MySql从一窍不通到入门(五)Sharding:分表、分库、分片和分区
转载:用sharding技术来扩展你的数据库(一)sharding 介绍
转载:MySQL架构方案 - Scale Out & Scale Up.
转载: 数据表分区策略及实现(一)
转载:开源数据库 Sharding 技术 (Share Nothing)
转载:https://blog.csdn.net/kingcat666/article/details/78324678
一、Sharding
Sharding 是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。Shard这个词的意思是“碎片”。如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseShard)。将整个数据库打碎的过程就叫做sharding,可以翻译为分片。
形式上,Sharding可以简单定义为将大数据库分布到多个物理节点上的一个分区方案。每一个分区包含数据库的某一部分,称为一个shard,分区方式可以是任意的,并不局限于传统的水平分区和垂直分区。一个shard可以包含多个表的内容甚至可以包含多个数据库实例中的内容。每个shard被放置在一个数据库服务器上。一个数据库服务器可以处理一个或多个shard的数据。系统中需要有服务器进行查询路由转发,负责将查询转发到包含该查询所访问数据的shard或shards节点上去执行。
二、Scale Out/Scale Up 和 垂直切分/水平拆分
Mysql的扩展方案包括Scale Out和Scale Up两种。
Scale Out(横向扩展)是指Application可以在水平方向上扩展。一般对数据中心的应用而言,Scale out指的是当添加更多的机器时,应用仍然可以很好的利用这些机器的资源来提升自己的效率从而达到很好的扩展性。
Scale Up(纵向扩展)是指Application可以在垂直方向上扩展。一般对单台机器而言,Scale Up值得是当某个计算节点(机器)添加更多的CPU Cores,存储设备,使用更大的内存时,应用可以很充分的利用这些资源来提升自己的效率从而达到很好的扩展性。
MySql的Sharding策略包括垂直切分和水平切分两种。
垂直(纵向)拆分:是指按功能模块拆分,以解决表与表之间的io竞争。比如分为订单库、商品库、用户库...这种方式多个数据库之间的表结构不同。
水平(横向)拆分:将同一个表的数据进行分块保存到不同的数据库中,来解决单表中数据量增长出现的压力。这些数据库中的表结构完全相同。
表结构设计垂直切分。常见的一些场景包括
a). 大字段的垂直切分。单独将大字段建在另外的表中,提高基础表的访问性能,原则上在性能关键的应用中应当避免数据库的大字段
b). 按照使用用途垂直切分。例如企业物料属性,可以按照基本属性、销售属性、采购属性、生产制造属性、财务会计属性等用途垂直切分
c). 按照访问频率垂直切分。例如电子商务、Web 2.0系统中,如果用户属性设置非常多,可以将基本、使用频繁的属性和不常用的属性垂直切分开
表结构设计水平切分。常见的一些场景包括
a). 比如在线电子商务网站,订单表数据量过大,按照年度、月度水平切分
b). Web 2.0网站注册用户、在线活跃用户过多,按照用户ID范围等方式,将相关用户以及该用户紧密关联的表做水平切分
c). 例如论坛的置顶帖子,因为涉及到分页问题,每页都需要显示置顶贴,这种情况可以把置顶贴水平切分开来,避免取置顶帖子时从所有帖子的表中读取
三、分表和分区
分表从表面意思说就是把一张表分成多个小表,分区则是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上。
分表和分区的区别
1,实现方式上
mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件(MyISAM引擎:一个.MYD数据文件,.MYI索引文件,.frm表结构文件)。
2,数据处理上
分表后数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。分区则不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表还是一张表,数据处理还是由自己来完成。
3,提高性能上
分表后,单表的并发能力提高了,磁盘I/O性能也提高了。分区突破了磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
在这一点上,分区和分表的测重点不同,分表重点是存取数据时,如何提高mysql并发能力上;而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
4,实现的难易度上
分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式和分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。 分区实现是比较简单的,建立分区表,跟建平常的表没什么区别,并且对代码端来说是透明的。
分区的适用场景
1. 一张表的查询速度已经慢到影响使用的时候。
2. 表中的数据是分段的
3. 对数据的操作往往只涉及一部分数据,而不是所有的数据
- CREATE TABLE sales (
- id INT AUTO_INCREMENT,
- amount DOUBLE NOT NULL,
- order_day DATETIME NOT NULL,
- PRIMARY KEY(id, order_day)
- ) ENGINE=Innodb
- PARTITION BY RANGE(YEAR(order_day)) (
- PARTITION p_2010 VALUES LESS THAN (2010),
- PARTITION p_2011 VALUES LESS THAN (2011),
- PARTITION p_2012 VALUES LESS THAN (2012),
- PARTITION p_catchall VALUES LESS THAN MAXVALUE);
分表的适用场景
1. 一张表的查询速度已经慢到影响使用的时候。
2. 当频繁插入或者联合查询时,速度变慢。
分表的实现需要业务结合实现和迁移,较为复杂。
四、分表和分库
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库。
与分表策略相似,分库可以采用通过一个关键字取模的方式,来对数据访问进行路由,如下图所示
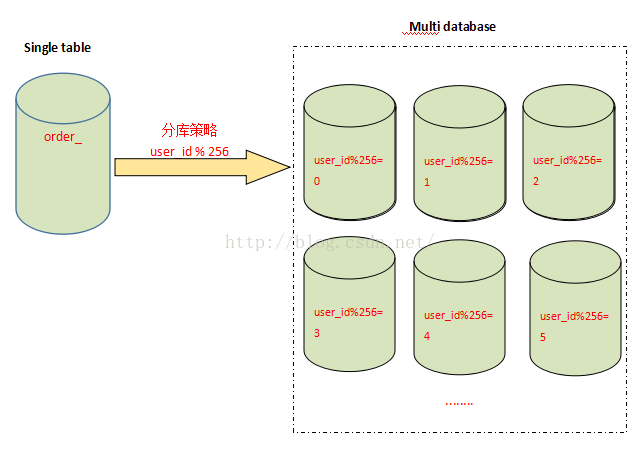
五、分库分表存在的问题
1 事务问题。
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2 跨库跨表的join问题。
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3 额外的数据管理负担和数据运算压力。
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order
by语句就可以搞定,但是在进行分表之后,将需要n个order
by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
解决方案
1. 使用类似JTA提供的分布式事物机制
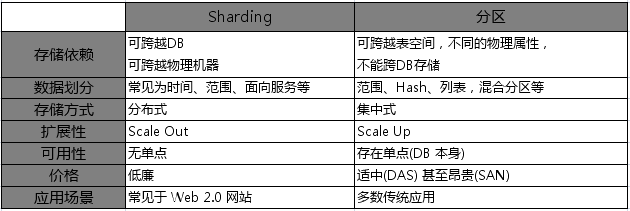
六、分片(Sharding)和分区(Partition)
sharding和partition的区别:
MySql从一窍不通到入门(五)Sharding:分表、分库、分片和分区的更多相关文章
- MySQL性能优化(五):分表
原文:MySQL性能优化(五):分表 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/vbi ...
- 重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践
一.MySQL扩展具体的实现方式 随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量. 关于数据库的扩展主要包括:业务拆分.主从复制.读写分离.数据库分库 ...
- DevExpress XtraReports 入门五 创建交叉表报表
原文:DevExpress XtraReports 入门五 创建交叉表报表 本文只是为了帮助初次接触或是需要DevExpress XtraReports报表的人群使用的,为了帮助更多的人不会像我这样浪 ...
- sharding sphere 分表分库 读写分离
sharding jdbc: sharding sphere 的 一部分,可以做到 分表分库,读写分离. 和 mycat 不同的 是 sharding jdbc 是 一个 jdbc 驱动 在 驱动这个 ...
- 总结下Mysql分表分库的策略及应用
上月前面试某公司,对于mysql分表的思路,当时简要的说了下hash算法分表,以及discuz分表的思路,但是对于新增数据自增id存放的设计思想回答的不是很好(笔试+面试整个过程算是OK过了,因与个人 ...
- 由mysql分区想到的分表分库的方案
在分区分库分表前一定要了解分区分库分表的动机. 对实时性要求比较高的场景,使用数据库的分区分表分库. 对实时性要求不高的场景,可以考虑使用索引库(es/solr)或者大数据hadoop平台来解决(如数 ...
- mycat原理及分表分库入门
1.什么是MyCat: MyCat是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原 ...
- Mycat分表分库
一.Mycat介绍 Mycat 是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的的Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以 ...
- 学会数据库读写分离、分表分库——用Mycat,这一篇就够了!
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
随机推荐
- Java基础【基本数据类型包装类、int与String 之间的相互转换】
为什么会有基本类型包装类? 将基本类型数据类型封装成对象,这样的好处可以在对象中定义更多方法操作该数据. 包装类常用的操作就是用于基本数据类型与字符串之间的转换 问题:int a=100; 为什么不能 ...
- SQL语句执行的顺序机制
From Where Group by Having Select 表达式 Distinct ORDER BY TOP/OFFSET-FETCH
- 解决 Boost安装:fatal error: bzlib.h: No such file or directory 问题
参考: How to install all the boost development libraries? 解决 Boost安装:fatal error: bzlib.h: No such fil ...
- latex 脚注编号也成为超链接
我们用LaTeX写文章时,往往会引用tabularx和hyperref两个包,当我们想让脚注编号也成为超链接以方便阅读时,往往会发现在hyperref包的属性里设置hyperfootnotes=tru ...
- python中常用的模块一
一,常用的模块 模块就是我们将装有特定功能的代码进行归类,从代码编写的单位来看我们的程序,从小到大的顺序: 一条代码<语句块,<代码块(函数,类)<模块我们所写的所有py文件都是模块 ...
- jsp技术和el表达式和jstl技术
注:本文参考黑马视频的讲义 jsp技术 1.jsp脚本 )<%java代码%> ----- 内部的java代码翻译到service方法的内部 )<%=java变量或表达式> - ...
- HAProxy用法详解
一.HAProxy简介 (1)HAProxy 是一款提供高可用性.负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费.快速并且可靠的一种解决方案. HAProx ...
- EditPlus查找替换
换行符\n,记得选择正则表达式 1]正则表达式应用——替换指定内容到行尾解决:① 在替换对话框,查找内容里输入“abc.*”② 同时勾选“正则表达式”复选框,然后点击“全部替换”按钮其中,符号的含义如 ...
- String,StringBuilder区别,一个是常量,一个是可变量
String str="这就是爱的呼唤,这就是爱的奉献!!"; //这个str是不可变的字符串序列,要变会生成新的字符串,原字符串不变,是常量 StringBuilder sBui ...
- sort-桶排序
void list_insert(list<int> &t,int num) { auto iter=t.begin(); for(;iter!=t.end();++iter) { ...