字符串操作-格式化输出-Python
字符串操作示例
strip
p将字符串开头和末尾的空白(但不包括中间的空白)删除,并返回删除后的结果。
s.strip().lstrip().rstrip(',')
在一个字符串参数中指定要删除哪些字符
'*** SPAM * for * everyone!!! ***'.strip(' *!')
复制字符串
#strcpy(sStr1,sStr2)
sStr1 = 'strcpy'
sStr2 = sStr1
sStr1 = 'strcpy2'
print sStr2
连接字符串
#strcat(sStr1,sStr2)
sStr1 = 'strcat'
sStr2 = 'append'
sStr1 += sStr2
print sStr1
查找字符
#strchr(sStr1,sStr2)
# < 0 为未找到
sStr1 = 'strchr'
sStr2 = 's'
nPos = sStr1.index(sStr2)
print nPos
比较字符串
#strcmp(sStr1,sStr2)
sStr1 = 'strchr'
sStr2 = 'strch'
print cmp(sStr1,sStr2)
扫描字符串是否包含指定的字符
#strspn(sStr1,sStr2)
sStr1 = '12345678'
sStr2 = '456'
#sStr1 and chars both in sStr1 and sStr2
print len(sStr1 and sStr2)
字符串长度
#strlen(sStr1)
sStr1 = 'strlen'
print len(sStr1)
将字符串中的大小写转换
S.lower() #小写
S.upper() #大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
#实例:
#strlwr(sStr1)
sStr1 = 'JCstrlwr'
sStr1 = sStr1.upper()
#sStr1 = sStr1.lower()
print sStr1
追加指定长度的字符串
#strncat(sStr1,sStr2,n)
sStr1 = '12345'
sStr2 = 'abcdef'
n = 3
sStr1 += sStr2[0:n]
print sStr1
字符串指定长度比较
#strncmp(sStr1,sStr2,n)
sStr1 = '12345'
sStr2 = '123bc'
n = 3
print cmp(sStr1[0:n],sStr2[0:n])
复制指定长度的字符
#strncpy(sStr1,sStr2,n)
sStr1 = ''
sStr2 = '12345'
n = 3
sStr1 = sStr2[0:n]
print sStr1
将字符串前n个字符替换为指定的字符
#strnset(sStr1,ch,n)
sStr1 = '12345'
ch = 'r'
n = 3
sStr1 = n * ch + sStr1[3:]
print sStr1
扫描字符串
#strpbrk(sStr1,sStr2)
sStr1 = 'cekjgdklab'
sStr2 = 'gka'
nPos = -1
for c in sStr1:
if c in sStr2:
nPos = sStr1.index(c)
break
print nPos
翻转字符串
#strrev(sStr1)
sStr1 = 'abcdefg'
sStr1 = sStr1[::-1]
print sStr1
find
在字符串中查找子串。如果找到,就返回子串的第一个字符的索引,否则返回-1。
>>> 'With a moo-moo here, and a moo-moo there'.find('moo')
7
>>> title = "Monty Python's Flying Circus"
>>> title.find('Monty')
center
在两边添加填充字符(默认为空格)让字符串居中
>>> "The Middle by Jimmy Eat World".center(39)
' The Middle by Jimmy Eat World '
>>> "The Middle by Jimmy Eat World".center(39, "*")
'*****The Middle by Jimmy Eat World*****'
分割字符串
#strtok(sStr1,sStr2)
sStr1 = 'ab,cde,fgh,ijk'
sStr2 = ','
sStr1 = sStr1[sStr1.find(sStr2) + 1:]
print sStr1
#或者
s = 'ab,cde,fgh,ijk'
print(s.split(','))
join
其作用与split相反,用于合并序列的元素
delimiter = ','
mylist = ['Brazil', 'Russia', 'India', 'China']
print delimiter.join(mylist)
>>> seq = ['1', '2', '3', '4', '5']
>>> sep.join(seq) # 合并一个字符串列表
'1+2+3+4+5'
>>> dirs = '', 'usr', 'bin', 'env'
>>> '/'.join(dirs)
'/usr/bin/env'
>>> print('C:' + '\\'.join(dirs))
C:\usr\bin\env
PHP 中 addslashes 的实现
复制代码代码如下:
def addslashes(s):
d = {'"':'\"', "'":"\'", "\0":"\\0", "\":"\\"}
return ''.join(d.get(c, c) for c in s)
s = "John 'Johny' Doe (a.k.a. "Super Joe")\\0"
print s
print addslashes(s)
只显示字母与数字
def OnlyCharNum(s,oth=''):
s2 = s.lower();
fomart = 'abcdefghijklmnopqrstuvwxyz0123456789'
for c in s2:
if not c in fomart:
s = s.replace(c,'');
return s;
print(OnlyStr("a000 aa-b"))
截取字符串
str = '0123456789′
print str[0:3] #截取第一位到第三位的字符
print str[:] #截取字符串的全部字符
print str[6:] #截取第七个字符到结尾
print str[:-3] #截取从头开始到倒数第三个字符之前
print str[2] #截取第三个字符
print str[-1] #截取倒数第一个字符
print str[::-1] #创造一个与原字符串顺序相反的字符串
print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
print str[-3:] #截取倒数第三位到结尾
print str[:-5:-3] #逆序截取,具体啥意思没搞明白?
字符串在输出时的对齐
S.ljust(width,[fillchar])
#输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.rjust(width,[fillchar]) #右对齐
S.center(width, [fillchar]) #中间对齐
S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
字符串中的搜索和替换
S.find(substr, [start, [end]])
#返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索
S.index(substr, [start, [end]])
#与find()相同,只是在S中没有substr时,会返回一个运行时错误
S.rfind(substr, [start, [end]])
#返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号
S.rindex(substr, [start, [end]])
S.count(substr, [start, [end]]) #计算substr在S中出现的次数
S.replace(oldstr, newstr, [count])
#把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换
S.strip([chars])
#把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
S.lstrip([chars])
S.rstrip([chars])
S.expandtabs([tabsize])
#把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
字符串的分割和组合
S.split([sep, [maxsplit]])
#以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
S.rsplit([sep, [maxsplit]])
S.splitlines([keepends])
#把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。
S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
字符串的mapping,这一功能包含两个函数
String.maketrans(from, to)
#返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。
S.translate(table[,deletechars])
# 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译表。
字符串还有一对编码和解码的函数
S.encode([encoding,[errors]])
# 其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib big5 bzse64等都支持。errors默认值为"strict",意思是UnicodeError。可能的值还有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 和所有的通过codecs.register_error注册的值。这一部分内容涉及codecs模块,不是特明白
S.decode([encoding,[errors]])
字符串的测试、判断函数,这一类函数在string模块中没有,这些函数返回的都是bool值
S.startswith(prefix[,start[,end]])
#是否以prefix开头
S.endswith(suffix[,start[,end]])
#以suffix结尾
S.isalnum()
#是否全是字母和数字,并至少有一个字符
S.isalpha() #是否全是字母,并至少有一个字符
S.isdigit() #是否全是数字,并至少有一个字符
S.isspace() #是否全是空白字符,并至少有一个字符
S.islower() #S中的字母是否全是小写
S.isupper() #S中的字母是否便是大写
S.istitle() #S是否是首字母大写的
字符串类型转换函数,这几个函数只在string模块中有
string.atoi(s[,base])
#base默认为10,如果为0,那么s就可以是012或0x23这种形式的字符串,如果是16那么s就只能是0x23或0X12这种形式的字符串
string.atol(s[,base]) #转成long
string.atof(s[,base]) #转成float
判断字符串是否满足特定的条件
isalnum、isalpha、isdecimal、isdigit、isidentifier、islower、isnumeric、isprintable、isspace、istitle、isupper。
这里再强调一次,字符串对象是不可改变的,也就是说在python创建一个字符串后,你不能把这个字符中的某一部分改变。任何上面的函数改变了字符串后,都会返回一个新的字符串,原字串并没有变。其实这也是有变通的办法的,可以用S=list(S)这个函数把S变为由单个字符为成员的list,这样的话就可以使用S[3]='a'的方式改变值,然后再使用S=" ".join(S)还原成字符串
格式话输出
%方式
print ("the book's price is %s" % price)
语法:
print 函数包含以下三个部分,第一部分是格式化字符串(相当于字符串模板),该格式化字符串中包含一个“%s”占位符,它会被第三部分的变量或表达式的值代替;第二部分固定使用“%”作为分隔符。
格式化字符串中的“%s”被称为转换说明符(Conversion Specifier),其作用相当于一个占位符,它会被后面的变量或表达式的值代替。“%s”指定将变量或值使用 str() 函数转换为字符串
如果格式化字符串中包含多个“%s”占位符,第三部分也应该对应地提供多个变量,并且使用圆括号将这些变量括起来
user = "Charli"
age = 8
# 格式化字符串有两个占位符,第三部分提供2个变量
print("%s is a %s years old boy" % (user , age))
格式转换说明:
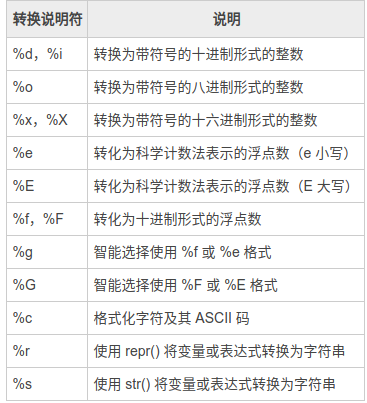
在默认情况下,转换出来的字符串总是右对齐的,不够宽度时左边补充空格。Python 也允许在最小宽度之前添加一个标志来改变这种行为,Python 支持如下标志:
-:指定左对齐。
+:表示数值总要带着符号(正数带“+”,负数带“-”)。
0:表示不补充空格,而是补充 0。
示例:
num = -28
print("num is: %6i" % num)
print("num is: %6d" % num)
print("num is: %6o" % num)
print("num is: %6x" % num)
print("num is: %6X" % num)
print("num is: %6s" % num)
num2 = 30
# 最小宽度为0,左边补0
print("num2 is: %06d" % num2)
# 最小宽度为6,左边补0,总带上符号
print("num2 is: %+06d" % num2)
# 最小宽度为6,右对齐
print("num2 is: %-6d" % num2)
对于转换浮点数,Python 还允许指定小数点后的数字位数:如果转换的是字符串,Python 允许指定转换后的字符串的最大字符数。这个标志被称为精度值,该精度值被放在最小宽度之后,中间用点 ( . ) 隔开
my_value = 3.001415926535
# 最小宽度为8,小数点后保留3位
print("my_value is: %8.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0
print("my_value is: %08.3f" % my_value)
# 最小宽度为8,小数点后保留3位,左边补0,始终带符号
print("my_value is: %+08.3f" % my_value)
the_name = "Charlie"
# 只保留3个字符
print("the name is: %.3s" % the_name) # 输出Cha
# 只保留2个字符,最小宽度10
print("the name is: %10.2s" % the_name)
%[(name)][flags][width].[precision]typecode
参数说明
(name) 可选,用于选择指定的key
flags 可选,可供选择的值有:
+ 右对齐;正数前加正好,负数前加负号;
- 左对齐;正数前无符号,负数前加负号;
空格 右对齐;正数前加空格,负数前加负号;
0 右对齐;正数前无符号,负数前加负号;用0填充空白处
width 可选,占有宽度
.precision 可选,小数点后保留的位数
typecode 必选:
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
o,将整数转换成 八 进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号 注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
.format格式
[[fill]align][sign][#][0][width][,][.precision][type]
#参数:
fill 【可选】空白处填充的字符
align 【可选】对齐方式(需配合width使用)
<,内容左对齐
>,内容右对齐(默认)
=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
,内容居中
sign 【可选】有无符号数字
+,正号加正,负号加负;
-,正号不变,负号加负;
空格 ,正号空格,负号加负;
\# 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
, 【可选】为数字添加分隔符,如:1,000,000
width 【可选】格式化位所占宽度
.precision 【可选】小数位保留精度
type 【可选】格式化类型
传入” 字符串类型 “的参数
s,格式化字符串类型数据
空白,未指定类型,则默认是None,同s
传入“ 整数类型 ”的参数
b,将10进制整数自动转换成2进制表示然后格式化
c,将10进制整数自动转换为其对应的unicode字符
d,十进制整数
o,将10进制整数自动转换成8进制表示然后格式化;
x,将10进制整数自动转换成16进制表示然后格式化(小写x)
X,将10进制整数自动转换成16进制表示然后格式化(大写X)
传入“ 浮点型或小数类型 ”的参数
e, 转换为科学计数法(小写e)表示,然后格式化;
E, 转换为科学计数法(大写E)表示,然后格式化;
f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
g, 自动在e和f中切换
G, 自动在E和F中切换
%,显示百分比(默认显示小数点后6位)
用法
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
#pyversion:python3.5
#owner:fuzj
f1 = "i am {0}, i am {1}d years old".format('Jeck',26) #采用位置参数来索引
f2 = "i am {name}, i am {age}d years old".format(**{'name':'jeck','age':26}) #采用自定义key来缩影,此时**表示将字典的k/v取出
f3 = "--{name:*^10s}-- =={age:<10.2f}==".format(name='Jeck',age=26.457) #将name的宽度设置为10,空余的使用*号不全,并居中显示,age类型设置为浮点型,宽度为10.并左对齐
f4 = "原数:{:d} 二进制:{:b}, 八进制:{:o}, 十六进制x:{:x},十六进制X:{:X}".format(15, 15, 15, 15, 15) #进制转换
f5 = "原数:{:d}, 科学计数法e:{:e}, 科学计数法E:{:E}" .format(1000000000,1000000000,1000000000) #科学计数法表示
f6 = "原数:{:2F}, 百分号表示{:.2%}, 原数:{:d},自动分割表示:{:,}".format(0.75,0.7584,10000000,10000000 ) #百分号表示及自动分割
print(f1)
print(f2)
print(f3)
print(f4)
print(f5)
print(f6)
字符串操作-格式化输出-Python的更多相关文章
- #python str.format 方法被用于字符串的格式化输出。
#python str.format 方法被用于字符串的格式化输出. #''.format() print('{0}+{1}={2}'.format(1,2,3)) #1+2=3 可见字符串中大括号内 ...
- python - 字符串的格式化输出
# -*- coding:utf-8 -*- '''@project: jiaxy@author: Jimmy@file: study_2_str.py@ide: PyCharm Community ...
- Python基础学习_01字符串的拼接(字符串的格式化输出)
# 字符串的拼接 ---字符串的格式化输出 # 字符串的拼接 ---字符串的格式化输出 name = input("name:") age = input("age:&q ...
- JSON字符串控制台格式化输出 java
1.正常情况下返回的json数据格式如下: {"header":{"transSn":"e33128bb7622462ebfb2cbfcc46baa1 ...
- python大法好——变量、常量、input()、数据类型、字符串、格式化输出、运算符、流程控制语句、进制、字符编码
python基础知识 1.变量 变量:把程序运算的中间结果临时存到内存里,以备后面的代码可以继续调用. 作用:A.存储数据. B.标记数据. 变量的声明规则: A:变量名只能是字母,数字或下划线任意组 ...
- 【Python④】python恼人的字符串,格式化输出
恼人的字符串 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码 ...
- 18.Python格式化字符串(格式化输出)
Python 提供了“%”对各种类型的数据进行格式化输出,例如如下代码: price = 108 print ("the book's price is %s" % price) ...
- Python格式化字符串(格式化输出)
熟悉C语言 printf() 函数的读者能够轻而易举学会 Python print() 函数,它们是非常类似的. print() 函数使用以%开头的转换说明符对各种类型的数据进行格式化输出,具体请看下 ...
- 『无为则无心』Python基础 — 10、Python字符串的格式化输出
目录 1.什么是格式化输出 2.Python格式化输出的五种方式 方式一:字符串之间用+号拼接 方式二:print()函数可同时输出多个字符串 方式三:占位符方式 方式四:f格式化方式(推荐) 方式五 ...
随机推荐
- soap-ws获取ws中的所有的接口方法
soap-ws获取wsdl中的所有的接口方法 示例wsdl文件如下,生成的过程可以参考https://www.cnblogs.com/chenyun-/p/11502446.html: <def ...
- mybatis-plus配置多数据源invalid bound statement (not found)
mybatis-plus配置多数据源invalid bound statement (not found) 错误原因 引入mybatis-plus应该使用的依赖如下,而不是mybatis <de ...
- 老贾的幸福生活day6 整型和布尔值的转换 字符串讲解 for 循环简介
整型和布尔值的转换: 整型: python 2 整型 int long(长整型) /获取的是整型 python 3 整型 int 获取的是浮点数(小数) 十进制转二进制: print(bin(36)) ...
- python的文件读写操作
文件读写 本文转自廖雪峰老师的教程https://www.liaoxuefeng.com/wiki/1016959663602400/1017607179232640 读写文件是最常见的IO操作.Py ...
- Docker——入门
虚拟化最大区别:虚拟化技术元件,资源申请调度到其他硬件服务器: Docker是一个开源得应用容器引擎,让开发者可以打包他们得应用以及依赖包到一共可移植得容器中,然后发布到任何流行得linux机器上,也 ...
- 怎样理解DOM
一句话总结: DOM 是一个 js 对象. 他可以赋予 js 控制 html 文档的能力. 全称: Document Object Model. DOM 的最小组成单位是: 节点 , 节点有7种类型 ...
- java 字节流与字符流的区别(转)
字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢? 实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操 ...
- asp.net 12 AJAX
Javascript:ajax Ajax:get <%@ Page Language="C#" AutoEventWireup="true" CodeBe ...
- 修改NPM默认全局安装路径
场景: 最近在新电脑上鼓捣完环境后,打算切换下源,结果使用全局安装的nrm时提示找不到命令,之前都是这么用现在怎么不行了呢? 排查过程: 于是各种折腾,发现- g安装的插件目录在C盘中的某个路径中,后 ...
- 洛谷UVA11987Almost Union-Find题解--并查集的删除
题目链接 https://www.luogu.org/problemnew/show/UVA11987 分析 分析下操作发现就是加了个删除操作的并查集,怎么做删除操作呢. 我们用一个\(id[]\)记 ...