Hadoop学习(6)-HBASE的安装和命令行操作和java操作
使用HABSE之前,要先安装一个zookeeper
我以前写的有https://www.cnblogs.com/wpbing/p/11309761.html
先简单介绍一下HBASE
HBASE是一个数据库----可以提供数据的实时随机读写
他是一个nosql数据库,并不是结构化的,他只能粗略的进行一些查询,像多表之间的连接查询他是很难做到的(至少我这辣鸡不会)。
我也是第一次接触这种nosql,人家的表结构不太一样,就是啥吧,
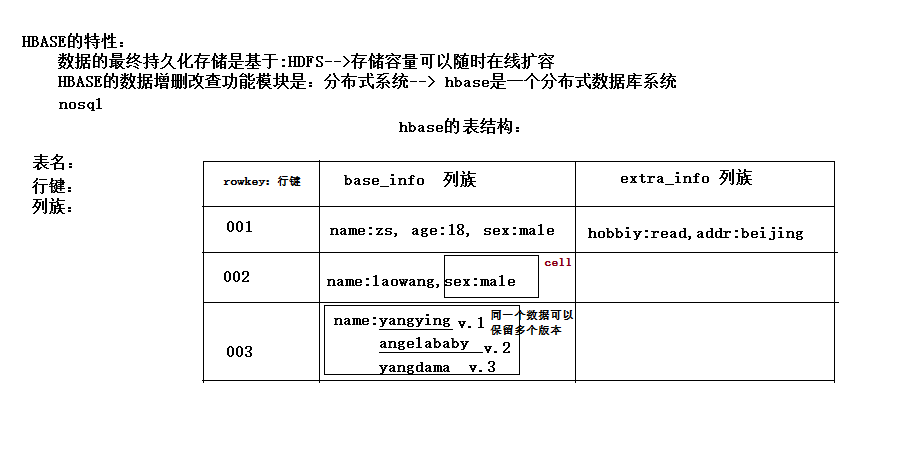
他有一个行健(类似于主键的东西)
然后剩下的就是你可以定义有几个列族
每个列族里面,
列族里面都是一个一个的key,value值。一对kv,称作一个cell。
每一个value又可以有多个值,并不是一个
l Hbase的表模型与关系型数据库的表模型不同:
l Hbase的表没有固定的字段定义;
l Hbase的表中每行存储的都是一些key-value对
l Hbase的表中有列族的划分,用户可以指定将哪些kv插入哪个列族
l Hbase的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中
l Hbase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复
l Hbase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,hbase不负责为用户维护数据类型
l HBASE对事务的支持很差
Hbase的表数据存储在HDFS文件系统中
HBASE是一个分布式系统
其中有一个管理角色: HMaster(一般2台,一台active,一台backup)
其他的数据节点角色: HRegionServer(很多台,看数据容量)
master用来配置数据储存和任务的分配,
regionserver管理着每一张表的区域数据
Regionserver管理着每一个的文件的范围,Zookeeper用来检测regionserver是否挂掉,master用来控制任务的分发。就是当regionserver挂掉了,如何找人接替他的任务。
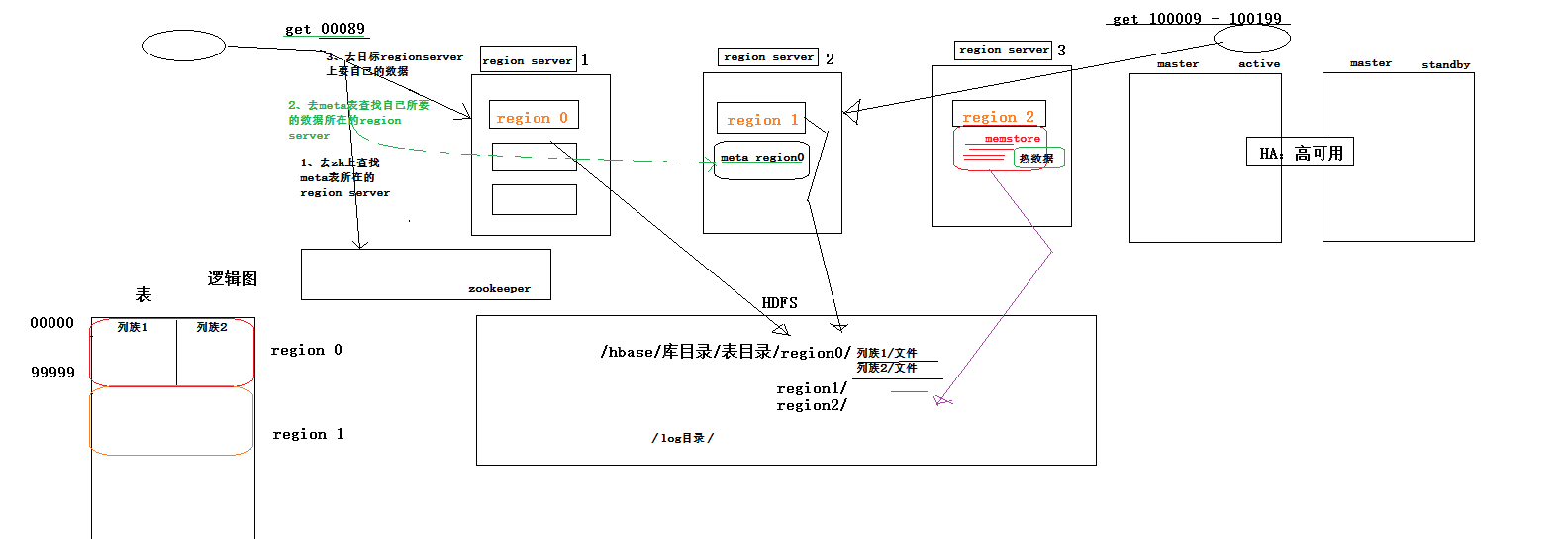
HBASE的大体工作机制是这样婶的
客户端怎么知道数据在哪台服务器,他会先查找那个索引表,hbase:meta表
那这个表在哪呢,

在zookeeper里面可以看到这个索引表的信息
这个东西是放到zookeeper里面,先看zookeeper的meta、变所在的regionserver,然后去访问它知道他的信息在哪
然后使用HBASE的话你要先有自己的Hadoop集群,保证hdfs是正常的,还有zookeeper是正常的,就这两点。
安装还是很简单的
解压hbase安装包
修改hbase-env.sh
|
export JAVA_HOME=/root/apps/jdk1.7.0_67 export HBASE_MANAGES_ZK=false |
修改hbase-site.xml
|
<configuration> <!-- 指定hbase在HDFS上存储的路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://hdp-01:9000/hbase</value> </property> <!-- 指定hbase是分布式的 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zk的地址,多个用“,”分割 --> <property> <name>hbase.zookeeper.quorum</name> <value>hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181</value> </property> </configuration> |
修改 regionservers
|
hdp-01 hdp-02 hdp-03 hdp-04 |
bin/start-hbase.sh
启动完后,还可以在集群中找任意一台机器启动一个备用的master
bin/hbase-daemon.sh start master
新启的这个master会处于backup状态
如果报错了,在这看错误,注意时间错误、
HBASE的对外端口是16010
同时也可以启动一个备用的master,在启动之后,随便在一台机器上,
Bin/hbase-daemon.sh start master
同时也可以试着访问这个页面

这hbase的系统表记录的是数据的索引表,记录哪个范围的数据储存在哪个regionserver
3. 启动hbase的命令行客户端
bin/hbase shell
Hbase> list // 查看表
Hbase> status // 查看集群状态
Hbase> version // 查看集群版本
1.1. HBASE表模型
hbase的表模型跟mysql之类的关系型数据库的表模型差别巨大
hbase的表模型中有:行的概念;但没有字段的概念
行中存的都是key-value对,每行中的key-value对中的key可以是各种各样,每行中的key-value对的数量也可以是各种各样
1.1.1. hbase表模型的要点:
1、一个表,有表名
2、一个表可以分为多个列族(不同列族的数据会存储在不同文件中)
3、表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
4、表中的每一对kv数据称作一个cell
5、hbase可以对数据存储多个历史版本(历史版本数量可配置)
6、整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region的数据也存储在不同文件中
7、hbase会对插入的数据按顺序存储:
要点一:首先会按行键排序
要点二:同一行里面的kv会按列族排序,再按k排序
1.1. hbase命令行客户端操作
1.1.1.1. 建表:
create 't_user_info','base_info','extra_info'
表名 列族名 列族名
1.1.1.2. 插入数据:
|
hbase(main):011:0> put 't_user_info','001','base_info:username','zhangsan' 0 row(s) in 0.2420 seconds hbase(main):012:0> put 't_user_info','001','base_info:age','18' 0 row(s) in 0.0140 seconds hbase(main):013:0> put 't_user_info','001','base_info:sex','female' 0 row(s) in 0.0070 seconds hbase(main):014:0> put 't_user_info','001','extra_info:career','it' 0 row(s) in 0.0090 seconds hbase(main):015:0> put 't_user_info','002','extra_info:career','actoress' 0 row(s) in 0.0090 seconds hbase(main):016:0> put 't_user_info','002','base_info:username','liuyifei' 0 row(s) in 0.0060 seconds |
1.1.1.3. 查询数据方式一:scan 扫描
|
hbase(main):017:0> scan 't_user_info' ROW COLUMN+CELL 001 column=base_info:age, timestamp=1496567924507, value=18 001 column=base_info:sex, timestamp=1496567934669, value=female 001 column=base_info:username, timestamp=1496567889554, value=zhangsan 001 column=extra_info:career, timestamp=1496567963992, value=it 002 column=base_info:username, timestamp=1496568034187, value=liuyifei 002 column=extra_info:career, timestamp=1496568008631, value=actoress 2 row(s) in 0.0420 seconds |
1.1.1.4. 查询数据方式二:get 单行数据
|
hbase(main):020:0> get 't_user_info','001' COLUMN CELL base_info:age timestamp=1496568160192, value=19 base_info:sex timestamp=1496567934669, value=female base_info:username timestamp=1496567889554, value=zhangsan extra_info:career timestamp=1496567963992, value=it 4 row(s) in 0.0770 seconds |
1.1.1.5. 删除一个kv数据
|
hbase(main):021:0> delete 't_user_info','001','base_info:sex' 0 row(s) in 0.0390 seconds |
删除整行数据:
|
hbase(main):024:0> deleteall 't_user_info','001' 0 row(s) in 0.0090 seconds hbase(main):025:0> get 't_user_info','001' COLUMN CELL 0 row(s) in 0.0110 seconds |
1.1.1.6. 删除整个表:
|
hbase(main):028:0> disable 't_user_info' 0 row(s) in 2.3640 seconds hbase(main):029:0> drop 't_user_info' 0 row(s) in 1.2950 seconds hbase(main):030:0> list TABLE 0 row(s) in 0.0130 seconds => [] |
1.1. Hbase重要特性--排序特性(行键)
插入到hbase中去的数据,hbase会自动排序存储:
排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序
Hbase的这个特性跟查询效率有极大的关系
比如:一张用来存储用户信息的表,有名字,户籍,年龄,职业....等信息
然后,在业务系统中经常需要:
查询某个省的所有用户
经常需要查询某个省的指定姓的所有用户
思路:如果能将相同省的用户在hbase的存储文件中连续存储,并且能将相同省中相同姓的用户连续存储,那么,上述两个查询需求的效率就会提高!!!
做法:将查询条件拼到rowkey内
当我们创建一个表之后,按道理说应该是可以在hdfs里面查看到数据的。但是。。。。
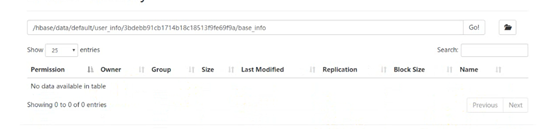
这里面没有数据,却能查到,那么数据到底存在哪呢,这些数据会存在内存中,这块内存空间叫做memstore,因为这样会快一点,他会把热数据放到这里面,就是刚刚访问过的数据,他会先放到内存中,但如果这时候宕机了怎么办,数据会丢吗,不会丢,他一方面会写数据,一方面会写日志,放在hdfs的日志目录里
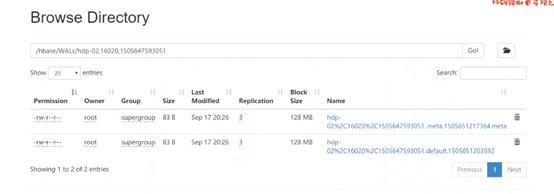
当内存中写满了,就会写到hdfs里
可以试一下,当你停一下,你就会发现hdfs里面就有数据了
布隆过滤器的功能:判断一个数据以前是否出现过
布隆过滤器的原理:把一个数据通过算法转化成只有01的二进制数据,
然后用一个比较大的数组来存,每一个数据的01都存到这个数组里面,注意他们是相互叠加的比如一个数据1位置有1,3位置有1,另一个数据1位置有1,4位置有1,那么加入后就是1位置有1,3位置有1,4位置有1,如果再来一个数据的01,1位置有1,5位置有1,那么可以判断,这个数据是从来没有出现过的,
所以布隆过滤器一个可以判断出没有出现过的数据,
而他判断出出现过的数据却有可能是没出现过的。
他在HBASE的应用啊,比如说,region Server管理的一个表的列族,他的真实存放位置是hdfs,在hdfs的某个目录下。而且他这个列族文件不止一个,比如,当这个列族的数据改变的时候,他会生成一个新的文件,因为他没发修改hdfs里的文件,或者就算不改,列族里有许许多多的key,value,他们也会放在这个目录下的不同文件里面
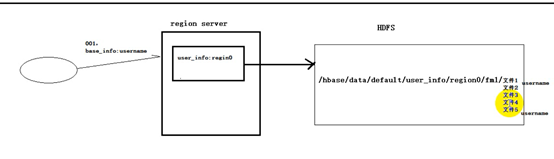
每个文件都有个布隆过滤器,它是由这个文件kv的二进制值决定,当你要查询一个数据的话,他会先那这个数据的二进制值和某个文件的布隆过滤器比一下,如果匹配了,他就会找这个文件
关于java的一些api
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.regionserver.BloomType;
import org.junit.Before;
import org.junit.Test; /**
*
* 1、构建连接
* 2、从连接中取到一个表DDL操作工具admin
* 3、admin.createTable(表描述对象);
* 4、admin.disableTable(表名);
5、admin.deleteTable(表名);
6、admin.modifyTable(表名,表描述对象);
*
* @author hunter.d
*
*/
public class HbaseClientDDL {
Connection conn = null; @Before
public void getConn() throws Exception{
// 构建一个连接对象
Configuration conf = HBaseConfiguration.create(); // 会自动加载hbase-site.xml
conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181,hdp-04:2181"); conn = ConnectionFactory.createConnection(conf);
} /**
* DDL
* @throws Exception
*/
@Test
public void testCreateTable() throws Exception{ // 从连接中构造一个DDL操作器
Admin admin = conn.getAdmin(); // 创建一个表定义描述对象
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("user_info")); // 创建列族定义描述对象
HColumnDescriptor hColumnDescriptor_1 = new HColumnDescriptor("base_info");
hColumnDescriptor_1.setMaxVersions(3); // 设置该列族中存储数据的最大版本数,默认是1 HColumnDescriptor hColumnDescriptor_2 = new HColumnDescriptor("extra_info"); // 将列族定义信息对象放入表定义对象中
hTableDescriptor.addFamily(hColumnDescriptor_1);
hTableDescriptor.addFamily(hColumnDescriptor_2); // 用ddl操作器对象:admin 来建表
admin.createTable(hTableDescriptor); // 关闭连接
admin.close();
conn.close(); } /**
* 删除表
* @throws Exception
*/
@Test
public void testDropTable() throws Exception{ Admin admin = conn.getAdmin(); // 停用表
admin.disableTable(TableName.valueOf("user_info"));
// 删除表
admin.deleteTable(TableName.valueOf("user_info")); admin.close();
conn.close();
} // 修改表定义--添加一个列族
@Test
public void testAlterTable() throws Exception{ Admin admin = conn.getAdmin(); // 取出旧的表定义信息
HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info")); // 新构造一个列族定义
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info");
hColumnDescriptor.setBloomFilterType(BloomType.ROWCOL); // 设置该列族的布隆过滤器类型 // 将列族定义添加到表定义对象中
tableDescriptor.addFamily(hColumnDescriptor); // 将修改过的表定义交给admin去提交
admin.modifyTable(TableName.valueOf("user_info"), tableDescriptor); admin.close();
conn.close(); } /**
* DML -- 数据的增删改查
*/ }
import java.util.ArrayList;
import java.util.Iterator; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellScanner;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test; public class HbaseClientDML {
Connection conn = null; @Before
public void getConn() throws Exception{
// 构建一个连接对象
Configuration conf = HBaseConfiguration.create(); // 会自动加载hbase-site.xml
conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181"); conn = ConnectionFactory.createConnection(conf);
} /**
* 增
* 改:put来覆盖
* @throws Exception
*/
@Test
public void testPut() throws Exception{ // 获取一个操作指定表的table对象,进行DML操作
Table table = conn.getTable(TableName.valueOf("user_info")); // 构造要插入的数据为一个Put类型(一个put对象只能对应一个rowkey)的对象
Put put = new Put(Bytes.toBytes("001"));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("张三"));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("18"));
put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); Put put2 = new Put(Bytes.toBytes("002"));
put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("李四"));
put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("28"));
put2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("上海")); ArrayList<Put> puts = new ArrayList<>();
puts.add(put);
puts.add(put2); // 插进去
table.put(puts); table.close();
conn.close(); } /**
* 循环插入大量数据
* @throws Exception
*/
@Test
public void testManyPuts() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info"));
ArrayList<Put> puts = new ArrayList<>(); for(int i=0;i<100000;i++){
Put put = new Put(Bytes.toBytes(""+i));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("张三"+i));
put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes((18+i)+""));
put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); puts.add(put);
} table.put(puts); } /**
* 删
* @throws Exception
*/
@Test
public void testDelete() throws Exception{
Table table = conn.getTable(TableName.valueOf("user_info")); // 构造一个对象封装要删除的数据信息
Delete delete1 = new Delete(Bytes.toBytes("001")); Delete delete2 = new Delete(Bytes.toBytes("002"));
delete2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr")); ArrayList<Delete> dels = new ArrayList<>();
dels.add(delete1);
dels.add(delete2); table.delete(dels); table.close();
conn.close();
} /**
* 查
* @throws Exception
*/
@Test
public void testGet() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); Get get = new Get("001".getBytes()); Result result = table.get(get); // 从结果中取用户指定的某个key的value
byte[] value = result.getValue("base_info".getBytes(), "age".getBytes());
System.out.println(new String(value)); System.out.println("-------------------------"); // 遍历整行结果中的所有kv单元格
CellScanner cellScanner = result.cellScanner();
while(cellScanner.advance()){
Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所属的行键的字节数组
byte[] familyArray = cell.getFamilyArray(); //列族名的字节数组
byte[] qualifierArray = cell.getQualifierArray(); //列名的字节数据
byte[] valueArray = cell.getValueArray(); // value的字节数组 System.out.println("行键: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength()));
System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength()));
System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength())); } table.close();
conn.close(); } /**
* 按行键范围查询数据
* @throws Exception
*/
@Test
public void testScan() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // 包含起始行键,不包含结束行键,但是如果真的想查询出末尾的那个行键,那么,可以在末尾行键上拼接一个不可见的字节(\000)
Scan scan = new Scan("10".getBytes(), "10000\001".getBytes()); ResultScanner scanner = table.getScanner(scan); Iterator<Result> iterator = scanner.iterator(); while(iterator.hasNext()){ Result result = iterator.next();
// 遍历整行结果中的所有kv单元格
CellScanner cellScanner = result.cellScanner();
while(cellScanner.advance()){
Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所属的行键的字节数组
byte[] familyArray = cell.getFamilyArray(); //列族名的字节数组
byte[] qualifierArray = cell.getQualifierArray(); //列名的字节数据
byte[] valueArray = cell.getValueArray(); // value的字节数组 System.out.println("行键: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength()));
System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength()));
System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength()));
System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength()));
}
System.out.println("----------------------");
}
} }
Hadoop学习(6)-HBASE的安装和命令行操作和java操作的更多相关文章
- Hadoop学习(7)-hive的安装和命令行使用和java操作
Hive的用处,就是把hdfs里的文件建立映射转化成数据库的表 但hive里的sql语句都是转化成了mapruduce来对hdfs里的数据进行处理 ,并不是真正的在数据库里进行了操作. 而那些表的定义 ...
- Hadoop学习(5)-zookeeper的安装和命令行,java操作
zookeeper是干嘛的呢 Zookeeper的作用1.可以为客户端管理少量的数据kvkey:是以路径的形式表示的,那就意味着,各key之间有父子关系,比如/ 是顶层key用户建的key只能在/ 下 ...
- webpack学习(一)安装和命令行、一次js/css的打包体验及不同版本错误
一.前言 找了一个视频教程开始学习webpack,跟着视频学习,在自己的实际操作中发现,出现了很多问题.基本上都是因为版本的原因而导致,自己看的视频是基于webpack 1.x版,而自己现在早已是we ...
- Phoenix |安装配置| 命令行操作| 与hbase的映射| spark对其读写
Phoenix Phoenix是HBase的开源SQL皮肤.可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据. 1.特点 1) 容易集成:如Spark,Hi ...
- 【分布式】ZooKeeper学习之一:安装及命令行使用
ZooKeeper学习之一:安装及命令行使用 一直都想着好好学一学分布式系统,但是这拖延症晚期也是没得治了,所以干脆强迫自己来写一个系列博客,从zk的安装使用.客户端调用.涉及到的分布式原理.选举过程 ...
- mac安装GNU命令行工具
mac安装GNU命令行工具 2.添加的repo tap home/dupes brew install coreutils binutils diffutils ed -- ...
- 【Mac】Mac OS X 安装GNU命令行工具
macos的很多用户都是做it相关的人,类unix系统带来了很多方面,尤其是经常和linux打交道的人. 但是作为经常使用linux 命令行的人发现macos中的命令行工具很多都是bsd工具,跟lin ...
- Django之win7下安装与命令行工具
Django之win7下安装与命令行工具 下载安装 pip3 install django 注意:自动添加环境变量 测试是否安装成功 1.输入python 2.输入import django 3.输入 ...
- 你使用 Web 平台安装程序命令行工具
你使用 Web 平台安装程序命令行工具 获取的软件由其所有者授权给你.Microsoft 未授予你第三方软件的任何权利.已成功加载主源: https://go.microsoft.com/?linki ...
随机推荐
- springboot读取外部配置文件
springboot项目打成jar包后不好进行配置文件修改,可设置为读取外部配置文件,方便进行配置修改. 步骤: 1.将jar包中的application.properties配置文件复制到自定义路径 ...
- 'internalField' 和'boundaryField'的区别?【翻译】
翻译自:CFD-online 帖子地址:http://www.cfd-online.com/Forums/openfoam/84322-difference-between-internalfield ...
- fixedFluxPressure边界条件【转载】
转载自:http://blog.sina.com.cn/s/blog_e256415d0102vikh.html fixedFluxPressure是OpenFOAM较新的一个边界条件,表示边界处压力 ...
- Java核心复习 —— J.U.C 并发工具类
一.CountDownLatch 文档描述 A synchronization aid that allows one or more threads to wait until* a set of ...
- xposed代码示例
package com.example.xposedhook; import android.util.Log; import de.robv.android.xposed.IXposedHookLo ...
- 异步任务神器 和定时任务Celery
异步任务神器 Celery Celery 在程序的运行过程中,我们经常会碰到一些耗时耗资源的操作,为了避免它们阻塞主程序的运行,我们经常会采用多线程或异步任务.比如,在 Web 开发中,对新用户的注册 ...
- STL算法之find
定义 template <class InputIterator, class T> InputIterator find (InputIterator first, InputItera ...
- SQL按照顺序时间段统计
借助master..spt_values表 按照时间(半小时)划分统计时间段: select ,dateInfo.dday) as time) StartTime, ,),dateInfo.dday) ...
- FM与FFM深入解析
因子机的定义 机器学习中的建模问题可以归纳为从数据中学习一个函数,它将实值的特征向量映射到一个特定的集合中.例如,对于回归问题,集合 T 就是实数集 R,对于二分类问题,这个集合可以是{+1,-1}. ...
- TynSerial类介绍
TynSerial类介绍 TynSerial是咏南中间件封装的,支持数据二进制序列(还原)的类. 支持WINDOWS.LINUX.MAC.IOS.ANDROID. 支持D6及以上版本. 支持TCP/H ...