MySQL— pymysql and SQLAlchemy
目录
一、pymysql
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。
1. 下载安装
#在终端直接运行
pip3 install pymysql
2. 使用操作
a. 执行SQL
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='t1')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回受影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,))
# 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
b. 获取新创建数据自增ID
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='t1')
cursor = conn.cursor()
cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
conn.commit() # 获取最新自增ID
new_id = cursor.lastrowid cursor.close()
conn.close()
c. 获取查询数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts")
# 获取第一行数据
row_1 = cursor.fetchone()
# 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如:
- cursor.scroll(1,mode='relative') # 相对当前位置移动
- cursor.scroll(2,mode='absolute') # 相对绝对位置移动
d. fetch数据类型
关于默认获取的数据是元组类型,如果想要获得字典类型的数据,即:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='', db='t1')
# 游标设置为字典类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
r = cursor.execute("call p1()")
result = cursor.fetchone()
conn.commit()
cursor.close()
conn.close()
二、SQLAlchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
1. 下载安装
#在终端直接运行
pip3 install SQLAlchemy
2. SQLAlchemy依赖关系
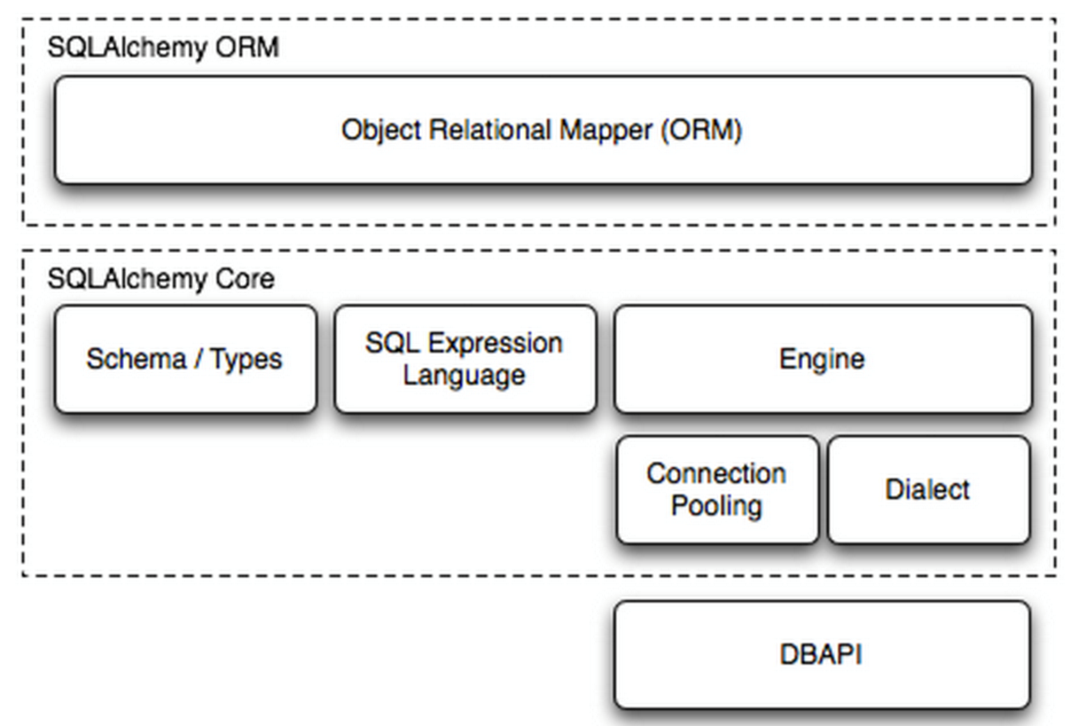
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
3. ORM功能使用
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine #表明依赖关系并创建连接,最大连接数为5
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5)
Base = declarative_base()
# 创建单表
class Users(Base):
__tablename__ = 'users' # 表名
id = Column(Integer, primary_key=True,autoincrement=True) # id列,主键自增
name = Column(String(32)) # name列
extra = Column(String(16)) # extra列
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 创建联合唯一索引
Index('ix_id_name', 'name', 'extra'), # 创建普通索引
)
# 一对多
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True)
caption = Column(String(50), default='red', unique=True)
class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
favor_id = Column(Integer, ForeignKey("favor.nid")) # 创建外键
# 多对多
class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
port = Column(Integer, default=22)
class Server(Base):
__tablename__ = 'server'
id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False)
class ServerToGroup(Base):
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id')) # 创建外键
group_id = Column(Integer, ForeignKey('group.id')) # 创建外键
def init_db():
Base.metadata.create_all(engine)
def drop_db():
Base.metadata.drop_all(engine)
注:设置外键的另一种方式 ForeignKeyConstraint(['other_id'], ['othertable.other_id'])
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) Base = declarative_base() # 创建单表
class Users(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String(32))
extra = Column(String(16)) __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'),
Index('ix_id_name', 'name', 'extra'),
) def __repr__(self):
return "%s-%s" %(self.id, self.name) # 一对多
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True)
caption = Column(String(50), default='red', unique=True) def __repr__(self):
return "%s-%s" %(self.nid, self.caption) class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
favor_id = Column(Integer, ForeignKey("favor.nid"))
# 与生成表结构无关,仅用于查询方便
favor = relationship("Favor", backref='pers') # 多对多
class ServerToGroup(Base):
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id'))
group_id = Column(Integer, ForeignKey('group.id'))
group = relationship("Group", backref='s2g')
server = relationship("Server", backref='s2g') class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
port = Column(Integer, default=22)
# group = relationship('Group',secondary=ServerToGroup,backref='host_list') class Server(Base):
__tablename__ = 'server' id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False) def init_db():
Base.metadata.create_all(engine) def drop_db():
Base.metadata.drop_all(engine) Session = sessionmaker(bind=engine)
session = Session()
表结构 + 数据库连接
b.1 增
#单条增加
obj = Users(name="alex0", extra='sb')
session.add(obj) #多条增加
session.add_all([
Users(name="alex1", extra='sb'),
Users(name="alex2", extra='sb'),
]) #提交
session.commit()
b.2 删
#先查询到要删除的记录,再delete
session.query(Users).filter(Users.id > 2).delete()
session.commit()
b.3 改
#先查询,再更新
session.query(Users).filter(Users.id > 2).update({"name" : ""}) # 直接更改
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + ""}, synchronize_session=False) # 字符串拼接
session.query(Users).filter(Users.id > 2).update({"num": Users.num + 1}, synchronize_session="evaluate") # 数字相加
session.commit()
b.4 查
ret = session.query(Users).all()
ret = session.query(Users.name, Users.extra).all()
ret = session.query(Users).filter_by(name='alex').all()
ret = session.query(Users).filter_by(name='alex').first() ret = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(User.id).all() ret = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='ed').all()
b.5 其它
# 条件
ret = session.query(Users).filter_by(name='alex').all() # 条件内为关键字表达式
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all() # 条件内为SQL表达式
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all() # between
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all() # in
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() # not in
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all() # 子查询条件 from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() # and
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() # or
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all() # 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all() # e开头
ret = session.query(Users).filter(~Users.name.like('e%')).all() # 非e开头 # 限制
ret = session.query(Users)[1:2] # 相当于limit # 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组
from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all() ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() # 笛卡儿积连表
ret = session.query(Person).join(Favor).all() # 默认内连 inner join
ret = session.query(Person).join(Favor, isouter=True).all() # 左连 # 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
参考资料:
1. Python开发【第十九篇】:Python操作MySQL
MySQL— pymysql and SQLAlchemy的更多相关文章
- 【转】MySQL— pymysql and SQLAlchemy
[转]MySQL— pymysql and SQLAlchemy 目录 一.pymysql 二.SQLAlchemy 一.pymysql pymsql是Python中操作MySQL的模块,其使用方法和 ...
- Flask学习笔记:数据库ORM操作MySQL+pymysql/mysql-python+SQLAlchemy/Flask-SQLAlchemy
Python中使用sqlalchemy插件可以实现ORM(Object Relationship Mapping,模型关系映射)框架,而Flask中的flask-sqlalchemy其实就是在sqla ...
- mysql、pymysql、SQLAlchemy
1.MySQL介绍 http://www.cnblogs.com/wupeiqi/articles/5699254.html,基础操作参见此文章,此处不赘述. 安装:yum install mysql ...
- 14.python与数据库之mysql:pymysql、sqlalchemy
相关内容: 使用pymysql直接操作mysql 创建表 查看表 修改表 删除表 插入数据 查看数据 修改数据 删除数据 使用sqlmary操作mysql 创建表 查看表 修改表 删除表 插入数据 查 ...
- Python操作MySQL:pymysql和SQLAlchemy
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy pymsql pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb ...
- python运维开发(十二)----rabbitMQ、pymysql、SQLAlchemy
内容目录: rabbitMQ python操作mysql,pymysql模块 Python ORM框架,SQLAchemy模块 Paramiko 其他with上下文切换 rabbitMQ Rabbit ...
- pymysql和 SQLAlchemy在python下的使用
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy import create_engine, Table, Column, In ...
- 特殊汉字“𣸭”引发的对于字符集的思考;mysql字符集;sqlalchemy字符集设置;客户端字符集设置;
字符集.字符序的概念与联系 在数据的存储上,MySQL提供了不同的字符集支持.而在数据的对比操作上,则提供了不同的字符序支持. MySQL提供了不同级别的设置,包括server级.database级. ...
- mysql数据库----python操作mysql ------pymysql和SQLAchemy
本篇对于Python操作MySQL主要使用两种方式: 原生模块 pymsql ORM框架 SQLAchemy 一.pymysql pymsql是Python中操作MySQL的模块,其使用方法和MySQ ...
随机推荐
- 自学Zabbix9.2 zabbix网络发现规则配置详解+实战
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 自学Zabbix9.2 zabbix网络发现规则配置详解+实战 1. 创建网络发现规则 Conf ...
- 【CF960G】Bandit Blues(第一类斯特林数,FFT)
[CF960G]Bandit Blues(第一类斯特林数,FFT) 题面 洛谷 CF 求前缀最大值有\(a\)个,后缀最大值有\(b\)个的长度为\(n\)的排列个数. 题解 完完全全就是[FJOI] ...
- 用DotNetOpenAuth实现基于OAuth 2.0的web api授权 (一)Getting Start
1. 下载 源码下载 2. build solution,创建虚拟目录: 右健MyContatacts/MyPromo项目,选择Properties,点击左边的Web,点击 Create Virtua ...
- es某个分片受损或卡在INITIALIZING状态时解决办法
参考这篇文章 # OK last warning: you will probably lose data. Don't do this if you can't risk that. CLUSTER ...
- 调用系统命令之subprocess模块
除了常见的os.system和os.popen方法,官方强烈推荐使用subprocess来调用系统命令. 这个库用起来其实很简单,按照惯例先贴一下官文关键点: The subprocess modul ...
- [ZJOI2007]矩阵游戏——非常漂亮的二分图转化
题意: 小 Q 是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏――矩阵游戏.矩阵游戏在一个 N×N 黑白方阵进行(如同国际象棋一般,只是颜色是随意的).每次可以对该矩阵进行两种操作: ...
- zookeeper配置
原文链接:https://www.cnblogs.com/yuyijq/p/3438829.html 前面两篇文章介绍了Zookeeper是什么和可以干什么,那么接下来我们就实际的接触一下Zookee ...
- Netty 4.1 Getting Start (翻译) + Demo
一.先来官方入门页面的翻译(翻译不好请多包涵) 入门 本章以简单的例子来介绍Netty的核心概念,以便让您快速入门.当您阅读完本章之后,您就能立即在Netty的基础上写一个客户端和一个服务器. 如果您 ...
- idea中的language level 介绍
language level 介绍 其他 IDE 没有看到类似 language level 的设置,所以这个功能应该算是 IntelliJ IDEA 特有的,可是 IntelliJ IDEA 官网也 ...
- R语言 画图roc
这才是我要的滑板鞋~~~~~ #glm模型glm.model=train(y~.,data=data_train, method="glm", metric="ROC&q ...