『TensorFlow』分布式训练_其二_单机多GPU并行&GPU模式设定
一、tensorflow GPU设置
GPU指定占用
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.7)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
上面分配给tensorflow的GPU显存大小为:GPU实际显存*0.7。
GPU模式禁用
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1"
GPU资源申请规则
# 设置 GPU 按需增长
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
二、单机多GPU工作原理
以一篇csdn博客(出处见水印)上的图说明多GPU工作原理:
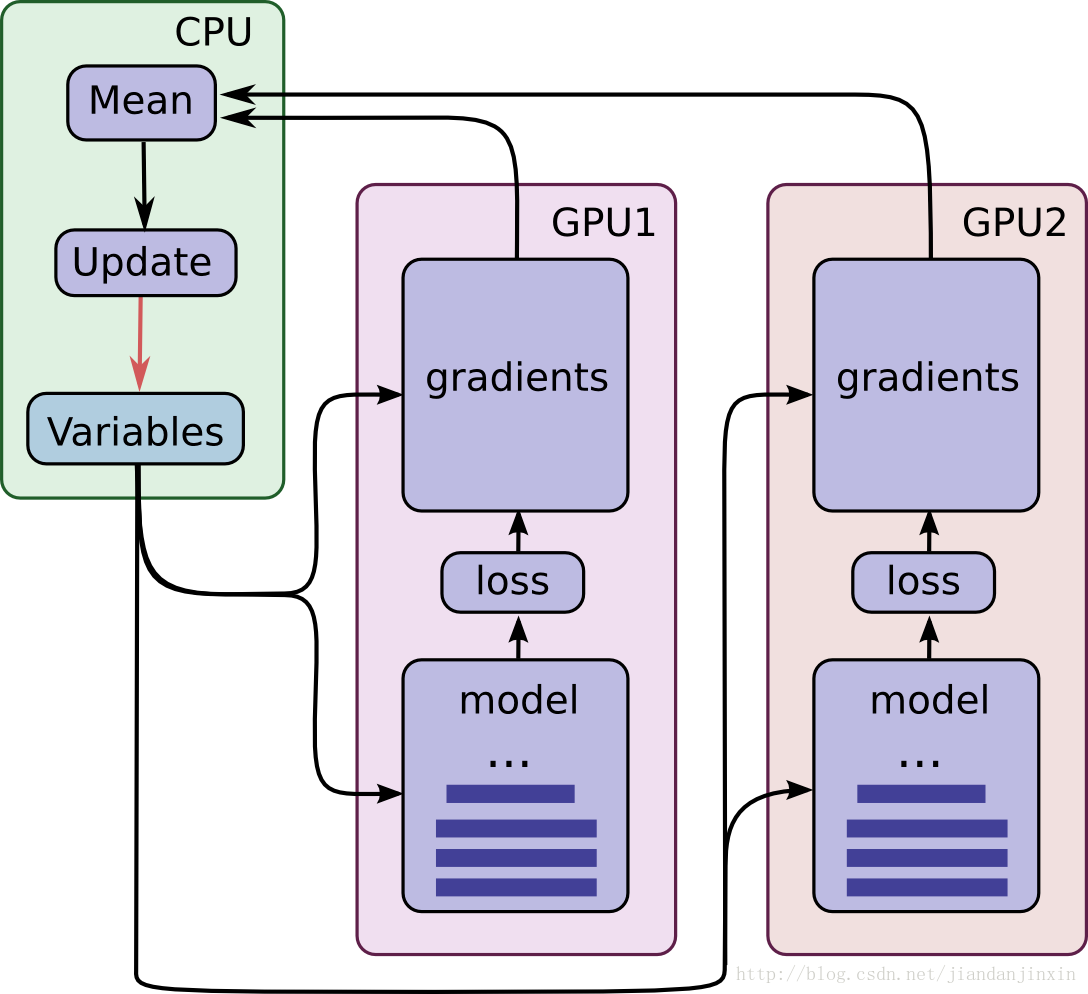
想让 TensorFlow 在多个 GPU 上运行, 需要建立 multi-tower 结构, 在这个结构里每个 tower 分别被指配给不同的 GPU 运行,汇总工作一般交由CPU完成,示意如下,
# 新建一个 graph.
c = []
for d in ['/gpu:2', '/gpu:3']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3])
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2])
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
# 新建session with log_device_placement并设置为True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# 运行这个op.
print sess.run(sum)
三、官方demo
多GPU分布+LR衰减+滑动平均
和MXNet不同,由于TensorFlow使用上下文指定设备,所以数据无需显示的拷贝到指定设备,在目标设备上下文中获取即可(需要调用对应节点于该设备下,如下文中的出队节点)
另一个值得注意的点在于收集来的梯度格式为List of lists of (gradient, variable) tuples,我们计算后返回的是List of (gradient, variable) tuples,variable随便指定一组gpu上的即可,这是因为和MXNet不同,MXNet是得到grad平均值后分发给各个GPU各自更新,TensorFlow实际是各个GPU使用同一套参数(tf.get_variable_scope().reuse_variables()),虽然会被拷贝到各个设备,但是彼此之间是有逻辑关系的,是共享参数,简化示意如下:
#将神经网络的优化过程跑在不同的GPU上
for i in range(N_GPU):
with tf.debice('/gpu:%d'%i)
with tf.name_scope('GPU_%d'%i) as scope:
cur_loss = get_loss(x,y_regularizer,scope)
#tf.get_variable的命名空间
tf.get_variable_scope().reuse_variables()
#使用当前gpu计算所有变量的梯度
grads= opt.compute_gradients(cur_loss)
tower_grads.append(grads)
#计算变量的平均梯度
grads = average_gradients(tower_grads)
#使用平均梯度更新参数
apply_gradient_op = opt.apply_gradients(grads,global_step = global)
models/tutorials/image/cifar10/cifer10_multi_gpu-train.py
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================== """A binary to train CIFAR-10 using multiple GPUs with synchronous updates.
Accuracy:
cifar10_multi_gpu_train.py achieves ~86% accuracy after 100K steps (256
epochs of data) as judged by cifar10_eval.py.
Speed: With batch_size 128.
System | Step Time (sec/batch) | Accuracy
--------------------------------------------------------------------
1 Tesla K20m | 0.35-0.60 | ~86% at 60K steps (5 hours)
1 Tesla K40m | 0.25-0.35 | ~86% at 100K steps (4 hours)
2 Tesla K20m | 0.13-0.20 | ~84% at 30K steps (2.5 hours)
3 Tesla K20m | 0.13-0.18 | ~84% at 30K steps
4 Tesla K20m | ~0.10 | ~84% at 30K steps
Usage:
Please see the tutorial and website for how to download the CIFAR-10
data set, compile the program and train the model.
http://tensorflow.org/tutorials/deep_cnn/
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function from datetime import datetime
import os.path
import re
import time import numpy as np
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import cifar10 FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string('train_dir', '/tmp/cifar10_train',
"""Directory where to write event logs """
"""and checkpoint.""")
tf.app.flags.DEFINE_integer('max_steps', 1000000,
"""Number of batches to run.""")
tf.app.flags.DEFINE_integer('num_gpus', 1,
"""How many GPUs to use.""")
tf.app.flags.DEFINE_boolean('log_device_placement', False,
"""Whether to log device placement.""") def tower_loss(scope, images, labels):
"""Calculate the total loss on a single tower running the CIFAR model.
Args:
scope: unique prefix string identifying the CIFAR tower, e.g. 'tower_0'
images: Images. 4D tensor of shape [batch_size, height, width, 3].
labels: Labels. 1D tensor of shape [batch_size].
Returns:
Tensor of shape [] containing the total loss for a batch of data
""" # Build inference Graph.
logits = cifar10.inference(images) # Build the portion of the Graph calculating the losses. Note that we will
# assemble the total_loss using a custom function below.
_ = cifar10.loss(logits, labels) # Assemble all of the losses for the current tower only.
losses = tf.get_collection('losses', scope) # Calculate the total loss for the current tower.
total_loss = tf.add_n(losses, name='total_loss') # Attach a scalar summary to all individual losses and the total loss; do the
# same for the averaged version of the losses.
for l in losses + [total_loss]:
# Remove 'tower_[0-9]/' from the name in case this is a multi-GPU training
# session. This helps the clarity of presentation on tensorboard.
loss_name = re.sub('%s_[0-9]*/' % cifar10.TOWER_NAME, '', l.op.name)
tf.summary.scalar(loss_name, l) return total_loss def average_gradients(tower_grads):
"""Calculate the average gradient for each shared variable across all towers.
Note that this function provides a synchronization point across all towers.
Args:
tower_grads: List of lists of (gradient, variable) tuples. The outer list
is over individual gradients. The inner list is over the gradient
calculation for each tower.
Returns:
List of pairs of (gradient, variable) where the gradient has been averaged
across all towers.
"""
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = []
for g, _ in grad_and_vars:
# Add 0 dimension to the gradients to represent the tower.
expanded_g = tf.expand_dims(g, 0) # Append on a 'tower' dimension which we will average over below.
grads.append(expanded_g) # Average over the 'tower' dimension.
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0) # Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default(), tf.device('/cpu:0'):
# Create a variable to count the number of train() calls. This equals the
# number of batches processed * FLAGS.num_gpus.
global_step = tf.get_variable(
'global_step', [],
initializer=tf.constant_initializer(0), trainable=False) # Calculate the learning rate schedule.
num_batches_per_epoch = (cifar10.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN /
FLAGS.batch_size)
decay_steps = int(num_batches_per_epoch * cifar10.NUM_EPOCHS_PER_DECAY) # Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(cifar10.INITIAL_LEARNING_RATE,
global_step,
decay_steps,
cifar10.LEARNING_RATE_DECAY_FACTOR,
staircase=True) # Create an optimizer that performs gradient descent.
opt = tf.train.GradientDescentOptimizer(lr) # Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
batch_queue = tf.contrib.slim.prefetch_queue.prefetch_queue(
[images, labels], capacity=2 * FLAGS.num_gpus)
# Calculate the gradients for each model tower.
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:%d' % i):
with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope:
# Dequeues one batch for the GPU
image_batch, label_batch = batch_queue.dequeue()
# Calculate the loss for one tower of the CIFAR model. This function
# constructs the entire CIFAR model but shares the variables across
# all towers.
loss = tower_loss(scope, image_batch, label_batch) # Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables() # Retain the summaries from the final tower.
summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope) # Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(loss) # Keep track of the gradients across all towers.
tower_grads.append(grads) # We must calculate the mean of each gradient. Note that this is the
# synchronization point across all towers.
grads = average_gradients(tower_grads) # Add a summary to track the learning rate.
summaries.append(tf.summary.scalar('learning_rate', lr)) # Add histograms for gradients.
for grad, var in grads:
if grad is not None:
summaries.append(tf.summary.histogram(var.op.name + '/gradients', grad)) # Apply the gradients to adjust the shared variables.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step) # Add histograms for trainable variables.
for var in tf.trainable_variables():
summaries.append(tf.summary.histogram(var.op.name, var)) # Track the moving averages of all trainable variables.
variable_averages = tf.train.ExponentialMovingAverage(
cifar10.MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables()) # Group all updates to into a single train op.
train_op = tf.group(apply_gradient_op, variables_averages_op) # Create a saver.
saver = tf.train.Saver(tf.global_variables()) # Build the summary operation from the last tower summaries.
summary_op = tf.summary.merge(summaries)
################################################################################
# Build an initialization operation to run below.
init = tf.global_variables_initializer() # Start running operations on the Graph. allow_soft_placement must be set to
# True to build towers on GPU, as some of the ops do not have GPU
# implementations.
sess = tf.Session(config=tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=FLAGS.log_device_placement))
sess.run(init) # Start the queue runners.
tf.train.start_queue_runners(sess=sess) summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph) for step in xrange(FLAGS.max_steps):
start_time = time.time()
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time assert not np.isnan(loss_value), 'Model diverged with loss = NaN' if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size * FLAGS.num_gpus
examples_per_sec = num_examples_per_step / duration
sec_per_batch = duration / FLAGS.num_gpus format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), step, loss_value,
examples_per_sec, sec_per_batch)) if step % 100 == 0:
summary_str = sess.run(summary_op)
summary_writer.add_summary(summary_str, step) # Save the model checkpoint periodically.
if step % 1000 == 0 or (step + 1) == FLAGS.max_steps:
checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step) def main(argv=None): # pylint: disable=unused-argument
cifar10.maybe_download_and_extract()
if tf.gfile.Exists(FLAGS.train_dir):
tf.gfile.DeleteRecursively(FLAGS.train_dir)
tf.gfile.MakeDirs(FLAGS.train_dir)
train() if __name__ == '__main__':
tf.app.run()
数据输入函数如下,
def distorted_inputs():
"""Construct distorted input for CIFAR training using the Reader ops.
Returns:
images: Images. 4D tensor of [batch_size, IMAGE_SIZE, IMAGE_SIZE, 3] size.
labels: Labels. 1D tensor of [batch_size] size.
Raises:
ValueError: If no data_dir
"""
if not FLAGS.data_dir:
raise ValueError('Please supply a data_dir')
data_dir = os.path.join(FLAGS.data_dir, 'cifar-10-batches-bin')
images, labels = cifar10_input.distorted_inputs(data_dir=data_dir,
batch_size=FLAGS.batch_size)
if FLAGS.use_fp16:
images = tf.cast(images, tf.float16)
labels = tf.cast(labels, tf.float16)
return images, labels
tf.contrib.slim.prefetch_queue.prefetch_queue从介绍来看就是个输入数据队列
Signature: tf.contrib.slim.prefetch_queue.prefetch_queue(tensors, capacity=8, num_threads=1, dynamic_pad=False, shared_name=None, name=None)
Docstring:
Creates a queue to prefetech tensors from `tensors`. A queue runner for enqueing tensors into the prefetch_queue is automatically
added to the TF QueueRunners collection. Example:
This is for example useful to pre-assemble input batches read with
`tf.train.batch()` and enqueue the pre-assembled batches. Ops that dequeue
from the pre-assembled queue will not pay the cost of assembling the batch. images, labels = tf.train.batch([image, label], batch_size=32, num_threads=4)
batch_queue = prefetch_queue([images, labels])
images, labels = batch_queue.dequeue()
logits = Net(images)
loss = Loss(logits, labels) Args:
tensors: A list or dictionary of `Tensors` to enqueue in the buffer.
capacity: An integer. The maximum number of elements in the queue.
num_threads: An integer. Number of threads running the enqueue op.
dynamic_pad: Boolean. Whether to allow variable dimensions in input shapes.
shared_name: (optional). If set, this queue will be shared under the given
name across multiple sessions.
name: (Optional) A name for the operations. Returns:
A queue from which you can dequeue tensors with the same type and shape
as `tensors`.
『TensorFlow』分布式训练_其二_单机多GPU并行&GPU模式设定的更多相关文章
- 『TensorFlow』分布式训练_其三_多机分布式
本节中的代码大量使用『TensorFlow』分布式训练_其一_逻辑梳理中介绍的概念,是成熟的多机分布式训练样例 一.基本概念 Cluster.Job.task概念:三者可以简单的看成是层次关系,tas ...
- 『TensorFlow』分布式训练_其一_逻辑梳理
1,PS-worker架构 将模型维护和训练计算解耦合,将模型训练分为两个作业(job): 模型相关作业,模型参数存储.分发.汇总.更新,有由PS执行 训练相关作业,包含推理计算.梯度计算(正向/反向 ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- 『TensorFlow』SSD源码学习_其五:TFR数据读取&数据预处理
Fork版本项目地址:SSD 一.TFR数据读取 创建slim.dataset.Dataset对象 在train_ssd_network.py获取数据操作如下,首先需要slim.dataset.Dat ...
- 『TensorFlow』SSD源码学习_其八:网络训练
Fork版本项目地址:SSD 作者使用了分布式训练的写法,这使得训练部分代码异常臃肿,我给出了部分注释.我对于多机分布式并不很熟,而且不是重点,所以不过多介绍,简单的给出一点训练中作者的优化手段,包含 ...
- 『TensorFlow』SSD源码学习_其四:数据介绍及TFR文件生成
Fork版本项目地址:SSD 一.数据格式介绍 数据文件夹命名为VOC2012,内部有5个子文件夹,如下, 我们的检测任务中使用JPEGImages文件夹和Annotations文件夹. JPEGIm ...
- 『TensorFlow』网络操作API_中_损失函数及分类器
一.误差值 度量两个张量或者一个张量和零之间的损失误差,这个可用于在一个回归任务或者用于正则的目的(权重衰减). l2_loss tf.nn.l2_loss(t, name=None) 解释:这个函数 ...
- 『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
Fork版本项目地址:SSD 参考自集智专栏 一.SSD基础 在分类器基础之上想要识别物体,实质就是 用分类器扫描整张图像,定位特征位置 .这里的关键就是用什么算法扫描,比如可以将图片分成若干网格,用 ...
- 『TensorFlow』SSD源码学习_其三:锚框生成
Fork版本项目地址:SSD 上一节中我们定义了vgg_300的网络结构,实际使用中还需要匹配SSD另一关键组件:被选取特征层的搜索网格.在项目中,vgg_300网络和网格生成都被统一进一个class ...
随机推荐
- P5091 【模板】欧拉定理
思路 欧拉定理 当a与m互质时 \[ a^ {\phi (m)} \equiv 1 \ \ (mod\ m) \] 扩展欧拉定理 当a与m不互质且\(b\ge \phi(m)\)时, \[ a^b \ ...
- 比赛总结——牛客网 NOIP赛前集训营提高组模拟第一场
第一场打的很惨淡啊 t1二分+前缀最小值没想出来,20分的暴力也挂了,只有10分 t2数位dp,调了半天,结果因为忘了判0的特殊情况WA了一个点,亏死 t3emmmm.. 不会 imone说是DSU ...
- AndroidStudio Gradle下载速度慢解决方法
1.在软件里点开工程文件下的 build.gradle 2..在 buildscript 和 allprojects 的 repositories 中分别注释掉 jcenter() 3.在 build ...
- maven下载jar包下载不下来的解决方法
转载请注明出处: 在eclipse中安装了maven插件,项目在运行的时候,一直通过pom.xml文件下载jar包,一直下载不下来, 在更新maven库时,如果网络问不定或者是一些自己手动安装到本地m ...
- 解决pip ReadTimeoutError问题
参考: 更新pip时报错:Read Timeout Error 解决pip ReadTimeoutError问题 问题:在Mac OSX系统下使用pip install时报错: ReadTimeout ...
- 【译】第20节---数据注解-InverseProperty
原文:http://www.entityframeworktutorial.net/code-first/inverseproperty-dataannotations-attribute-in-co ...
- 51nod 1624 取余最长路
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1624 题意: 思路:因为一共只有3行,所以只需要确定第一行和第二行的转折 ...
- 使用JS语句,利用for循环的方法创建表格的两种方法
首先去layui官网下载教程示例,在项目中加载layui.css,layui.js,JQuery.js 第一种: 将jsp语句写成字符串的形式,使用document.write()方式输出: 代码如下 ...
- 设计模式之组合模式(composite)
概念: 将对象组合成树形结构以表示“部分-整体”的层次结构.使用户对单个对象和组合对象的使用更具有一致性. 适用性:想表示对象的部分-整体层次结构.
- linux中date命令显示
1. date用来显示具体的日期和24进制的时间 [jasmine.qian@ ~]$ date Fri Jan 25 14:17:17 CST 2019 [jasmine.qian@ ~]$ dat ...