深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing
2018-02-02 21:21:09
Paper: https://openreview.net/pdf/99b7cb0c78706ad8e91c13a2242bb15b7de325ad.pdf
Blog: https://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/
【Abstract】
一个 capsule 是一组神经元,其输出代表了同一个实例的不同属性。capsule network 的每层包括多个 capsule。我们一种 capsule,每个 capsule 拥有一个逻辑单元来表示一个实例是否出现,以及一个 4*4 的矩阵来学习表示实例和视角(姿态)之间的关系。一个 layer 的 capsule 投票给 该 layer 之上的许多不同的 capsules 的 pose matrix,通过用 可训练的视角不变的转换矩阵(trainable viewpoint-invariant transformation matrices)乘以 自身的 pose matrix,来学习表示部分和整体之间的关系(to represent part-whole relationships)。每一个这样子的投票都会被给予一个系数进行加权(each of these votes is weighted by an assignment coefficient)。这些系数可以 用 期望最大化算法(the Expectation-Maximization algorithm)来迭代的进行更新,such that the output of each capsule is routed to a capsule in the layer above that receives a cluster of similar votes。转换矩阵是通过 BP 算法进行更新的,through the unrolled iterations of EM between each pair of adjacent capsule layers. 在 smallNORB data 上,capsule 降低了测试误差,并且也显示了对对抗攻击(adversarial attack)的更好的抵抗能力。
【Introduction】
CNN 是基于一个简单的事实:一个视觉系统需要利用图像中所有位置的相同知识( a vision system needs to use the same knowledge at all locations in the image)。这是通过捆绑特征检测器的权重来实现的,使得在一个位置上学习到的 feature 在其他位置仍然可用。Convolutional capsule 将这个不同位置共享的思路拓展到到包括了 the relationship between an object or object-part and the viewer. capsule 的目标是充分利用潜在的 linearity,既可以处理 视角变换问题,又可以改善 segmentation decisions。
Capsule 利用高维的 coincidence filtering:一个熟悉的物体应该被检测到,通过寻找其 pose matrix 的投票协约(by looking for agreement between votes for its pose matrix)。这些从 parts 的投票已经可以被检测到。A part produces a vote by multiplying its own pose matrix by a learned transformation matrix that represents the viewpoint invariant realtionship between the part and the whole. 随着视角的变化,部分的 和 全局的 pose matrices 将会一致的进行改变,任何来自不同 parts 的投票都会得到坚持。
找到高维的投票紧密聚类,agree in a mist of irrelevant votes,是将 parts 赋予 wholes 解决问题的一种方法。这件事是非平凡的,因为我们不能在高维度的 pose space 像 低纬度转换空间那样,可以进行卷积。为了解决这个挑战,我们利用一个快速的迭代过程,称为:“routing by agreement”,that updates the probability with which a part is assigned to a whole based on the proximity of the vote coming from that part to the votes coming from other parts that are assigned to that whole。 这是一个有效的分割原则(segmentation principle),允许熟悉形状的知识 来引导分割,而不是仅仅利用 low-level cues,例如:在色彩或者速度上的近邻或者一致。 capsule 和 标准的神经网络之间的一个重大区别是:一个 capsule 的激活是基于多个到来的姿态估计的对比(the acitivation of a capsule is based on a comparion between multiple incoming pose predictions);而 标准的神经网络是基于 a single acitivity vector 和 a learned weight vector 之间的对比。
【How Capsule Work】
神经网络通常利用简单的 非线性函数 到线性 filter 的 scalar output 上。他们可能也会用 softmax non-linearities 来将 a whole vector of logits 转换为 a vector of probabilities。Capsule 利用一个更加复杂的非线性函数,将 the whole set of activation probabilities and poses of the capsules in one layer 转换为 the acitivation probilities and poses of capsules in the next layer。
一个 capsule network 是由多层的 capsule 构成的。第 L 层的 capsule 集合表示为 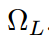 。每一个 capsule 有一个 4*4 的 pose matrix,M,以及 一个激活概率,a。他们像标准的神经网络中的激活函数一样:他们依赖于当前的输入,并且不会被存储。第L层 的每一个 capsule i 和 第 L+1 层的每一个 capsule 是一个 4*4 可训练的转换矩阵(trainable transformation matrix),Wij。这些 Wij 以及 连个学习到的 biases,是仅存的参数。capsule i 的 pose matrix 通过 Wij 进行转换,来对 capsule j 的 pose matrix 执行一个投票 Vij = Mi Wij。第 L+1 层的 capsules 的 poses 和 activations 通过利用 non-linear routing procedure 来计算,which gets as input Vij and ai for all i, j。
。每一个 capsule 有一个 4*4 的 pose matrix,M,以及 一个激活概率,a。他们像标准的神经网络中的激活函数一样:他们依赖于当前的输入,并且不会被存储。第L层 的每一个 capsule i 和 第 L+1 层的每一个 capsule 是一个 4*4 可训练的转换矩阵(trainable transformation matrix),Wij。这些 Wij 以及 连个学习到的 biases,是仅存的参数。capsule i 的 pose matrix 通过 Wij 进行转换,来对 capsule j 的 pose matrix 执行一个投票 Vij = Mi Wij。第 L+1 层的 capsules 的 poses 和 activations 通过利用 non-linear routing procedure 来计算,which gets as input Vij and ai for all i, j。
这个非线性的过程是 the Expectation-Maximization procedure 的一个版本。它迭代的调整 mean,variance,and 第L+1层的 capsules 的激活概率,以及 assignment probabilities between all i, j。
【Using EM for routing-by-agreement】
让我们假设我们已经决定了在一层的所有 capsule 的 the poses 以及 acitivation probabilities,现在我们想要决定激活一层中的那些 capsules,以及 如何将 激活的 low-level capsule 赋予到 一个激活的 high-level capsule 上。一个 high-level layer 的每个 capsule,对应了一个 Gaussian,the lower layer 的每一个激活capsule 的 pose 对应了一个 data-point。
利用最小化描述长度的原则,我们可以决定是否去激活一个 high-level capsule。
Choice 0:如果我们不去激活他,我们必须付出一个 fixed cost per data-point,以此来描述 the poses of all the lower-level capsules that are assigned to the higher-level capsule。
Choice 1:if we do activate the higher-level capsule we must pay a fixed cost for coding its mean and variance and the fact that it is active and then pay additional costs, pro-rated by the assignment probabilities, for describing the discrepancies between the lower-level means and the values predicted for them when the mean of the higher-level capsule is used to predict them via the inverse of the transformation matrix.
一个更加简单的方法来计算描述一个 datapoint 的 cost 的方法是:use the negative log probability density of that datapoint's vote under the Gaussian distribution fitted by whatever higher-level capsule it gets assigned to (在高斯分布的情况下,数据点投票的 负的 log 概率密度)。Choice 0 和 Choice 1 之间代价的差异,然后通过每一次迭代的 logistic function 来决定 high-level capsule's 激活概率。
利用我们对 choice 1 的有效估计,解释 a whole data-point i 的代价,通过利用 capsule j 拥有一个坐标对齐的 covariance matrix,就是简单的解释 vote Vij 的每一个维度 h 的代价的求和。这就是简单的 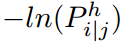 ,其中,输入 P 是第 h 个成分的概率密度(the probability density of the h-th component of the vectorized vote Vij under j's Gaussian model for dimension h )。
,其中,输入 P 是第 h 个成分的概率密度(the probability density of the h-th component of the vectorized vote Vij under j's Gaussian model for dimension h )。
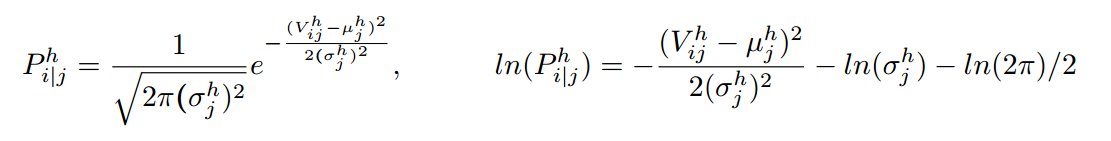
累加单个维度 h 的所有 lower-level capsules,我们有:
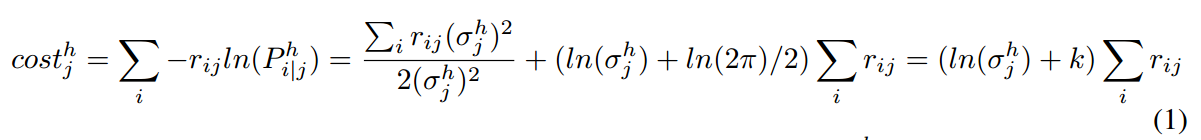
其中,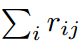 是 赋予给 j 的数据量,k 是常数,$V^h_{ij}$ 是 Vij 的维度 h 的值。Turning on j increases the description length for the means of the lower-level capsules assigned to j by the sum of the cost over all dimensions, so we define the acitivation function of capsules j to be:
是 赋予给 j 的数据量,k 是常数,$V^h_{ij}$ 是 Vij 的维度 h 的值。Turning on j increases the description length for the means of the lower-level capsules assigned to j by the sum of the cost over all dimensions, so we define the acitivation function of capsules j to be:
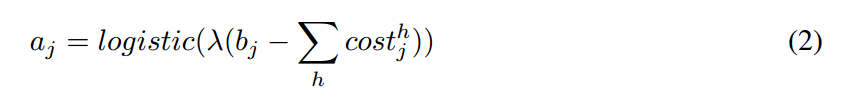
其中,$-b_j$ 代表了描述 capsule j 的 mean 和 variance 代价。
为了能够定下来 the pose parameters 和 第 L+1 层的 capsules 的激活函数,我们运行几次迭代 EM 算法(通常是 3次)。这个通过整个 capsule layer 的非线性过程,是一种用 EM 算法进行 cluter finding 的形式,我们称之为:EM Routing 。

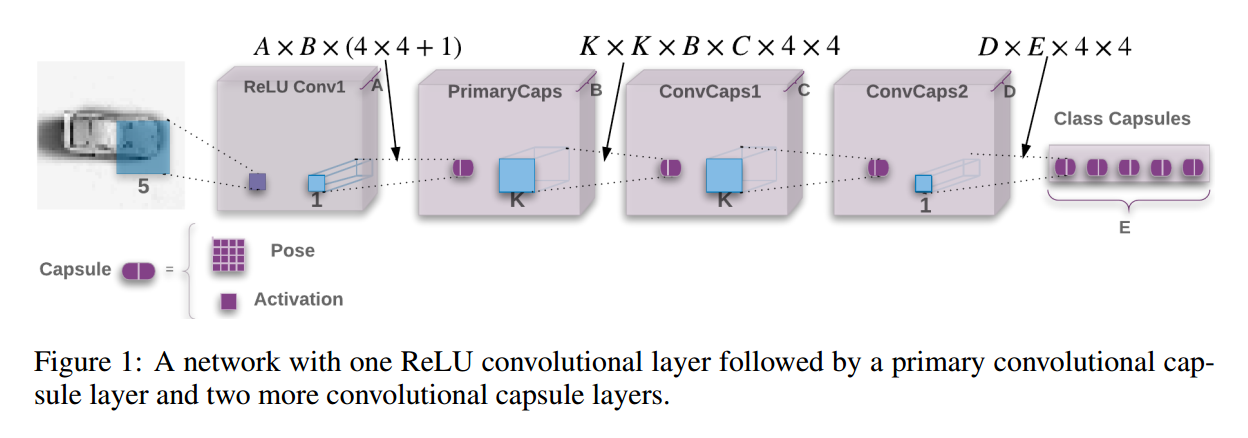
【The Capsules Architecture】
Spread Loss:
为了使得训练尽可能对模型的超参数不敏感,我们利用 “spread loss” 来直接最大化 the activation of the target class 和 the activation of the other classes 之间的 gap。如果激活错了类别,$a_i$,接近 margin,m:
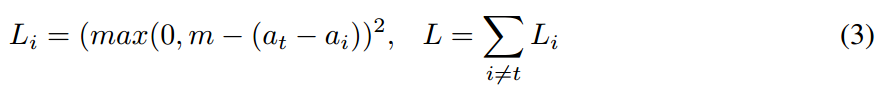
Blog: “Understanding Matrix capsules with EM Routing (Based on Hinton's Capsule Networks)”
我们首先覆盖 the matrix capsules,用 EM (Expectation Maximization)routing 来分类带有不同视角的图像(to classify images with different viewpoints)。
CNN Challengs:
标准 CNN 对空间关系并没有处理的很好,然后我们在这里会讨论怎么用 capsule network 来解决这些不足。
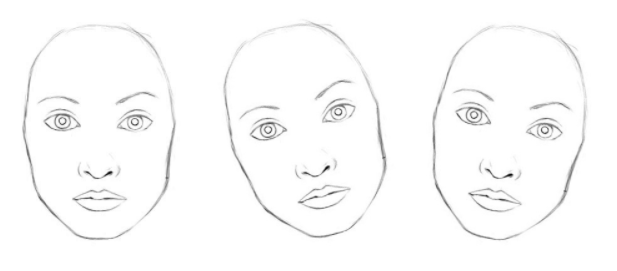
概念上来说,CNN 训练神经网络来处理不同的特征角度(different feature orientations (0°, 20°, -20°)),with a top level face detection neuron.
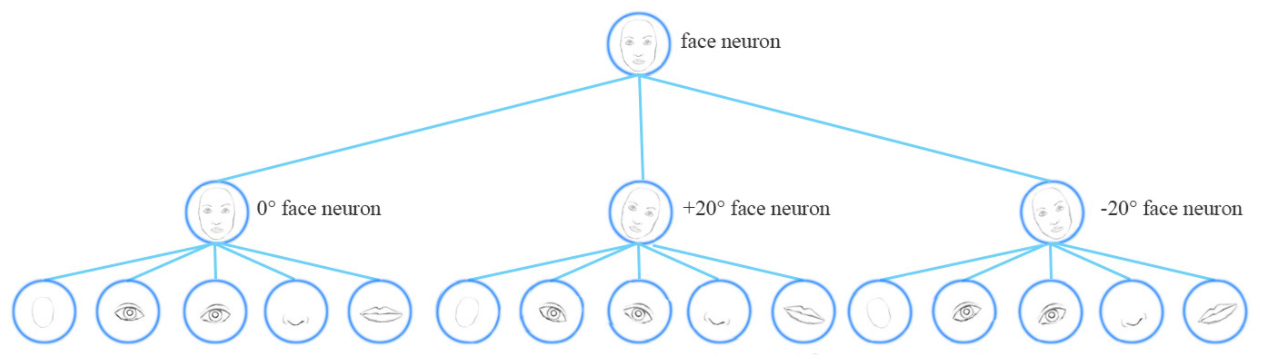
为了解决这些问题,我们添加更多的 卷积层 以及 特征图。然而,这种方法尝试记住 dataset,而不是 generalize a solution。这需要大量的训练数据来处理不同的视角来避免 overfitting。但是,像小孩这样都可以以很少的样本,就可以识别不同的数字。我们现有的 deep learning models,包括 CNN,都无法很好的用好这些数据(inefficient in utilizing datapoints)。
Adversaires:
CNN 对简单的移动,旋转,或者 resize 单独的 feature,也并没有很好的处理能力。CNN 这个时候,依然会认为下面这个图是一张 human face: 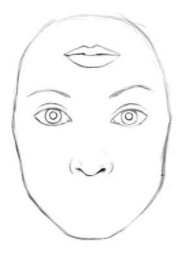
另外,CNN 针对 对抗样本 也无计可施,典型的案例如下:

Capsule:
A capsule captures the likeliness of a feature and its variant. (一个 capsule 捕获了一个特征 及其 变种的似然性)。 所以,the capsule 不仅仅检测 a feature,也会被训练来学习和检测其变种(variants)。
例如,同样的 network layer 也可以检测按照顺时针旋转的 face。
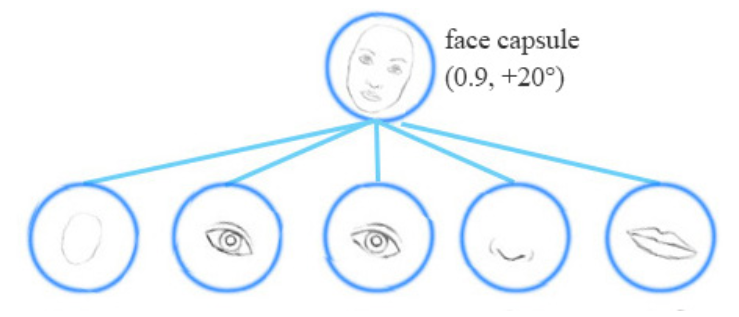
Equivariance:
Equivariance is the detection of objects that can transform to each other。
Matrix capsule:
一个矩阵胶囊(matrix capsule)捕获了 the activation(likeliness)similar to that of a neuron, but also captures a 4*4 pose matrix。在计算机图形学中,一个 pose matrix 定义了一个目标 转化 和 旋转,等价于 物体视角的变换。
例如,第二行的物体都和第一行相同,但仅仅视角不同而已。在 matrix capsule 中,我们训练一个模型来捕获 the pose information(orientation,azimuths etc ...)。当然,这也仅仅和其他 deep learning 方法一样,这就是我们的直觉,而并没有保证。

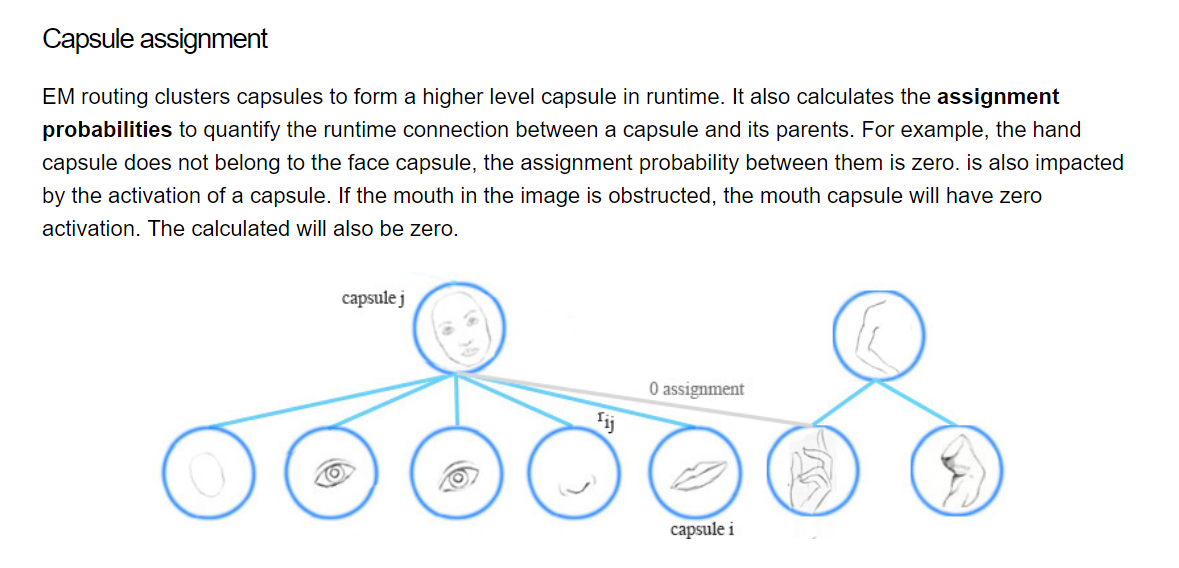
EM(Expectation Maximization)routing 的目标是:group capsules to form a part-whole relationship using a clustering technique (EM)。
用聚类的方法来构建 部分-整体关系 。。。
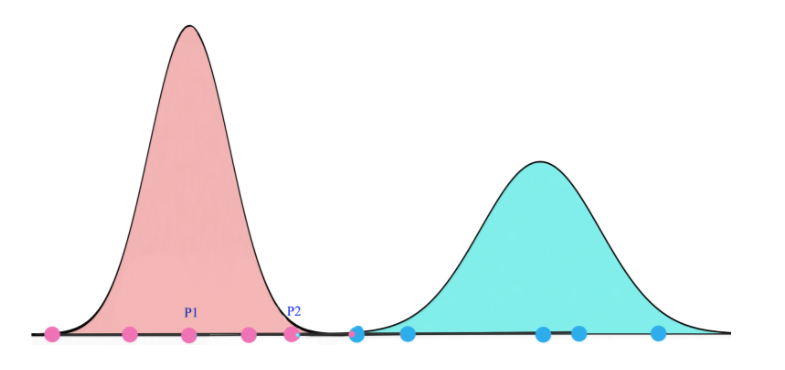
在机器学习中,我们用 EM 聚类方法来 聚类 datapoints 到 高斯分布(we use EM clustering to cluster datapoints into Gaussian distributions)。
例如,我们聚类 datapoints 到 两个 clusters by two gaussian distributions。然后,我们通过对应的 高斯分布 来表示 datapoints:
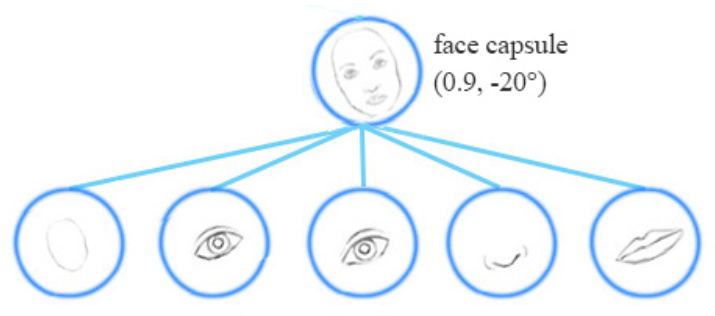
In the face detection example, each of the mouth, eyes and nose detection capsules in the lower layer makes predictions (votes) on the pose matrices of its possible parent capsules. Each vote is a predicted value for a parent capsule’s pose matrix, and it is computed by multiplying its own pose matrix with a transformation matrix that we learn from the training data.
我们采用 the EM routing 来将多个 capsules 归纳为 parent capsule:

也就是说,如果 鼻子,嘴巴,眼睛胶囊 都投票给 一个相似的 pose matrix value,我们将其聚类以构成 parent capsule:the face capsule
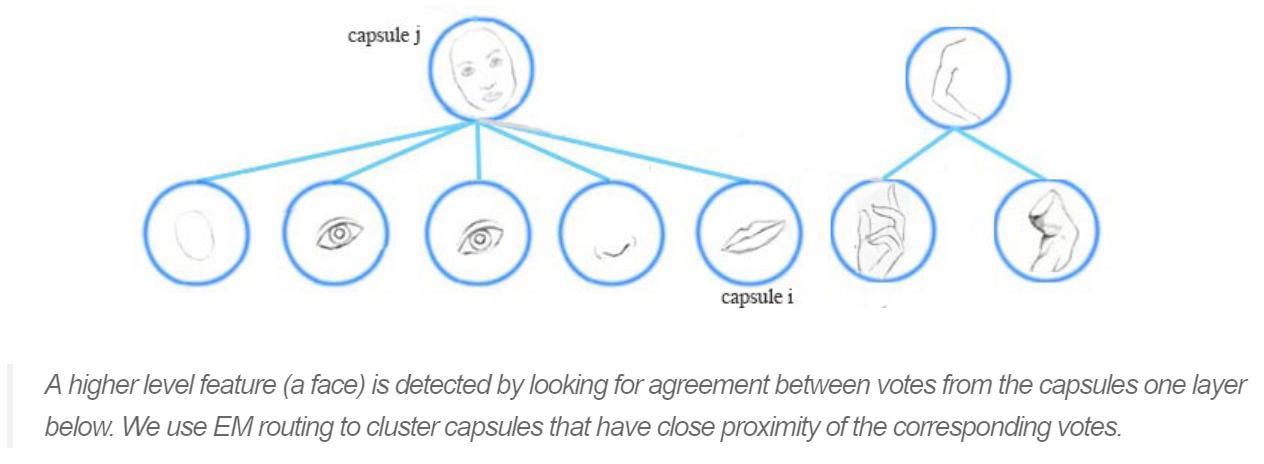
一个高层的特征(a face)被检测到,通过寻找下一层胶囊的投票所构成的 agreement。我们用 EM routing 来聚类 capsules,that have close proximity of the corresponding votes。
Gaussian mixture model & Expectation Maximization (EM)
我们先看看什么是 EM。一个高斯混合模型 将 datapoints 聚类到:混合高斯分布(a mixture of Gaussian distributions)。下面,我们将 datapoints 聚类到黄色 和 红色 cluster:
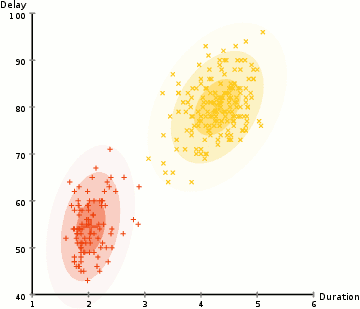
关于 EM 算法(Expectation Maximization Algorithm)的具体介绍,可以参考:https://www.cnblogs.com/pinard/p/6912636.html
Using EM for Routing-by-Agreement
一个高层的特征(如:a face)通过来自底层的 capsule 的投票来被检测到。一个给 parent capsule 的投票是通过:将该胶囊的姿态矩阵(pose matrix) 和 视角不变转换(viewpoint invariant transformation) 相乘得到的(by multipling the pose matrix of capsule with a viewpoint invariant transformation)。
他不但学习到了 a face 是由什么组成的,而且也要确保在某些转换之后 the parent capsule 的姿态信息(the pose information)与其 sub-components 相匹配。
下面是 routing-by-agreement 的可视化。我们将有相似投票的 capsules 进行分组,after transform the pose and with a viewpoint invariant transformation。
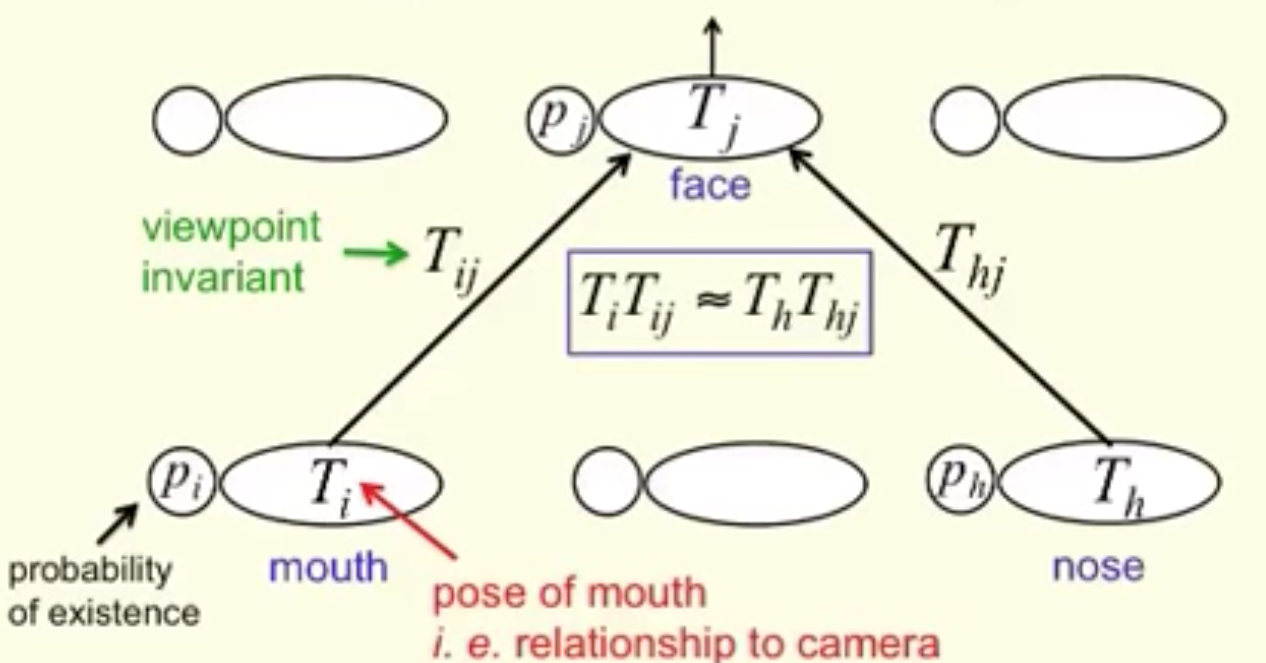
即使视角可能改变,the pose matrices 和 the votes 可能也相应的做出改变。在我们的例子当中,当 face 被旋转之后,投票的位置可能由红色点,变成了 粉红色的点。除非,EM routing 是基于近邻的,所以 EM routing 仍然可以成功的聚类相同的 children capsules。所以,the transformation matrices 对于物体的不同视角,却仍然是相同的:viewpoint invariant。对于不同的视角,我们仅仅需要 one set of the transformation matrices 以及 one parent capsule。

深度学习课程笔记(十二) Matrix Capsule的更多相关文章
- 深度学习课程笔记(二)Classification: Probility Generative Model
深度学习课程笔记(二)Classification: Probility Generative Model 2017.10.05 相关材料来自:http://speech.ee.ntu.edu.tw ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十)Q-learning (Continuous Action)
深度学习课程笔记(十)Q-learning (Continuous Action) 2018-07-10 22:40:28 reference:https://www.youtube.com/watc ...
- 深度学习课程笔记(七):模仿学习(imitation learning)
深度学习课程笔记(七):模仿学习(imitation learning) 2017.12.10 本文所涉及到的 模仿学习,则是从给定的展示中进行学习.机器在这个过程中,也和环境进行交互,但是,并没有显 ...
- 深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble 2017.10.06 材料来自: 首先提到的是 Bagging 的方法: 我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果.例如: ...
随机推荐
- 深度解读 AlphaGo 算法原理
http://blog.csdn.net/songrotek/article/details/51065143 http://blog.csdn.net/dinosoft/article/detail ...
- (Review cs231n) Gradient Calculation and Backward
---恢复内容开始--- 昨日之补充web. 求解下图的梯度的流动,反向更新参数的过程,表示为 输入与损失梯度的关系,借助链式法则,当前输入与损失之间的梯度关系为局部梯度乘以后一层的梯度. ---恢复 ...
- 转:【专题六】UDP编程
引用: 前一个专题简单介绍了TCP编程的一些知识,UDP与TCP地位相当的另一个传输层协议,它也是当下流行的很多主流网络应用(例如QQ.MSN和Skype等一些即时通信软件传输层都是应用UDP协议的) ...
- JustOj 1936: 小明A+B
题目描述 小明今年3岁了, 现在他已经能够认识100以内的非负整数, 并且能够进行100以内的非负整数的加法计算. 对于大于等于100的整数, 小明仅保留该数的最后两位进行计算, 如果计算结果大于等于 ...
- 常用正则表达式爬取网页信息及HTML分析总结
Python爬取网页信息时,经常使用的正则表达式及方法. 1.获取<tr></tr>标签之间内容 2.获取<a href..></a>超链接之间内容 3 ...
- easyui dialog 和 dategrid相关设置与应用
1 dialog一些参数 可以进行文件上传等操作closed:true:定义初始状态为关闭:modal:true:对话框被打开时,会有一个modal-mask,使得对话框底部的内容被一个层覆盖,不 ...
- Java程序员秋招面经大合集(BAT美团网易小米华为中兴等)
Cvte提前批 阿里内推 便利蜂内推 小米内推 金山wps内推 多益网络 拼多多学霸批 搜狗校招 涂鸦移动 中国电信it研发中心 中兴 华为 苏宁内推 美团内推 百度 腾讯 招商银行信用卡 招银网络科 ...
- Linux 下wifi 驱动开发(四)—— USB接口WiFi驱动浅析
源: Linux 下wifi 驱动开发(四)—— USB接口WiFi驱动浅析
- ELK学习笔记之F5利用ELK进行应用数据挖掘系列(1)-HTTP
0x00 概述 F5 BIGIP从应用角度位于网络结构的关键咽喉位置,可获取所有应用的流量,针对流量执行L7层处理,即便是TLS加密的流量也可以通过F5进行SSL offload.通过F5可以统一获取 ...
- js DOM常见事件
js事件命名为on+动词 1.onclick事件,点击鼠标时触发,ondbclick双击事件 <h1 onclick="this.innerHTML='点击后文本'"> ...