Hadoop简介及架构
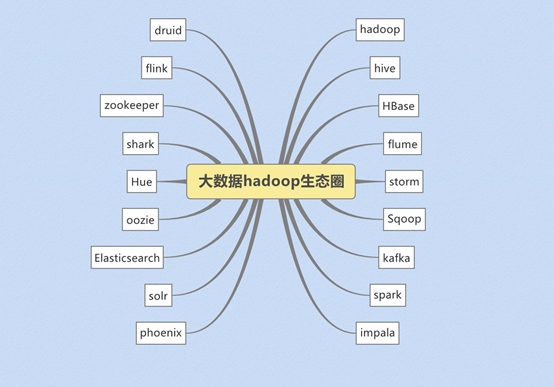
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件

2、hadoop的历史版本介绍
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
3、hadoop三大公司发型版本介绍
免费开源版本apache:
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到,学习可以用,实际生产工作环境尽量不要使用
apache所有软件的下载地址(包括各种历史版本):
http://archive.apache.org/dist/
免费开源版本hortonWorks:
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)
软件收费版本ClouderaManager:
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用
4、hadoop的架构模型(1.x,2.x的各种架构模型介绍)
4.1、1.x的版本架构模型介绍

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
JobTracker:接收用户的计算请求任务,并分配任务给从节点
TaskTracker:负责执行主节点JobTracker分配的任务
4.2、2.x的版本架构模型介绍
第一种:NameNode与ResourceManager单节点架构模型
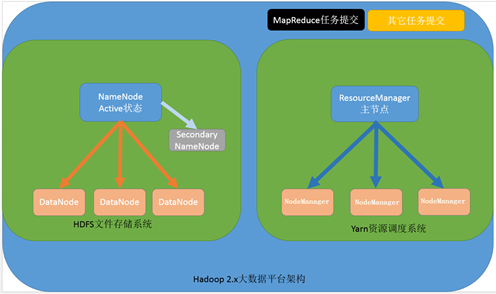
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务
第二种:NameNode单节点与ResourceManager高可用架构模型

文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分,通过zookeeper实现ResourceManager的高可用
NodeManager:负责执行主节点ResourceManager分配的任务
第三种:NameNode高可用与ResourceManager单节点架构模型
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,其中nameNode可以有两个,形成高可用状态
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
JournalNode:文件系统元数据信息管理
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配,以及计算任务的划分
NodeManager:负责执行主节点ResourceManager分配的任务
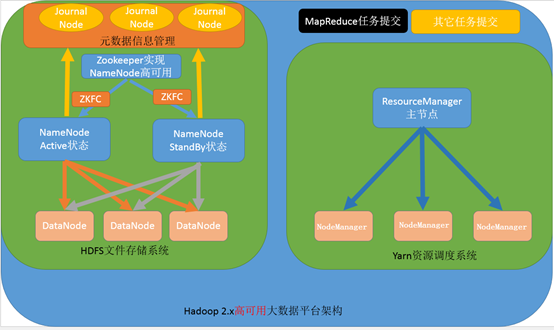
第四种:NameNode与ResourceManager高可用架构模型
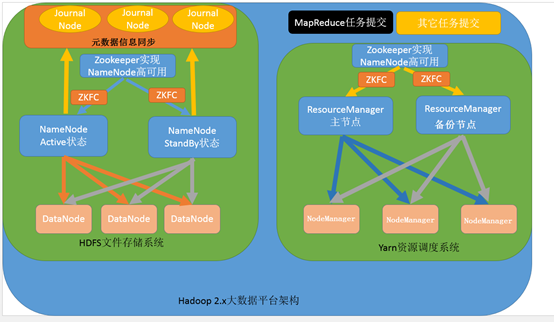
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据,一般都是使用两个,实现HA高可用
JournalNode:元数据信息管理进程,一般都是奇数个
DataNode:从节点,用于数据的存储
数据计算核心模块:
ResourceManager:Yarn平台的主节点,主要用于接收各种任务,通过两个,构建成高可用
NodeManager:Yarn平台的从节点,主要用于处理ResourceManager分配的任务
Hadoop简介及架构的更多相关文章
- NO.1 hadoop简介
第一次接触这个时候在网上查了很多讲解,以下很多只是来自网络. 1.Hadoop (1)Hadoop简介 Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层 ...
- Hadoop简介与分布式安装
Hadoop的基本概念和分布式安装: Hadoop 简介 Hadoop 是Apache Lucene创始人道格·卡丁(Doug Cutting)创建的,Lucene是一个应用广泛的文本搜索库,Hado ...
- 1 预备知识--Hadoop简介
1 预备知识--Hadoop简介 Hadoop是Apache的一个开源的分布式计算平台,以HDFS分布式文件系统和MapReduce分布式计算框架为核心,为用户提供了一套底层透明的分布式基础设施Had ...
- Amazon EMR(Elastic MapReduce):亚马逊Hadoop托管服务运行架构&Hadoop云服务之战:微软vs.亚马逊
http://s3tools.org/s3cmd Amazon Elastic MapReduce (Amazon EMR)简介 Amazon Elastic MapReduce (Amazon EM ...
- Hadoop1-认识Hadoop大数据处理架构
一.简介概述 1.什么是Hadoop Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构 Hadoop是基于java语言开发,具有很好的跨平 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- Hadoop工程包架构解析
Hadoop源码解析 1 --- Hadoop工程包架构解析 1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算 ...
- 基于hadoop的BI架构
BI系统,是企业利用数据驱动运营的一个典型系统.BI系统通过发掘企业运行过程中的数据,发现企业的潜在风险.为企业的各项决策提供数据支撑. 传统的BI系统通常构建于关系型数据库之上.随着企业业务量的增大 ...
- Hadoop:Hadoop简介及环境配置
http://blog.csdn.net/pipisorry/article/details/51243805 Hadoop简介 下次写上... 皮皮blog 配置hadoop环境可能出现的问题 每次 ...
随机推荐
- cookbook 6.1 温标的转换
任务: 在开氏温度(Kelvin).摄氏度(Celsius).华氏温度(Fahrenheit).兰金温度(Rankine)之间做转换 解决方案: #coding=utf-8 class Tempera ...
- mysql5.7提示密码过期的解决方法
首先把MySQL关闭 打开一个终端,输入 sudo /usr/local/mysql/bin/mysqld_safe --skip-grant-tables 执行完命令后,再打开一个新的终端 sudo ...
- codeforces643D
阿狸的基环内向树森林 Background 当阿狸醒来的时候,发现自己处在基环内向森林的深处,阿狸渴望离开这个乌烟瘴气的地方.“明天还有与桃子的约会呢”,阿狸一边走一边说,“可是,这个森林的出口在哪儿 ...
- Python基础之变量和常量
变量 将运算得到中间结果暂存到内存,以便后续程序调用. 变量的命名规则: 变量由字母.数字.下划线搭配组合而成 不能以数字开头,更不能全是数字 不能是Python中的关键字,这些符号和字母已经被Pyt ...
- vue添加外部js
1.新建节点 const s = document.createElement("script"); 2.设置节点属性 s.type = "text/javascript ...
- PHP-异常-1
PHP 错误处理 在 PHP 中,默认的错误处理很简单.一条消息会被发送到浏览器,这条消息带有文件名.行号以及一条描述错误的消息. 在创建脚本和 web 应用程序时,错误处理是一个重要的部分.如果您的 ...
- 网络爬虫技术实现java依赖库整理输出
网络爬虫技术实现java依赖库整理输出 目录 1 简介... 2 1.1 背景介绍... 2 1.2 现有方法优缺点对比... 2 2 实现方法... 2 ...
- HailStone序列
目前HailStone序列还未被证明是否有穷,所以它未必是一个算法. * HailStone序列* n=1时,返回1:* n>1时且为偶数时,{n} ∪ {n/2}* n>1时且为奇数时, ...
- LeetCode 136. 只出现一次的数字(Single Number)
题目描述 给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次.找出那个只出现了一次的元素. 说明: 你的算法应该具有线性时间复杂度. 你可以不使用额外空间来实现吗? 示例 1: ...
- spark streaming 6: BlockGenerator、RateLimiter
BlockGenerator和RateLimiter其实很简单,但是它包含了几个很重要的属性配置的处理,所以记录一下. ))) , SECONDS) From WizNote