Oracle 与 postgreSQL 事务处理区别(多版本与undo区别)
2015年左右,因为工作需要用MongoDB、CouchBase这两种文档型数据库,时不时到这两个数据库官网上查资料、报BUG。时常可以在MongoDB官网上看到这样一些新闻,“某某企业成功将MySQL替换成MongoDB,性能大幅提升”,“某某公司将Oracle替换成MongoDB,节约成本若干”……
而在CouchBase官网上,又会时不时看到这样的新闻:“A公司将MongoDB替换成CouchBase,性能提升显著”、“B公司将MongoDB替换为CouchBase,性能大大提升。”……
这样的广告词往往让数据架构人员无所事从,看到了上面的新闻,如果你是数据架构人员,你要如何选择数据库呢?
是用关系型的MySQL/Oracle,还是“更好”的MongoDB,还是“更更好”的CouchBase?或者,还有“更更更好”数据库可供选择,要不要尝个鲜?
我相信放在官网中的新闻,一定不会弄虚做假。但隐藏了很多关键信息后,这样的新闻就略有点不负责了。
要知道2015年时,MongoDB才刚刚支持一个Document内的事务。简单点说,还不支持跨行事务。如果你轻信了这样的新闻,贸然将需要跨行的、复杂事务的应用,建立在了MongoDB之上,你可以去准备你的简历了。
CouchBase也一样,它是CouchDB和Memcached的组合。CouchDB是文档型数据库,Memcached作为存储引擎,合起来就是CouchBase。其实相当于把数据放在Memcached中的MongoDB。
它之所以比MongoDB更快,是因为它的数据都是在内存中。如果MongoDB的内存也很大,所有数据也都缓存在内存中,谁更快还不好说。
而且,一旦CouchBase数据量超过主机内存,发生真正的物理I/O,其性能下降是十分明显的,往往要慢于MongoDB。
不明白这些数据库的内在本质,贸然的选择某个数据库。个人准备简历这只是小事,对企业造成的损坏将难以估量。之前我写过一篇《Digg启示录》,为大家总结美国知识分享类网站Digg,为追求横向扩展,而盲目的替换底层数据库,导致问题重重,应用频繁出错,网页时常打不开,致使公司在重要的发展窗口期痛失契机,最后50万美元被收购的下场(高峰时期,Digg曾估值5亿美元)。
如果你面对繁多的数据库,有点眼花撩乱,没关系有美创专业的数据库团队在,美创可以为您的数据提供从架构选型、到运维、到安全……等全方位的服务。
广告就到这里,今天为大家继续梳理数据架构选型中的坑,这一期我们讨论OLTP的“事务”。
很多人对这个词已经陌生,NoSQL大行其道之后,事务好像已经是可有可无的东西了。实际上不然,NoSQL的领头羊MongoDB一直在默默的发展事务功能,到4.0以上版本(现在最新版是4.3),已经基本上实现传统关系型数据库的事务功能了。
事务对OLAP型应用来说的确是可有可无,但对OLTP来说,绝对是必须的。
事务的概念是从哪里来的呢?这可以一直追溯到上世纪70年代,关系型数据库刚刚诞生的时期。
1970前后,已经功成名就的数据库圈大佬——E.F.Codd,有感于层次、网状数据库的不便,提出了创世级的关系模型,从此开启了关系数据库时代。
(E.F.Cood,关系型数据库之父,图灵奖得主)
但是在整个70年代,关系型的发展都不是太好,E.F.Codd老爷子忙于推广他的关系模型。无暇他顾。
这时候比E.F.Codd小20岁的数据库新秀:James Gray(昵称Jim)登场了。
(青年时期的Jim)
Jim是IBM SYSTEM R的开发人员。SYSTEM R是IBM的关系型数据库的尝试。Jim在开发SYSTEM R时,不断在思考一个问题:
“如何能多、快、好、省的保证数据库的一致性”。
Jim老爷子想出来的大招就是:
把数据库中相关的操作看作一个统一的原子操作,这些相关的操作要么都成功、要么都失败。这就是事务了,事务的概念,就从这里诞生了。
只要保证每个事务都是一致的,数据库就是一致的。
这样,问题“保证数据库的一致性”,就变为“保证事务一致性”。
你看,问题的范围大大缩小了。这就是顶级架构师的思维。
说到如何“多、快、好、省”的保证事务一致性?
这个问题并不简单,数据库的操作是多重并发的,事务是互相重叠且相关的,在一段时间内,我可能更新了你要查询的行,你要删除他正在更新的行……在这种互相交织在一起的情况是十分普遍的。
Jim老爷子后来研究了一辈子事务这东西,终于在1994年获得了图灵奖。图灵奖可以计算机界的诺贝尔奖,而有关数据库的图灵奖,一共有4次。其中,就有一次就是和事务相关的,足以说明事务很复杂、很重要。
(James Gray的演讲)
Jim老爷子后来把他的研究成果还写成了一本书,叫《事务处理:概念与技术》。如果你想开发一个能保证事务一致性的数据库,建议你读一读。
简要说一下老爷子的思想,当时已经有了两阶段提交协议,但它是针对分布式的,因此比较松散,用它来实现事务的原子性太慢了。
Jim另辟捷径,提出了一个DO-UNDO-REDO协议,来张老爷子的书《事务处理:概念与技术》中的图说明一下吧:
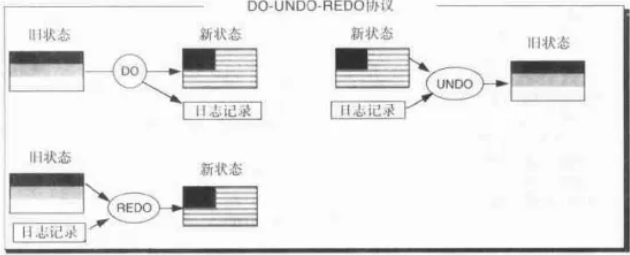
搞过Oracle、DB2、SQLServer的人一看这图,一定就能心领神会。
我摘录一下书中对此图的解释:
DO,就是操作,比如一些UPDATE、INSERT或DELETE的SQL。它让数据库从旧的状态变为新的状态。它同时会产生日志。
UNDO,利用日志,将新状态变回旧的状态。
REDO,利用日志,从旧状态转移到新状态。
这个图其实和DB2、SQLServer中的事务机制完全一样,他们的UNDO日志和REDO日志就是合在一起的。比如:在SQLServer中就叫事务日志,回滚、恢复都靠事务日志。
之所以DB2、SQLServer中的事务机制,和Jim老爷子书中的图一模一样,因为这两个数据库都和Jim老爷子有直接的联系:
DB2可以说是脱胎于IBM的关系型数据库尝试产品:SYSTEM R。Jim老爷子当年是SYSTEM R的主力开发。
SQLServer更不必说,Jim老爷不想离开生活惯了的洛杉矶去西雅图,Bill.Gets专门在洛杉矶建了一个研究院,由老爷子做院长,领导开发了SQLSever数据库。
额外说一下,我曾看到过一个问题:程序员为什么爱发博客。最高票的回答是:因为解决了一个牛B的问题,身边却没有人懂。
在上世纪70年代,还没有博客这玩意,邮件组还要再过几年才流行。Jim在SYSTEM R中解决了一系列复杂的事务、一致性等问题,但是,无人能欣赏,这种寂寞高手的感觉,高处不胜寒。
怎么办,Jim一边开发着SYSTEM R,思考着复杂的事务问题,一边抽空写博客,对了,当时还没有博客,那就写论文吧。1976年时,Jim写了篇重要的论文:《共享数据库的一致性和锁的粒度(Granularity of Locks and Degrees of Consistency in a Shared Data Base)》。就是在这篇论文中,Jim首次提出了“事务”和一致性的概念。
老爷子论文写的不亦乐乎,没想到旁边有个“偷拳”的家伙——埃里森。小埃当时已经看了E.F.Codd在IBM时的论文,搞了个关系型数据库Oracle。IBM是当时当之无愧的大哥,跟着大哥走还会有错?
小埃偷拳偷的不亦乐乎的时候,Jim又发表了他的关于事务的论文,所以,如你所见,Oracle中的事务也是DO-UNDO-REDO协议了。
只不过,Oracle把UNDO和REDO分开了,UNDO有专门的UNDO段。这后来又影响了MySQL、国产的达梦数据库,他们的UNDO都是分离的,UNDO在UNDO段中。
虽然UNDO和REDO合在一起,才是正宗Jim老爷的思想。但分离式的设计也不差,很难说谁比谁更强。
从事务的角度上来说,Oracle、DB2、SQLServer、达梦,这些数据库事务的设计各有千秋。
从成熟度上来说,当然是Oracle、DB2的成熟度更高、性能更好,但SQLServer、达梦数据库也不错,性能上、功能上,也完全可以满足我们的需要。
但数据库的江湖上,除了DO-UNDO-REDO派之外,还有另外一大流派。因为使用了完全不同的事务实现协议,有些操作的性能表现和DO-UNDO-REDO派有着明显的差异。
这另外一大派,是由另一图灵奖得主、开宗立派的宗师级大师,迈克尔.斯通布雷克(Michael Stonebraker)开创的多版本派。
(图灵奖,颁奖仪式上的Michael Stonebraker)
在数据库界风起云涌的70年代,Michael按耐不住寂寞,出手搞了一个关系型的数据库:Ingres。Ingres衍生出很多数据库,PostgreSQL就是其中之一。
Michael老爷子认可Jim的事务概念,但对于如何实现事务,他采用了和Jim不一样的方法,他没有完全采用DO-UNDO-REDO协议,REDO仍然是需要的。Redo中的后映像是为了恢复。UNDO呢,它是前映像数据,为了把数据恢复修改之前。
把数据恢复到修改之前,或者提供前映像读,未必就一定需要UNDO日志(或UNDO 段)。也可以使用多版本的机制。
下面以Update为例,比较一下多版本派和UNDO派在事务流程中的不同,从中总结一下这两种流派的优、缺点。
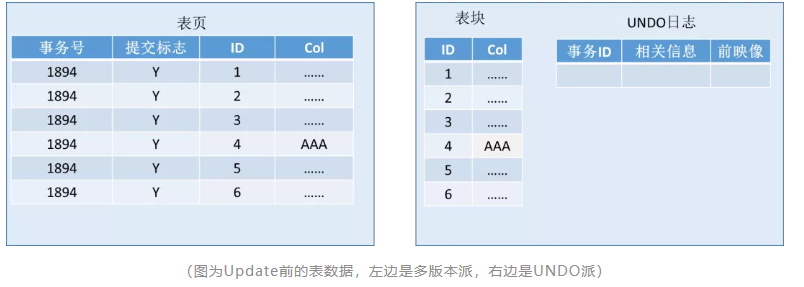
(图为Update前的表数据,左边是多版本派,右边是UNDO派)
对于多版本派的表来说,每一行数据都会增加些版本信息,事务号、提交标志就是这些版本信息的一部分。有些多版本派的数据库,会用一个事务开始的时间戳代表事务号,而不是用特定的一个数字。这在NoSQL/NewSQL数据库中很常见。
对于UNDO派的数据库来说呢,会有一个UNDO日志。Oracle/MySQL是有一个专门的UNDO段。DB2/SQLServer的UNDO和REDO都是放一起的。
下面,用户发出了更新操作,数据库收到了一条Update命令:
Update test set col=’BBB’ where id=4
数据库在执行这条SQL时,相关事务和表数据的处理流程如下:
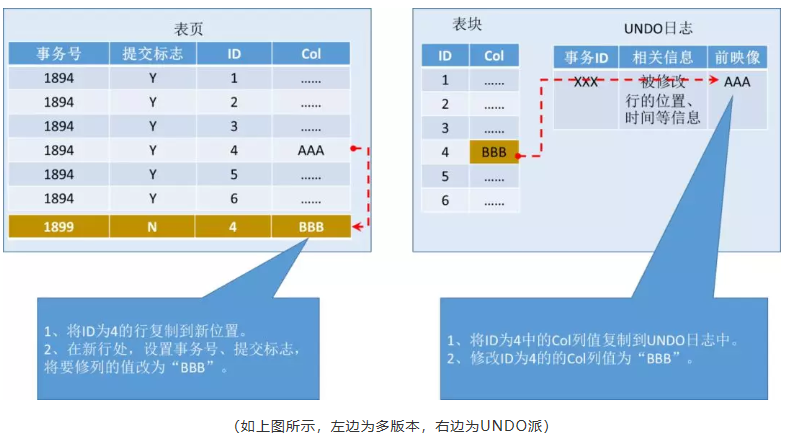
(如上图所示,左边为多版本,右边为UNDO派)
多版本派,会首先将ID为4的行复制到新位置,然后设置新行的事务号为1899,提交标志为N,代表事务未提交,再修改要Update的列值为“BBB”。如果其他Session查询到ID为4的行,直接根据提交标记,即可判断出此事务未提交,那么,就再向前查寻ID值为4、事务号最大的、提交标记为是的行,就是满足一致性要求的行了。
UNDO派则先将前映像写入UNDO区域,再在原行中修改要修改的列。这一派系我就不详细介绍了,相信读者对这一派系了解会更多。
通过对比,我想读者朋友就发现了,如果表有十列,那怕只更新一列,多版本派也要将整行复制到新位置处。而UNDO派呢,只需要将被修改列的原值复制到UNDO日志中即可。这么一比,在Update操作方面,UNDO派是有优势的。
当然,作为图灵奖得主,Michael老爷开创的多版本派肯定是有自己特长的。
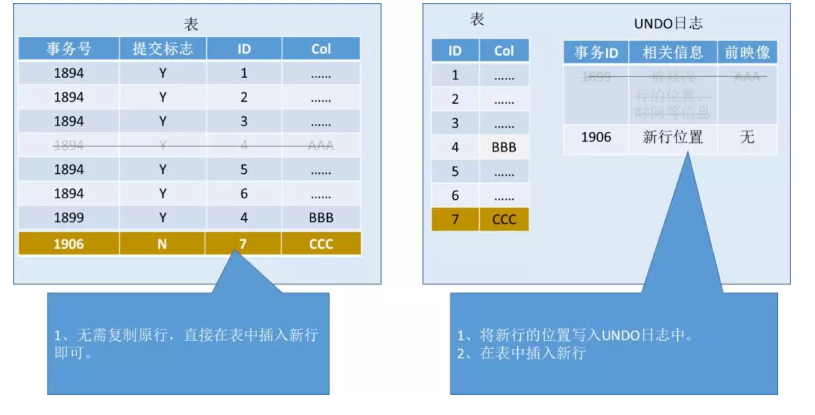
各位多版本派的粉丝,先放下40米大刀,不要急,下面我们来比一下插入操作:
多版本派的Insert操作十分简单,直接在表中插入新行即可。
相对来说,UNDO派的Insert,就略为复杂了。要将新行的位置信息写入UNDO日志,将来回滚的时候,好根据这个位置找到新行在哪儿。
虽然UNDO派只复杂了那么一点点,但对于追求短、平、快的OLTP应用来说,一次SQL调用可能也就几毫秒、十几毫秒。额外的操作UNDO,已经是不小的操作了。
看到了吧,Michael老爷子的多版本派成功扳回一局。
对于删除操作,我就不再放图了。UNDO派,要把原行整行数据复制到UNDO日志中去。多版本派对于删除操作的处理多有不同。最基本、最简单的,就是删除时也把整行复制到新位置,加上删除标志。
这符合多版本派的一贯思想,就是不修改原行,每DML一次,只复制、修改新行。
很多NoSQL数据库就是这样做的,但成熟的关系型、多版本派数据库,如PostgreSQL,并不会这样简单粗爆。它是在原行处设置一些事务标志,在删除行的时候,只需标记行被删除就可以了,避免了将被删除行复制到新位置。具体细节,我们就不再这里展开讨论了。总之PostgreSQL的删除和插入一样,都是十分节省资源的。
UNDO派脱胎于闭源的、商业的SYSTEM R,因此它广范应用于关系的、闭源的、商业的数据库。这个我们前面提到了,如Oracle、DB2、达梦,还有开源的MySQL。
多版本派,源于Ingres,这个数据库是开源的,而且,多版派的实现也相对更为简单,不需维护一块专门的UNDO空间。因此多版本派也广泛应用于开源的、或NoSQL/NewSQL等非关系型的数据库。
虽然在关系型中,有名的好像也只有PostgreSQL。但是几乎所有支持事务的NoSQL/NewSQL数据库,都属于多版本派。
好了,现在我们可以总结一下了。这两大派的数据库谁更适用哪种场景呢?
简单总结一下
暗黑料理界又出新品!
◎ 多版本派的Insert/Delete不需要复制原行数据,因此简单而快速,但Update负担会重,特别是针对列较多但每次Update只更新少量列的情况。
(注:多版本派的Delete不需要复制原行数据,只是针对PostgreSQL,多数多版本派的NoSQL/NewSQL,Delete时还是要复制原行数据到新位置的。)
◎ UNDO派,它的优势在于平衡,无论什么DML,都少不了操作UNDO的步骤,性能表现都差不多。
结合应用来说,比如你有一个日志型的OLTP应用。每秒有大量的并发Session,向数据库中插入大量数据(这和OLAP中少量Session插入大量数据还不样,OLAP的我们以后再说),但这些数据从不Update,或者说很少Update。那么,多版本派的数据库就十分适合了,比如PostgreSQL。
如果对事务的要求没那么高,那么一些NoSQL/NewSQL的数据库也可以考虑。比如,事务不多的事情下,可以考虑MongoDB。因为完全的支持ACID的、跨多个表(MongoDB中叫集合)的事务,MongoDB也是刚支持不久,以成熟度来论,相比PostgreSQL会差一些。
如果不需要跨表、跨行的事务,甚至不需要事务,选择面就更多了,像HBase、Cassandra等的插入性能都是不错的。
如果有一个OLTP交易型的应用,有大量的查询,和A转帐给B这样的交易操作,也就是Update A的余额、再Update B的余额。UNDO派的数据库就比较适合了。毕竟,Update操作时UNDO派更节省资源。
但是,有时候应用的界限并不是那么清楚。比如一套大型的应用中,即有日志型的功能,又有交易型的功能,而且数据还是混在一起的。这种情况下,总不能将数据写两份,分别放在不同数据库中吧(极端情况下,也可以这样做)。
这要如何选择呢?就要看那种功能更重要了。日志型功能更重要,就选多版本派的数据库。交易型功能更重要,就选UNDO派数据库。如果都重要,我建议优选UNDO派的、成熟的数据库。因为UNDO派各种操作性能更加平衡,不会出现忽快忽慢的情况。
要说,不同宗派之间,还容易选择。但是同一宗派内部呢?
同一宗派内部,我们也不好在公开场合说谁优谁劣,TPCC的性能测试数据,每家都十分优秀。
大家使用的基本思想是一样的,好坏取决于开发者的编程能力,能去开发数据库的,都是像下面这样的好程序员:
( 见过我的人都说,我也是一名标准的好程序员:) )
所以,同一宗派内部,在不考虑钱的情况下,选择成熟度高的数据库。要考虑钱的情况下,国产的数据库,和开源数据库的确是一个不错的选择。现在国产数据库、和像MySQL/PostgreSQL这样的历史悠久的开源数据库,成熟度也已经十分好了。
除去事务的影响,不同的数据存储、组织模式、锁级别等,都会带来一些性能差别。比如:Oracle的表是堆表,堆表是无序的。MySQL InnoDB的表是索引组织表,索引组织表是要按索引排序的。排序操作会额外带来一些性能损耗,但会提升按主键查询时的性能,等等。这些非事务性的,我们后面再总结。
好了,篇幅已经不短了,这一期,我们只说事务。后续,留待下一期吧。
话说UNDO派、多版派,就像少林、武当两大派一样,统领江湖几十载,江湖上一片风平浪静。各个应用厂商按需选择,一时江湖上倒也相安无事。
进入二十一世纪一零年代,UNDO派开山宗师Jim某一日正在洞府中打坐修行,忽然一阵心旗摇动,Jim掐指一算,自知大限将至,遂扬帆出海,小舟从此逝、江海寄余生。
(注:2007年年初,Jim架游艇出海,将老母亲骨灰撒入大海,然后失踪。海岸警卫队、志愿者、学术界朋友纷纷加入搜索,甚至动用卫星和若干先进技术,搜索几天后仍一无所获。但很多人仍没有放弃搜索,直到五年又四个月后(2012年5月16),才宣布他的死亡。)
多版本派开山宗师Michael,也年寿已高,不问江湖世事。江湖中两位大佬一死一老,对江湖的控制力大大减弱。正在这时,一本叫做NoSQL的武功秘籍,在江湖上又掀起血雨腥风。
至于NoSQL重出江湖之后,数据库界又有什么样的风云变幻,且听下回分解。
转载自:https://mp.weixin.qq.com/s/6RiVgNp6T-2CnfBy8rpHvA
Oracle 与 postgreSQL 事务处理区别(多版本与undo区别)的更多相关文章
- CentOS以及Oracle数据库发展历史及各版本新功能介绍, 便于构造环境时有个对应关系
CentOS版本历史 版本 CentOS版本号有两个部分,一个主要版本和一个次要版本,主要和次要版本号分别对应于RHEL的主要版本与更新包,CentOS采取从RHEL的源代码包来构建.例如CentOS ...
- MySQL&SQL server&Oracle&Access&PostgreSQL数据库sql注入详解
判断数据库的类型 当我们通过一些测试,发现存在SQL注入之后,首先要做的就是判断数据库的类型. 常用的数据库有MySQL.Access.SQLServer.Oracle.PostgreSQL.虽然绝大 ...
- Sql获取表所有列名字段——select * 替换写法,Sqlserver、Oracle、PostgreSQL、Mysql
实际开发中经常用到select * from table,往往需要知道具体的字段,这个时候再去数据库中翻或者查看数据字典比较麻烦.为了方便,自己特意写了一个小函数f_selectall,针对SqlSe ...
- Ubuntu桌面版本和服务器版本之间的区别(转载)
转载自:http://blog.csdn.net/fangaoxin/article/details/6335992 http://www.linuxidc.com/Linux/2010-11/297 ...
- oracle VS postgresql系列-行列转换
[需求]例如先有数据为 id | name ------+--------- | lottu | xuan | rax | ak | vincent 现在需要转换为 id | names ------ ...
- Mcafee两个Mac版本之间的区别
近期打算为Mac安装个杀毒软件,由于自己windows平台下用的是VSE,所以Mac平台也首选Mcafee家的东西了.到Mcafee官网下载点一看,有以下几个版本可以用在Mac上: 有点懵了,查看了一 ...
- 在oracle中where 子句和having子句中的区别
在oracle中where 子句和having子句中的区别 1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用 ...
- 微软提供的API的各个版本之间的区别
First Floor Software这个diff lists非常方便的给出了微软提供的API的各个版本之间的区别,比如下表是.NET 4和.NET 4.5的API变化总结.我们可以看到.NET 4 ...
- 【Oracle】ORACLE SQL Developer不支持JAVA版本
ORACLE SQL Developer不支持JAVA版本 今天我打开 ORACLE SQL Developer准备开始练手.没有想到却给出了错误提示. 我 是安装了java JDK的而且是1.6版本 ...
随机推荐
- WUSTOJ 1332: Prime Factors(Java)
题目链接:1332: Prime Factors Description I'll give you a number , please tell me how many different prim ...
- Shiro简介、入门案例、web容器的集成
目的: shiro简介 Shiro入门案例 Shiro与web容器的集成 shiro简介(中文官网:https://www.w3cschool.cn/shiro/andc1if0.html) 1.什么 ...
- 启动 docker 容器时报错
错误信息: iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 9300 -j DNAT --to-dest ...
- flutter从入门到精通五
在flutter的世界里,一切都是Widget,图像,文本,布局模型等等,一切都是Widget flutter中,尽量将Widget放在MaterialApp.其封装了所需要的一些Widget,Mat ...
- html启动本地.exe文件
之前没有了解这个内容,还是一个小伙伴在面试中遇到的一个题目,感觉挺有意思就研究了一下这个东西到底是怎么用的.搜了一下解决方法,是添加注册表,自己运行了可以使用 第一步:首先打开注册表,方法是 win+ ...
- IIS发布问题解决
一. HTTP Error 502.5 - ANCM Out-Of-Process Startup Failure ://安装AspNetCoreModule托管模块后执行1. net stop wa ...
- google mock C++单元测试框架
转:google mock C++单元测试框架 2012-03-12 09:33:59 http://blog.chinaunix.net/uid-25748718-id-3129590.html G ...
- git一些简单运用
1.删除本地文件后,继续从远处仓库拉取回来,提示up-to-date,执行如下 git reset --hard origin/master 待补充
- 关于文本设置overflow:hidden后引起的垂直对齐问题
目前有这样的需求,一行标题中,前面为图标,后面是文字,文字要实现一行省略的效果 首先把文字设为:display: inline-block; 然后设置省略: overflow: hidden; wor ...
- TypeScript算法与数据结构-栈篇
本文的源码在这里,可以参考一下 栈也是一种使用非常广泛的线性数据结构,它具有后进先出last in first out的特点.通俗的例子就像我们平时一本一本的往上放书,等到我们又想用书时,我们首先接触 ...