Receiver Operating Characteristics (ROC)
The Receiver Operating Characteristics (ROC) of a classifier shows its performance as a trade off between selectivity and sensitivity. Typically a curve of false positive (false alarm) rate versus true positive rate is plotted while a sensitivity or threshold parameter is varied.
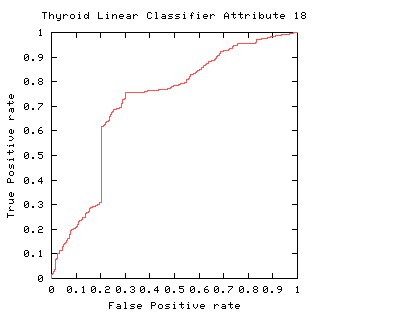 Fig. 1
Fig. 1
The curve always goes through two points (0,0 and 1,1). 0,0 is where the classifier finds no positives (detects no alarms). In this case it always gets the negative cases right but it gets all positive cases wrong. The second point is 1,1 where everything is classified as positive. So the classifier gets all positive cases right but it gets all negative cases wrong. (I.e. it raises a false alarm on each negative case).
Random Classifier ROC
A classifier that randomly guesses has ROC which lies somewhere along the diagonal line connecting 0,0 and 1,1.
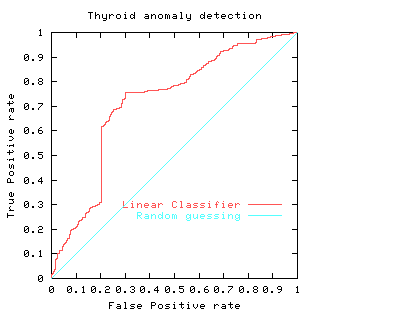 Fig. 2
Fig. 2
Worse than Random ROC
It is possible to do worse than random. This means the classifier's answer is correlated with the actual answer but negatively correlated. This means its ROC will lie below the diagonal. When this happens its performance can be improved by swapping the polarity of the classifiers output. This has the effect of rotating the ROC curve. (Or identically reflecting about a vertical line half way between 0 and 1 on the x-axis and then reflecting about a horizontal line halfway up the y-axis, or vice-versa).
The ROC curve (purple curve) could always be below the diagonal. Ie for all threshold values its performance is worse than random. Alternatively the ROC curve may cross the diagonal. In this case its overall performance can be improved by selectively reversing the classifier's answer, depending upon the range of threshold values which put it below the diagonal.
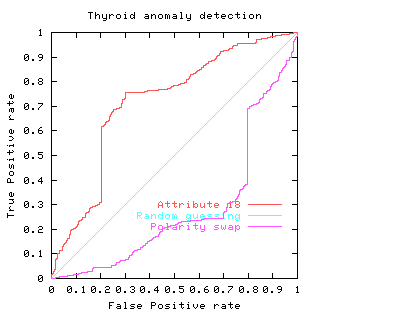 Fig. 3
Fig. 3
Area Under an ROC
The area under the ROC is a convenient way of comparing classifiers. A random classifier has an area of 0.5, while and ideal one has an area of 1. The area under the red (attribute 18) ROC curve is 0.717478 The area under the blue (attribute 19) ROC curve is 0.755266
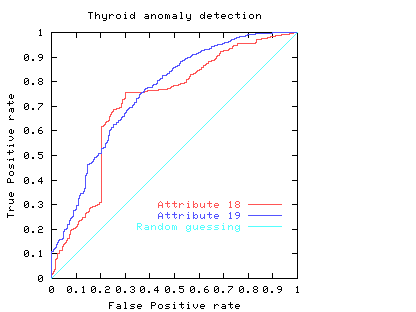 Fig. 4
Fig. 4
In practice to use a classifier one normally has to chose an operating point, a threshold. This fixes a point on the ROC. In some cases the area may be misleading. That is, when comparing classifiers, the one with the larger area may not be the one with the better performance at the chosen threshold (or limited range).
Choosing the Operating Point
Usually a classifier is used at a particular sensitivity, or at a particular threshold. The ROC curve can be used to choose the best operating point. (Of course this point must lie on the classifier's ROC). The best operating point might be chosen so that the classifier gives the best trade off between the costs of failing to detect positives against the costs of raising false alarms. These costs need not be equal, however this is a common assumption.
If the costs associated with classification are a simple sum of the cost of misclassifying positive and negative cases then all points on a straight line (whose gradient is given by the importance of the positive and negative examples) have the same cost. If the cost of misclassifying positive and negative cases are the same, and positive and negative cases occur equally often then the line has a slope of 1. That is it is at 45 degrees. The best place to operate the classifier is the point on its ROC which lies on a 45 degree line closest to the north-west corner (0,1) of the ROC plot.
Let
alpha = cost of a false positive (false alarm)
beta = cost of missing a positive (false negative)
p = proportion of positive cases
Then the average expected cost of classification at point x,y in the ROC space is
C = (1-p) alpha x + p beta (1-y)
Isocost lines (lines of equal cost) are parallel and straight. Their gradient depends upon alpha/beta and (1-p)/p. (Actually the gradient = alpha/beta times (1-p)/p). If costs are equal (alpha = beta) and 50% are positive (p = 0.5), the gradient is 1 and the isocost lines are at 45 degrees.
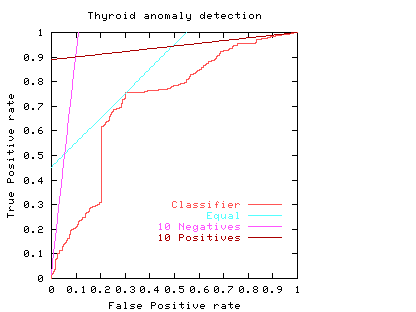 Fig. 5
Fig. 5
The light blue line in Fig. 5 shows the least cost line when costs of misclassifying positive and negative cases are equal. The purple line on the graph corresponds to when the costs of missing negative cases outweighs the cost of missing positive cases by ten to one. (e.g. p = 0.5, alpha = 1 and beta = 10). The third straight line (brown nearly horizontal) gives the optimum operating conditions when the costs of missing a positive case outweighs ten fold the cost of raising a false alarm. That is when it is much more important to maintain a high true positive rate and the negative cases have little impact on the total costs. (e.g. p = 0.91, alpha = 1 and beta = 1).
The graph shows the natural tendency to operate near the extremes of the ROC if either the costs associated with each of the two classes are very different or the individuals to be classified are highly biased to one class at the expense of the other. However in these extremes there will be comparatively little data in the minority case. This makes the calculation of the ROC itself more subject to statistical fluctuations (than near the middle) therefore much more data is required if the same level of statistical confidence is required.
Consider again the two classifiers for predicting problems with people's Thyroids (cf. Fig. 4). We see comparisons are not straightforward. For simplicity, we will assume each the costs associated with both classifiers are the same and they are equally acceptable to people. If one considered only the area under their ROC's, then we would prefer attribute 19 (blue line). However if we accept the linear costs argument then one of the two prominent corners of the linear classifier using attribute 18 (red) would have the least costs when positive and negative costs are more or less equal. However if costs (including factoring in the relative abundances of the two classes) associated with missing positives (or indeed) raising false alarms are dominant the attribute 19 would be the better measurement.
Another reason for preferring attribute 19, might be that at its chosen operating point, the calculation of its ROC is based on more data. Therefore it is subject to less statistical fluctuations and so (other things being equal) we can have more confidence in our predictions about how well the classifier will work at this threshold.
ROC and Error Rate
Error rate can be readily extracted from an ROC curve. Points on the ROC space with equal error rate are straight lines. Their gradient (like isocost lines) are given by the relative frequency of positive and negative examples. That is points along the ROC curve which intersect one of these lines have equal error rate.
The error rate can be obtained by setting the misclassification costs equal to each other and unity. (I.e. alpha = beta = 1). So
error rate = (1-p) x + p (1-y)
In the simple case where there are equal numbers of positive and negative examples, lines of equal error rate are at 45 degrees. That is they lie parallel to the diagonal (light blue lines). In this case the error rate is equal to half the false positive rate plus half (1 minus the true positive rate).
The ROC curve highlights a drawback of using a single error rate. In the Thyroid data there are few positive examples. If these are equally important as the negative cases the smallest error rate for this linear classifier is 5.7%, see purple line. Note this least error line almost intersects with the origin. That is, its apparently good performance (94.3% accuracy) arises because it suggests almost all data are negative (which is true) but at this threshold it had almost no ability to spot positive cases.
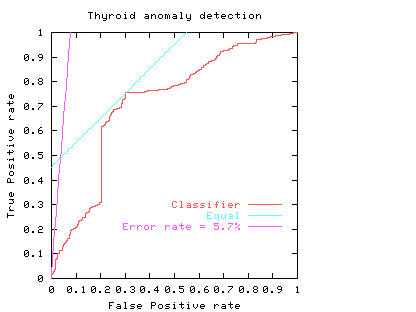 Fig. 6
Fig. 6
Convex Hull of the ROC
If the underlying distributions are fixed, an ROC curve will always be monotonic (does not decrease in the y direction as we trace along it by increasing x). But it need not be convex (as shown by the red line in the figures above). Scott [BMVC'98] showed that a non-convex classifier can be improved because it is always possible to operate the classifier on the convex hull of its ROC curve. However as our papers show sometimes it is possible to find nonlinear combinations of classifiers which produce an ROC exceeding their convex hulls.
Scott's ``Maximum Realisable'' ROC
Scott [BMVC'98] describes a procedure which will create from two existing classifiers a new one whose performance (in terms of its ROC) lies on a line connecting the performance of its two components. This is done by choosing one or other of the classifiers at random and using its result. E.g. if we need a classifier whose false positive rate versus its true positive rate lies on a line half way between the ROC points of classifiers A and B, then Scott's composite classifier will randomly give the answer given by A half the time and that given by B the other half, see Fig. 7 (Of course persuading patients to accept such a random diagnose may not be straightforward).
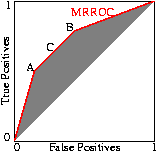
Fig. 7 Classifier C is created by choosing the output of classifier A half the time and classifier B the other half. Any point in the shaded area can be created. The ``Maximum Realisable ROC'' is its convex hull (solid red line).
The performance of the composite can be readily set to any point along the line simply by varying the ratio between the number of times one classifier is used relative to the other. Indeed this can be readily extended to any number of classifiers to fill the space between them. The better classifiers are those closer to the zero false positive axis or with a higher true positive rate. In other words the classifiers lying on the convex hull. Since Scott's procedure can tune the composite classifier to any point on the line connecting classifiers on the convex hull, the convex hull represents all the useful ROC points.
Scott's random combination method can be applied to each set of points along the ROC curve. So Scott's ``maximum realisable'' ROC is the convex hull of the classifier's ROC. Indeed, if the ROC is not convex, an improved classifier can easily be created from it The nice thing about the MRROC, is that it is always possible. But as Fig. 8 (and papers) show, it may be possible to do better automatically.
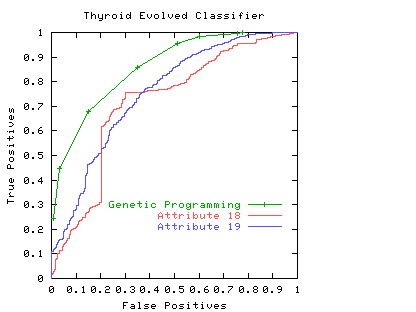
Fig. 8 The ROC produced by genetic programming using threshold values 0.2, 0.3, ... 1.0 on the Thyroid data (verification set)
ROC literature
Psychological Science in the Public Interest article (26 pages) on medical uses of ROCs by John A. Swets and Robyn M. Dawes and John Monahan. More ROC links
Acknowledgments
I would like to thank Danny Alexander for suggesting improvements.
W.B.Langdon@cs.ucl.ac.uk 10 April 2001 (last update 10 May 2011)
Receiver Operating Characteristics (ROC)的更多相关文章
- ROC曲线 Receiver Operating Characteristic
ROC曲线与AUC值 本文根据以下文章整理而成,链接: (1)http://blog.csdn.net/ice110956/article/details/20288239 (2)http://b ...
- ROC曲线(Receiver Operating Characteristic Curve)
分类模型尝试将各个实例(instance)划归到某个特定的类,而分类模型的结果一般是实数值,如逻辑回归,其结果是从0到1的实数值.这里就涉及到如何确定阈值(threshold value),使得模型结 ...
- Exploratory Undersampling for Class-Imbalance Learning
Abstract - Undersampling is a popular method in dealing with class-imbalance problems, which uses on ...
- Python Tools for Machine Learning
Python Tools for Machine Learning Python is one of the best programming languages out there, with an ...
- ROC 曲线/准确率、覆盖率(召回)、命中率、Specificity(负例的覆盖率)
欢迎关注博主主页,学习python视频资源 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.ht ...
- 机器学习-TensorFlow应用之classification和ROC curve
概述 前面几节讲的是linear regression的内容,这里咱们再讲一个非常常用的一种模型那就是classification,classification顾名思义就是分类的意思,在实际的情况是非 ...
- ROC和AUC介绍以及如何计算AUC ---好!!!!
from:https://www.douban.com/note/284051363/?type=like 原帖发表在我的博客:http://alexkong.net/2013/06/introduc ...
- 【转】ROC和AUC介绍以及如何计算AUC
转自:https://www.douban.com/note/284051363/ ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器( ...
- 分类器的评价指标-ROC&AUC
ROC 曲线:接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,roc 曲线上每个点反映着对同一信号刺激的感 ...
随机推荐
- 【转】Qt鼠标键盘事件
http://blog.csdn.net/lovebird_27/article/details/50351336 Qt 程序需要在main()函数创建一个QCoreApplication对象,然后调 ...
- 关于repaint和reflow的笔记
repaint(重绘) ,repaint发生更改时,元素的外观被改变,且在没有改变布局的情况下发生,如改变outline,visibility,background color,box-shadow不 ...
- 《剑指offer》第四十五题(把数组排成最小的数)
// 面试题45:把数组排成最小的数 // 题目:输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼 // 接出的所有数字中最小的一个.例如输入数组{3, 32, 321},则打印出这3 ...
- git Bash下复制粘贴
git复制:Ctrl+insert git粘贴:Shift+Insert git常用快捷键链接地址:https://www.jianshu.com/p/cc1fbd89e087 在gitHup上下载他 ...
- python Django 项目创建
注:后续如不特色说明,使用python版本均为python3 创建项目 django-admin startproject projectName 启动服务 python manage.py runs ...
- (转)c# 属性与索引器
属性是一种成员,它提供灵活的机制来读取.写入或计算私有字段的值. 属性可用作公共数据成员,但它们实际上是称为“访问器”的特殊方法. 这使得可以轻松访问数据,还有助于提高方法的安全性和灵活性. 一个简单 ...
- Java接口简单理解
1.接口: 接口成员变量默认声明方式:public.static.final 接口成员方法默认声明方式:public.abstract public interface Interface_class ...
- change_bit 按位取反
int change_bit(int nr, void * addr){ int oldbit; //1.第nr位取反, 原nr位入CF //2. sbbl带借位减(把源操作数和标志 ...
- python安装pandas和lxml
一.安装python 二.安装pip 三.安装mysql-connector(window版):下载mysql-connector-python-2.1.3,解压后进入目录,命令安装:pip inst ...
- 阻止ajax缓存方法
通过添加meta标签 <meta http-equiv= "pragma" content= "no-cache"/> (pragma: 杂注) & ...