win10+pyspark+pycharm+anaconda单机环境搭建
一、工具准备
1. jdk1.8
2. scala
3. anaconda3
4. spark-2.3.1-bin-hadoop2.7
5. hadoop-2.8.3
6. winutils
7. pycharm
二、安装
1. jdk安装
oracle官网下载,安装后配置JAVA_HOME、CLASS_PATH,bin目录追加到PATH,注意:win10环境下PATH最好使用绝对路径!下同!

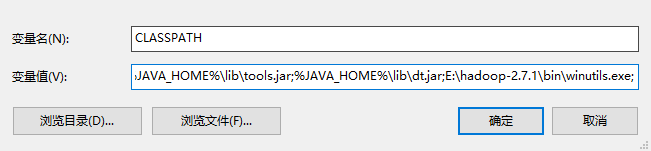
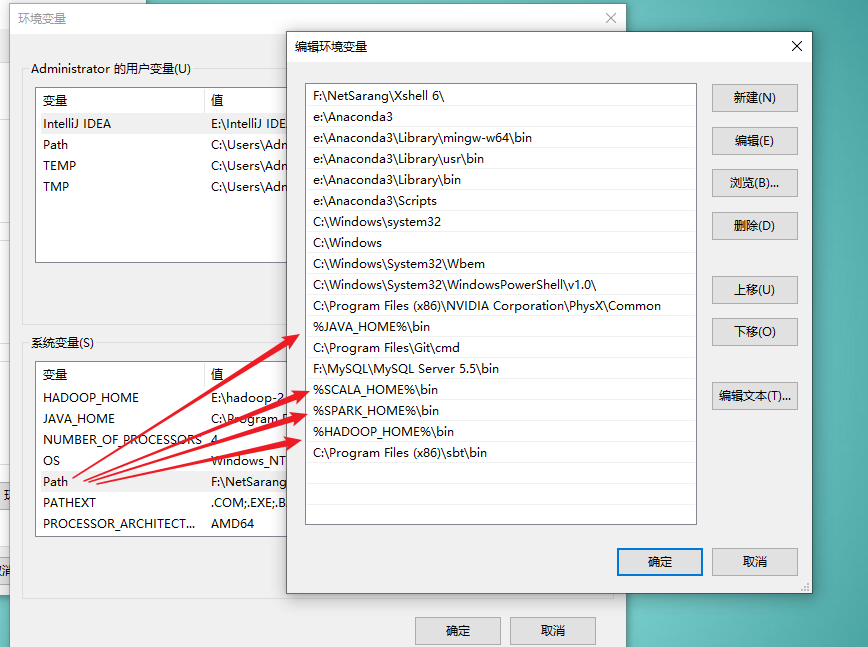
2. scala安装
官网下载,安装后配置SCALA_HOME,bin目录追加到PATH(上图包含)

3. anaconda3安装
官网下载,安装时注意在“追加到PATH”复选框打钩
4. spark安装
官网下载压缩包,解压缩后配置SPARK_HOME,bin目录追加到PATH(上图包含)
5. hadoop安装
官网下载版本>=spark对应hadoop版本,解压缩后配置HADOOP_HOME,bin目录追加到PATH(上图包含)
6. winutils安装
下载地址:https://github.com/steveloughran/winutils,按hadoop版本对应下载
7. pycharm安装
下载付费版本,使用lanyu注册码激活,注意按照提示添加域名解析到hosts文件
三、处理python相关
- 将pyspark文件夹(在spark-2.3.1-bin-hadoop2.7\python目录)复制到anaconda3\Lib\site-packages目录下
- 将winutils解压缩后用对应版本的bin目录替换hadoop下的bin目录
- conda install py4j
- 进入hadoop\bin目录下,以管理员方式打开cmd,输入命令:winutils.exe chmod 777 c:\tmp\Hive,若提示错误,检查Hive目录是否存在,若不存在,则手动创建,再重新执行命令
四、验证
打开pycharm,使用anaconda中的python作为解释器,输入以下代码并运行:
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a', 'b', 'c'], ['b', 'd', 'd']])
words = doc.flatMap(lambda d: d).distinct().collect()
word_dict = {w: i for w, i in zip(words, range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict = {}
wd = word_dict_b.value
for w in d:
if wd[w] in dict:
dict[wd[w]] += 1
else:
dict[wd[w]] = 1
return dict
print(doc.map(wordCountPerDoc).collect())
print("successful!")
运行结果:
[{0: 1, 1: 1, 2: 1}, {1: 1, 3: 2}]
successful!
本文为win10+pyspark+pycharm+anaconda的单机测试环境搭建。
win10+pyspark+pycharm+anaconda单机环境搭建的更多相关文章
- windows7 spark单机环境搭建及pycharm访问spark
windows7 spark单机环境搭建 follow this link how to run apache spark on windows7 pycharm 访问本机 spark 安装py4j ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- win10子系统linux.ubuntu开发环境搭建
移步新博客... win10子系统linux.ubuntu开发环境搭建
- Kafka 0.7.2 单机环境搭建
Kafka 0.7.2 单机环境搭建当下载完Kafka后,进行解压,其目录结构如下: bin config contrib core DISCLAIMER examples lib lib_manag ...
- kafka单机环境搭建及其基本使用
最近在搞kettle整合kafka producer插件,于是自己搭建了一套单机的kafka环境,以便用于测试.现整理如下的笔记,发上来和大家分享.后续还会有kafka的研究笔记,依然会与大家分享! ...
- HBase单机环境搭建
在搭建HBase单机环境之前,首先你要保证你已经搭建好Java环境: $ java -version java version "1.8.0_51" Java(TM) SE Run ...
- Hadoop —— 单机环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- Solr单机环境搭建及部署
一.定义 官网的定义: Solr是基于Lucene构建的流行,快速,开放源代码的企业搜索平台.它具有高度的可靠性,可伸缩性和容错能力,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配 ...
- hadoop单机环境搭建
[在此处输入文章标题] Hadoop单机搭建 1. 工具准备 1) Hadoop Linux安装包 2) VMware虚拟机 3) Java Linux安装包 4) Window 电脑一台 2. 开始 ...
随机推荐
- #软件更新#Visual Studio更新到16.3.8
#软件更新#Visual Studio更新到16.3.8 此次更新包括以下内容:(1)支持Xcode 11.2.(2)修复无法从System.String类型转化的bug.(3)修复UWP开发中,加载 ...
- Kali Linux软件更新日报20190622
Kali Linux软件更新日报20190622 (1)laudanum更新到1.0+r36-0kali3,此次更新移除了添加到webshells的链接. (2)mimikatz更新到2.2.0- ...
- JDK动态代理在RPC框架中的应用
RPC框架中一般都有3个角色:服务提供者.服务消费者和注册中心.服务提供者将服务注册到注册中心,服务消费者从注册中心拉取服务的地址,并根据服务地址向服务提供者发起RPC调用.动态代理在这个RPC调用的 ...
- vs Qt mysql 打包程序 Driver not loaded Driver not loaded
vs下开发Qt连接mysql程序,开发过程中操作MySQL没有问题,但打包以后安装在别的电脑上发现竟然无法连接MySQL,打包的时候,所需的libmysql.dll等dll文件拷贝到exe同级目录了, ...
- 算法习题---4-7RAID技术(UV509)
一:题目 (一)基础知识补充(RAID和奇偶校验) 磁盘管理—磁盘阵列(RAID)实例详解(本题目常用RAID 5技术实现) 奇偶校验(同行数据中同位上的1的个数,偶校验时:1的个数为偶数则校验结果为 ...
- Flink 实现指定时长或消息条数的触发器
Flink 中窗口是很重要的一个功能,而窗口又经常配合触发器一起使用. Flink 自带的触发器大概有: CountTrigger: 指定条数触发 ContinuousEventTimeTrigger ...
- 配置ssh免密,仍需要密码
配置ssh免密码登录后,仍提示输入密码 解决方法: 首先我们就要去查看系统的日志文件 tail /var/log/secure -n 20 Authentication refused: bad ...
- 细聊Oracle通过ODBC数据源连接SQL Server数据库
类似文章搜索引擎上有很多,内容大致相同,今天所谓细聊是因为我在借鉴这些文章时候走了些弯路,所以写此文,为自己备忘,同时如果能为初涉此处知识点的小伙伴提供些帮助就更好了,文章结尾处的一些扩展有一定实战意 ...
- Swift4.0复习协议
1.协议的定义: /// 定义一个协议MyProt protocol MyProt { /// 声明了一个实例方法foo, /// 其类型为:() -> Void func foo() ...
- Yii2打印原始sql语句
$query = User::find() ->where(['id'=>[1,2,3,4]) ->select(['username']) // get the AR raw sq ...