zookeeper集群
0,Zookeeper基本原理
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
ZooKeeper采用一种称为Leader election的选举算法(也有称做:分布式选举算法-Paxos)的。在整个集群运行过程中,只有一个Leader,其他的都是Follower,如果ZooKeeper集群在运行过程中Leader出了问题,系统会采用该算法重新选出一个Leader,
ZooKeeper用于三台以上的服务器集群之中,只要还有超过半数的服务器在线,ZooKeeper就能够正常提供服务,过半,意味着实际能够有效参与选举的节点数量是奇书个数,否者不能有效的过半
Zookeeper逻辑图如下,
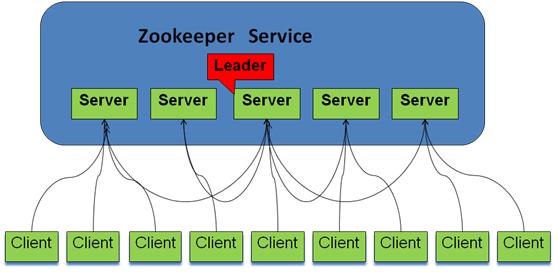
- 客户端可以连接到每个server,每个server的数据完全相同。
- 每个follower都和leader有连接,接受leader的数据更新操作。
- Server记录事务日志和快照到持久存储。
- 大多数server可用,整体服务就可用。
- Leader节点在接收到数据变更请求后,首先将变更写入本地磁盘,以作恢复之用。当所有的写请求持久化到磁盘以后,才会将变更应用到内存中。
- ZooKeeper使用了一种自定义的原子消息协议,在消息层的这种原子特性,保证了整个协调系统中的节点数据或状态的一致性。Follower基于这种消息协议能够保证本地的ZooKeeper数据与Leader节点同步,然后基于本地的存储来独立地对外提供服务。
- 当一个Leader节点发生故障失效时,失败故障是快速响应的,消息层负责重新选择一个Leader,继续作为协调服务集群的中心,处理客户端写请求,并将ZooKeeper协调系统的数据变更同步(广播)到其他的Follower节点。
1,系统环境配置
我这里使用的是在VMWare中安装centos7每个虚拟机都选择桥接模式。即可在网络中独立分配一个IP,每台机器单独设定一个IP。
- 配置hosts:vi /etc/hosts
192.168.137.122 master
192.168.137.123 slave1
192.168.137.124 slave2
- 关闭防火墙 (很重要,不然会出现No rout to host异常)
systemctl status firewalld.service #检查防火墙状态
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #禁止开机启动防火墙
- 关闭SELINUX:vi /etc/selinux/config
#SELINUX=enforcing #注释掉
#SELINUXTYPE=targeted #注释掉
SELINUX=disabled #增加 - 4. 立即生效配置
setenforce #使配置立即生效
2,java安装环境变量配置
略
3,配置无密钥的SSH访问
在此处为了方便,我将所有网内的节点机器都互相能SSH无密钥登录,可以理解为双向无密钥登录。
- 使用下列命令在每个虚拟机上都生成密钥
ssh-keygen -t rsa #生成密钥,一路回车即可,只适用于测试环境,正式环境请设定密码
- 每个节点机器的公钥传输到master机器上
scp ~/.ssh/id_rsa.pub master:~/.ssh/slave1.id_rsa.pub #在slave1中,将公钥文件传输至master机器上,并修改文件名为slave1.id_rsa.pub
scp ~/.ssh/id_rsa.pub master:~/.ssh/slave2.id_rsa.pub #在slave2中,将公钥文件传输至master机器上,并修改文件名为slave2.id_rsa.pub - 在master机器上生成统一的authorized_keys
cd ~/.ssh
cat id_rsa.pub >> authorized_keys #这个是master生成的公钥,就在本机
cat slave1.id_rsa.pub >> authorized_keys
cat slave2.id_rsa.pub >> authorized_keys完成后可以使用rm -f slave1.id_rsa.pub删除拷贝过来的秘钥文件
- 将统一的authorized_keys分发至每个节点
scp authorized_keys root@master1:~/.ssh
scp authorized_keys root@master2:~/.ssh
authorized_keys是公钥的字典文件,这样下来所有的,所有节点的authorized_keys文件中记录的秘钥都相同了,因为可以实现每个机器的ssh互通了。
4,Zookeeper集群安装
zookeeper安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个目录,修改一下配置即可。
- 下载zookeeper-3.4.8,使用下列命令解压到指定路径
tar -zxvf zookeeper-3.4.8.tar.gz
mv zookeeper-3.4.8 /home/zookeeper #这里可以指定你喜欢的任意目录 - 修改环境变量:vi /etc/profile 加入下列内容
# set zookeeperpath
export ZOOKEEPER_HOME=/home/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin - 使用下面命令复制配置文件(也可直接建立)
cp /home/zookeeper/conf/zoo_sample.cfg /home/zookeeper/conf/zoo.cfg
- 使用 vi /home/zookeeper/conf/zoo.cfg 修改配置文件,具体内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/zookeeper/zkdata
dataLogDir=/home/zookeeper/zklog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=slaver1:2888:3888
server.3=slaver2:2888:3888tickTime: zookeeper中使用的基本时间单位, 毫秒值.
dataDir: 数据目录. 可以是任意目录.
dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置.
clientPort: 监听client连接的端口号.
nitLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。 - 创建myid文件:在zoo.cfg指定的dataDir目录下建立以服务器节点对应的myid文件,如master节点中,创建myid文件内容为1,slave1中创建myid文件内容为2...
- 使用下列命令将zoopeeper拷贝到其他节点
scp /home/zookeeper root@master1: /home/
scp /home/zookeeper root@master2: /home/完成后,只需在其他节点上修改vi /etc/profile,以及对应的myid,即可
4,启动Zookeeper集群
- 在所有节点执行下列命令启动
cd /home/zookeeper
bin/zkServer.sh start正常会显示如下状态

- 使用jps命令查看系统进程

- 使用下列命令检查运行状态
bin/zkServer.sh -status
如显示一下状态表示启动失败

具体失败原因可阅读zookeeper/zookeeper.out文件查阅
如显示一下状态表示启动成功
查看其余节点,整个包括集群中各个结点的角色会有一个leader,其他都是follower。
我们通过more zookeeper.out检查启动输入日志,会发现有下列异常
我启动的顺序是master>slave1>slave2,由于ZooKeeper集群启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
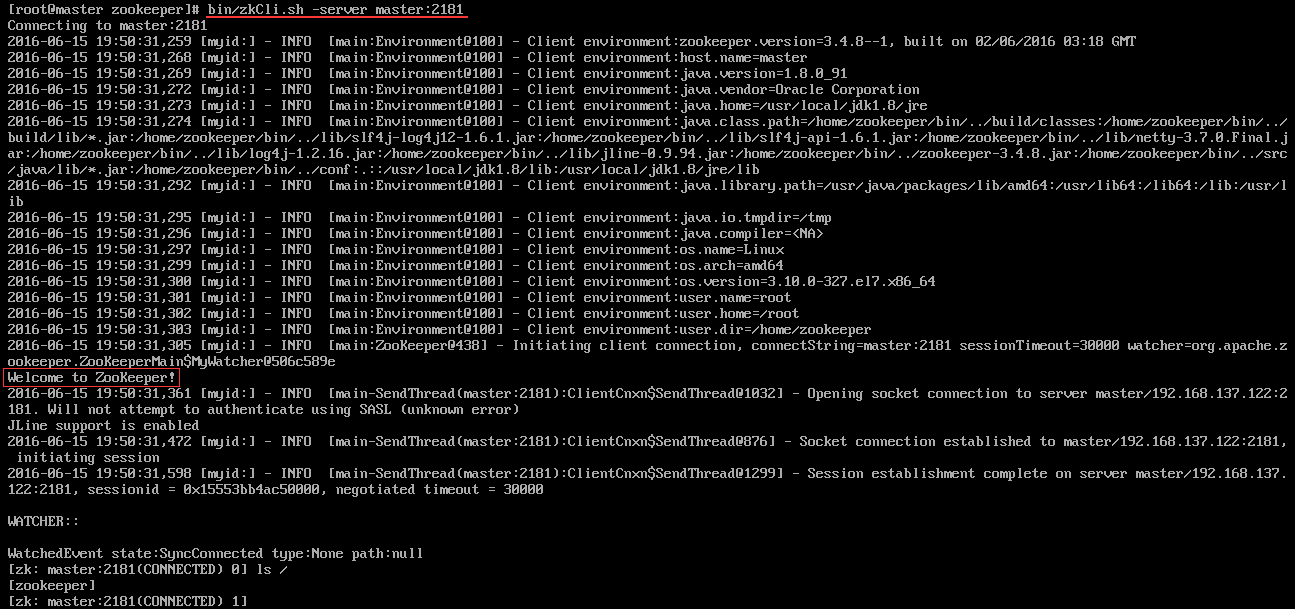
其他结点可能也出现类似问题,属于正常。 - 客户端连接测试: 对于客户端来说,ZooKeeper是一个整体(ensemble),无论连接到那个节点,实际上都在独享整个ZooKeeper集群的服务,所以,我们可以在任何一个结点上建立到服务集群的连接
5,参考
- zookeeper项目使用几点小结 http://agapple.iteye.com/blog/1184023
- ZooKeeper架构设计及其应用要点 http://shiyanjun.cn/archives/474.html
- ZooKeeper原理及使用 http://blog.csdn.net/xinguan1267/article/details/38422149
- Zookeeper 的学习与运用 http://blog.jiguang.cn/push_zookeeper_study_usage/
- Zookeeper-Zookeeper leader选举 http://www.cnblogs.com/yuyijq/p/4116365.html
- zookeeper原理 http://cailin.iteye.com/blog/2014486
zookeeper集群的更多相关文章
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- ZooKeeper1 利用虚拟机搭建自己的ZooKeeper集群
前言: 前段时间自己参考网上的文章,梳理了一下基于分布式环境部署的业务系统在解决数据一致性问题上的方案,其中有一个方案是使用ZooKeeper,加之在大数据处理中,ZooKeeper确实起 ...
- 构建高可用ZooKeeper集群
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
- 搭建zookeeper集群
简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置 ...
- ZooKeeper集群搭建中的Connection refused而导致的启动失败
1. 前言 每一次搭建集群环境都像一次战斗,作战中任何一个细节的出错都会导致严重的后果,所以搭建中所需要做的配置如系统配置.网络配置(防火墙记得关).用户权限.文件权限还有配置文件等等内容,都必须非常 ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- 构建高可用ZooKeeper集群(转载)
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
- solrCloud+tomcat+zookeeper集群配置
solrcolud安装solrCloud+tomcat+zookeeper部署 转载请出自出处:http://eksliang.iteye.com/blog/2107002 http://eksli ...
- zookeeper集群某个follower启动失败
配置完成zookeeper集群,发现有一个节点,进程正常但是状态异常 查看日志一开始进入歧途了,查看的是这个目录 其实应该查看这个目录的日志 失败日志: 很明显,没有权限,更改权限,启动成功
随机推荐
- Redis学习笔记~目录
回到占占推荐博客索引 百度百科 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合). ...
- 《SQL必知必会》—— 读后总结
- LINQ系列:Linq to Object分组操作符
分组是指根据一个特定的值将序列中的值或元素进行分组.LINQ只包含一个分组操作符:GroupBy. GroupBy 1>. 原型定义 public static IQueryable<IG ...
- SQL Server中In-Flight日志究竟是多少
在SQL Server中,利用日志的WAL来保证关系数据库的持久性,但由于硬盘的特性,不可能使得每生成一条日志,就直接向磁盘写一次,因此日志会被缓存起来,到一定数据量才会写入磁盘.这部分已经生 ...
- Android 圆形头像 自己动手
圆形头像DIY 现在大部分app使用的都是圆形头像,网上开源的也很多,但是有没有考虑过DIY圆形头像呢?下面就自己实现一个,先看下demo展示 第一步:原理解释(图片很丑,原理很真) 1.画外框圆形, ...
- 【求助】WPF 在XP下 有的Textbox光标会消失
最近做个项目,一直有一个问题没有解决,就是在XP下,有的Textbox里在文本框里没有东西的时候,会没有光标.不同的XP机器,失去光标的Textbox也不一样. 各位大师看下面的三张图,当Textbo ...
- jquery $.each的用法
通过它,你可以遍历对象.数组的属性值并进行处理. 使用说明 each函数根据参数的类型实现的效果不完全一致: 1.遍历对象(有附加参数) $.each(Object, function(p1, p2) ...
- Cinder 组件详解 - 每天5分钟玩转 OpenStack(47)
本节我们将详细讲解 Cinder 的各个子服务. cinder-api cinder-api 是整个 Cinder 组件的门户,所有 cinder 的请求都首先由 nova-api 处理.cinder ...
- 小菜学习Winform(二)WMPLib实现音乐播放器
前言 现在网上有很多的音乐播放器,但好像都不是.net平台做的,在.net中实现音乐文件的播放功能很简单,下面就简单实现下. SoundPlayer类 在.net提供了音乐文件的类:SoundPlay ...
- eclipse导入项目Archive for required library cannot be read or is not a valid ZIP file
原因 :部分文件毁坏. 解决办法:1. 在eclipse中运行maven clean install 2. 报错,找到报错的文件物理删除,然后重新运行maven clean install 3. 循 ...