准备专门写一篇文章,因为Bloom filter这个东西在分布式系统中非常常见而且有用,现在需要知道的是它是用来快速判断你需要查找的rowKey是否存在于HFile中(一堆的rowKey中)。
重点来了!
看完上面的内容我们就可以解决文章开始提出的问题了:
HBase读文件细粒度的过程?
HBase随机读写快除了MemStore之外的原因?
这两个问题我一起回答。
0.这里从找到对应的Region开始说起,前面的过程可以看上一篇文章。
1.首先用MemStoreScanner搜索MemStore里是否有所查的rowKey(这一步在内存中,很快),
2.同时也会用Bloom Block通过一定算法过滤掉大部分一定不包含所查rowKey的HFile,
3.上面提到在RegionServer启动的时候就会把Trailer,和Load-on-open-section里的block先后加载到内存,
所以接下来会查Trailer,因为它记录了每个HFile的偏移量,可以快速排除掉剩下的部分HFile。
4.经过上面两步,剩下的就是很少一部分的HFile了,就需要根据Index Block索引数据(这部分的Block已经在内存)快速查找rowkey所在的block的位置;
5.找到block的位置后,检查这个block是否在blockCache中,在则直接去取,如果不在的话把这个block加载到blockCache进行缓存,
当下一次再定位到这个Block的时候就不需要再进行一次IO将整个block读取到内存中。
6.最后扫描这些读到内存中的Block(可能有多个,因为有多版本),找到对应rowKey返回需要的版本。
另外,关于blockCache很多人都理解错了,这里要注意的是:
blockCache并没有省去扫描定位block这一步,只是省去了最后将Block加载到内存的这一步而已。
这里又引出一个问题,如果BlockCache中有需要查找的rowKey,但是版本不是最新的,那会不会读到脏数据?
HBase是多版本共存的,有多个版本的rowKey那说明这个rowKey会存在多个Block中,其中一个已经在BlockCache中,则省去了一次IO,但是其他Block的IO是无法省去的,它们也需要加载到BlockCache,然后多版本合并,获得需要的版本返回。解决多版本的问题,也是rowKey需要先定位Block然后才去读BlockCache的原因。

HBase篇(4)-你不知道的HFile的更多相关文章
- HBase篇(5)- BloomFilter
[每日五分钟搞定大数据]系列,HBase第五篇.上一篇我们落下了Bloom Filter,这次我们来聊聊这个东西. Bloom Filter 是什么? 先简单的介绍下Bloom Filter(布隆过滤 ...
- HBase篇(3)-架构详解
[每日五分钟搞定大数据]系列,HBase第三篇 聊完场景和数据模型我们来说下HBase的架构,在网上找了张比较清晰的图,我觉得这张图能说明很多问题,那这一篇我们就重点来解析下这张图 角色与职责 先介绍 ...
- HBase学习笔记之HFile格式
主要看Roger的文档,这里作为文档的补充 HFile的格式-HFile的基本结构 Trailer通过指针找到Meta index.Data index.File info. Meta index保存 ...
- Hbase篇--HBase中一对多和多对多的表设计
一.前述 今天分享一篇关于HBase的一对多和多对多的案例的分析. 二.具体案例 案例一.多对多 人员-角色 人员有多个角色 角色优先级 角色有多个人员 人员 删除添加角色 角 ...
- HBase篇--HBase常用优化
一.前述 HBase优化能够让我们对调优有一定的理解,当然企业并不是所有的优化全都用,优化还要根据业务具体实施. 二.具体优化 1.表的设计 1.1 预分区 默认情况下,在创建HBase表的时候会自 ...
- HBase篇--初始Hbase
一.前述 1.HBase,是一个高可靠性.高性能.面向列.可伸缩.实时读写的分布式数据库.2.利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量 ...
- HBase篇(1)-特性与应用场景
[每日五分钟搞定大数据]系列,HBase第一篇 结束了Zookeeper篇, 接下来我们来说下Google三驾马车之一BigTable的开源实现:HBase,要讲的内容暂定如下: 这是第一篇我们先不聊 ...
- HBase,region以及HFile概念
什么是HBase的Region? 大家一定对一个词不陌生:域分区,这个域就是Region:Region定义为key的一个取值范围的子集的数据载体:比如常见的域分区有固定大小分区,比如1-10一个reg ...
- hbase(二)hfile结构
HFile结构 截止hbase 1.0.2版本,hfile已经有3个版本,要深入了解hfile的话,还是要从第一个版本开始看起. hfile v1 Data Block:保存表中的数据,这部分可以被压 ...
随机推荐
- 口碑订单,ERP本地加/退菜无法回流至手机端的解决办法-订单金额不统一erp本地加菜H5没有
关于 口碑订单,ERP本地加/退菜无法回流至手机端的解决办法-订单金额不统一erp本地加菜H5没有 1. 2. 3. PS:是正餐后付的务必要选择口碑后付 完成以上设置即可
- Symantec Backup Exec 2010 安装报 bad ELF interpreter: No such file or directory
在64位的Red Hat Enterprise Linux Server release 6.6上安装Symantec Backup Exec 2010时, 遇到下面错误: # ./installra ...
- java使用插件pagehelper在mybatis中实现分页查询
摘要: com.github.pagehelper.PageHelper是一款好用的开源免费的Mybatis第三方物理分页插件 PageHelper是国内牛人的一个开源项目,有兴趣的可以去看源码,都有 ...
- Windows Server 2016-管理Active Directory复制任务
Repadmin.exe可帮助管理员诊断运行Microsoft Windows操作系统的域控制器之间的Active Directory复制问题. Repadmin.exe内置于Windows Serv ...
- Unity的AssetDatabase路径格式
开发环境 windows 7 Unity 5.3 及更高版本 前言 使用AssetDatabase.Load或AnimatorController.CreateAnimatorControllerAt ...
- stored information about method csdn
Eclipse编译时保留方法的形参 Window -> Preferences -> Java -> Compiler. 选中Store information about meth ...
- 2016某知名互联网公司PHP面试题及答案(续)
1 写出mysql中,插入数据,读出数据,更新数据的语句 INSERT INTO 表名 VALUES ("",""): SELECT * FROM 表名:. U ...
- echo 1+2+"3+4+5“输出的结果是6
如上,为什么echo 1+2+"3+4+5"输出的结果是6呢?刚开始我也不是很明白,以为有问题,但在电脑上运行程序的时候,结果出现6 了.这让我更加疑惑不解.现将问题解释一番. 在 ...
- Zookeeper Health Checks
Short Description: The article talks about the basic health checks to be performed when working on i ...
- nginx基本配置与参数说明
user nobody; #启动进程,通常设置成和cpu的数量相等 worker_processes 1; #全局错误日志及PID文件 #error_log logs/error.log; # ...