Understanding matrix factorization for recommendation
http://nicolas-hug.com/blog/matrix_facto_4
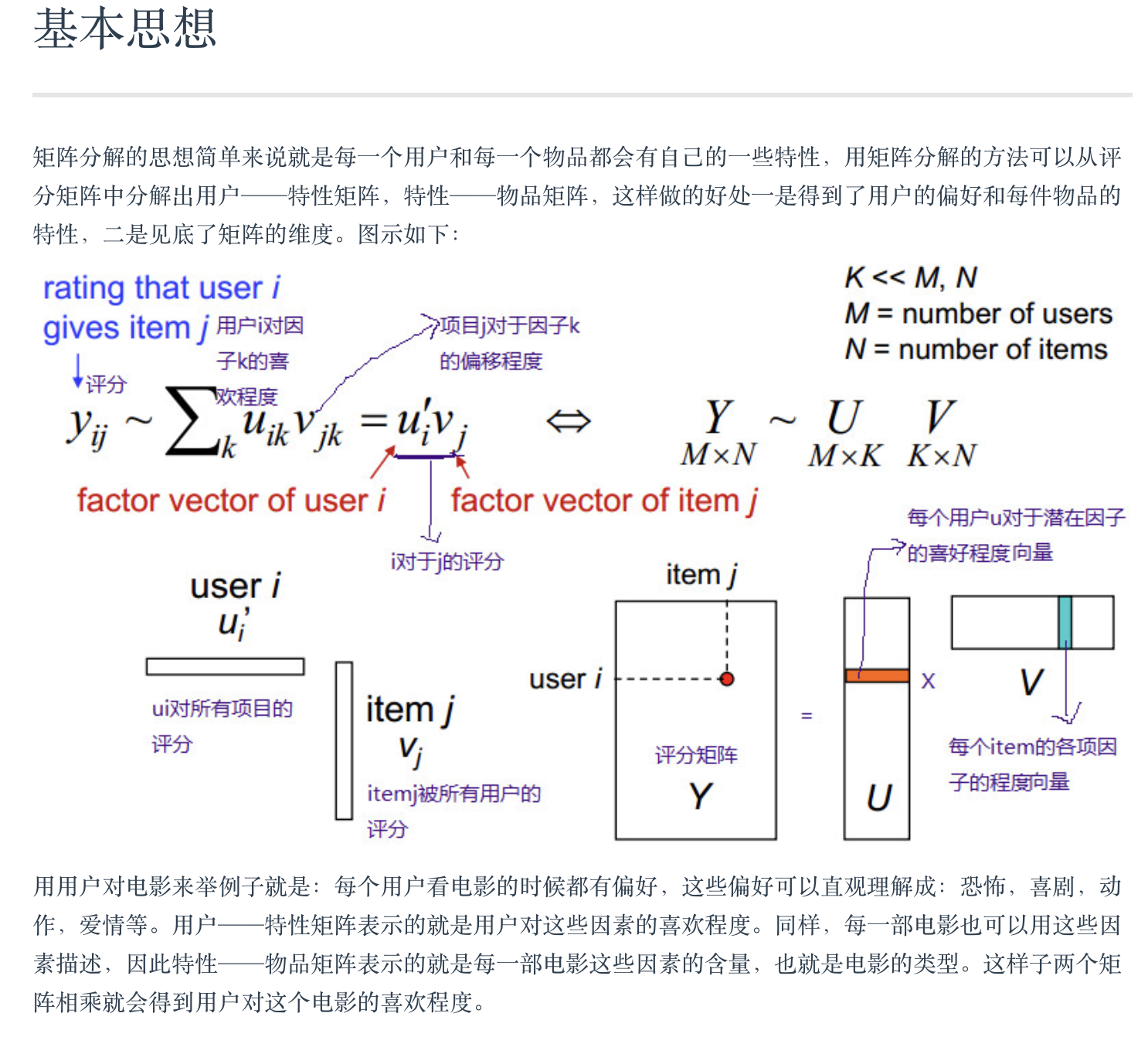
import numpy as np
import surprise # run 'pip install scikit-surprise' to install surprise
from surprise.model_selection import cross_validate
class MatrixFacto(surprise.AlgoBase):
'''A basic rating prediction algorithm based on matrix factorization.'''
def __init__(self, learning_rate, n_epochs, n_factors):
self.lr = learning_rate # learning rate for SGD
self.n_epochs = n_epochs # number of iterations of SGD
self.n_factors = n_factors # number of factors
def fit(self, trainset):
'''Learn the vectors p_u and q_i with SGD'''
print('Fitting data with SGD...')
# Randomly initialize the user and item factors.
p = np.random.normal(0, .1, (trainset.n_users, self.n_factors))
q = np.random.normal(0, .1, (trainset.n_items, self.n_factors))
# SGD procedure
for _ in range(self.n_epochs):
for u, i, r_ui in trainset.all_ratings():
err = r_ui - np.dot(p[u], q[i])
# Update vectors p_u and q_i
p[u] += self.lr * err * q[i]
q[i] += self.lr * err * p[u]
# Note: in the update of q_i, we should actually use the previous (non-updated) value of p_u.
# In practice it makes almost no difference.
self.p, self.q = p, q
self.trainset = trainset
def estimate(self, u, i):
'''Return the estmimated rating of user u for item i.'''
# return scalar product between p_u and q_i if user and item are known,
# else return the average of all ratings
if self.trainset.knows_user(u) and self.trainset.knows_item(i):
return np.dot(self.p[u], self.q[i])
else:
return self.trainset.global_mean
# data loading. We'll use the movielens dataset (https://grouplens.org/datasets/movielens/100k/)
# it will be downloaded automatically.
data = surprise.Dataset.load_builtin('ml-100k')
#data.split(2) # split data for 2-folds cross validation
algo = MatrixFacto(learning_rate=.01, n_epochs=10, n_factors=10)
#surprise.evaluate(algo, data, measures=['RMSE'])
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
Understanding matrix factorization for recommendation的更多相关文章
- Matrix Factorization SVD 矩阵分解
Today we have learned the Matrix Factorization, and I want to record my study notes. Some kownledge ...
- 关于NMF(Non-negative Matrix Factorization )
著名的科学杂志<Nature>于1999年刊登了两位科学家D.D.Lee和H.S.Seung对数学中非负矩阵研究的突出成果.该文提出了一种新的矩阵分解思想――非负矩阵分解(Non-nega ...
- Matrix Factorization, Algorithms, Applications, and Avaliable packages
矩阵分解 来源:http://www.cvchina.info/2011/09/05/matrix-factorization-jungle/ 美帝的有心人士收集了市面上的矩阵分解的差点儿全部算法和应 ...
- 机器学习技法:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- 《Non-Negative Matrix Factorization for Polyphonic Music Transcription》译文
NMF(非负矩阵分解),由于其分解出的矩阵是非负的,在一些实际问题中具有非常好的解释,因此用途很广.在此,我给大家介绍一下NMF在多声部音乐中的应用.要翻译的论文是利用NMF转录多声部音乐的开山之作, ...
- 机器学习技法笔记:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- Non-negative Matrix Factorization 非负矩阵分解
著名的科学杂志<Nature>于1999年刊登了两位科学家D.D.Lee和H.S.Seung对数学中非负矩阵研究的突出成果.该文提出了一种新的矩阵分解思想――非负矩阵分解(Non-nega ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
随机推荐
- Linux文件误删恢复
一.需求研究 分析对比debugfs.testdisk 6.14.extundelete,对比各自官网介绍和操作说明本次决定研究extundelete对文件和目录的恢复操作. 二.项目内容 1.工具安 ...
- linux 文件描述符表 打开文件表 inode vnode
在Linux中,进程是通过文件描述符(file descriptors,简称fd)而不是文件名来访问文件的,文件描述符实际上是一个整数.Linux中规定每个进程能最多能同时使用NR_OPEN个文件 ...
- 6.66 分钟,一文Python爬虫解疑大全教入门!
我收集了大家关注爬虫最关心的 16 个问题,这里我再整理下分享给大家,并一一解答. 1. 现在爬虫好找工作吗? 如果是一年前我可能会说爬虫的工作还是挺好找的,但现在已经不好找了,一市场饱和了,二是爬 ...
- AVL排序二叉树树
AVL树第一部分,(插入) AVL树是一种自平衡二叉搜索树(BST),其中对于所有节点,左右子树的高度差不能超过1. 一个AVL树的示例 上面的树是AVL树,因为每个节点的左子树和右子树的高度之间的差 ...
- PAT(B) 1094 谷歌的招聘(Java)
题目链接:1094 谷歌的招聘 (20 point(s)) 题目描述 2004 年 7 月,谷歌在硅谷的 101 号公路边竖立了一块巨大的广告牌(如下图)用于招聘.内容超级简单,就是一个以 .com ...
- golang 管理 pidfile
Pidfile 存储了进程的进程 id.一般情况下 pidfile 有以下几个作用: 其他进程可以读取 pidfile 获取运行进程的 pid(当然也可以通过其他命令 动态获取) 在启动进程前先检查 ...
- Spring AOP日志实现(四)--Bean的设计
日志Bean的设计: 类名及方法名:
- iview前台端口设置,跨域端口设置
前台启动默认端口: 跨域端口: 完毕
- Java之协程(quasar)
一.前面我们简单的说了一下,Python中的协程原理.这里补充Java的协程实现过程.有需要可以查看python之协程. 二.Java协程,其实做Java这么久我也没有怎么听过Java协程的东西,但是 ...
- 区块链公链分片技术(sharding)方案思维导图