数据分析 - seaborn 模块
seaborn 模块
简述
对 matplotlib 模块进行了二次封装, 底层依旧使用还是 matplotlib 的, 但是在此基础上增加了很多的易用性模板, 更加方便使用
引用使用
import seaborn as sns

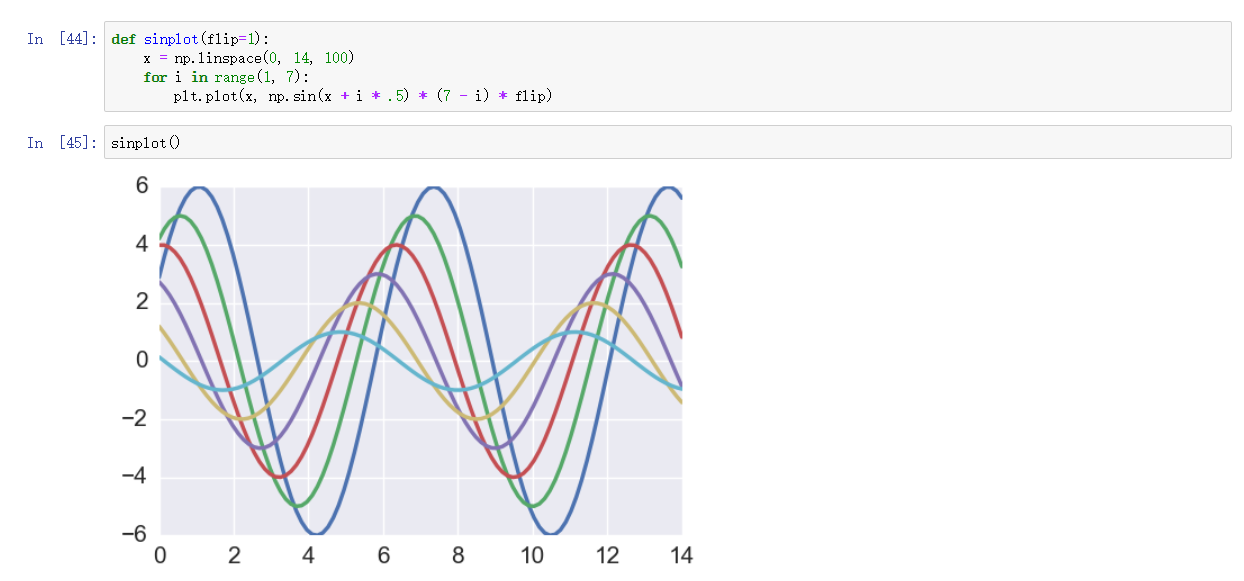
对比 matplotlib 默认风格
默认风格的方法 - set
主题风格
设置风格 - set_style
可选参数
- darkgrid
- whitegrid
- dark
- white
- ticks
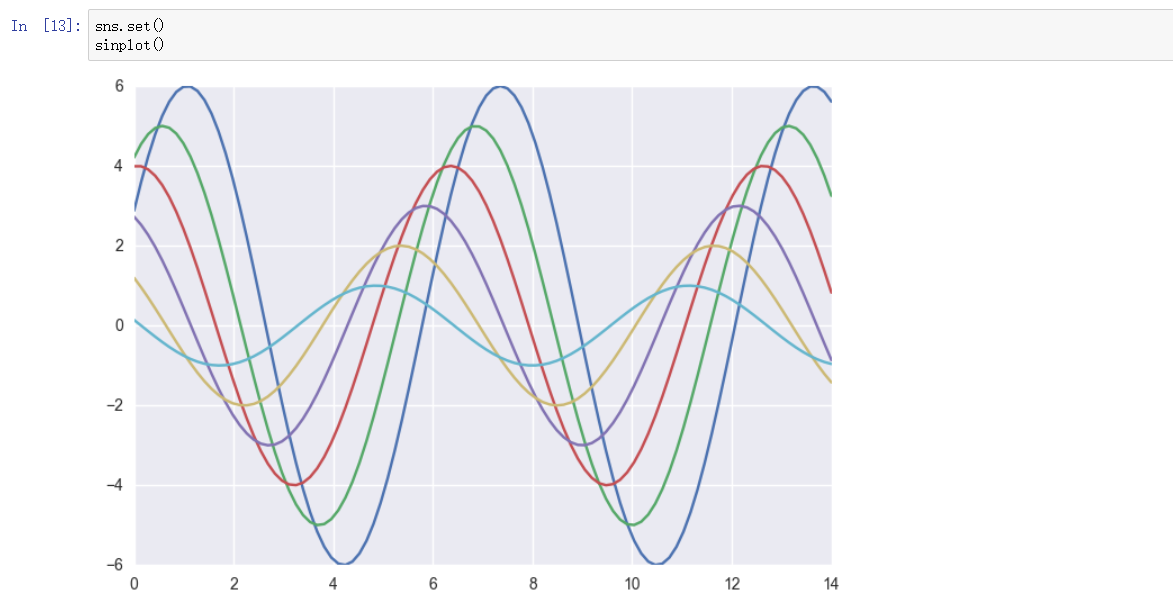
white 风格
完全的清亮背景色, 无刻线, 无刻度尺
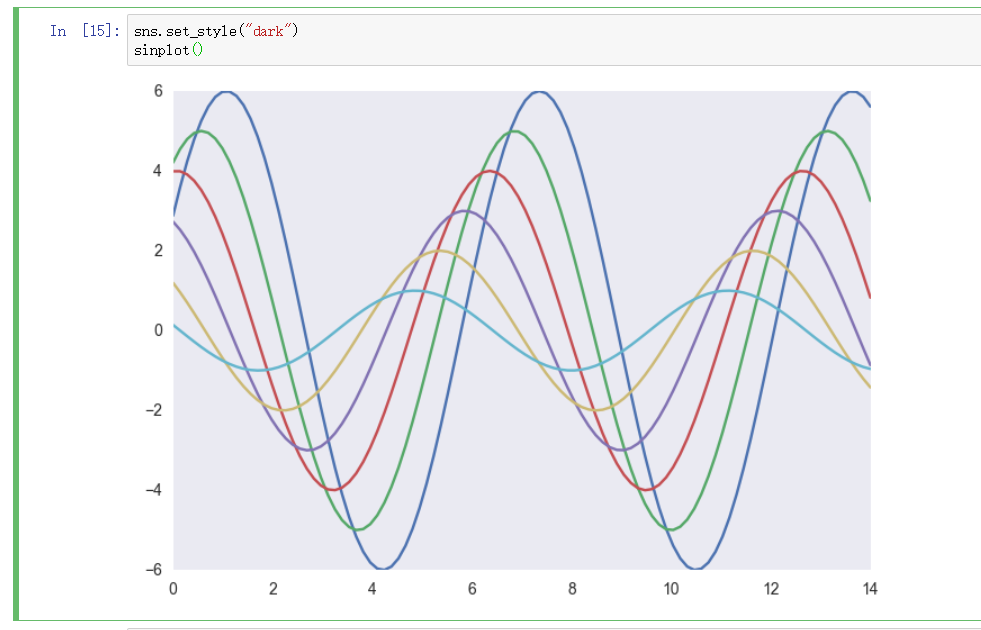
drak 风格
背景色深灰, 无刻线, 无刻度尺
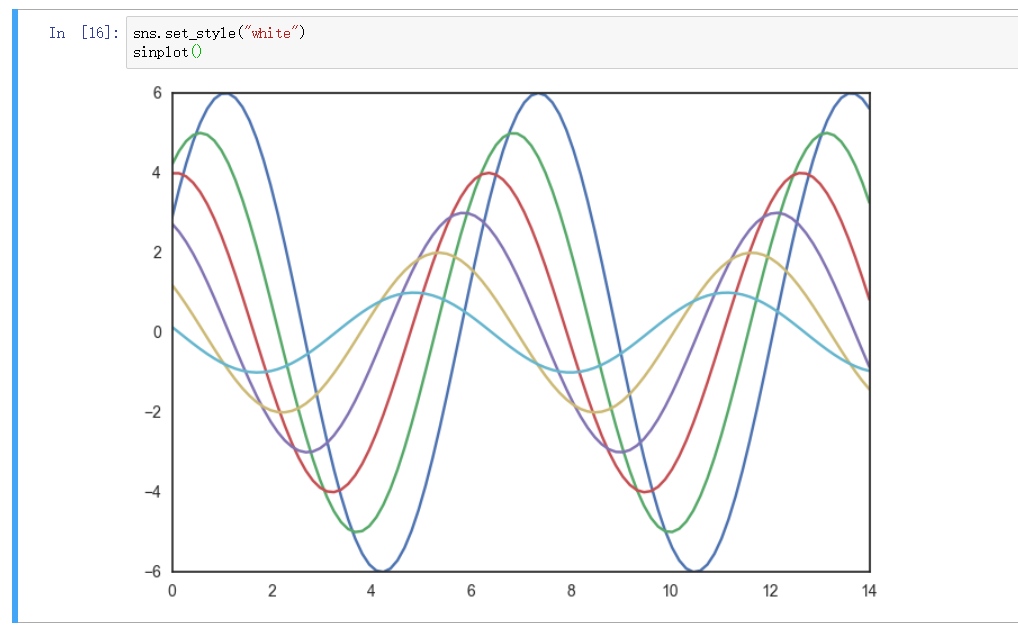
whitegrid 风格
带有 y轴 数据刻线, 背景清亮
ticks 风格
带有刻度尺
darkgrid 风格
带有x, y 刻线, 且背景深灰, 无刻度尺
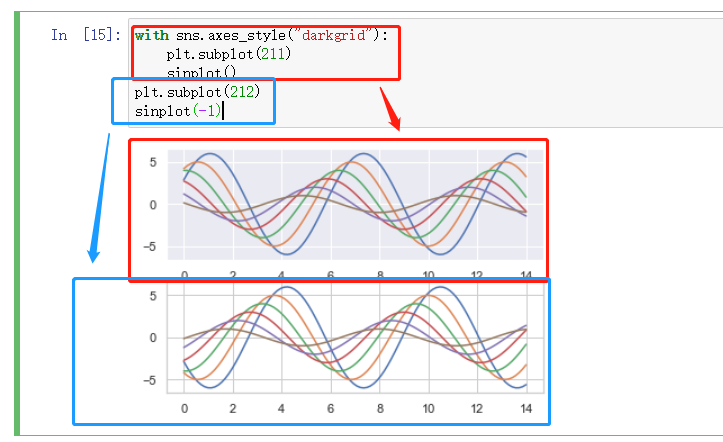
批量执行风格 - axes_style
在缩进内的都可以套用此风格, 在画子图的时候使用此方法设定不同的风格可以更直观的看出差异,方便观察
自定义风格修改
默认的主题风格是比较固定的, 可以在此基础上进行一定的修改满足自定制
修改边界线 - despine
去掉上面和右边的线,
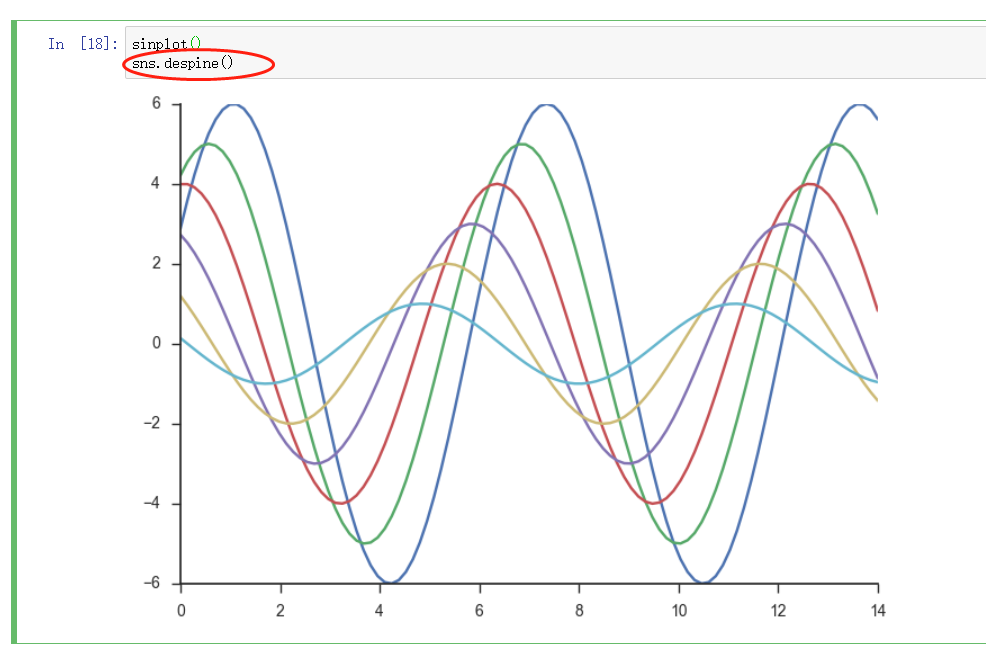
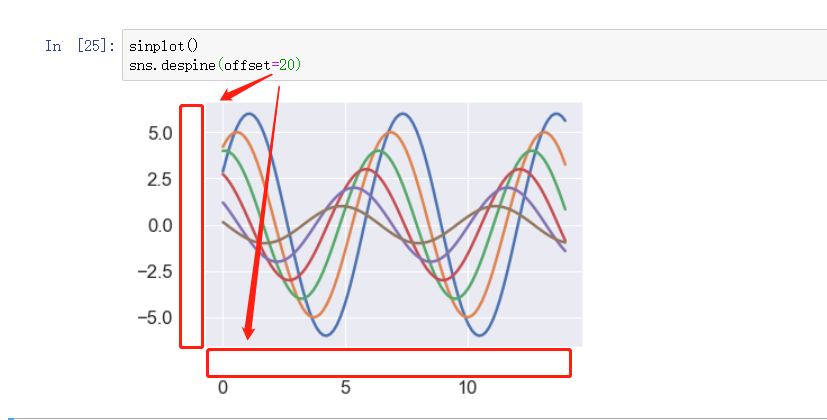
可设置参数 offset 设置 数值与坐标轴线的距离
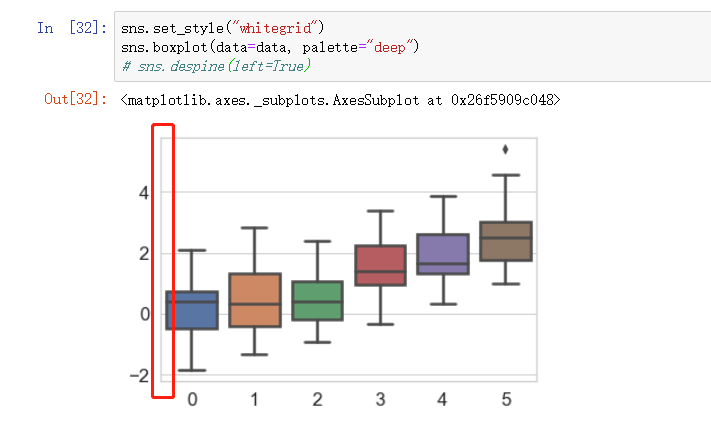
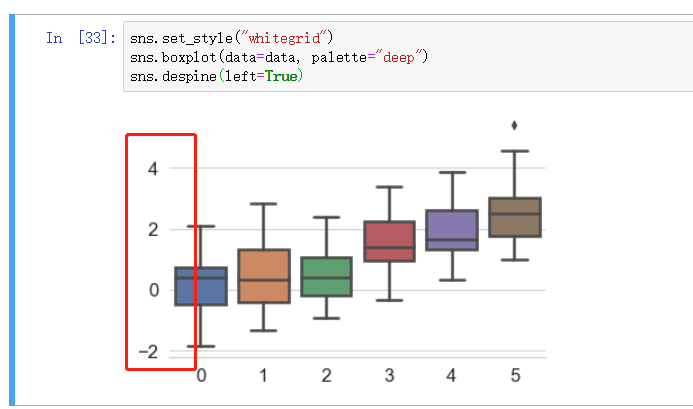
可设置参数 left 去除左右的边界线, 其他方位可选是, top , bottom , right
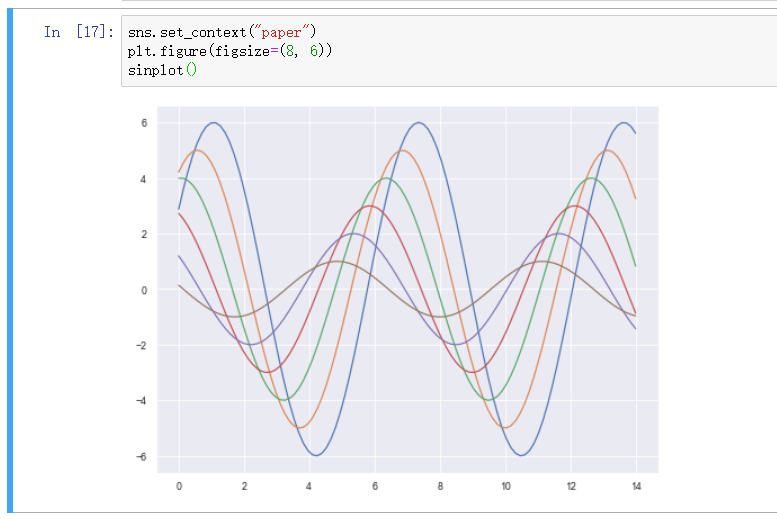
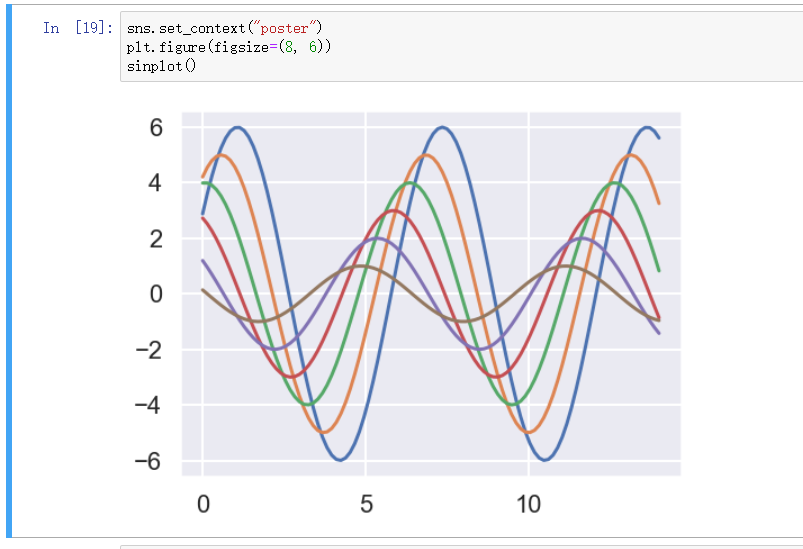
修改布局 - set_context
可选风格
- paper
- talk
- poster
- notebook
大小从小到大, 里面的格子可以看得出来哦


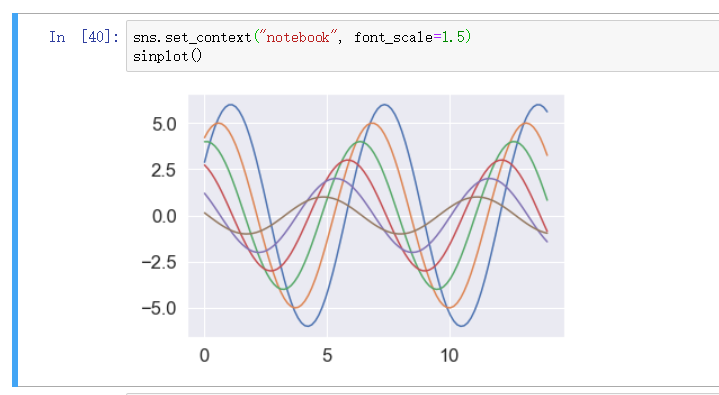
可选参数 font_scale 设定字体大小
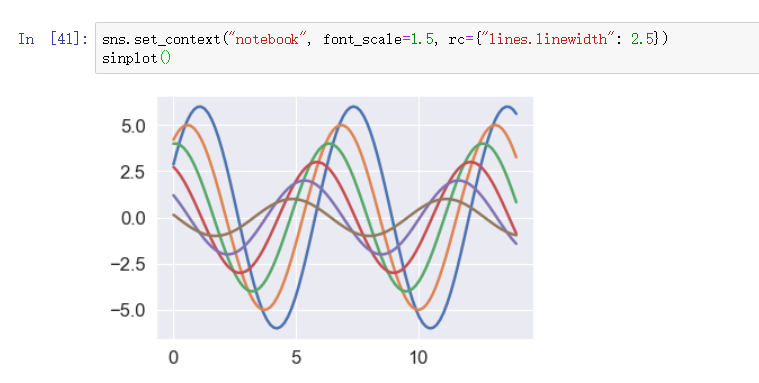
可选参数 rc 设定线的粗细
调色板
调色板 - 离散型
- 颜色很重要 - 用于展示数据更直观的体现, 颜色区分展示是很舒适的
- color_palette() 能传入任何Matplotlib所支持的颜色
- color_palette() 不写参数则默认颜色
- set_palette() 设置所有图的颜色
默认色板 - color_palette
6个默认的颜色循环主题: deep , muted , pastel , bright , dark , colorblind

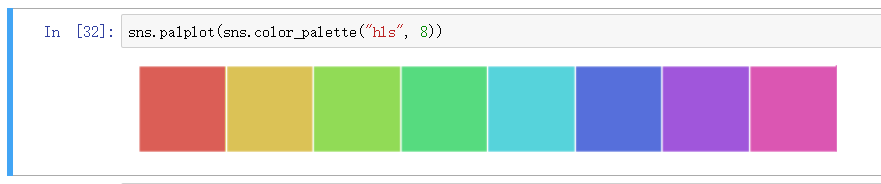
画板 - hls 空间
当你有六个以上的分类要区分时,最简单的方法就是在一个圆形的颜色空间中画出均匀间隔的颜色(这样的色调会保持亮度和饱和度不变)。
这是大多数的当他们需要使用比当前默认颜色循环中设置的颜色更多时的默认方案。
最常用的方法是使用 hls 的颜色空间,这是RGB值的一个简单转换。
使用方法具体就是输入一个数字, 则输出多少颜色, hls 画板适合快速的生成多色画板


画板 - Paired 空间
Paired 适用于成对出现的色板排列. 用于某些数据对更加直观方便

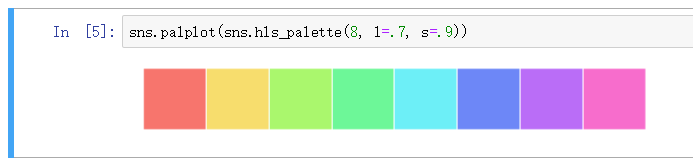
饱和度, 亮度 - hls_palette
hls_palette 函数来控制颜色的亮度和饱和
- l - 亮度 lightness
- s - 饱和 saturation
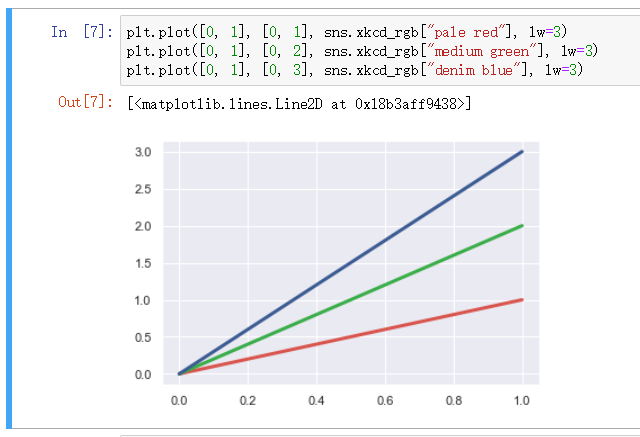
指定颜色 - xkcd
指定特定颜色的时候使用 xkcd_rgb 函数可实现 , 传入参数为键值形式取值, 可对颜色类型和深浅进行特化
xkcd 包含了一套众包努力的针对随机RGB色的命名。产生了954个可以随时通过 xdcd_rgb 字典中调用的命名颜色。

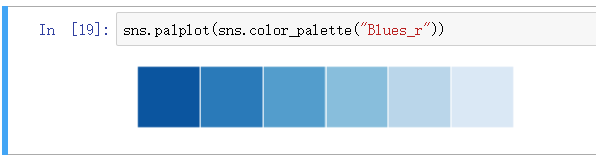
调色板 - 连续型
连续型色板用于相同色系的深浅度进行渐变处理

默认是由浅到深的渐变, 翻转则在选取颜色后加 _r 进行翻转
画板 - cubehelix_palette
色调线性变换 ,可以使用 color_palette 传参 "cubehelix" 或者直接使用 cubehelix_palette 函数
推荐后者, 后者可以传递更多的参数以及自动提示更方便
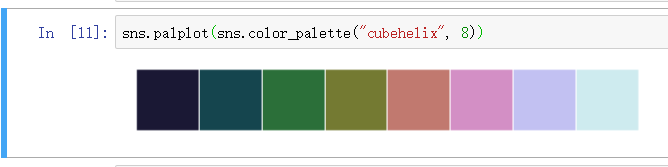
颜色区间 - start,rot
cubehelix_palette 函数的可选参数 start,rot 控制颜色区间

指定深浅 - light_palette,dark_palette


简单示例

变量分析
单变量分析
数据范式,基础准备

直方图 - distplot
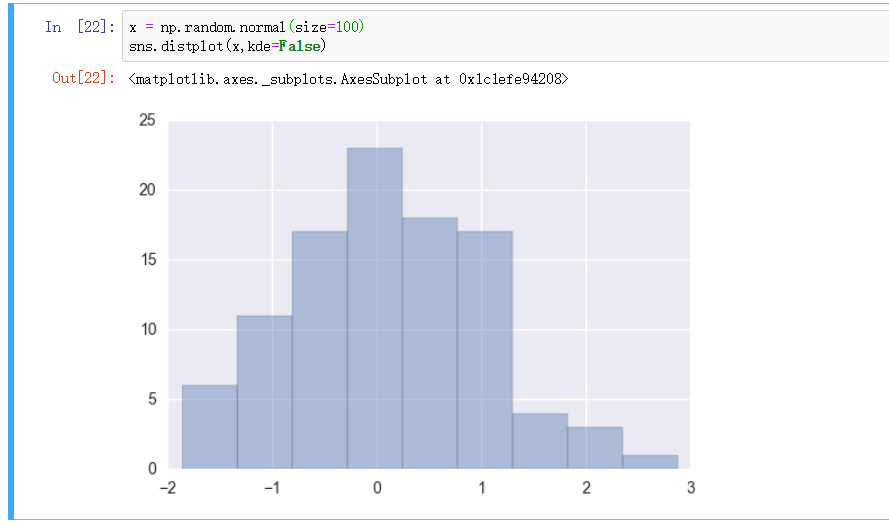
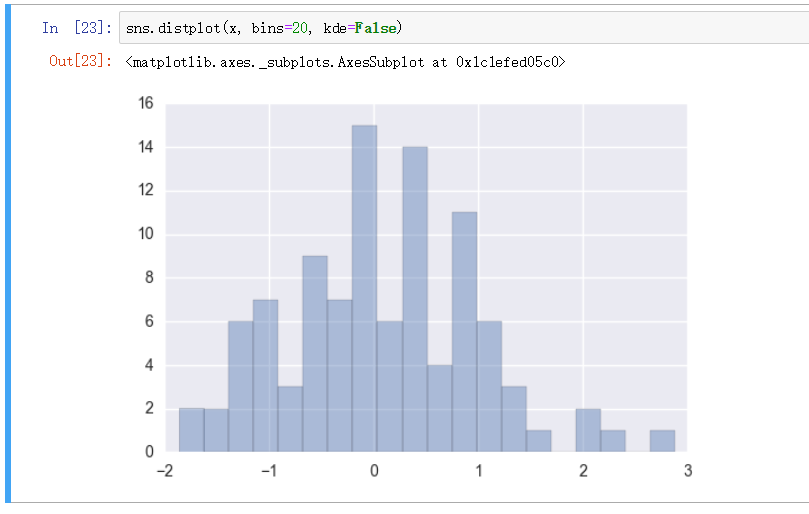
也可以指定 bins 的大小, 更细化的展示数据
加入 fit 展示统计指标

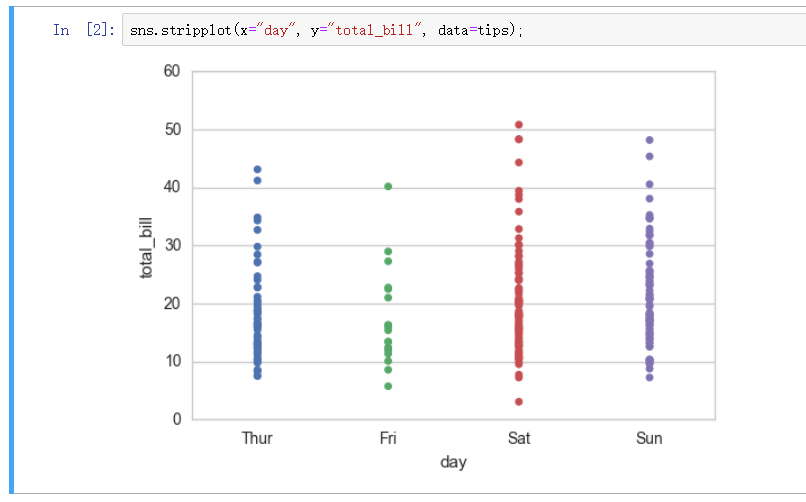
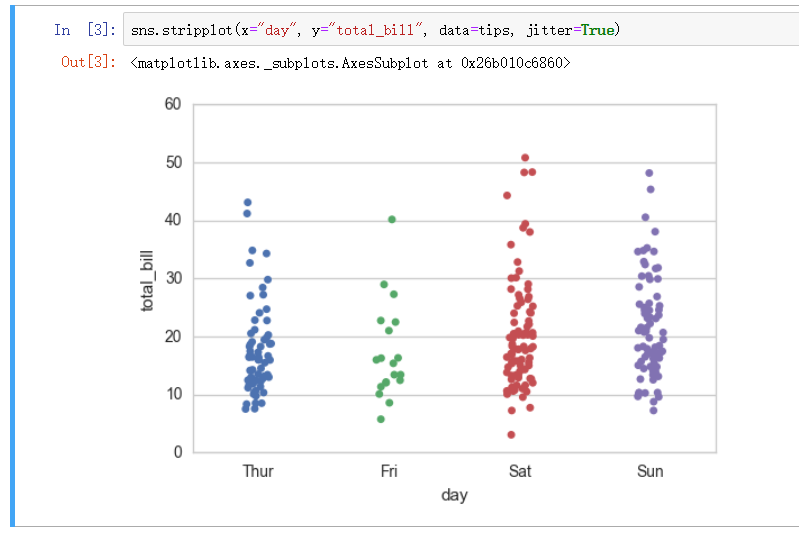
分布散点图 - stripplot
stripplot 函数创建散点图展示单变量数据量
但是数据过大出现的重叠会导致堆积造成连线成面等现象无法正确观察
重叠处理 - 偏移 jitter
设置 jitter 可以使数据偏移左右位置散开展示, 但是看起来还是不太直观
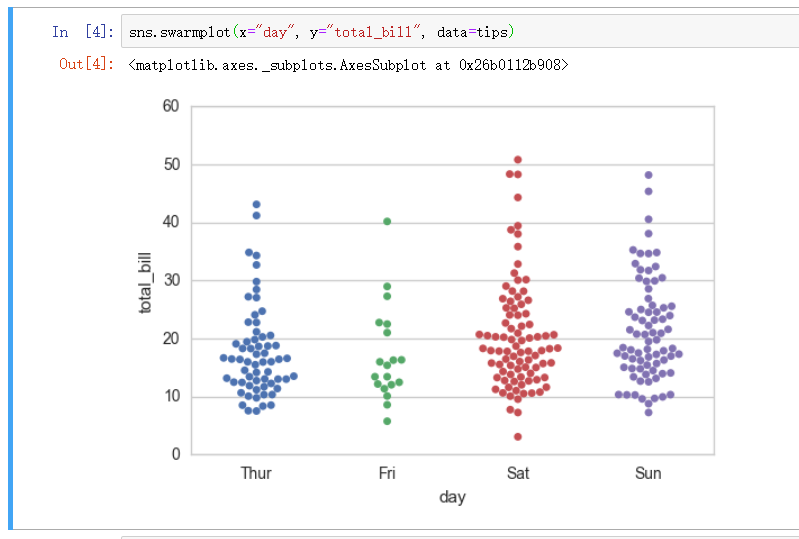
分簇散点图 - swarmplot
swarmplot 创建的散点图则彻底将数据散开呈现圣诞树结构, 更加清晰的展示
盒型图 - boxplot
盒型图概念
- IQR即统计学概念四分位距,第1/4分位 与 第3/4之间的距离
- N = 1.5IQR 如果一个值>Q3+N或 < Q1-N,则为离群点

小提琴图 - violinplot
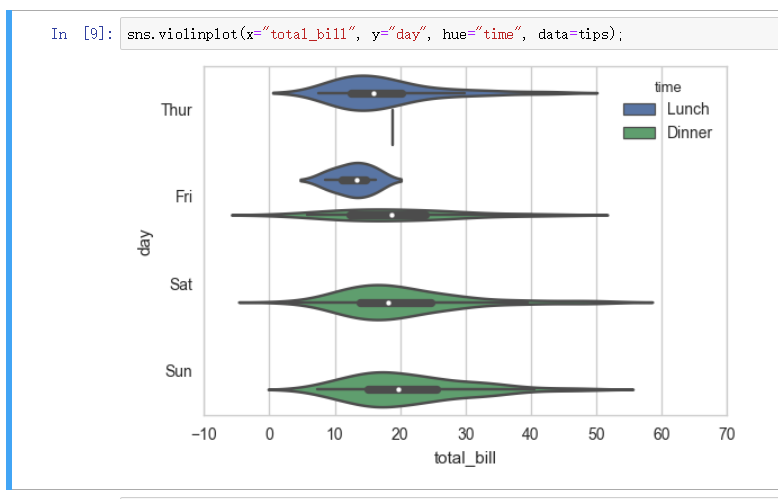
多变量体现的时候小提琴图默认是区分的, 如上图的吃晚餐和吃午餐的在周一到周五之间的关系上就是分为两色分别展示
如果想更直观的展示一天中 午餐顾客数量和晚餐顾客数量的对比. 则可以加入 split 参数, 如下图的 每天吃饭男女的关系
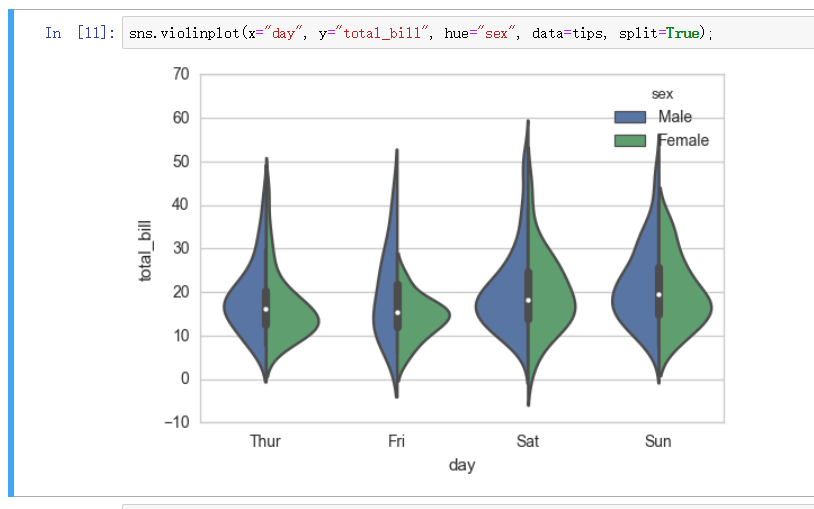
组合图
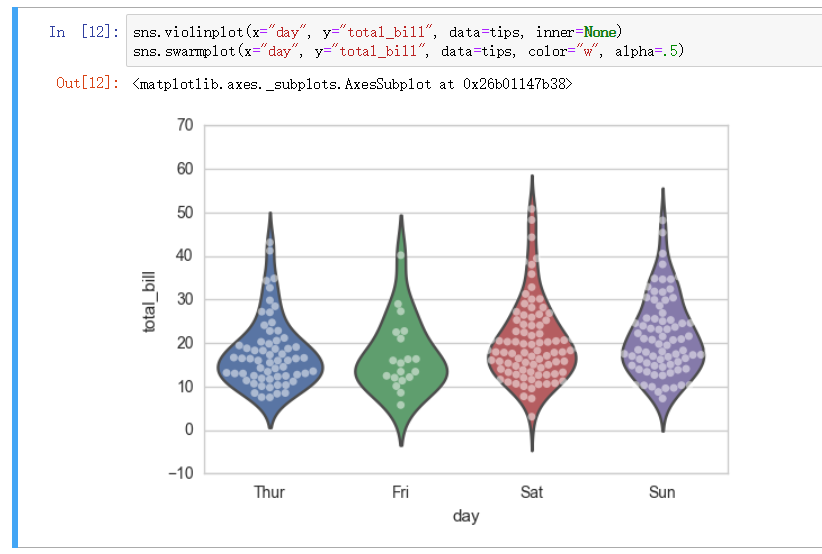
图之间是可以组合的. 比如如下的小提琴图和分簇散点图的组合, 小提琴设置 inner=None 表示去除中间的显示
alpha 则设置透明度
条形图 - barplot
下图展示的是泰坦尼克号中不同性别. 不同船舱等级情况下的获救几率

多变量分析
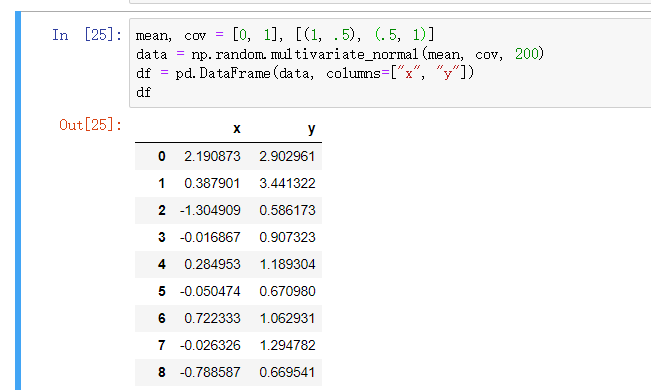
数据范式准备
根据均值和协方差生成数据
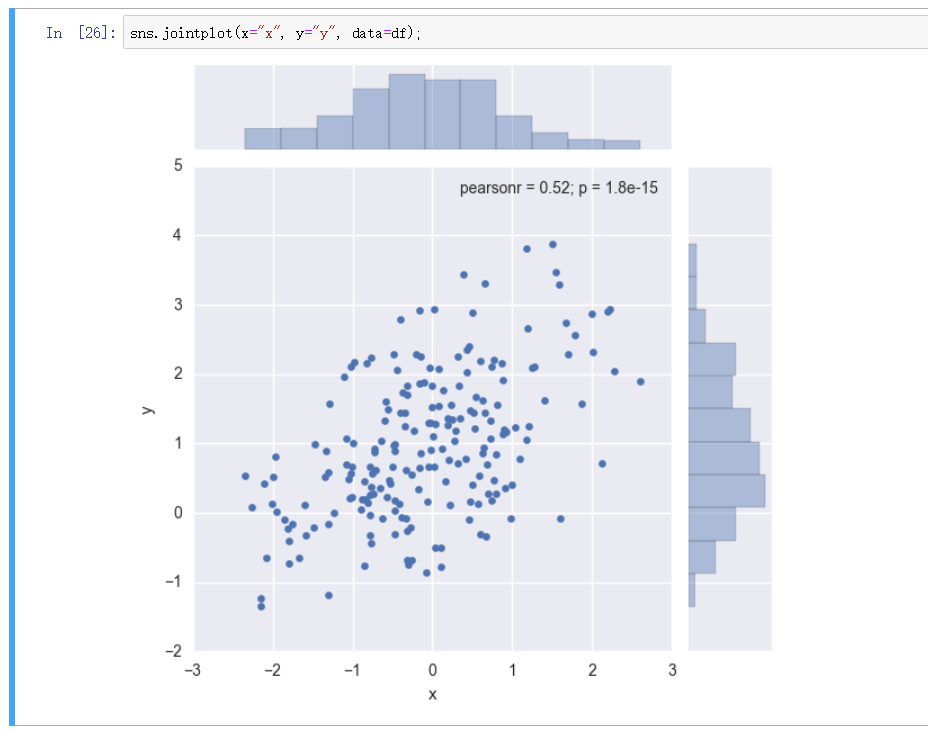
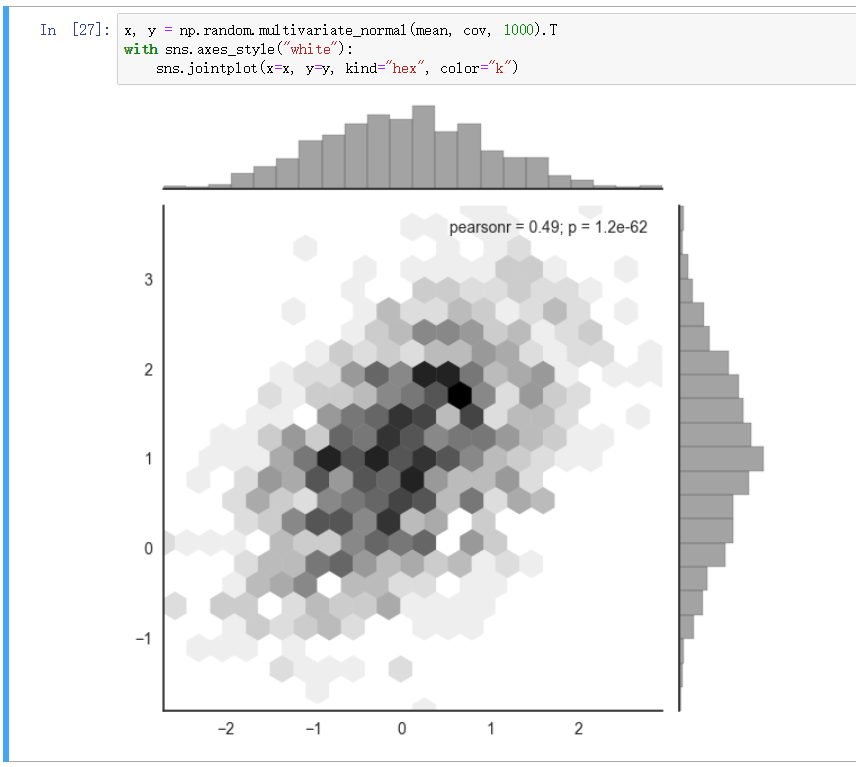
综合散点图 - jointplot
观测两个变量之间的分布关系最好用散点图 ,利用 jointplot 建立散点图且自动创建配合直方图
重叠处理 - 蜂巢图
散点图在大量数据的时候点会堆叠导致无法观察, 因此可使用 hex 图这样对重复数据点会有深浅变化
在 jointplot 中指定可选参数 kind 为 hex 即可
读取数据集 - load_dataset
读取数据集 load_dataset 函数,示例使用内置的鸢尾花数据集, (有4个特征的数据集)
矩阵散点图 - pairplot
在使用 pairplot 函数读取即可所有特质之间的 两两对应关系
因此不再需要手动执行循环建立子图较为繁琐的方式去处理
由下图可见, 4个特征的两两对应关系, 对角线表示是相同特征的对比, 因此单特征展现为直方图, 其他为散点图

回归分析
数据范式准备
内置的 tips 数据样本, 顾客的一系列特征与愿意出多少小费的关联

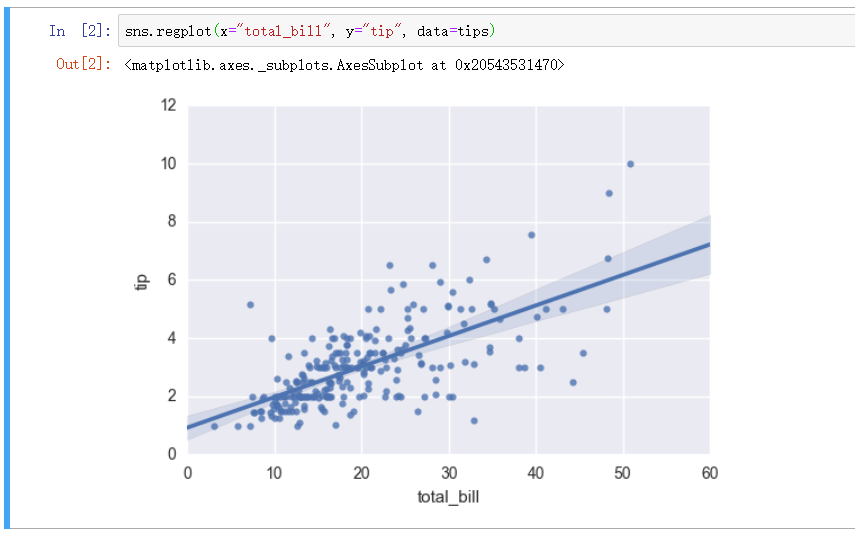
回归图 - regplot
regplot() 和l mplot() 都可以绘制回归关系,推荐 regplot()
传入参数必选 x,y,data ,分别表示 x 轴, y 轴, 以及样本数据
绘制出的图形可以大体战术出 全部小费金额和小费之间的线性关系以及数据分布的散点展示
加入数据抖动 - x_jitter
一些不太适合做线性回归的数据可以加入抖动进行更好的适配

拟合以及其他操作参考 这里
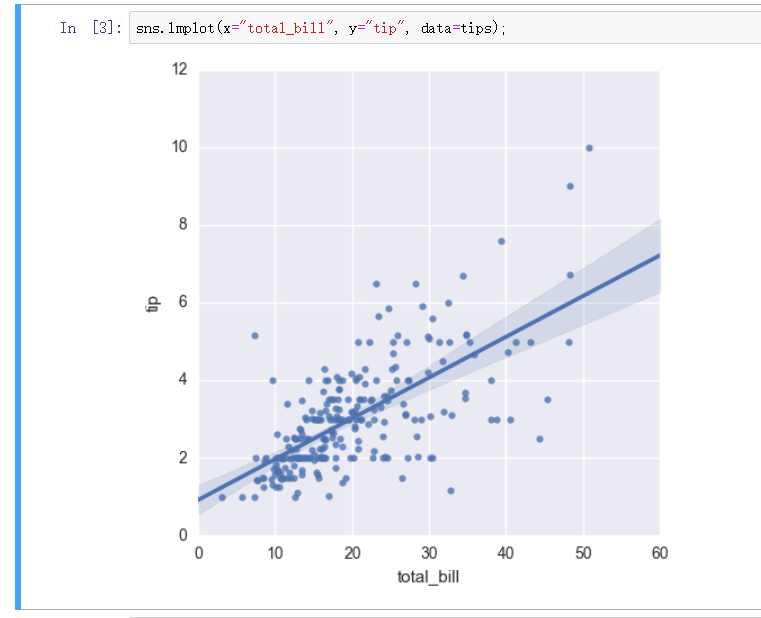
回归图 - mplot
mplot 绘制的图和 regplot 大体差不多, 但是可供支持的参数更多, 可以实现更多复杂的指标操作
FacetGrid 使用
基本工作流程是FacetGrid使用数据集和用于构造网格的变量初始化对象。然后,可以通过调用 FacetGrid.map() 或将一个或多个绘图函数应用于每个子集 FacetGrid.map_dataframe() 最后,可以使用其他方法调整绘图,以执行更改轴标签,使用不同刻度或添加图例等操作
内部属性
class seaborn.FacetGrid(
data, row=None, col=None, hue=None, col_wrap=None, sharex=True,
sharey=True, height=3, aspect=1, palette=None, row_order=None,
col_order=None, hue_order=None, hue_kws=None, dropna=True,
legend_out=True, despine=True, margin_titles=False,
xlim=None, ylim=None, subplot_kws=None, gridspec_kws=None, size=None)
data : DataFrame
处理后的(“长格式”)dataframe数据,其中每一列都是一个变量(特征),每一行都是一个样本
row, col, hue : strings
定义数据子集的变量,这些变量将在网格的不同方面绘制。请参阅下面 *_order 参数以控制该变量的级别顺序
例如: col="sex", hue="smoker" ,即列表示性别,颜色语意表示是否吸烟,下面示例会给出详细说明
col_wrap : int, optional
这个意思是图网格列维度限制,比如 col_wrap =3 ,那么在这个画布里最多只能画3列。行不限制,这样就限制了列的个数。
share{x,y} : bool, ‘col’, or ‘row’ optional
是否共享x轴或者y轴,就是说如果为真,就共享同一个轴,否则就不共享,默认是都共享,即都为 True
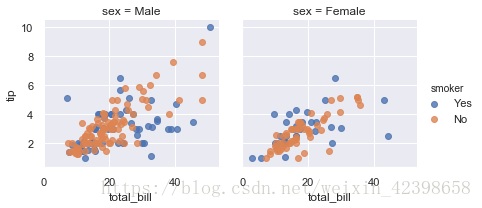
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=True)# 都共享
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=False)# 关闭共享y轴, 关闭后会每个表独立画一个 y 轴
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
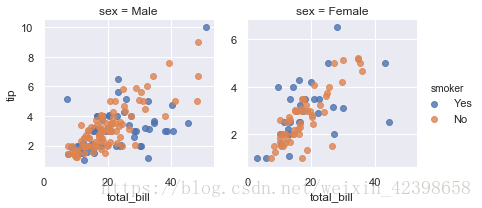
height : scalar, optional
每个图片的高度设定,默认为3
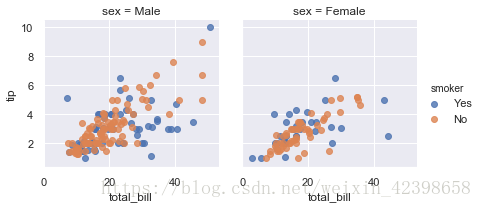
aspect : scalar, optional
文档说是纵横比,是说每个小图的横轴长度和纵轴的比
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=True, aspect=1) # 默认为1,即等高等宽
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=True, aspect=0.5) # 改为0.5
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();

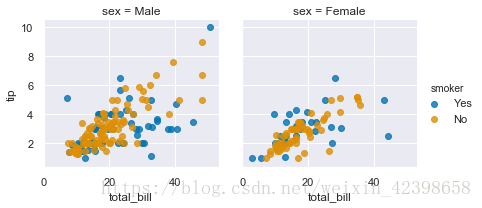
palette : palette name, list, or dict, optional
这个简单,一般在使用hue时来改变颜色的,有这几种系统给的可选 deep, muted, bright, pastel, dark, colorblind
举个例子还是上图的啊,不给代码了,直接上图了,此时我给的是 palette='colorblind'
{row,col,hue}_order : lists, optional
对所给命令的级别进行排序。默认情况下,这将是数据中显示的级别,如果变量是 pandas 分类,则是类别顺序。
g = sns.FacetGrid(tips, col="sex", hue="smoker",sharex=True, sharey=True,col_order=['老大', '老二', '老三', '老四'])
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
调换一下位置看看:
就不全上传代码了,关键代码给出:
col_order=['老大', '老二', '老三', '老四']
到这里大家就可以看出来了,这个命令是可以让我们设置画图的顺序的

hue_kws : dictionary of param -> list of values mapping
其他关键字参数插入到绘图调用中,让其他绘图属性在色相变量的级别上有所不同(例如散点图中的标记)
>>> pal = dict(Lunch="seagreen", Dinner="gray") # 先定义一个字典,把颜色确定
>>> g = sns.FacetGrid(tips, col="sex", hue="time", palette=pal,# 然后传递给palette
... hue_order=["Dinner", "Lunch"])#hue_order这个官方解释的好,优先Dinner
>>> g = (g.map(plt.scatter, "total_bill", "tip", **kws)
... .add_legend())
>>> g = sns.FacetGrid(tips, col="sex", hue="time", palette=pal,hue_order=["Dinner", "Lunch"],
hue_kws=dict(marker=["^", "v"])) # 给颜色语意使用不同的标签,这样可以进行一部分区别
>>> g = (g.map(plt.scatter, "total_bill", "tip", **kws).add_legend())
总结来说,hue_kwss就是增加能快速辨识的方法,在变量很多时很有用,我把hue_order=["Dinner", "Lunch"]换一下位置看看,确实是有顺序的
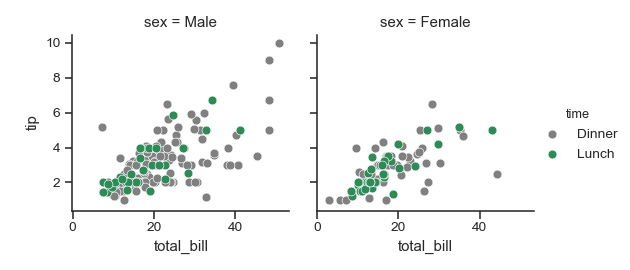
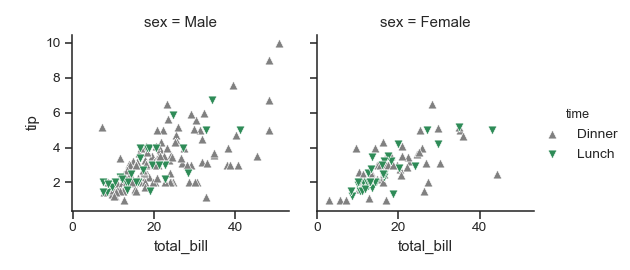
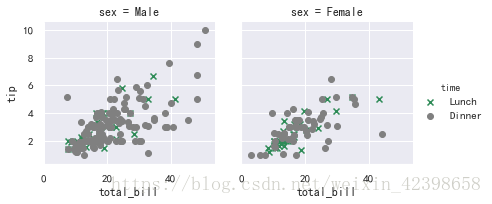
legend_out : bool, optional
默认为True,legend是图例的意思,如果True,图形尺寸将被扩展,并且图例将被绘制在中心右侧的图形之外,上面的图都是这样的,为假时,图例单独放出来,下面是为假的情况,看下下面的图例和上面的区别

despine : boolean, optional
从图中移除顶部和右侧脊柱,就是边缘框架
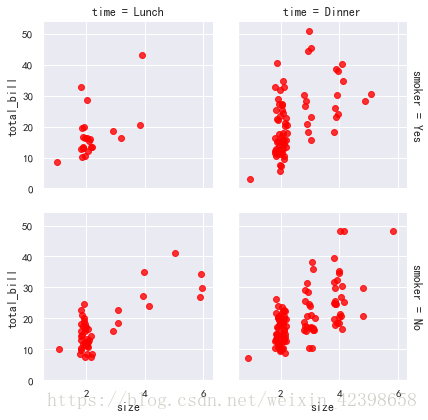
margin_titles : bool, optional
如果是真的,那么行变量的标题就会被绘制到最后一列的右边。这个选项是实验性的,在所有情况下都可能不起作用。
直接看图吧:
g = sns.FacetGrid(tips, row="smoker", col="time",
margin_titles=False) # margin_titles为假的时候
g.map(sns.regplot, "size", "total_bill", color="red",
fit_reg=False, x_jitter=.2);
再给出margin_titles=True的图,代码和上面一样,可以看出来了,行变量的标题就会被绘制到最后一列的右边

{x, y}lim: tuples, optional
每个方面的每个轴的限制(只有当共享x时才相关,y是正确的
subplot_kws : dict, optional
传递给matplotlib的subplot(s) 方法的关键字参数字典Dictionary of keyword arguments passed to matplotlib subplot(s) methods.这个需要看看subplot函数的参数,后面有时间补上
gridspec_kws : dict, optional
传递给matplotlib的gridspec模块的关键字参数的字典(Via plt.subplots)。matplotlib >= 1.4,如果colwrap不是None,则会被忽略。也许查看相关函数,改天再补上
这个两个参数是为了和matplotlib传参是使用的
内部方法
__init__(data [,row,col,hue,col_wrap,...]) |
初始化matplotlib图和FacetGrid对象。 |
add_legend([legend_data,title,label_order]) |
绘制一个图例,可能将其放在轴外并调整图形大小。 |
despine(** kwargs) |
从小平面上移除轴刺。 |
facet_axis(row_i,col_j) |
使这些索引识别的轴处于活动状态并返回。 |
facet_data() |
生成器用于每个方面的名称索引和数据子集。 |
map(func,* args,** kwargs) |
将绘图功能应用于每个方面的数据子集。 |
map_dataframe(func,* args,** kwargs) |
喜欢.map但是将args作为字符串传递并在kwargs中插入数据。 |
savefig(* args,** kwargs) |
保存图。 |
set(** kwargs) |
在每个子图集Axes上设置属性。 |
set_axis_labels([x_var,y_var]) |
在网格的左列和底行设置轴标签。 |
set_titles([template,row_template,...]) |
在每个构面上方或网格边距上绘制标题。 |
set_xlabels([label]) |
在网格的底行标记x轴。 |
set_xticklabels([labels, step]) |
在网格的底行设置x轴刻度标签。 |
set_ylabels([label]) |
在网格的左列标记y轴。 |
set_yticklabels([labels]) |
在网格的左列上设置y轴刻度标签。 |
示例
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
tips.head()
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4 tips['day'].unique()
# 从数据中可以看出sex、smoker、time均为两个状态值
[Sun, Sat, Thur, Fri]
Categories (4, object): [Sun, Sat, Thur, Fri] g = sns.FacetGrid(tips, col="time")
# 像这样初始化网格会设置matplotlib图形和轴,但不会在它们上绘制任何内容。

# 在该网格上可视化数据的主要方法是使用该FacetGrid.map()方法。
# 为其提供绘图功能以及要绘制的数据框中的变量名称。让我们使用直方图来
# 查看每个子集中tip的分布。
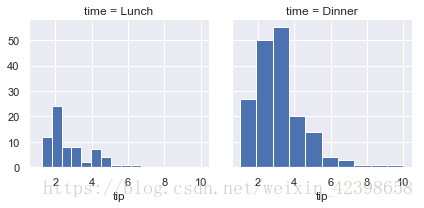
g = sns.FacetGrid(tips, col="time")
g.map(plt.hist, "tip");
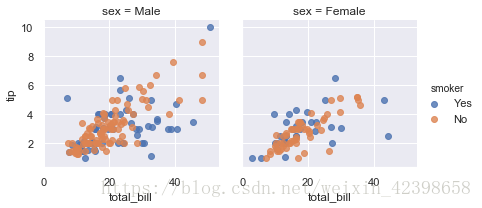
g = sns.FacetGrid(tips, col="sex", hue="smoker",col_wrap=2)
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
# 此功能将绘制图形并注释轴,希望一步生成完成的绘图。要创建关系图,
# 只需传递多个变量名称。您还可以提供关键字参数,这些参数将传递给
# 绘图函数,看看col_wrap的功能
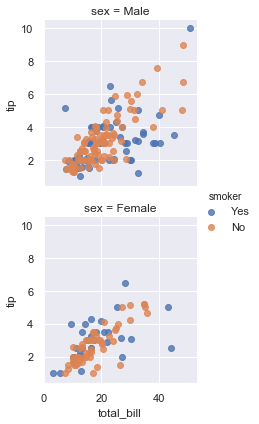
g = sns.FacetGrid(tips, col="sex", hue="smoker",col_wrap=1)
g.map(plt.scatter, "total_bill", "tip", alpha=0.8)
g.add_legend();
# 此时col_wrap=1 ,说明col_wrap是限制网格中图的列的个数的
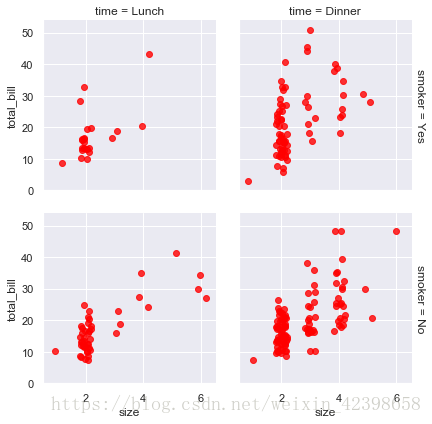
# 可以单独传递类构造函数改变网格外观
g = sns.FacetGrid(tips, row="smoker", col="time",
margin_titles=True)
g.map(sns.regplot, "size", "total_bill", color="red",
fit_reg=False, x_jitter=.2);
# margin_titles=True的作用是把标题写到侧面,
# fit_reg=False关闭回归,我们下面看看关闭效果
g = sns.FacetGrid(tips, row="smoker", col="time",
margin_titles=False)
g.map(sns.regplot, "size", "total_bill", color="red",
fit_reg=True, x_jitter=.2);
# 关闭margin_titles=False,打开fit_reg=True
# margin_titles打开的好处是可以让人很轻松的看明白图的差别

# margin_titlesmatplotlib API未正式支持,并且在所有情况下都可能
# 无法正常工作。特别是,它目前不能与位于绘图之外的图例一起使用。 # 通过 height、aspect提供每个面的高度以及纵横比来设置图形的大小
g = sns.FacetGrid(tips, col="day", height=4, aspect=.5)
g.map(sns.barplot, "sex", "total_bill");
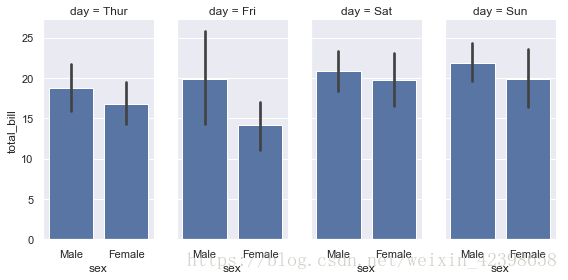
# facet的默认排序源自DataFrame中的信息。如果用于定义构面的变量具有
# 分类类型,则使用类别的顺序。否则,facet将按照类别级别的出现顺序排列。
# 但是,可以使用适当的*_order参数指定任何构面尺寸的顺序
ordered_days = tips.day.value_counts().index
g = sns.FacetGrid(tips, row="day", row_order=ordered_days,
height=1.7, aspect=4,)
g.map(sns.distplot, "total_bill", hist=False, rug=True);

绘制成对数据关系
PairGrid还允许您使用相同的绘图类型快速绘制小子图的网格,以可视化每个
子图中的数据。在一个PairGrid中,每个行和列都分配给不同的变量,因此结果
图显示数据集中的每个成对关系。这种情节有时被称为“散点图矩阵”,因为这是
显示每种关系的最常用方式,但PairGrid不限于散点图。
理解a FacetGrid和a 之间的差异很重要PairGrid。在前者中,
每个方面都表现出以不同级别的其他变量为条件的相同关系。在后者中,
每个图显示不同的关系(尽管上三角和下三角将具有镜像图)。使用
PairGrid可以为您提供数据集中有趣关系的非常快速,非常高级的摘要。
该类的基本用法非常相似FacetGrid。首先初始化网格,然后将绘图函数
传递给map方法,并在每个子图上调用它。还有一个伴侣功能,pairplot()
它可以为更快的绘图提供一些灵活性
iris = sns.load_dataset("iris")
# 该数据大家应该很熟悉了,就不看数据了
g = sns.PairGrid(iris)
g.map(plt.scatter);
# 可以在对角线上绘制不同的函数,以显示每列中变量的单变量分布。
# 但请注意,轴刻度不会与该图的计数轴或密度轴对应。
g = sns.PairGrid(iris)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);

# 使用此图的一种非常常见的方法是通过单独的分类变量对观察结果进行着色。
# 例如,iris数据集对三种不同种类的鸢尾花中的每一种都有四种测量值,
# 因此您可以看到它们之间的差异。
g = sns.PairGrid(iris, hue="species")
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter)
g.add_legend();
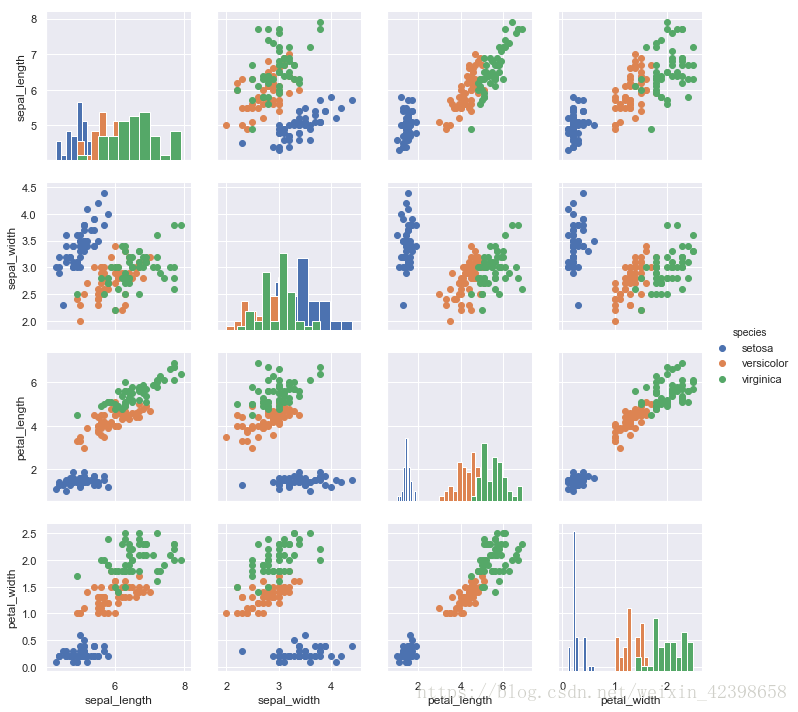
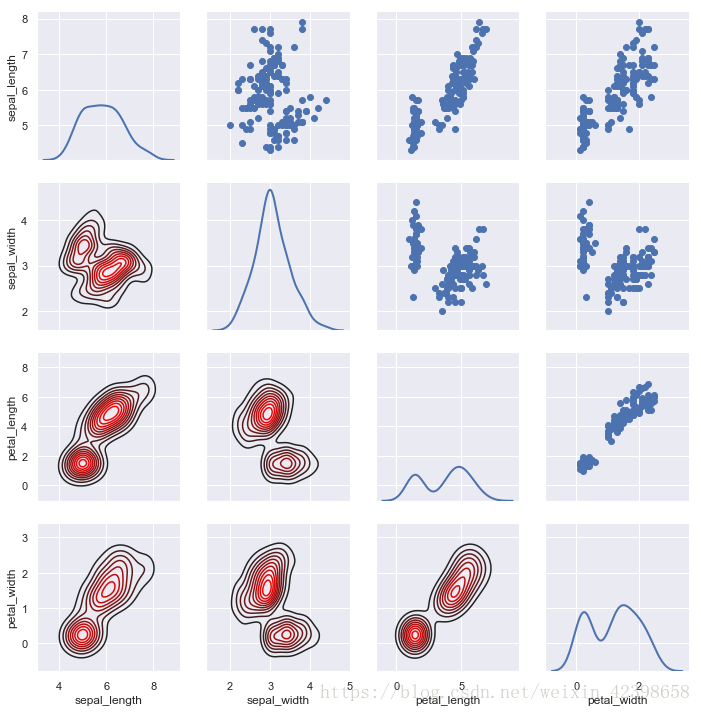
# 也可以在上三角和下三角中使用不同的函数来强调关系的不同方面。
g = sns.PairGrid(iris)
g.map_upper(plt.scatter)
g.map_lower(sns.kdeplot,color='red')
g.map_diag(sns.kdeplot, lw=2, legend=False);
# PairGrid很灵活,但要快速查看数据集,使用pairplot()可以更容易。
# 此功能默认使用散点图和直方图,但会添加一些其他类型
# (目前,您还可以绘制对角线上的回归图和对角线上的KDE)。
sns.pairplot(iris, hue="species", height=2.5);

heatmap - 热度图
图形变化用颜色趋势表现出来的形式 - 热度图
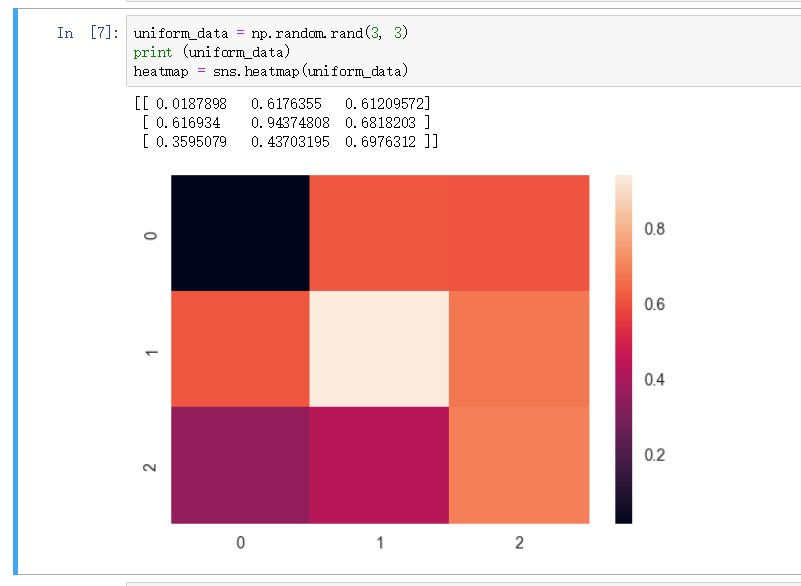
指定取值区间 - vim/vmax
未指定的时候自动会根据数据集中的最大最小值作为两极

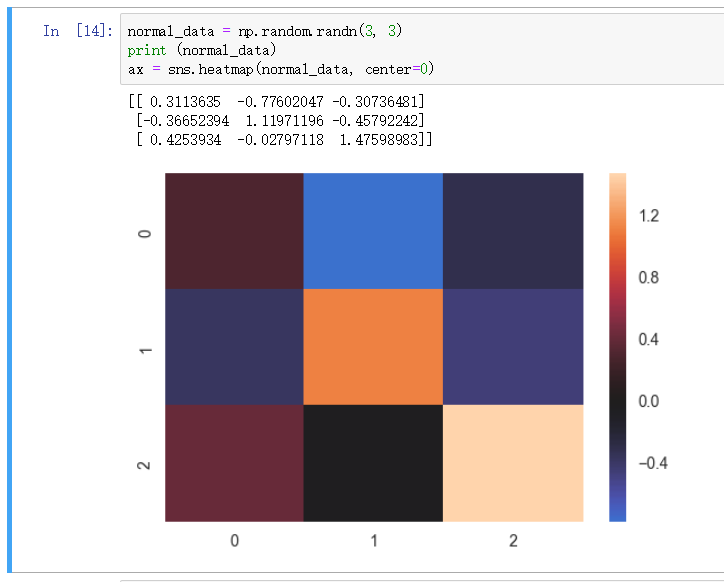
指定中心数据 - center
指定一个中心数据, 其上或者其下颜色差异都很大,
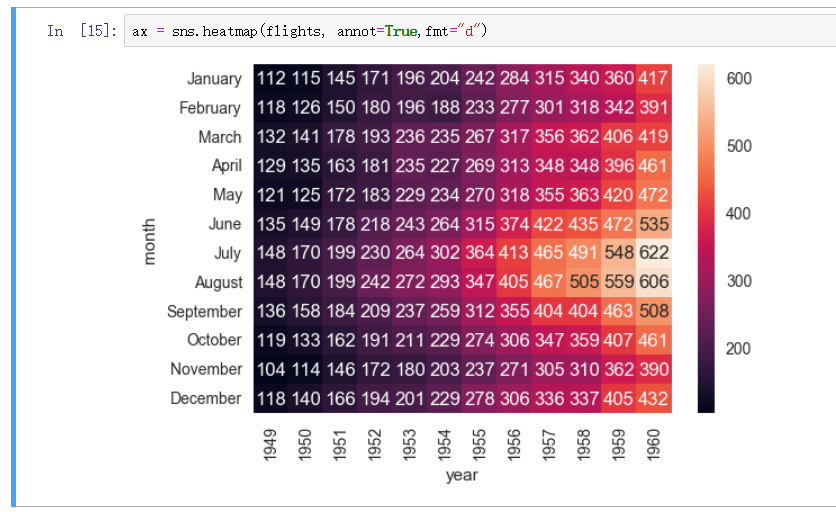
航班示例
利用函数 pivot 对数据集进行预处理, 然后转换为热量图

显示数字 - annot, fmt
设置 annot=True 表示显示数字, 设置 fmt="d" 指定格式, 这里指定 "d" 是比较好的选择, 默认不指定则会显示乱码较为难以观察 (默认科学计数法)
指定色格间距 - linewidths
默认的色格之间都是都没有间距的, 指定此属性后可设置间距, 加间距看着更舒服点

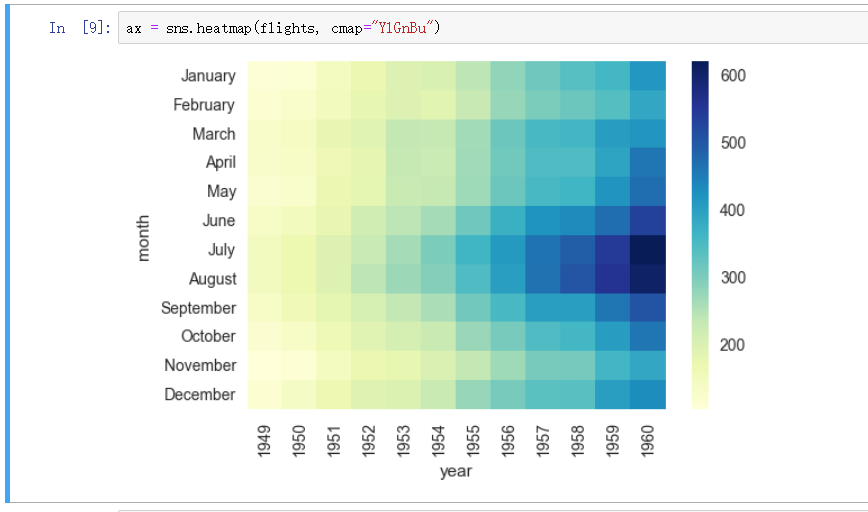
指定调色板 - cmap
调色板的选择也可以指定
隐藏色盘指标 - cbar
设置 cbar=False 则可以隐藏, 但是不方便观察, 不知道指标区间了, 酌情使用

数据分析 - seaborn 模块的更多相关文章
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- Python数据分析-Day2-Pandas模块
1.pandas简介 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标 ...
- seaborn模块的基本使用
Seaborn是基于matplotlib的Python可视化库. 它提供了一个高级界面来绘制有吸引力的统计图形.Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图 ...
- 数据分析 - matpltlib 模块
matplotlib 模块 引入模块 import matplotlib.pyplot as plt 设置图片大小 - figure 展示图片 - show 画图 - 实例化后指定类型画图 plot ...
- 数据分析 - numpy 模块
numpy 概述 ▨ Numerical Python. 补充了python所欠缺的数值计算能力 ▨ Numpy是其他数据分析及机器学习库的底层库 ▨ Numpy完全标准C语言实现,运行效率充分 ...
- 大数据分析——sklearn模块安装
前提条件:numpy.scipy以及matplotlib库的安装 (注:所有操作都在pycharm命令终端进行) ①numpy安装 pip install numpy ②scipy安装 pip ins ...
- Python数据分析-Day1-Numpy模块
1.numpy.genfromtxt读取txt文件 import numpyworld_alcohol = numpy.genfromtxt("world_alcohol.txt" ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
随机推荐
- linux程序对比
- 【异常】ERROR main:com.cloudera.enterprise.dbutil.SqlFileRunner: Exception while executing ddl scripts. com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'ROLES' already exists
1 详细异常 2019-10-11 10:33:55,865 INFO main:com.cloudera.server.cmf.Main: ============================= ...
- Matlab修改数值格式/精度/小数位数
————————————命令行方法————————————— 直接在命令行中输入以下命令,但该命令不影响数据的存储形式和计算精度,下次还需进行修改. format 默认格式 format short ...
- 鼠标点击自定义文字展现特效JS代码
JS特效使用方法 只需将如下JS代码放到</body>之前就好了 var a_idx = 0; jQuery(document).ready(function($) { $("b ...
- 复习一下js的prototype 属性
<html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</t ...
- web+下载文件夹
文件下载的实质就是文件拷贝,将文件从服务器端拷贝到浏览器端,所以文件下载需要IO技术将服务器端的文件读取到,然后写到response缓冲区中,然后再下载到个人客户端. "> <m ...
- [Sdwc] 线段
线段有如下两类特点:1 x y, 表示第 x 条线段和第 y 条线段相交 (相交在这里指至少有一个公共点)2 x y,表示第 x 条线段在第 y 条线段的左边,且它们不相交.共有 m 个特点,每个特点 ...
- DataTable转List,DataTable转为Model对象帮助类
DataTable转List,DataTable转为Model对象帮助类 public class ModelConvertHelper<T> where T : new() { publ ...
- K - Kia's Calculation(贪心)
Kia's Calculation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others ...
- CF1204C
CF1204C-Anna, Svyatoslav and Maps 题意: 题目传送门 不想说了,阅读题. 解法: 先用floyd跑出各顶点间的最短路.把p(1)加入答案,然后沿着题目给的路径序列遍历 ...