(转) Let’s make an A3C: Theory
本文转自:https://jaromiru.com/2017/02/16/lets-make-an-a3c-theory/
Let’s make an A3C: Theory
1. Theory
2. Implementation (TBD)
Introduction
Policy Gradient Methods is an interesting family of Reinforcement Learning algorithms. They have a long history1, but only recently were backed by neural networks and had success in high-dimensional cases. A3C algorithm was published in 2016 and can do better than DQN with a fraction of time and resources2.
In this series of articles we will explain the theory behind Policy Gradient Methods, A3C algorithm and develop a simple agent in Python.
It is very recommended to have read at least the first Theory article from Let’s make a DQNseries which explains theory behind Reinforcement Learning (RL). We will also make comparison to DQN and make references to these older series.
Background
Let’s review the RL basics. An agent exists in an environment, which evolves in discrete time steps. Agent can influence the environment by taking an action a each time step, after which it receives a reward r and an observed state s. For simplification, we only consider deterministic environments. That means that taking action a in state s always results in the same state s’.
Although these high level concepts stay the same as in DQN case, they are some important changes in Policy Gradient (PG) Methods. To understand the following, we have to make some definitions.
First, agent’s actions are determined by a stochastic policy π(s). Stochastic policy means that it does not output a single action, but a distribution of probabilities over actions, which sum to 1.0. We’ll also use a notation π(a|s) which means the probability of taking action a in state s.
For clarity, note that there is no concept of greedy policy in this case. The policy π does not maximize any value. It is simply a function of a state s, returning probabilities for all possible actions.
We will also use a concept of expectation of some value. Expectation of value X in a probability distribution P is:

where 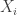

The important thing here is that if we had a pool of values X, ratio of which was given by P, and we randomly picked a number of these, we would expect the mean of them to be 
We’ll use the concept of expectation right away. We define a value function V(s) of policy π as an expected discounted return, which can be viewed as a following recurrent definition:

Basically, we weight-average the 
Action-value function Q(s, a) is on the other hand defined plainly as:

simply because the action is given and there is only one following s’.
Now, let’s define a new function A(s, a) as:

We call A(s, a) an advantage function and it expresses how good it is to take an action a in a state s compared to average. If the action a is better than average, the advantage function is positive, if worse, it is negative.
And last, let’s define 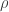


Policy Gradient
When we built the DQN agent, we used a neural network to approximate the Q(s, a) function. But now we will take a different approach. The policy π is just a function of state s, so we can approximate directly that. Our neural network with weights 

In practice, we can take an action according to this distribution or simply take the action with the highest probability, both approaches have their pros and cons.
But we want the policy to get better, so how do we optimize it? First, we need some metric that will tell us how good a policy is. Let’s define a function 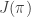

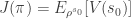
We can agree that this metric truly expresses, how good a policy is. The problem is that it’s hard to estimate. Good news are, that we don’t have to.
What we truly care about is how to improve this quantity. If we knew the gradient of this function, it would be trivial. Surprisingly, it turns out that there’s easily computable gradient of

I understand that the step from 
The formula might seem intimidating, but it’s actually quite intuitive when it’s broken down. First, what does it say? It informs us in what direction we have to change the weights of the neural network if we want the function
Let’s look at the right side of the expression. The second term inside the expectation, 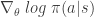
The first term, 
Both terms are inside an expectation over state and action distribution of π. However, we can’t exactly compute it over every state and every action. Instead, we can use that nice property of expectation that the mean of samples with these distributions lays near the expected value.
Fortunately, running an episode with a policy π yields samples distributed exactly as we need. States encountered and actions taken are indeed an unbiased sample from the
That’s great news. We can simply let our agent run in the environment and record the (s, a, r, s’) samples. When we gather enough of them, we use the formula above to find a good approximation of the gradient
Actor-critic
One thing that remains to be explained is how we compute the A(s, a) term. Let’s expand the definition:

A sample from a run can give us an unbiased estimate of the Q(s, a) function. We can also see that it is sufficient to know the value function V(s) to compute A(s, a).
The value function can also be approximated by a neural network, just as we did with action-value function in DQN. Compared to that, it’s easier to learn, because there is only one value for each state.
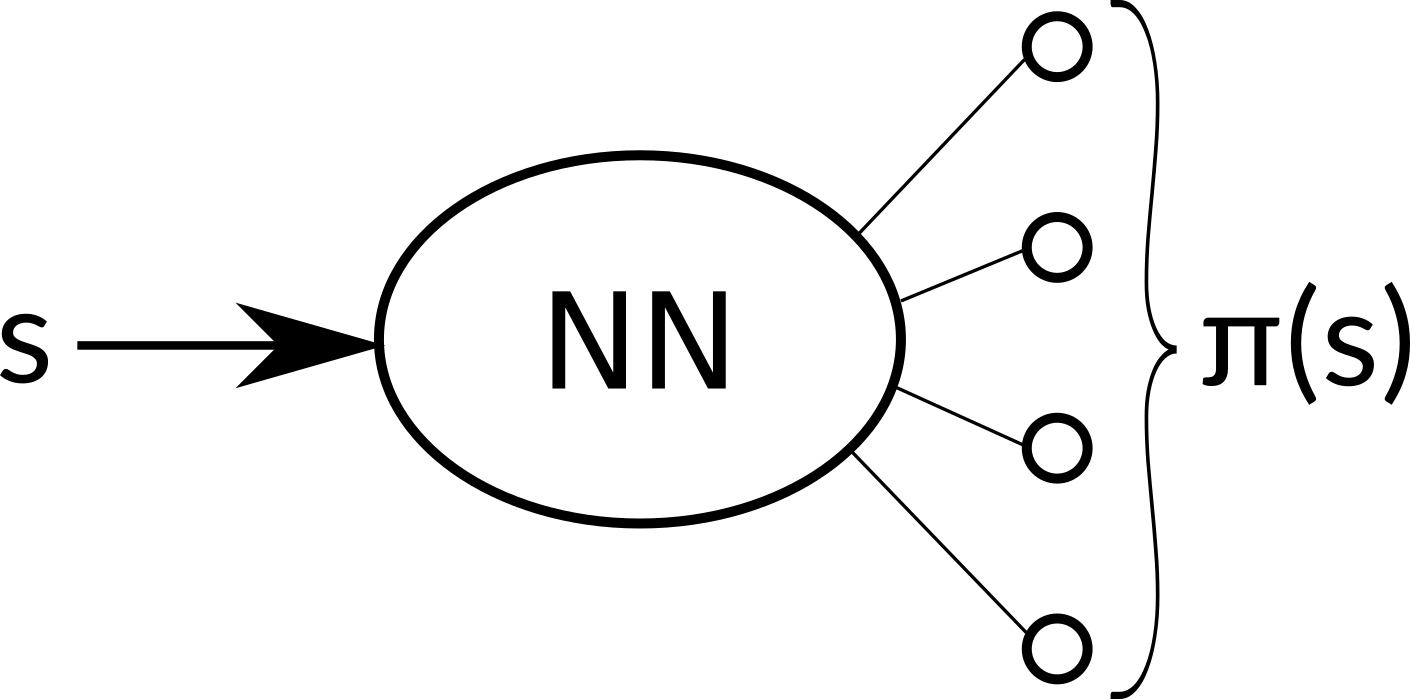
What’s more, we can use the same neural network for estimating π(s) to estimate V(s). This has multiple benefits. Because we optimize both of these goals together, we learn much faster and effectively. Separate networks would very probably learn very similar low level features, which is obviously superfluous. Optimizing both goals together also acts as a regularizing element and leads to a greater stability. Exact details on how to train our network will be explained in the next article. The final architecture then looks like this:
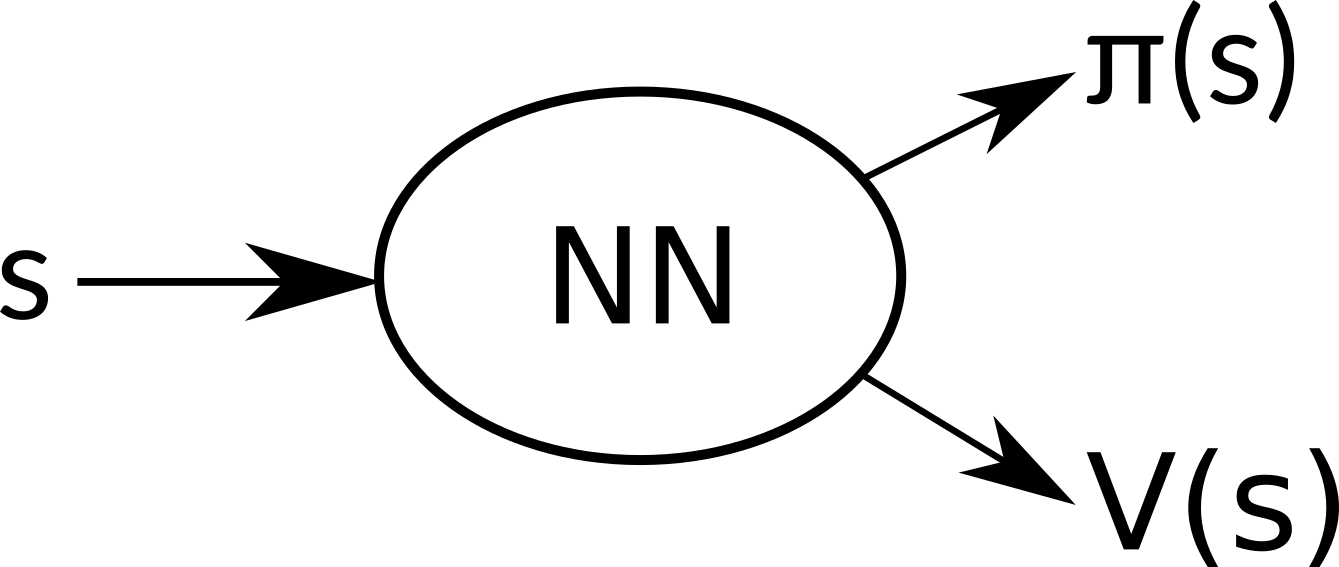
Our neural network share all hidden layers and outputs two sets – π(s) and V(s).
So we have two different concepts working together. The goal of the first one is to optimize the policy, so it performs better. This part is called actor. The second is trying to estimate the value function, to make it more precise. That is called critic. I believe these terms arose from the Policy Gradient Theorem:
The actor acts, and the critic gives insight into what is a good action and what is bad.
Parallel agents
The samples we gather during a run of an agent are highly correlated. If we use them as they arrive, we quickly run into issues of online learning. In DQN, we used a technique named Experience Replay to overcome this issue. We stored the samples in a memory and retrieved them in random order to form a batch.
But there’s another way to break this correlation while still using online learning. We can run several agents in parallel, each with its own copy of the environment, and use their samples as they arrive. Different agents will likely experience different states and transitions, thus avoiding the correlation2. Another benefit is that this approach needs much less memory, because we don’t need to store the samples.
This is the approach the A3C algorithm takes. The full name is Asynchronous advantage actor-critic (A3C) and now you should be able to understand why.
Conclusion
We learned the fundamental theory behind PG methods and will use this knowledge to implement an agent in the next article. We will explain how to use the gradients to train the neural network with our familiar tools, Python, Keras and newly TensorFlow.
References
- Williams, R., Simple statistical gradient-following algorithms for connectionist reinforcement learning, Machine Learning, 1992
- Mnih, V. et al., Asynchronous methods for deep reinforcement learning, ICML, 2016
- Sutton, R. et al., Policy Gradient Methods for Reinforcement Learning with Function Approximation, NIPS, 1999
- Silver, D., Policy Gradient Methods, https://www.youtube.com/watch?v=KHZVXao4qXs, 2015
Post navigation
Leave a Reply

(转) Let’s make an A3C: Theory的更多相关文章
- Introduction to graph theory 图论/脑网络基础
Source: Connected Brain Figure above: Bullmore E, Sporns O. Complex brain networks: graph theoretica ...
- 博弈论揭示了深度学习的未来(译自:Game Theory Reveals the Future of Deep Learning)
Game Theory Reveals the Future of Deep Learning Carlos E. Perez Deep Learning Patterns, Methodology ...
- Understanding theory (1)
Source: verysmartbrothas.com It has been confusing since my first day as a PhD student about theory ...
- Machine Learning Algorithms Study Notes(3)--Learning Theory
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- Java theory and practice
This content is part of the series: Java theory and practice A brief history of garbage collection A ...
- CCJ PRML Study Note - Chapter 1.6 : Information Theory
Chapter 1.6 : Information Theory Chapter 1.6 : Information Theory Christopher M. Bishop, PRML, C ...
- 信息熵 Information Theory
信息论(Information Theory)是概率论与数理统计的一个分枝.用于信息处理.信息熵.通信系统.数据传输.率失真理论.密码学.信噪比.数据压缩和相关课题.本文主要罗列一些基于熵的概念及其意 ...
- Computer Science Theory for the Information Age-4: 一些机器学习算法的简介
一些机器学习算法的简介 本节开始,介绍<Computer Science Theory for the Information Age>一书中第六章(这里先暂时跳过第三章),主要涉及学习以 ...
- Computer Science Theory for the Information Age-1: 高维空间中的球体
高维空间中的球体 注:此系列随笔是我在阅读图灵奖获得者John Hopcroft的最新书籍<Computer Science Theory for the Information Age> ...
随机推荐
- Spring NoSuchBeanDefinitionException
转http://www.baeldung.com/spring-nosuchbeandefinitionexception 1. Overview In this article, we are di ...
- golang学习笔记19 用Golang实现以太坊代币转账
golang学习笔记19 用Golang实现以太坊代币转账 在以太坊区块链中,我们称代币为Token,是以太坊区块链中每个人都可以任意发行的数字资产.并且它必须是遵循erc20标准的,至于erc20标 ...
- linux 环境RPM 安装MYSQL5.6
linux 环境RPM 安装MYSQL5.6 系统环境 CentOS7.2 1.关闭selinux 服务[SELinux是一种基于域-类型 模型(domain-type)的强制访问控制(MAC)安全系 ...
- 分页的模块layui
//调用分页模块 var laypage = layui.laypage; //分页的配置项 laypage.render({ elem:"page",//(指向存放分页的容器,值 ...
- 大数据自学6-Hue集成环境操作Hbase
上一章讲过,Hue集成环境是可以直接操作Hbase,但是公司的环境一直报错,虽然也可以透过写代码访问Hbase,但是看到Hue环境中无法访问,还是觉得不爽,因此决定再花些力气找找原因. 找原因要先查L ...
- Python进阶【第九篇】装饰器
什么是装饰器 装饰器本身就是函数,并且为其他函数添加附加功能 装饰器的原则:1.不修改被装饰对象的源代码 2.不修改被装饰对象的调用方式装饰器=高阶函数+函数嵌套+闭包 # res=timmer(t ...
- gradle 定义打包后的项目名
war { archiveName 'ROOT.war' } 或 task makeWar(type:org.gradle.api.tasks.bundling.War) { //指定生成的jar名 ...
- 2017第十三届湖南省省赛A - Seating Arrangement CSU - 1997
Mr. Teacher老师班上一共有n个同学,编号为1到n. 在上课的时候Mr. Teacher要求同学们从左至右按1, 2, …, n的顺序坐成一排,这样每个同学的位置是固定的,谁没来上课就一目了然 ...
- SQL介绍
SQL,即structured query language,结构化查询语言,是一种对关系型数据库中的数据进行管理和操作的语言方法,SQL包括6个部分 DQL:数据查询语言,最常用的为select,其 ...
- MD5算法详解
MD5是什么 message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法.在下载一下东西时,经常在一些压缩包属性里,看到md5值.而且这个下 ...