神经网络模型(Backbone)
自己搭建神经网络时,一般都采用已有的网络模型,在其基础上进行修改。从2012年的AlexNet出现,如今已经出现许多优秀的网络模型,如下图所示。 主要有三个发展方向:
Deeper:网络层数更深,代表网络VggNet
Module: 采用模块化的网络结构(Inception),代表网络GoogleNet
Faster: 轻量级网络模型,适合于移动端设备,代表网络MobileNet和ShuffleNet
Functional: 功能型网络,针对特定使用场景而发展出来。如检测模型YOLO,Faster RCNN;分割模型FCN, UNet

其发展历史可以分为三个阶段:

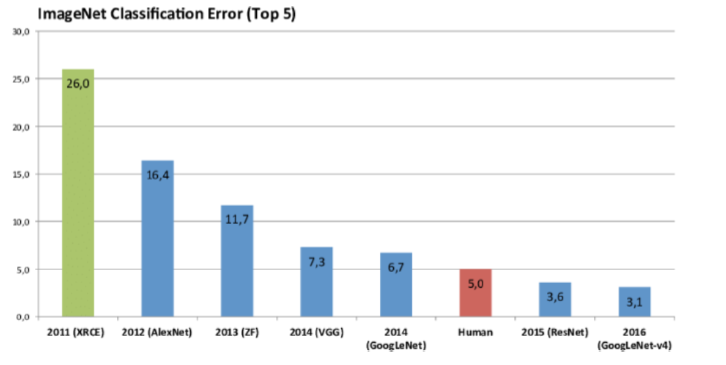
这些模型在ImageNet上的表现效果对比如下:
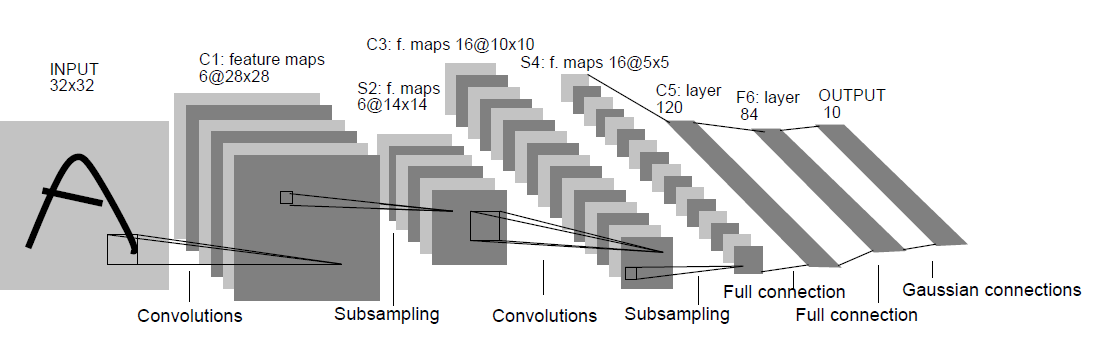
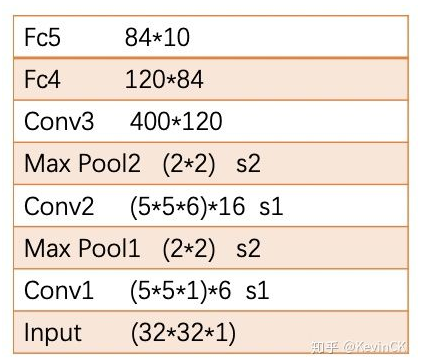
1. LeNet-5
LeNet-5是LeCun在1998年的论文中Gradient-Based Learning Applied to Document Recognition 提出的网络模型,其结构如下:(其中卷积为5*5的kernel,下采样为2*2的MaxPooling),其结构比较简单,关于LeNet-5结构设计的详细分析,参见:参考一,参考二
2. AlexNet
AlexNet是Alex Krizhevsky在2012的文章ImageNet Classification with Deep Convolutional Neural Networks中提出,其结构模型如下:(分上下两部分卷积,计算力不足,放在两块GPU上)
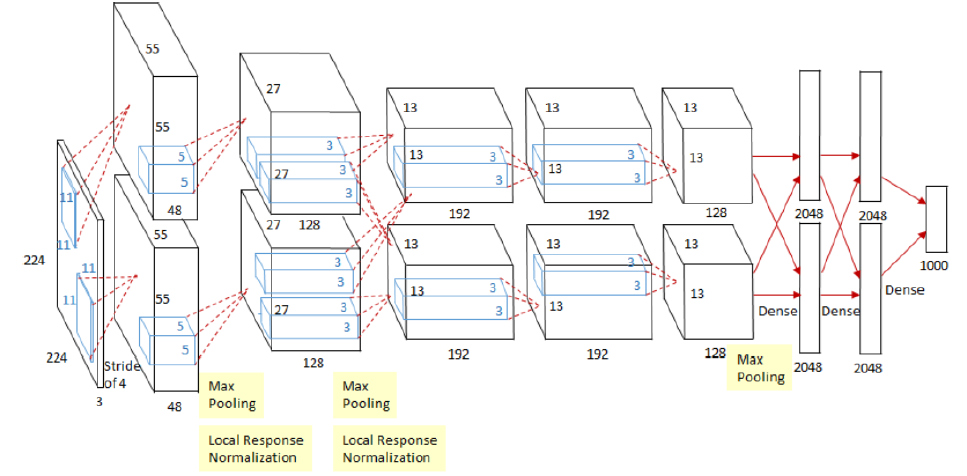

(1) Training on Multiple Gpus: 受于当时的算力限制,Alexnet创新地将图像分为上下两块分别训练,然后在全连接层合并在一起
(2) ReLU Nonlinearity: 采用ReLU激活函数代替Sigmoid或tanh, 解决了梯度饱和的问题
(3)Local Response Normalization: 局部响应归一化,
(4) Data Augmentation: 扩增数据,减小过拟合:第一种是 抠图(从256x256抠出224x224)加上水平反转。第二种是 改变RGB颜色通道强度。
(5) Dropout: 以一定概率舍弃神经元输出,减小过拟合。
3.ZFNet
ZFNet是2013年的论文Visualizing and Understanding Convolutional Networks中提出,是2013年ILSVRC的冠军。这篇文章使用反卷积(Deconvnet),可视化特征图(feature map),通过可视化Alex-net指出了Alex-net的一些不足,最后修改网络结构,使得分类结果提升;是CNN领域可视化理解的开山之作,作者通过可视化解释了为什么CNN有非常好的性能、如何提高CNN性能,然后进行调整网络,提高了精度(参考文章)
ZFNet通过修改结构中的超参数来实现对AlexNet的改良,具体说来就是增加了中间卷积层的尺寸,让第一层的步长和滤波器尺寸更小。其网络结构的两种表示图如下:
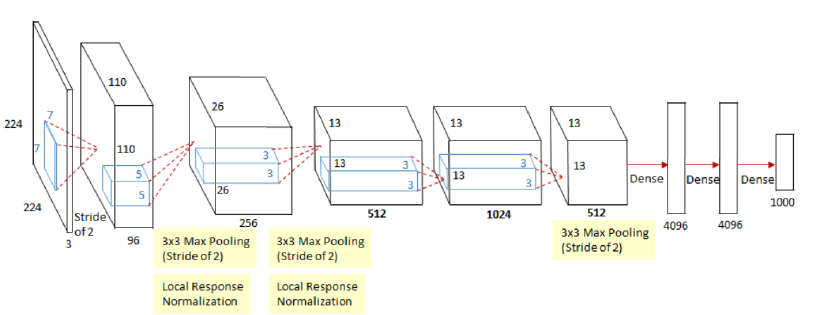
相比于AlexNet其改进如下:(ImageNet top5 error:16.4%提升到11.7%)
(1) Conv1: 第一个卷积层由(11*11, stride=4)变为(7*7,stride=2)
(2) Conv3, 4, 5: 第三,四,五个卷积核的通道数由384,384,256变为512,1024,512
3. VGGNet
VGGNet是2014年论文Very Deep Convolutional Networks for Large-scale Image Recognition 中提出,2014年的ImageNet比赛中,分别在定位和分类跟踪任务中取得第一名和第二名,其主要的贡献是展示出网络的深度(depth)是算法优良性能的关键部分,其结构如下:
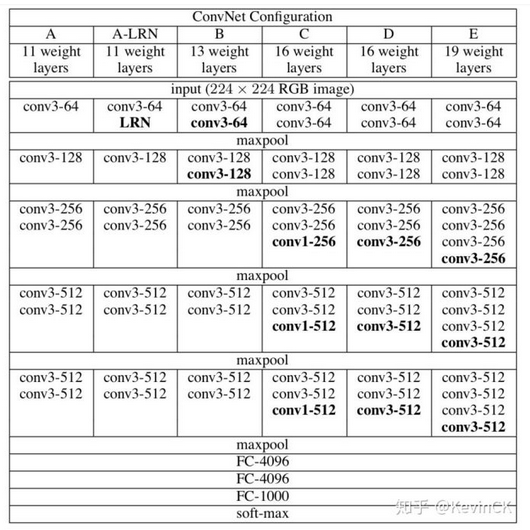
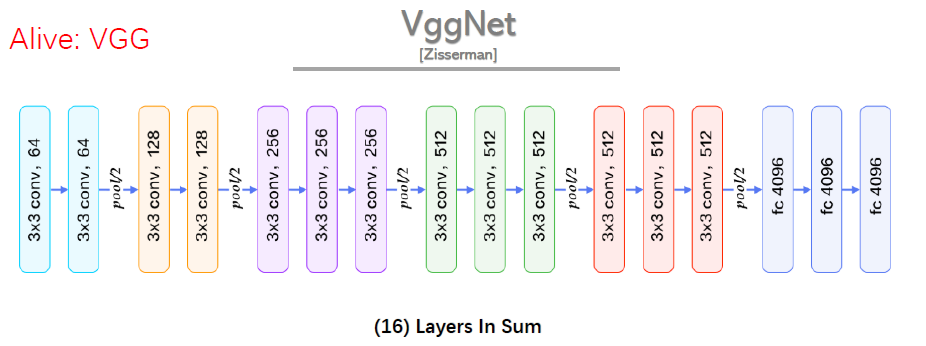
(1) 结构简洁:5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层激活单元都采用ReLU函数。
(2)小卷积核和多卷积核:VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27),如下图所示:

VGGNet提出的结论:
(1) LRN层无性能增益(A-LRN):AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升
(2) 随着深度增加,分类性能逐渐提高(从11层到19层)
(3) 多个小卷积核比单个大卷积核性能好
4. GoogLeNet
4.1 GoogLeNet V1
GoogLetNet V1是在2014年论文Going deeper with convolutions中提出的,ILSVRC 2014的胜利者。相比于VGG,其并不是单纯的将网络加深,还引入了Inception模块的概念,最终性能和VGG差不多,但参数量更少。
Inception提出原因:传统网络为了减少参数量,减小过拟合,将全连接和一般卷积转化为随机稀疏连接,但是计算机硬件对非均匀稀疏数据的计算效率差,为了既保持网络结构的稀疏性,又能利用密集矩阵的高计算你性能,Inception网络结构的主要思想是寻找用密集成分来近似最优局部稀疏连接,通过构造一种“基础神经元”结构,来搭建一个稀疏性、高计算性能的网络结构
Inception的结构如下图所示:

Inception架构特点:
(1)加深的基础上进行加宽,稀疏的网络结构,但能产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率
(2) 采用不同大小的卷积核意味着不同的感受野,最后在channel上拼接,意味着不同尺度的特征融合
(3)采用1*1卷积,一是减少维度来减少计算量和参数,二是修正线性激活,增加非线性拟合能力(每个1*1后都有ReLU激活函数)
以Inception为基础模块,GoogLeNet V1的整体网络架构如下(共22层):

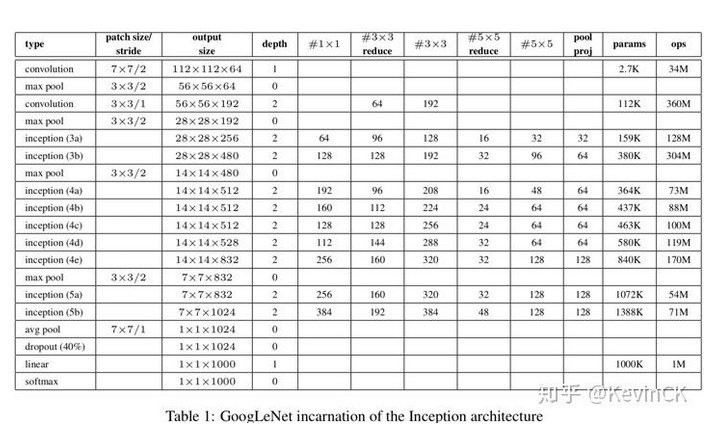
(1) 采用Inception模块化结构,方便添加修改
(2) 采用Average Pool 来代替全连接层(借鉴Network in Network),实际在最后一层还是添加了一个全连接层,方便做finetune。
(3) 另外增加了两个辅助的softmax分支(incetion 4b和4e后面),作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求 导为0,链式求导结果则为0。二是将中间某一层输出用作分类,起到模型融合作用。最后的loss=loss_2 + 0.3 * loss_1 + 0.3 * loss_0。实际测 试时,这两个辅助softmax分支会被去掉。
4.2 GoogLeNet V2, V3
GoogLeNet V2, V3是在2015年论文Rethinking the Inception Architecture for Computer Vision 中提出,主要是对V1的改进。
GoogLeNet v2的Inception结构和整体的架构如下:
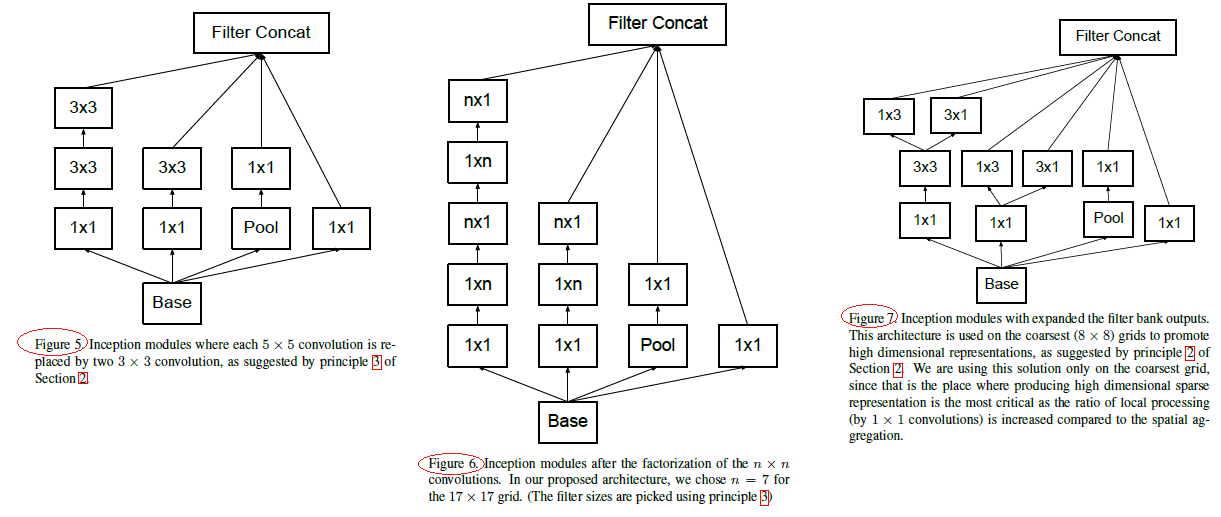
GoogLeNet V2网络特点:
(1) 借鉴VGG,用两个3*3卷积代替一个5*5卷积,降低参数量,提高计算速度(如上图Figure5中Inception)
(2)它们将滤波器大小nxn的卷积分解为1xn和nx1卷积的组合(7x7卷积相当于首先执行1x7卷积,然后在其输出上执行7x1卷积,如上图Figure6中Inception),但在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在12到20之间)
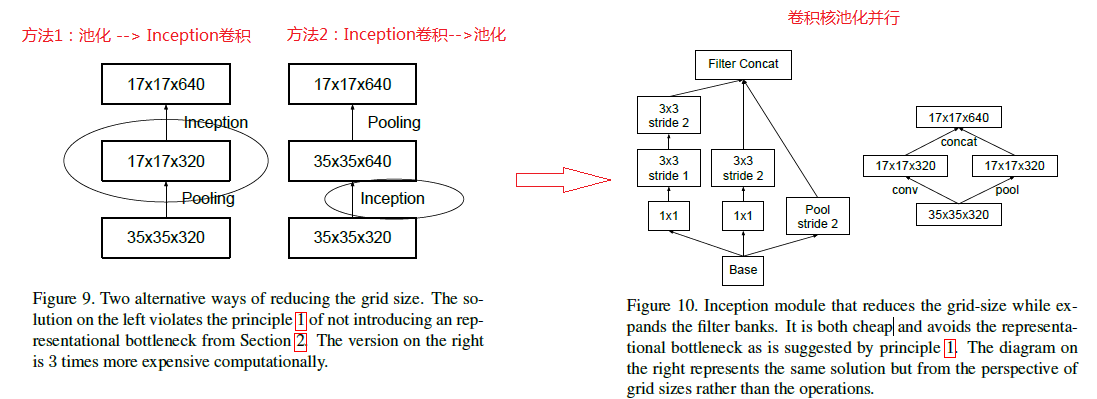
(3) 为了同时保持特征表示并降低计算量,将池化和卷积并行执行再合并,如下图所示:
GoogLeNet V3: V3包含了为V2规定的所有上述改进,另外还使用了以下内容:
(1)采用RMSProp优化器
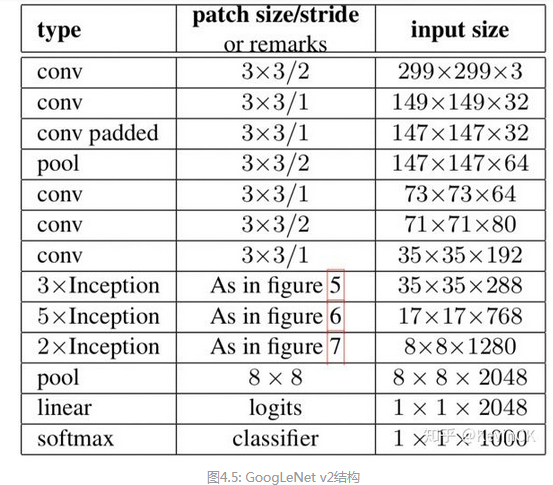
(2) 学习Factorization into small convolutions的思想,将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加 速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注 意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块。
(3) 在辅助分类器中的使用BatchNorm。
(4) 采用标签平滑(添加到损失公式中的一种正规化组件,可防止网络对类过于自信。防止过度拟合)
4.3 GoogLeNet V4
GoogLeNet V4(Inception V4)是在2016年的论文 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 中提出,主要是利用残差网络(ResNet)来改进V3,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。
5. ResNet
ResNet是何凯明在2015年的论文Deep Residual Learning for Image Recognition 中提出,ResNet网络提出了残差网络结构,解决了以前深层网络难训练的问题,将网络深度有GoogLeNet的22层提高到了152层。残差网络(bottleneck)的结构如下:(参考1)
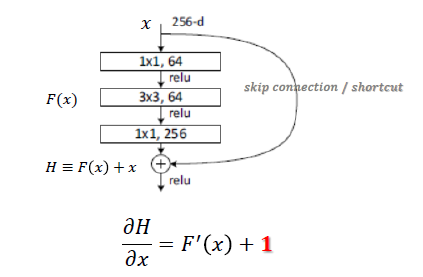
相比传统网络:y=f(x),ResNet Block公式为:y=f(x) + x,可以称之为skip connect。有两个点需要思考下:一是其导数总比原导数加1,这样即使原导数很小时,也能传递下去,能解决梯度消失的问题; 二是y=f(x) + x式子中引入了恒等映射(当f(x)=0时,y=2),解决了深度增加时神经网络的退化问题。
ResNet由多个Residual Block叠加成的,其结构如下:
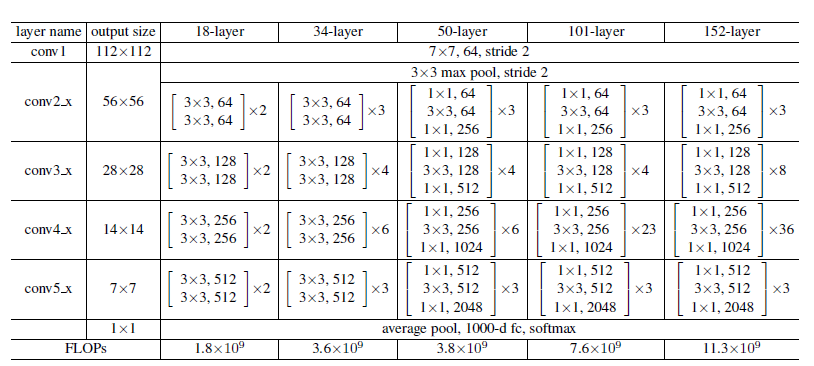
其中Resnet-18/34采用的residual block和Resnet-50/101/152不太一样,分别如下所示:
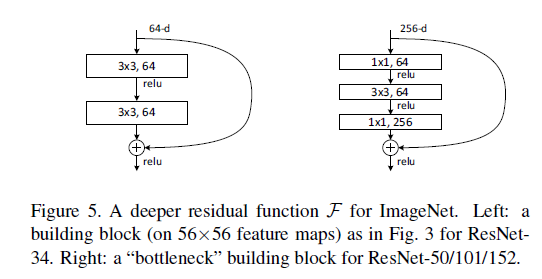
除了残差结构,ResNet还有两个细节需要关注下:
(1)第一个卷积层采用了7*7的大卷积核,更大的感受野,获取图片更多的初始特征(primary feature) (图片channel=3,第一层使用大kernel,增加的参 数量不是很大)
· (2)短路连接中,输入和输出维度不一致时,不能直接相加(Element-wise add),采用步长为2的卷积来减小维度尺寸?
6. DenseNet
DenseNet网络是在2017的论文 Densely Connected Convolutional Networks 中提出,与ResNet一致,也采用shortcut连接,但是其将前面所有层与后面层密集连接(dense connection), 另外其采用channel concatenate来实现特征重用(代替ResNet的Element-wise addition)。其整体网络结构如下图所示: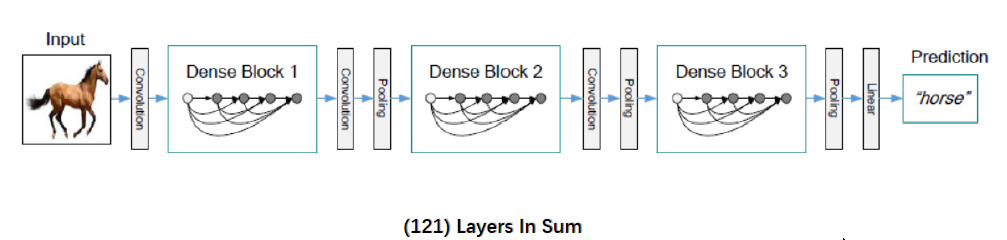
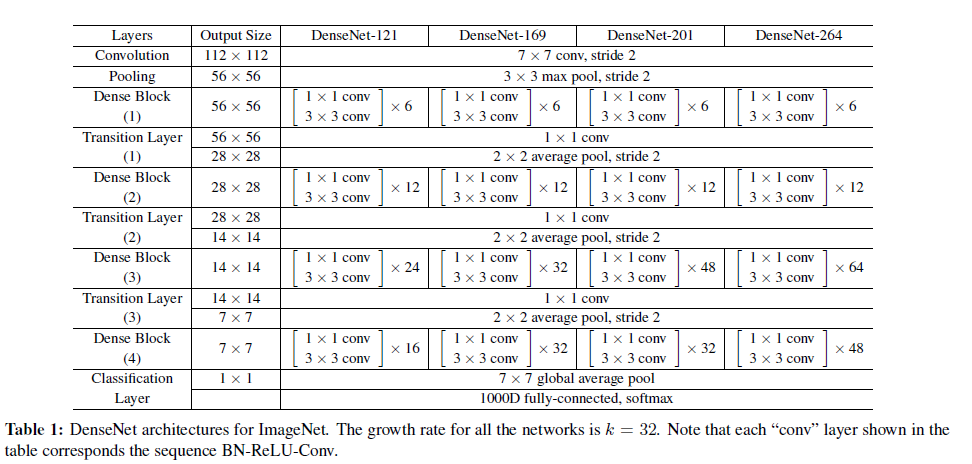
DenseNet网络包括Dense Block和Transition layer两个基础模块,Dense Block类似于ResNet中的residual block,其区别对比如下:

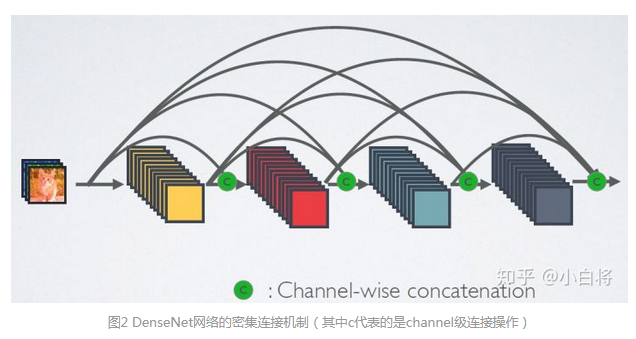
由上图可以发现两个主要区别:(参考1)
(1) DenseNet是密集连接,前面层和后面层间都有连接;ResNet只有相邻层有连接
(2) DenseNet是channel-wise concatenation; Resnet 是Element-wise addition
DenseNet的Transition layer主要是用来降低feature map的尺寸,将来自不同层的feature map变化为同等尺寸后进行concatenate,其结构如下:
BN + ReLU+1*1 Conv + 2*2 Average Pool
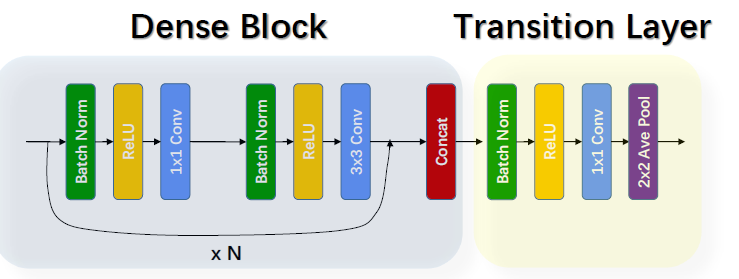
DenseNet的特点:
(1) 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练 (每层可以直达最后的误差信号)
(2) 参数更小且计算更高效 (concatenate来实现特征复用,计算量很小)
(3) 由于特征复用,分类器使用到了低级特征
(4) 需要较大的显存才能运行(所有层都需存储?)
参考:https://zhuanlan.zhihu.com/p/66215918
https://zhuanlan.zhihu.com/p/22038289
上述都是些大型的经典网络,运行较慢,需要的较大的算力,而轻量级网络则采用不同的设计和模型架构,来应对移动端设备上的使用,目前主要的轻量级网络包括 SqueezzeNet, MobileNet和ShuffleNet,其发展历史如下:

这些网络实现轻量级的主要方法如下:
(1) 优化网络结构: shuffle Net
(2) 减少网络的参数: Squeeze Net
(3) 优化卷积计算: MobileNet(改变卷积的顺序); Winograd(改变卷积计算方式)
(4) 删除全连接层: Squeeze Net; LightCNN
7. SqueezeNet
SqueezeNet是在2017年的论文 SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size中提出, squeezeNet的模型压缩策略主要有三个:(Idea from GoogLeNet) (参考1)
(1) 多使用1*1的卷积,少使用3*3的卷积,减少参数量
(2) 3*3卷积采用更少的channel数
(3) 将降采样后置,即推迟使用Pooling,从而增加感受野,尽可能多的获得feature
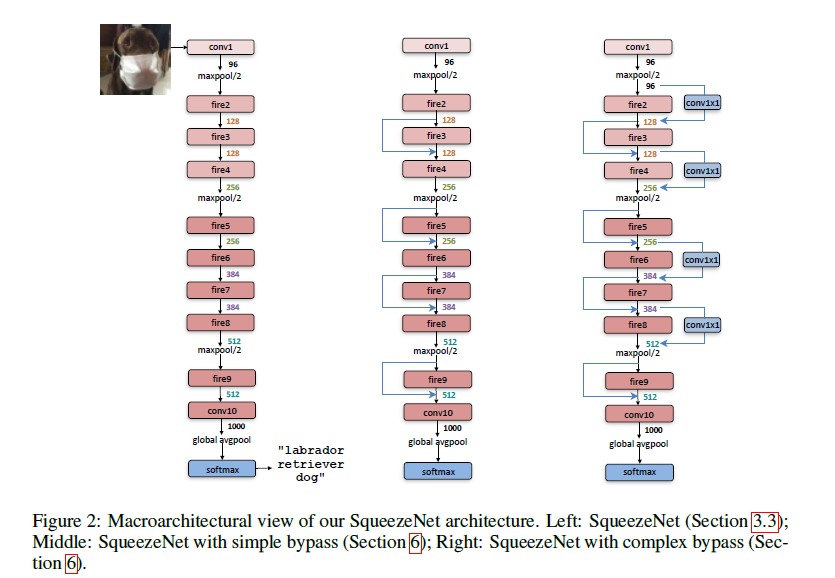
SqueezeNet的网络基础单元是Fire Module,多个fire module堆叠,结合pooling组成SqueezeNet,如下图所示:(右边两张加入了shortcut)

Fire Module又包括两部分:squeeze layer 和 Expand layer,如下图所示:
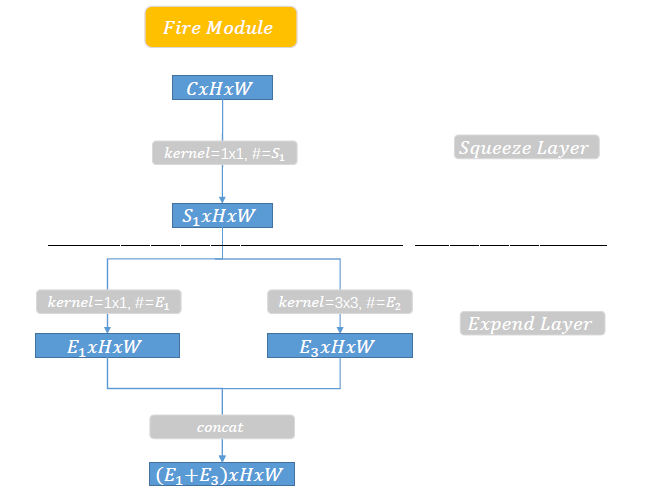
squeeze layer:主要是1*1的卷积,对网络channel进行压缩,卷积核的个数为S1
expand layer:1*1的卷积个数为E1,3*3的卷积个数为E3(上图中E2应该为E3),然后进行concate。
论文中关于E1, E3,S1的关系描述如下:

8. MobileNet
8.1 MobileNet V1
MobileNet V1是在2017年Google的论文 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications中提出,其主要压缩策略是深度可分离卷积(Depthwise separable Convolution),其包括两步,如下图所示:

(1) 深度卷积:将卷积拆分为单通道的形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,得到和输入特征图通道数一致的输出特征图。如下图,输入12×12×3的特征图,经过5×5×1×3的深度卷积之后,得到了8×8×3的输出特征图。输入个输出的维度是不变的3。

(2)逐点卷积:即1*1的卷积,对深度卷积得到的特征图进行升维,如下图,8×8×3的特征图,通过1*1*3*256的卷积,输出8*8*256的输出特征图。
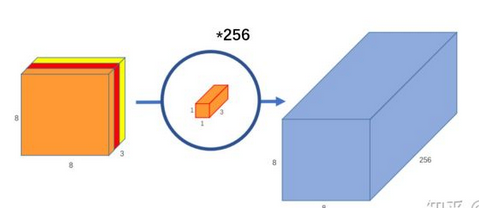
参数量和计算量对比:
深度可分离卷积和传统卷积相比操作和参数更少,如下图所示,可以发现深度可分离卷积操作数和参数都是传统卷积的(1/N +1/Dk2), 采用3*3卷积时大约是1/9。(但模型精度大概只降低1%)

模型结构对比:
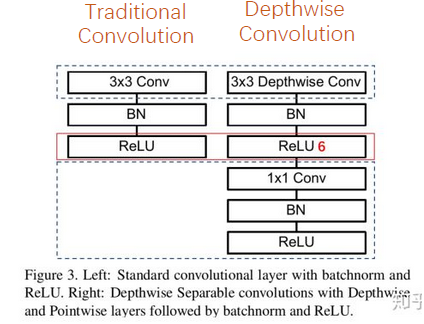
深度可分离卷积单元相比传统卷积多一个ReLU6激活函数和1*1卷积层,对比如下图:
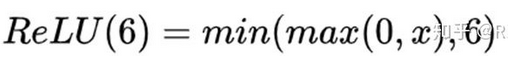
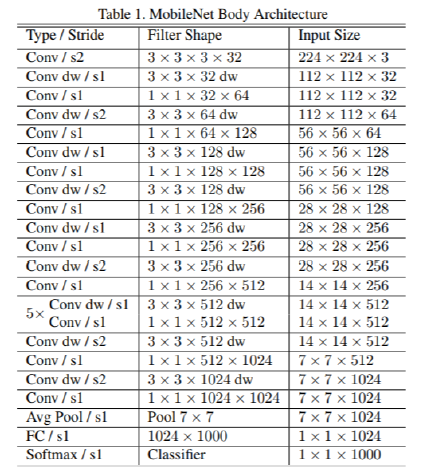
MobileNet V1网络的整体架构如下图, 多个深度卷积的堆叠(s2表示步长为2),: (参考1)
MobileNet V1还可以引入结构超参数来进一步压缩网络,主要是在kernel的深度和尺寸两方面,如下图:

8.2 MobileNet V2
MobileNet V2是在2018年的论文 MobileNetV2: Inverted Residuals and Linear Bottlenecks 中提出,对V1的卷积单元进行了改进,主要引入了Linear bottleneck和Inverted residuals。
(1) Linear bottleneck : 在原始V1训练时容易出现卷积层参数为空的现象,这是由于ReLU函数:对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少(参考);因此去掉卷积单元中最后一个ReLU函数。
(Linear bottleneck: Eltwise + with no ReLU at the end of the bottleneck)
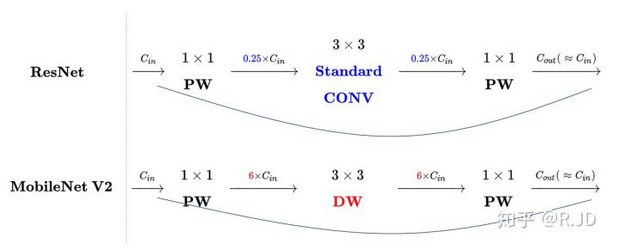
(2) Inverted Residual: 深度卷积本身没有改变channel的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,随后再进行降维。
(Inverted Residual: expand - transfer - reduce)
对比下V2和ResNet的结构,如下图:可以发现V2是先升,卷积,降维,和ResNet(降维,卷积,升维)相反,因此成为Inverted residual.
Linear bottleneck和Inverted Residual解释:
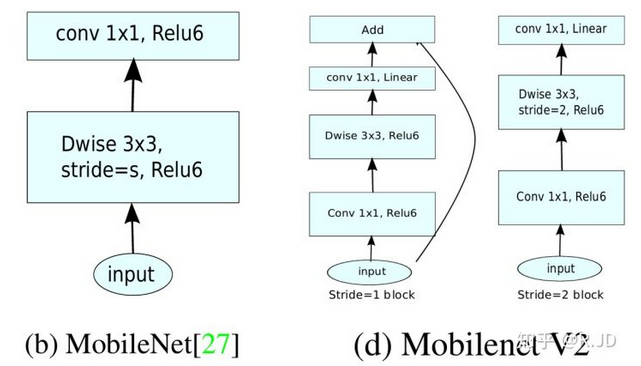
对比下V1和V2的卷积结构单元,如下图:V2将最后一层的ReLU6换成了Linear,并引入了shortcut进行升维和将维(最右边的stride=2减小尺寸,所以没有shortcut)。
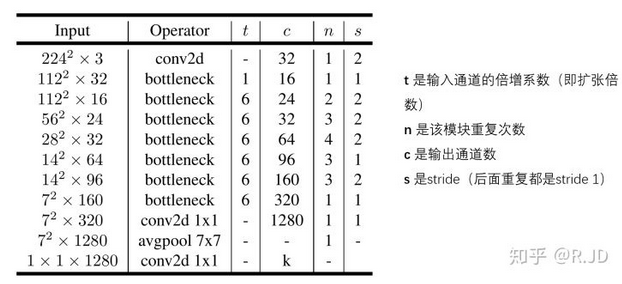
MobileNet V2的整体结构如下图:
8.3 MobileNet V3
MobileNet V3在2019年的论文Searching for MobileNetV3 中提出,还没啃完,有空来填坑。
9 ShuffleNet
9.1 shuffleNet V1
shuffleNet V1 是2017年在论文ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 中提出的,其主要压缩思路是group convolution 和 channel shuffle。(参考1,参考2)
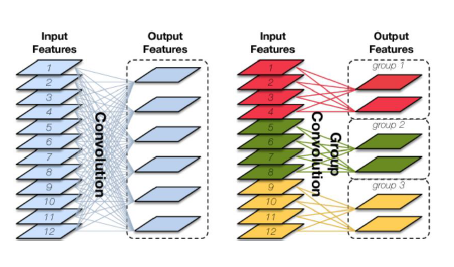
(1) group convolution(分组卷积): 分组卷积的思路是将输入特征图按通道数分为几组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。传统的卷积是卷积核在所有通道上进行卷积,算全通道卷积,而分组卷积算通道上的稀疏卷积,如下图所示。(mobileNet算是一种特殊的分组卷积,分组数和通道数一样)
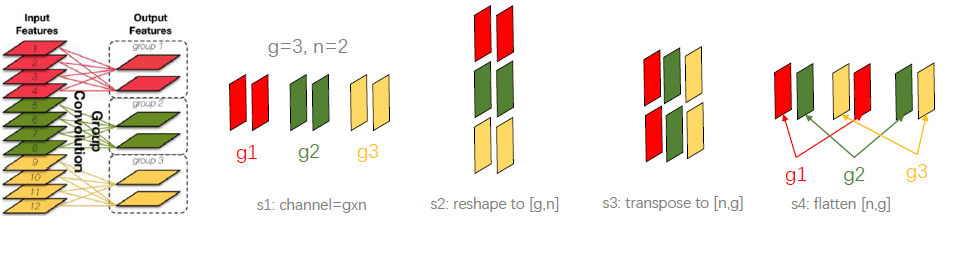
(2)channel shuffle(通道混洗) : 分组卷积以一个问题是不同组之间的特征图信息不通信,就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力。MobileNet是采用密集的1*1pointwise convolution进行通道特征融合,计算量较大。channel shuffle的思路是对分组卷积之后的特征图的排列顺序进行打乱重新排列,这样下一个分组卷积的输入就来自不同的组,信息可以在不同组之间流转。channel shuffle的实现步骤如下图所示:reshape--transpose-flatten
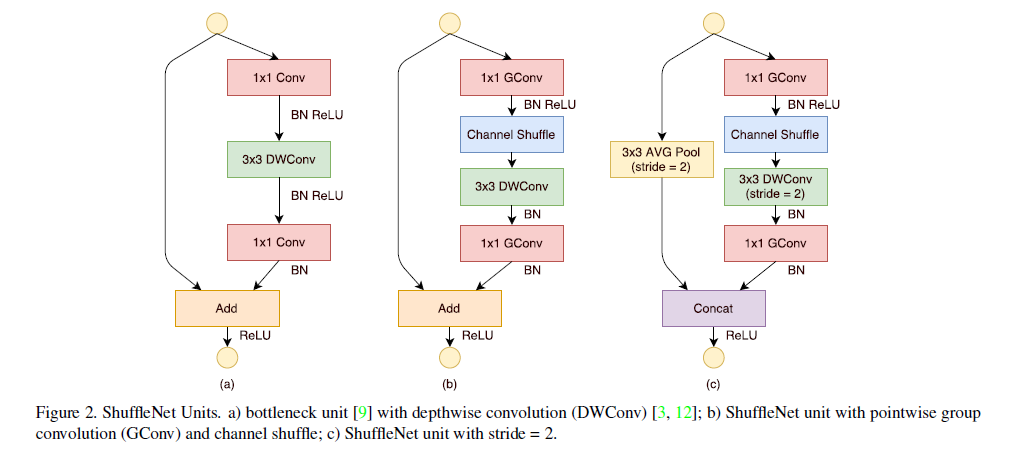
shufflleNet V1网络的基本单元如下图所示,相比a图中,b图将1x1的密集卷积换成分组卷积,添加了一个channel shuffle,另外3x3的depthwise convolution之后没有使用ReLU激活函数,图c中则采用stride=2,同时将elment-wise add 换成了concat。
shuffleNet V1特点,以及和ResNet和mobileNet的对比如下:

ShuffleNet V1的整体架构如下,每个stage都是shuffleNet基本单元的堆叠。

9.2 shuffleNet V2
shuffleNet V2 是2018年在论文ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design中提出的, 论文中针对设计快速的轻量级模型提出了四条指导方针(Guidelines):
(1)G1: 卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快

(2)G2: 过多的 group操作会增大MAC,从而使模型速度变慢

(3) G3: 模型中的分支数量越少,模型速度越快
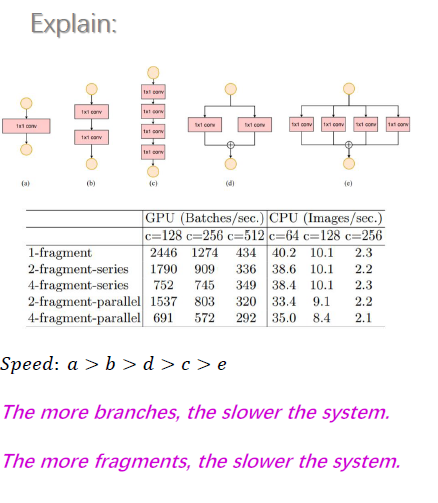
(4) G4:element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作。

论文中接着分析了其他网络模型违背了相应的原则方针,如下图所示:

针对上述四条guidelines,论文提出shuffleNet V2的基本单元,如下图:
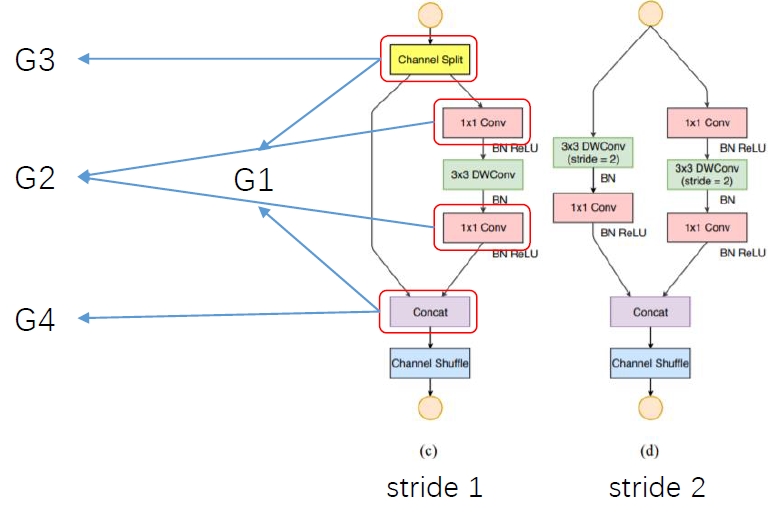
(1) channel split然后concat,保证输入输出channel一致,遵循准则1?
(2) 去掉1*1的分组卷积(channel split相当于分组了),遵循准则2
(3) channel split和将channel shuffle移动到后面,遵循准则3?
(4)利用concat代替add,遵循准则4
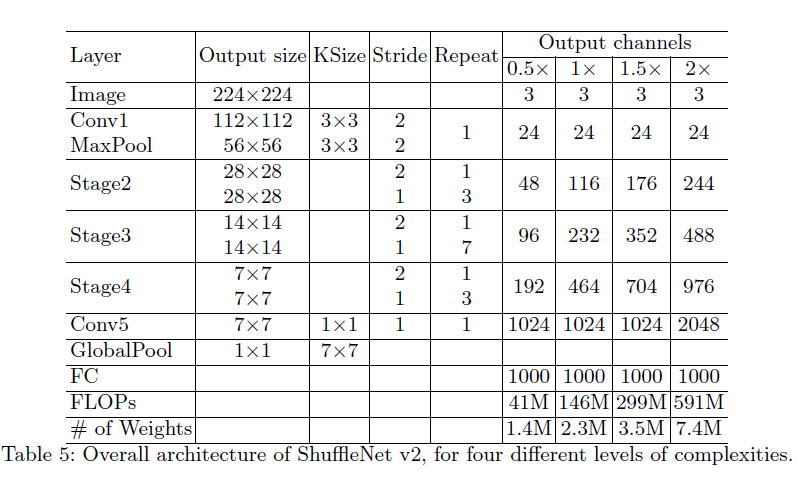
最后shuffleNet V2的整体架构如下:
参考:https://baijiahao.baidu.com/s?id=1589005428414488177&wfr=spider&for=pc
神经网络模型(Backbone)的更多相关文章
- BP神经网络模型与学习算法
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 建模算法(六)——神经网络模型
(一)神经网络简介 主要是利用计算机的计算能力,对大量的样本进行拟合,最终得到一个我们想要的结果,结果通过0-1编码,这样就OK啦 (二)人工神经网络模型 一.基本单元的三个基本要素 1.一组连接(输 ...
- BP神经网络模型及算法推导
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 手写数字识别 ----卷积神经网络模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----卷积神经网络模型 import os import tensorflow as tf #部分注释来源于 # http://www.cnblogs.com/rgvb178/p/ ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- 机器学习入门-BP神经网络模型及梯度下降法-2017年9月5日14:58:16
BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一. B ...
- 通过TensorFlow训练神经网络模型
神经网络模型的训练过程其实质上就是神经网络参数的设置过程 在神经网络优化算法中最常用的方法是反向传播算法,下图是反向传播算法流程图: 从上图可知,反向传播算法实现了一个迭代的过程,在每次迭代的开始,先 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
随机推荐
- java网络编程--httpurlconnection
HttpURLConnection是基于HTTP协议的,其底层通过socket通信实现.如果不设置超时(timeout),在网络异常的情况下,可能会导致程序僵死而不继续往下执行.可以通过以下两个语句来 ...
- SSM - SpringBoot - SpringCloud
SSM框架 Spring + Spring MVC + MyBatis:标准MVC模式 继 SSH (Struts+Spring+Hibernate)之后,主流的 Java EE企业级 Web应用程序 ...
- windows 下 redis 的安装及使用
1.下载及安装redis 下载地址:https://github.com/dmajkic/redis/downloads 找到对应的版本下载安装 打开cmd窗口,用cd命令进入到安装redis的根目录 ...
- Powershell-常用脚本
function Test-Port { Param([string]$ComputerName,$port = 5985,$timeout = 1000) try { $tcpclient = Ne ...
- Python函数Day5
一.内置函数 globals() 将全部的全局变量以字典的形式返回 locals() 将当前作用域的所有变量以字典的形式返回 a = 1 b = 2 def func(x): c = ...
- Linux 命令之 ln
ln 的作用是制作一个文件或者目录的快捷方式,让我们在使用的过程当中更加方便地使用. 下面我来简单介绍一下 ln 的基本用法. ln 的基本语法 生成一个软链 ln -s source_name li ...
- 26.C# 文件系统
1.流的含义 流是一系列具有方向性的字节序列,比如水管中的水流,只不过现在管道中装的不是水,而是字节序列.当流是用于向外部目标比如磁盘输出数据时称为输出流,当流是用于把数据从外部目标读入程序称为输入流 ...
- Codeforces Round #609 (Div. 2) D. Domino for Young
链接: https://codeforces.com/contest/1269/problem/D 题意: You are given a Young diagram. Given diagram i ...
- 使用Scrapy框架爬取腾讯新闻
昨晚没事写的爬取腾讯新闻代码,在此贴出,可以参考完善. # -*- coding: utf-8 -*- import json from scrapy import Spider from scrap ...
- springMvc--接受请求参数
作者:liuconglin 接收基本类型 表单: <h1>接受基本类型参数到Controller</h1> <form action="/param/test& ...