使用Keras基于AdvancedEAST的场景图像文本检测
Blog:https://blog.csdn.net/linchuhai/article/details/84677249
GitHub:https://github.com/huoyijie/AdvancedEAST
自然场景文本检测
自然场景文字是图像高层语义的一种重要载体,自然场景文本检测是图像处理的核心模块,近年来ICDAR的历界比赛成绩不断提升:
Result:http://rrc.cvc.uab.es/?ch=4&com=evaluation&task=1>v=1
EAST
论文:旷视 - CVPR2017 - EAST: An Efficient and Accurate Scene Text Detector
Github:https://github.com/argman/EAST https://github.com/kurapan/EAST
优点
1)步骤简化:传统的文本检测方法和一些基于深度学习的文本检测方法,大多是Multi-stage,在训练时需要对多个Stage调优,这势必会影响最终的模型效果,而且非常耗时。针对上述存在的问题,EAST提出了端到端的文本检测方法,消除中间多个Stage(如候选区域聚合,文本分词,后处理等),直接预测文本行,其架构就是下图中对应的E部分,跟前面的方法比起来的确少了比较多的过程。(类似于经典的CTPN架构)
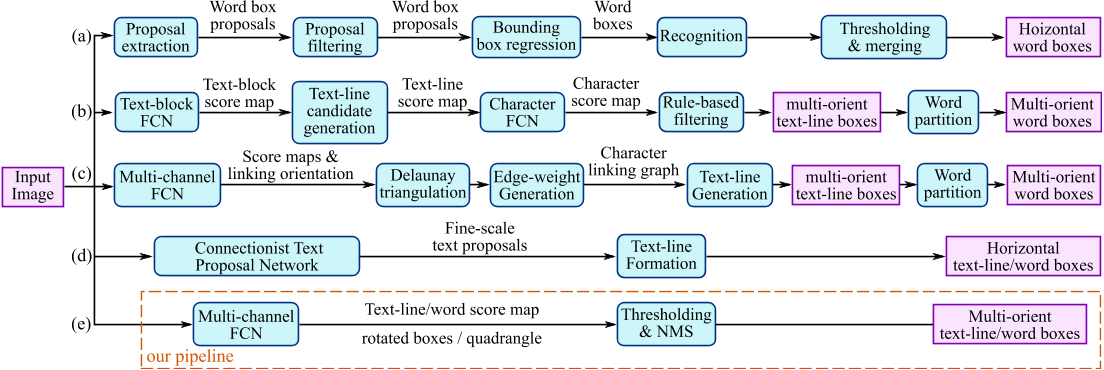
2)多方向文本定位:虽然CTPN方法在水平文本的检测方面效果比较好,但是对于竖直文本或者倾斜的文本,该方法的检测就很差,而EAST能支持多方向文本的定位。
网络结构
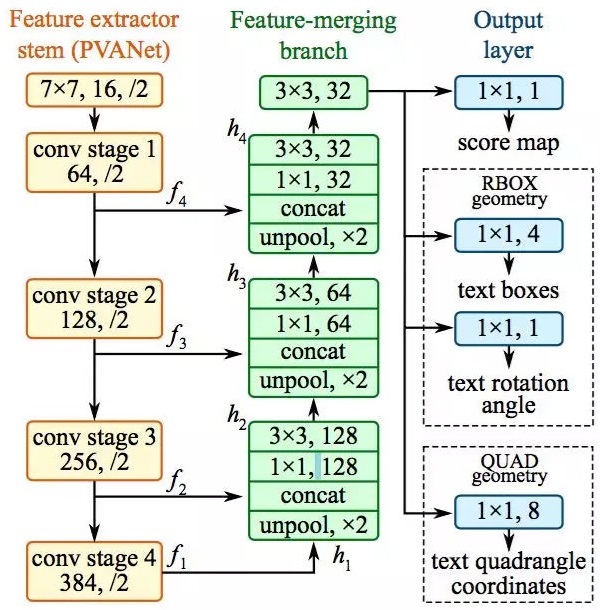
AdvancedEAST
开源:https://github.com/huoyijie/AdvancedEAST
优点
- 基于Keras,易于阅读和运行
- 基于EAST,一种先进的文本检测算法
- 易于训练模型
- 进行了重大改进,长文本预测更准确
分析:实验中,AdvancedEast获得了比East更好的预测准确性,特别是在长文本上。这是因为原始East使用所有像素的预测顶点坐标的加权平均值计算最终顶点坐标,而从四边形的另一侧预测2个顶点比较困难。
网络结构
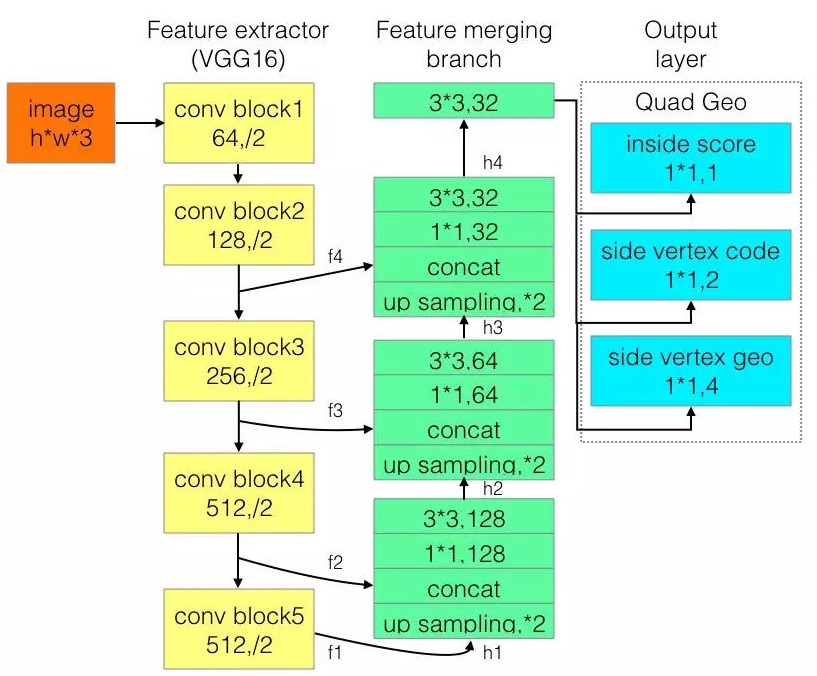
输出层分别是1位score map, 是否在文本框内;2位vertex code,是否属于文本框边界像素以及是头还是尾;4位geo,是边界像素可以预测的2个顶点坐标。所有像素构成了文本框形状,然后只用边界像素去预测回归顶点坐标。边界像素定义为黄色和绿色框内部所有像素,是用所有的边界像素预测值的加权平均来预测头或尾的短边两端的两个顶点。头和尾部分边界像素分别预测2个顶点,最后得到4个顶点坐标。
限制:检测器可以处理的文本实例的最大尺寸与网络的感受野成比例。 这限制了网络预测更长文本区域的能力,例如跨越图像的文本行。此外,对于垂直文本实例,该算法可能漏掉或给出不精确的预测,因为它们只占ICDAR 2015训练集中的一小部分文本区域。
|--data|----test|-------demo 测试样例|-------predict 预测样例|----train|-------ICPR_text_train ICPR MTWI 2018 图文识别挑战赛数据集
|--model|----east_model_weights_*.h5 模型权重文件|----vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 keras下基于tensorflow的VGG16模型notop权重系数h5文件 |--predict 预测|----num.py |----predict.py
|--train|----cfg.py 参数配置|----preprocess.py 数据预处理|----label.py 数据标签生成|----network.py 网络结构定义|----losses.py 损失函数定义|----data_generator.py 训练数据生成|----advanced_east.py 模型训练
数据集
tianchi ICPR dataset - https://pan.baidu.com/s/1NSyc-cHKV3IwDo6qojIrKA(ye9y)- ICPR MTWI 2018挑战赛:网络图像的文本检测
标签点
- 按顺序排列四个点,逆时针旋转,且第一个点为左上角点
刚开始选择最左边的点,如果最后计算的第二个点的Y比第一个点大,那就让最后一个点做为第一个点,其他点依次右移
- 以最小的X坐标为起点(起名为A)
- 其他三个点和第一个点(A)连线形成夹角,取中间的点为第三个点(起名C)
- 以AC为连线,在AC上方为D,下方为B
- 最后比较AC和BD的斜率,AC>BD,则顺序调整为DABC;AC<BD,则维持ABCD
例如:
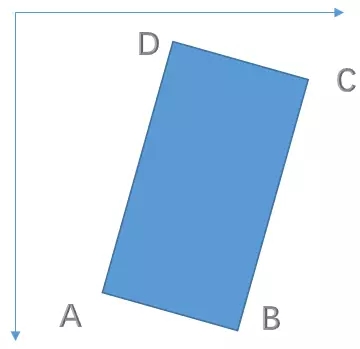
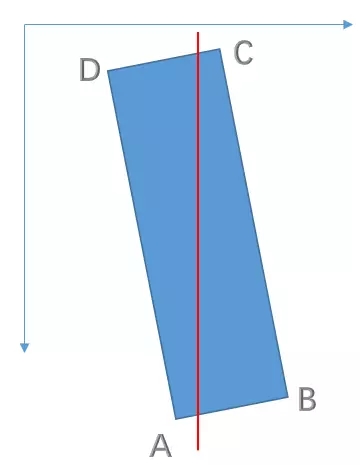
- 注意长边的位置:针对上面两幅图,第一张的
long_edge=0,2,第二张的long_edge=1,3
标签切边
- 以最短边的0.3进行缩放当做内部点

- 以最短边的0.6作为头尾点
- 注意:这里头尾都是针对最长边上的操作
- 注意:头和尾是按照标签点的顺序进行的,排在前面为头,排在后面为尾
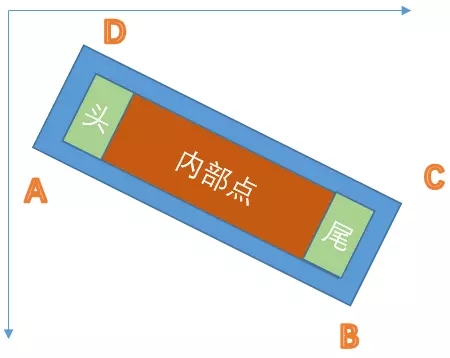
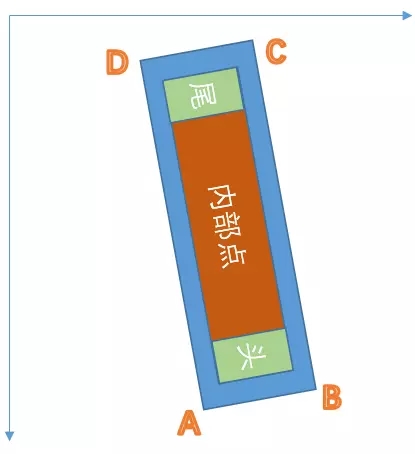
训练
预处理 - 调整图像大小为256*256、384*384、512*512、640*640、736*736(分别训练可以加快训练过程)
预训练模型 - https://pan.baidu.com/s/1KO7tR_MW767ggmbTjIJpuQ(kpm2)
1)准备数据集 # 数据集格式 - /ICPR_text_train/train_1000 # cfg.py定义images/labels路径 image_1000/*.jpg txt_1000/*.txt - X1,Y1,X2,Y2,X3,Y3,X4,Y4,“文本” # X1,Y1,Y2,X2,X3,X4,Y3,Y4 对于文本内容的四边形顶点 )参数配置 cfg.py )预处理 preprocess.py # 若原始图片过多,可不resize过多图片,[256,736]够了,其在cfg.py更改 )生成标签信息 label.py # 比较耗时 )执行模型训练 advanced_east.py
loss计算
#input : 1*w*h*3
#label : 1*160*160*7(batch,w,h,type)
def quad_loss(y_true, y_pred):
# loss for inside_score
logits = y_pred[:, :, :, :1]
labels = y_true[:, :, :, :1]
# balance positive and negative samples in an image
beta = 1 - tf.reduce_mean(labels)
# first apply sigmoid activation
predicts = tf.nn.sigmoid(logits)
# log +epsilon for stable cal
inside_score_loss = tf.reduce_mean(
-1 * (beta * labels * tf.log(predicts + cfg.epsilon) +
(1 - beta) * (1 - labels) * tf.log(1 - predicts + cfg.epsilon)))
inside_score_loss *= cfg.lambda_inside_score_loss
# loss for side_vertex_code
vertex_logits = y_pred[:, :, :, 1:3]
vertex_labels = y_true[:, :, :, 1:3]
vertex_beta = 1 - (tf.reduce_mean(y_true[:, :, :, 1:2])
/ (tf.reduce_mean(labels) + cfg.epsilon))
vertex_predicts = tf.nn.sigmoid(vertex_logits)
pos = -1 * vertex_beta * vertex_labels * tf.log(vertex_predicts +
cfg.epsilon)
neg = -1 * (1 - vertex_beta) * (1 - vertex_labels) * tf.log(
1 - vertex_predicts + cfg.epsilon)
positive_weights = tf.cast(tf.equal(y_true[:, :, :, 0], 1), tf.float32)
side_vertex_code_loss = \
tf.reduce_sum(tf.reduce_sum(pos + neg, axis=-1) * positive_weights) / (
tf.reduce_sum(positive_weights) + cfg.epsilon)
side_vertex_code_loss *= cfg.lambda_side_vertex_code_loss
# loss for side_vertex_coord delta
g_hat = y_pred[:, :, :, 3:]
g_true = y_true[:, :, :, 3:]
vertex_weights = tf.cast(tf.equal(y_true[:, :, :, 1], 1), tf.float32)
pixel_wise_smooth_l1norm = smooth_l1_loss(g_hat, g_true, vertex_weights)
side_vertex_coord_loss = tf.reduce_sum(pixel_wise_smooth_l1norm) / (
tf.reduce_sum(vertex_weights) + cfg.epsilon)
side_vertex_coord_loss *= cfg.lambda_side_vertex_coord_loss
return inside_score_loss + side_vertex_code_loss + side_vertex_coord_loss
def smooth_l1_loss(prediction_tensor, target_tensor, weights):
n_q = tf.reshape(quad_norm(target_tensor), tf.shape(weights))
diff = prediction_tensor - target_tensor
abs_diff = tf.abs(diff)
abs_diff_lt_1 = tf.less(abs_diff, 1)
pixel_wise_smooth_l1norm = (tf.reduce_sum(
tf.where(abs_diff_lt_1, 0.5 * tf.square(abs_diff), abs_diff - 0.5),
axis=-1) / n_q) * weights
return pixel_wise_smooth_l1norm
def quad_norm(g_true):
shape = tf.shape(g_true)
delta_xy_matrix = tf.reshape(g_true, [-1, 2, 2])
diff = delta_xy_matrix[:, 0:1, :] - delta_xy_matrix[:, 1:2, :]
square = tf.square(diff)
distance = tf.sqrt(tf.reduce_sum(square, axis=-1))
distance *= 4.0
distance += cfg.epsilon
return tf.reshape(distance, shape[:-1])
if __name__ == '__main__':
x, y = data_generator.gen(1)
loss_t = quad_loss(y,y)
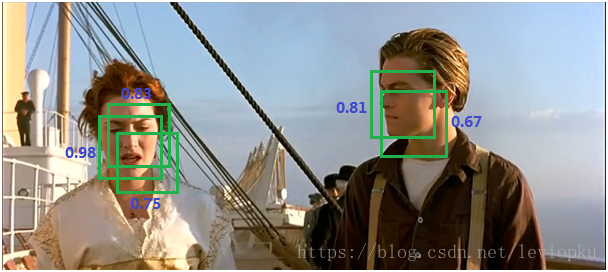
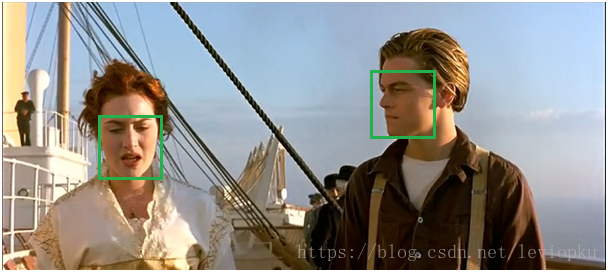
NMS(非极大值抑制)
- 作用:去掉detection任务重复的检测框(不是局部的最大值都去除)
基于前面的网络(如RPN)能为每个框给出一个score,score越大证明框越接近期待值。如上图,两个目标分别有多个选择框,现在要去掉多余的选择框。分别在局部选出最大框,然后去掉和这个框IOU>0.7的框。
pixel_threshold = 0.9 #内部点阈值(目标点概率) side_vertex_pixel_threshold = 0.9 #内部头尾点的阈值 ##头尾点取值范围,head->[0,trunc_threshold] tail->[1-trunc_threshold,1],变大之后检测能力变强 trunc_threshold = 0.1
预测


使用Keras基于AdvancedEAST的场景图像文本检测的更多相关文章
- 【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST)
文字识别分为两个具体步骤:文字的检测和文字的识别,两者缺一不可,尤其是文字检测,是识别的前提条件,若文字都找不到,那何谈文字识别.今天我们首先来谈一下当今流行的文字检测技术有哪些. 文本检测不是一件简 ...
- 使用Keras基于RCNN类模型的卫星/遥感地图图像语义分割
遥感数据集 1. UC Merced Land-Use Data Set 图像像素大小为256*256,总包含21类场景图像,每一类有100张,共2100张. http://weegee.vision ...
- OpenCV_contrib里的Text(自然场景图像中的文本检测与识别)
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake 待解决!!!Issue说明:最近做一些字符识别的事情,想试一下opencv_contrib里的Text(自然场景 ...
- EAST 自然场景文本检测
自然场景文本检测是图像处理的核心模块,也是一直想要接触的一个方面. 刚好看到国内的旷视今年在CVPR2017的一篇文章:EAST: An Efficient and Accurate S ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 使用Python基于VGG/CTPN/CRNN的自然场景文字方向检测/区域检测/不定长OCR识别
GitHub:https://github.com/pengcao/chinese_ocr https://github.com/xiaofengShi/CHINESE-OCR |-angle 基于V ...
- 图像文本跨模态细粒度语义对齐-置信度校正机制 AAAI2022
论文介绍:Show Your Faith: Cross-Modal Confidence-Aware Network for Image-Text Matching (跨模态置信度感知的图像文本匹配网 ...
- 深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全
深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全 原文地址:Image Completion with Deep Learning in TensorFlow by Bra ...
随机推荐
- Linux之zookeeper开机启动
1.用cd 命令切换到/etc/rc.d/init.d/目录下 [root@bogon ~]# cd /etc/rc.d/init.d 2.用touch zookeeper创建一个文件 [root@b ...
- super 和 this 的区别
一 this和super关键字区别 1.子类的构造函数如果要引用super的话,必须把super放在函数的首位.2.super(参数):调用基类中的某一个构造函数(应该为构造函数中的第一条语句)3.t ...
- Linux网络编程一、tcp三次握手,四次挥手
一.TCP报文格式 (图片来源网络) SYN:请求建立连接标志位 ACK:应答标志位 FIN:断开连接标志位 二.三次握手,数据传输,四次挥手 (流程图,图片来源于网络) (tcp状态转换图,图片来源 ...
- php " ",0,'0',false ==判断
今天项目中遇到的一个问题,举个栗子: if($_GET['is_has_idcard']==0 || $_GET['is_has_idcard']==1){ echo '这次我要上传身份证'; } i ...
- 黑马lavarel教程---13、分页
黑马lavarel教程---13.分页 一.总结 一句话总结: - lavarel里面的分页操作和tp里面的分页操作几乎是一模一样的 - 控制器:$data=Lesson::paginate(2); ...
- maven pom.xml基本设置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/20 ...
- Jmeter之集合点
Jmeter之集合点 Jmeter中也有集合点,看样子还是很强呀 哇哈哈 它只是通过计时器Synchronizing Timer实现的假集合点功能. 没有时间整理,来实际的,直接上图. 在线程下添加集 ...
- SQLserver本地数据库开发
远程端数据库中生成脚本 注意 远程端的数据库 是中文版的还是英文版的,一般我们装的是英文版的, 如果远程端数据库是中文版的,那么我们本地的是英文版,在生成的脚本那需要修改,同时去除相应的路劲代码. 修 ...
- Python-数据库索引浅谈
检索原理 检索初识 索引在MySQL中是一种"键",是存储引擎用于快速找到记录的一种数据结构.索引对于良好的检索性能,非常关键,尤其是当表中的数据量越大,索引对于性能的提升越显 ...
- pytorch中的激励函数(详细版)
初学神经网络和pytorch,这里参考大佬资料来总结一下有哪些激活函数和损失函数(pytorch表示) 首先pytorch初始化: import torch import t ...