机器学习 - 算法示例 - Xgboost
安装
能直接安装就再好不过
pip install xgboost
如果不能就下载之后本地安装
安装包下载地址 这里 想要啥包都有

数据集
pima-indians-diabetes.csv 文件

调查印度糖尿病人的一些数据, 最终的预测结果是是否患病
# 1. Number of times pregnant
# 2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test
# 3. Diastolic blood pressure (mm Hg)
# 4. Triceps skin fold thickness (mm)
# 5. 2-Hour serum insulin (mu U/ml)
# 6. Body mass index (weight in kg/(height in m)^2)
# 7. Diabetes pedigree function
# 8. Age (years)
# 9. Class variable (0 or 1)
共有 8 个特征变量, 以及 1 个分类标签
Xgboost 使用
基础使用框架
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 下载数据集
datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签
X = datasets[:,0:8]
Y = datasets[:,8] # 切分 训练集 测试集
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建 训练
model = XGBClassifier()
model.fit(X_train, y_train) # 预测模型
y_pred = model.predict(X_test)
predictions = [round(i) for i in y_pred] # 精度计算
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" %(accuracy * 100) )
Accuracy: 77.95%
中间过程展示
Xgboost 的原理是在上一棵树的基础上通过添加树从而实现模型的提升的
如果希望看到中间的升级过程可以进行如下的操作
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 下载数据集
datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签
X = datasets[:,0:8]
Y = datasets[:,8] # 切分 训练集 测试集
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建 训练
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, # 传入的训练数据
early_stopping_rounds=10, # 当多少次的 lost值不在下降就停止模型
eval_metric='logloss', # lost 评估标准
eval_set=eval_set, # 构造一个测试集, 没加入一个就进行一次测试
verbose=True # 是否展示出中间的详细数据打印
) # 预测模型
y_pred = model.predict(X_test)
predictions = [round(i) for i in y_pred] # 精度计算
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" %(accuracy * 100) )
打印的过程中会体现出 lost 值的变化过程
[0] validation_0-logloss:0.660186
Will train until validation_0-logloss hasn't improved in 10 rounds.
[1] validation_0-logloss:0.634854
[2] validation_0-logloss:0.61224
[3] validation_0-logloss:0.593118
[4] validation_0-logloss:0.578303
[5] validation_0-logloss:0.564942
[6] validation_0-logloss:0.555113
[7] validation_0-logloss:0.54499
[8] validation_0-logloss:0.539151
[9] validation_0-logloss:0.531819
[10] validation_0-logloss:0.526065
[11] validation_0-logloss:0.519769
[12] validation_0-logloss:0.514979
[13] validation_0-logloss:0.50927
[14] validation_0-logloss:0.506086
[15] validation_0-logloss:0.503565
[16] validation_0-logloss:0.503591
[17] validation_0-logloss:0.500805
[18] validation_0-logloss:0.497605
[19] validation_0-logloss:0.495328
[20] validation_0-logloss:0.494777
[21] validation_0-logloss:0.494274
[22] validation_0-logloss:0.493333
[23] validation_0-logloss:0.492211
[24] validation_0-logloss:0.491936
[25] validation_0-logloss:0.490578
[26] validation_0-logloss:0.490895
[27] validation_0-logloss:0.490646
[28] validation_0-logloss:0.491911
[29] validation_0-logloss:0.491407
[30] validation_0-logloss:0.488828
[31] validation_0-logloss:0.487867
[32] validation_0-logloss:0.487297
[33] validation_0-logloss:0.487562
[34] validation_0-logloss:0.487789
[35] validation_0-logloss:0.487962
[36] validation_0-logloss:0.488218
[37] validation_0-logloss:0.489582
[38] validation_0-logloss:0.489334
[39] validation_0-logloss:0.490968
[40] validation_0-logloss:0.48978
[41] validation_0-logloss:0.490704
[42] validation_0-logloss:0.492369
Stopping. Best iteration:
[32] validation_0-logloss:0.487297 Accuracy: 77.56%
详细打印
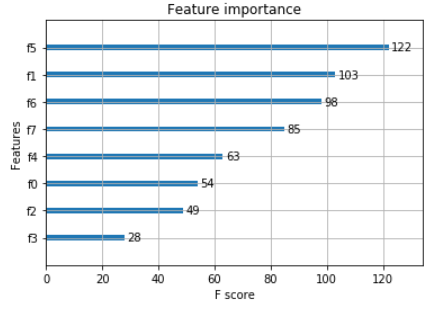
特征重要性展示
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot # 下载数据集
datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签
X = datasets[:,0:8]
Y = datasets[:,8] # 模型创建 训练
model = XGBClassifier()
model.fit(X, Y) # 展示特征重要程度
plot_importance(model)
pyplot.show()
参数调节
Xgboost 有很多的参数可以调节
常见参数
学习率
learning rate 一般设置在 0.1 以下
tree 相关参数
max_depth 最大深度
min_child_weight 最小叶子权重
subsample 随机选择比例
colsample_bytree 速记特征比例
gamma 损失率相关的一个参数
正则化参数
lambda
alpha
其他参数示例
更详细的的参数可以参考官方文档
xgb1 = XGBClassifier(
learning_rate= 0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective='binary:logistic', # 指定出是用什么损失函数, 一阶导还是二阶导
nthread=4, #
scale_pos_weight=1,
seed=27 # 随机种子
)
参数选择示例
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold # 下载数据集
datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签
X = datasets[:,0:8]
Y = datasets[:,8] # 模型创建 训练
model = XGBClassifier() # 学习率备选数据
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate) # 格式要求转换为字典格式 # 交叉验证
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) # 训练模型最佳学习率选择
grid_serarch = GridSearchCV(model,
param_grid,
scoring='neg_log_loss',
n_jobs=-1, # 当前所有 cpu 都跑这个事
cv=kfold)
grid_serarch = grid_serarch.fit(X, Y) # 打印结果
print("Best: %f using %s" % (grid_serarch.best_score_, grid_serarch.best_params_))
means = grid_serarch.cv_results_['mean_test_score']
params = grid_serarch.cv_results_['params'] for mean, param in zip(means, params):
print("%f with: %r" % (mean, param))
打印结果
Best: -0.483304 using {'learning_rate': 0.1}
-0.689811 with: {'learning_rate': 0.0001}
-0.661827 with: {'learning_rate': 0.001}
-0.531155 with: {'learning_rate': 0.01}
-0.483304 with: {'learning_rate': 0.1}
-0.515642 with: {'learning_rate': 0.2}
-0.554158 with: {'learning_rate': 0.3}
机器学习 - 算法示例 - Xgboost的更多相关文章
- 机器学习算法总结(四)——GBDT与XGBOOST
Boosting方法实际上是采用加法模型与前向分布算法.在上一篇提到的Adaboost算法也可以用加法模型和前向分布算法来表示.以决策树为基学习器的提升方法称为提升树(Boosting Tree).对 ...
- 机器学习算法中GBDT和XGBOOST的区别有哪些
首先xgboost是Gradient Boosting的一种高效系统实现,并不是一种单一算法.xgboost里面的基学习器除了用tree(gbtree),也可用线性分类器(gblinear).而GBD ...
- AI技术原理|机器学习算法
摘要 机器学习算法分类:监督学习.半监督学习.无监督学习.强化学习 基本的机器学习算法:线性回归.支持向量机(SVM).最近邻居(KNN).逻辑回归.决策树.k平均.随机森林.朴素贝叶斯.降维.梯度增 ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- Python实现的各种机器学习算法
七种算法包括: 线性回归算法 Logistic 回归算法 感知器 K 最近邻算法 K 均值聚类算法 含单隐层的神经网络 多项式的 Logistic 回归算法 01 线性回归算法 在线性回归中,我们想要 ...
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要: 数据挖掘.机器学习和推荐系统中的评测指标—准确率(Precision).召回率(Recall).F值(F-Measure)简介. 引言: 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型 ...
- 10 种机器学习算法的要点(附 Python 和 R 代码)
本文由 伯乐在线 - Agatha 翻译,唐尤华 校稿.未经许可,禁止转载!英文出处:SUNIL RAY.欢迎加入翻译组. 前言 谷歌董事长施密特曾说过:虽然谷歌的无人驾驶汽车和机器人受到了许多媒体关 ...
- 机器学习算法--GBDT
转自 http://blog.csdn.net/u014568921/article/details/49383379 另外一个很容易理解的文章 :http://www.jianshu.com/p/0 ...
- 机器学习算法( 五、Logistic回归算法)
一.概述 这会是激动人心的一章,因为我们将首次接触到最优化算法.仔细想想就会发现,其实我们日常生活中遇到过很多最优化问题,比如如何在最短时间内从A点到达B点?如何投入最少工作量却获得最大的效益?如何设 ...
随机推荐
- 【OF框架】新建库表及对应实体,并实现简单的增删改查操作,封装操作标准WebApi
准备 搭建好项目框架及数据库,了解框架规范. 1.数据库表和实体一一对应,表名实体名名字相同,用小写,下划线连接.字段名用驼峰命名法,首字母大写. 2.实体放在Entities目录下,继承Entity ...
- python数据类型:dict(字典)
一.字典的简单介绍 字典(dict)是python中唯一的一个映射类型.他是以{}括起来的键值对组成. 语法: {key1:value1,key2:value2......} 注意:key必须是不可变 ...
- Linux添加shell(.sh)脚本并添加定时任务
一.添加sheel脚本 1.首先创建一个执行程序:vim a.sh 2.编辑: #!/bin/bash python3 python.py >> test2.log 2>& ...
- Linux基础之终端、控制台、tty、pty等概念简介
基本概念: 1>tty(终端设备的统称): tty一词源于teletypes,或者teletypewriters,原来指的是电传打字机,是通过串行线用打印机键盘阅读和发送信息的东西,后来这东西被 ...
- 2019-2020-1 20199312《Linux内核原理与分析》第三周作业
计算机的三大法宝:程序存储计算机.函数调用.中断 堆栈的作用:记录函数调用框架.传递函数参数.保存返回值地址.提供函数内部局部便量的存储空间. 堆栈相关的寄存器 ESP:堆栈指针,指向堆栈栈顶 EBP ...
- sql server 存储过程---游标的循环
sqlserver中的循环遍历(普通循环和游标循环) sql 经常用到循环,下面介绍一下普通循环和游标循环 1.首先需要一个测试表数据Student
- Spring第四天
顾问包装通知 通知(advice)是Spring中的一种比较简单的切面,只能将切面织入到目标类的所有方法中,而无法对指定方法进行增强 顾问(advisor)是Spring提供的另外一种切面,可以织入到 ...
- sphinx和coreseek
sphinx是国外的一款搜索软件. coreseek是在sphinx的基础上,增加了中文分词功能,换句话说,就是支持了中文. Coreseek发布了3.2.14版本和4.1版本,其中的3.2.14版本 ...
- AS400 printer setting
(1) CRTOUTQ OUTQ(TESTLIB/PRINTER2) (2) CRTDEVPRT ===> CRTDEVPRT DEVD(PRINTER2) DEVCLS(*LAN) TYPE( ...
- plupload上传整个文件夹
大容量文件上传早已不是什么新鲜问题,在.net 2.0时代,HTML5也还没有问世,要实现这样的功能,要么是改web.config,要么是用flash,要么是用一些第三方控件,然而这些解决问题的方法要 ...