pytorch中如何使用DataLoader对数据集进行批处理
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步?
第一步:打开冰箱门。
我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说)。
首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果:

随后我们需要把X和Y组成一个完整的数据集,并转化为pytorch能识别的数据集类型:

我们来看一下这些数据的数据类型:

可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】。
好了,第一步结束了,冰箱门打开了。
第二步:把大象装进去。
就是把上一步做成的数据集放入Data.DataLoader中,可以生成一个迭代器,从而我们可以方便的进行批处理。

DataLoader中也有很多其他参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
好了,第二步结束了,大象装进去了。
第三步:把冰箱门关上。
好啦,现在我们就可以愉快的用我们上面定义好的迭代器进行训练啦。
在这里我们利用print来模拟我们的训练过程,即我们在这里对搭建好的网络进行喂入。

输出的结果是:
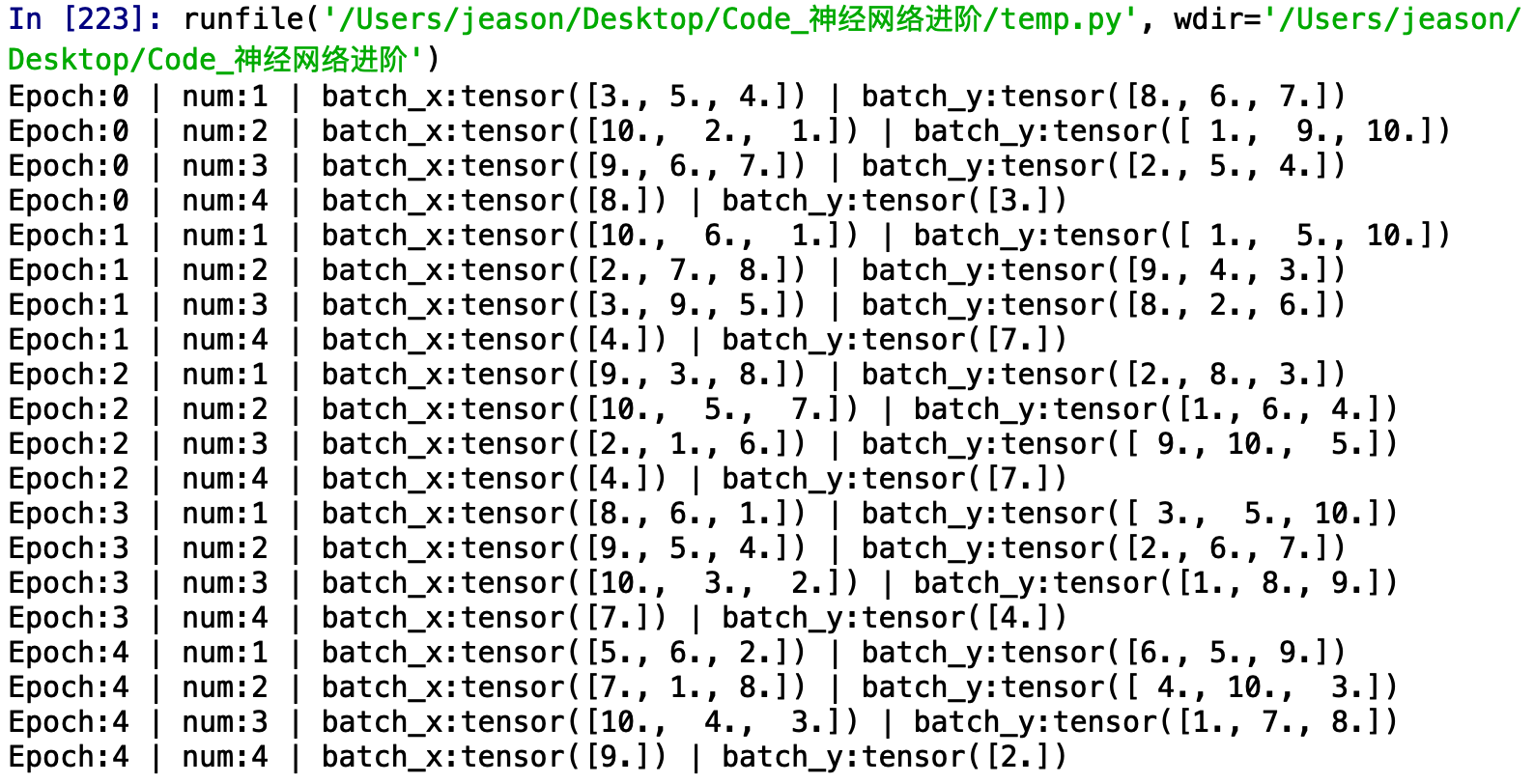
可以看到,我们一共训练了所有的数据训练了5次。数据中一共10组,我们设置的mini-batch是3,即每一次我们训练网络的时候喂入3组数据,到了最后一次我们只有1组数据了,比mini-batch小,我们就仅输出这一个。
此外,还可以利用python中的enumerate(),是对所有可以迭代的数据类型(含有很多东西的list等等)进行取操作的函数,用法如下:
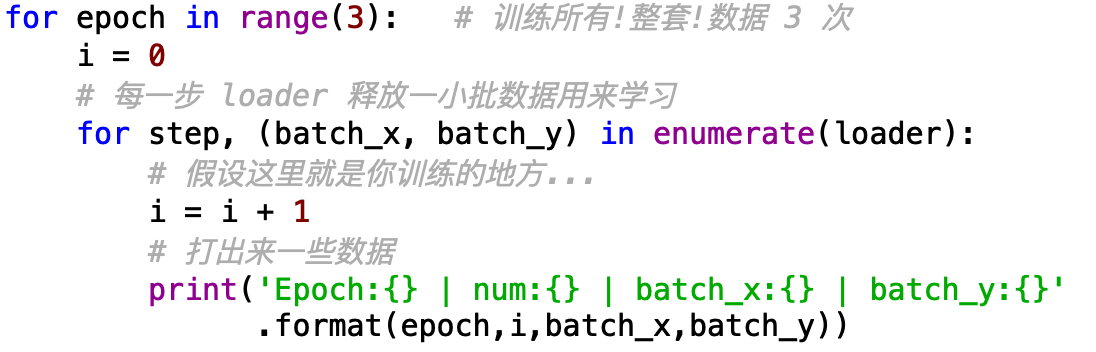
好啦,现在冰箱门就关上啦,(*^__^*)
pytorch中如何使用DataLoader对数据集进行批处理的更多相关文章
- pytorch Dataset数据集和Dataloader迭代数据集
import torch from torch.utils.data import Dataset,DataLoader class SmsDataset(Dataset): def __init__ ...
- pytorch中DataLoader, DataSet, Sampler之间的关系
转自:https://mp.weixin.qq.com/s/RTv0cUWvc0kuXBeNoXVu_A 自上而下理解三者关系 首先我们看一下DataLoader.__next__的源代码长什么样,为 ...
- PyTorch中的MIT ADE20K数据集的语义分割
PyTorch中的MIT ADE20K数据集的语义分割 代码地址:https://github.com/CSAILVision/semantic-segmentation-pytorch Semant ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- [深度学习] pytorch利用Datasets和DataLoader读取数据
本文简单描述如果自定义dataset,代码并未经过测试(只是说明思路),为半伪代码.所有逻辑需按自己需求另外实现: 一.分析DataLoader train_loader = DataLoader( ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
随机推荐
- js screen
windows.screen對象包含包含對象屏幕的信息: screen.availheight;屏幕高度 screen.availwidth;屏幕寬度
- Jenkins之前置替换脚本内容
在执行Jenkins任务前,需要修改执行的工程的某个文件中的内容,在前置步骤中编写脚本进行修改. Pre Steps Windows batch script @echo off CHCP setlo ...
- BZOJ4259 残缺的字符串(FFT)
两个串匹配时相匹配的位置位置差是相同的,那么翻转一个串就变成位置和相同,卷积的形式. 考虑如何使用卷积体现两个位置能否匹配.一个暴力的思路是每次只考虑一种字符,将其在一个串中设为1,并在另一个串中将不 ...
- Nodejs+Express+Mysql实现简单用户管理增删改查
源码地址 https://github.com/king-y/NodeJs/tree/master/user 目录结构 mysql.js var mysql = require('mysql'); v ...
- 自学Aruba4.1-Aruba开机初始化
点击返回:自学Aruba之路 自学Aruba4.1-Aruba开机初始化 无线控制器刚启动的时候,是没有任何配置的,需要进行初始化配置才能进行管理. 通过无线控制器的console端口连接无线控制器, ...
- 51nod 1462 树据结构 | 树链剖分 矩阵乘法
题目链接 51nod 1462 题目描述 给一颗以1为根的树. 每个点有两个权值:vi, ti,一开始全部是零. Q次操作: 读入o, u, d o = 1 对u到根上所有点的vi += d o = ...
- [poj2528]Mayor's posters
题目描述 The citizens of Bytetown, AB, could not stand that the candidates in the mayoral election campa ...
- [luogu4265][USACO18FEB]Snow Boots silver
题目大意 求出最少需要丢去多少双靴子才能到达终点. 解法 解法一: 看到数据的范围,非常清楚\(O(n^3)\)能过掉所有的数据,那么我们就果断暴力. 解法二: 比较容易会想到用DP做,我一开始定义\ ...
- 如何用ip代替机器名访问sharepoint site
1. iis里绑定ip 2. AAM里加一条ip的记录
- suoi07 区间平均++ (二分答案+前缀和)
https://www.vijos.org/d/SUOI/p/59dc5af7d3d8a1361ae62b97 二分一个答案,然后做一做前缀和,用满足区间大小的最小值减一减,判断答案合不合法 然而还要 ...