论文阅读-使用隐马模型进行NER
Named Entity Recognition in Biomedical Texts using an HMM Model 2004年,引用79
1.摘要
Although there exists a huge number of biomedical texts online, there is a lack of tools good enough to help people get information or knowledge from them. Named entity Recognition (NER) becomes very important for further processing like information retrieval, information extraction and knowledge discovery. We introduce a Hidden Markov Model (HMM) for NER, with a word
similarity-based smoothing. Our experiment shows that the word similarity-based smoothing can improve the performance by using huge unlabeled data. While many systems have laboriously hand-coded rules for all kinds of word features, we show that word similarity is a potential method to automatically get word formation, prefix, suffix and abbreviation information automatically from biomedical texts, as well as useful word distribution information.
虽然网上有大量生物医学文本,但是缺乏足够好的工具还帮助人们从中获取信息和知识。NER对进一步的处理,像信息检索、信息提取和知识发现变得非常重要。我们引入了对NER的HMM模型,包括基于单词相似度的平滑。实验表明,通过使用大量无标签数据,基于单词相似度的平滑能够提高效果。尽管许多系统对于各种文字特征都有费力的手工编码规则,但我们表明,单词相似度是一个潜在方法,可以从生物文本中自动获取单词格式、前缀、后缀和缩写信息,以及有用的单词分布信息。
2.使用数据
标记数据是:GENIA 3.02
无标记数据:17G XML abstract data from MEDLINE, which contains 1,381,132 abstracts.
3.分布单词相似性
Proximity-based Similarity
上下文的单词具有依赖关系,那么这个依赖关系可以通过一个小窗口的共存来表示,根据这个定义了如何去给word单词定特征。
We define the features of the word w to be the first non-stop word on either side of w and the intervening stop words。
例如:
“He got a job from this company.” (Considering a, from and this to be stop words.)
什么是停止stop单词?就是:which can be defined as the top-k most frequent words in the corpus.在语料库种出现次数多的(很明显是在标记的数据集中。)

//有一个疑问,如果是对每个单词都有一个独特的Feature(根据其寻找的规则,那么应该是不同的),那么很明显单词之间的特征向量维度是不同的啊。那么本论文里的特征向量一般是几维左右的?并没有提及。
计算单词相似度
既然单词可以用特征向量来表示了,那么两个单词之间的相似度也可以计算了,是使用余弦相似度。但是并不是特征向量的余弦相似度。
The point-wise mutual information (PMI) between a feature fi and a word u measures the strength association between them.
特征fi和单词u之间的点方向互信息( PMI )测量它们之间的强度关联。
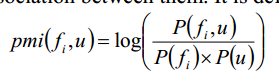

那么,其实只要一旦有了特征(可能是我现在NLP知识还太贫乏,不知道这个特征是依据这么来找的),就可以计算了所有的pmi(fi,u)了,并且计算sim(u,v)。
//想看它们的代码是怎么写的,我还是有点想知道这个特征向量长什么样子。
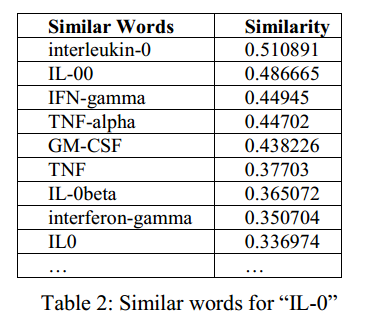
比如图2中的计算结果,是IL-0的相似单词。
Only a subset of the similarity information is useful, because the similarity of words outside of the training data and test data vocabulary is not used.
但是计算出来的相似信息,只有相似性信息的子集是有用的,因为不使用训练数据和测试数据词汇之外的单词的相似性。(这里是说交集?)
//也就是最终模型的验证还是得用标记数据。大量的非标记数据只是用来计算相似单词的。
并且从上图中可以发现摘要中关于能够自动获取单词的更多格式信息。
4.将平滑运用到隐马模型中
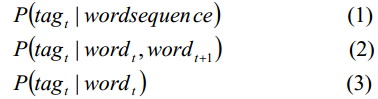
1式是正常的隐马模型,但是计算困难;使用2式进行近似计算;如果训练数据中没有这个二元模型,那么使用3式;如果没有这个一元模型,那么就是用从训练集中获取的低频率单词。
//最后一句不太明白。为什么,要用低频的呢?忽然明白,因为这个词都没有再训练集中出现,那么肯定是概率比较低的,那就用其他的低频替代了?后面它的方法的意思是直接忽略,这样模型的F值更高。

//这个4式是怎么计算的?sim是从无标签数据中得到的,但是分子上的P(tagt|w't)是怎么计算的?这就比较奇怪了。
S(w)是候选相似单词集和(为什么说时候选呢?因为之后会根据这个单词的频率进行筛选,较低的不计算在内),sim(w,w’) is the similarity between word w and w’. sim是相似值。
For each word w, we define p as the distribution of w’s tags, which are annotated in the training data.

使用KL散度来计算两个单词标签分布函数(概率模型)P的差距。
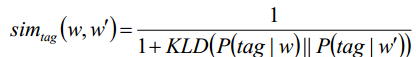
那么单词w和w'的标签分布相似度被定义为如上。
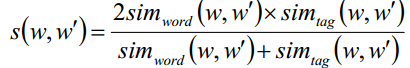
上式是一个调和平均值,是单词相似度和标签分布相似性,这个值来作为单词的相似度。
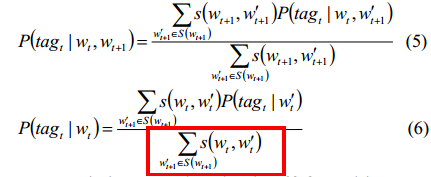
所以5式和6式分别用来平滑二元模型和一元模型。
//第6式的分布不太理解,为什么是w't+1呢?是它的下一个? 不太明白。
5.计算流程

//5和6不太明白。明明二元模型都没有,为什么还要用2?
1.检查二元模型(wt,wt+1)出现的频率,也就是两个单词连着出现的次数。
2.检测wt出现的次数
3.使用5进行二元平滑,并且对相似单词进行检查,如果出现次数>10。
4.使用6式进行单词平滑,
最终表现:

2比1表现好,因为它屏蔽了低频率的一元模型,我们的系统比1和2好,因为是没有使用低频率的一元和二元模型。
//其实不是很明白啊。什么意思呢?
论文阅读-使用隐马模型进行NER的更多相关文章
- 隐马尔科夫模型 HMM(Hidden Markov Model)
本科阶段学了三四遍的HMM,机器学习课,自然语言处理课,中文信息处理课:如今学研究生的自然语言处理,又碰见了这个老熟人: 虽多次碰到,但总觉得一知半解,对其了解不够全面,借着这次的机会,我想要直接搞定 ...
- HMM:隐马尔可夫模型HMM
http://blog.csdn.net/pipisorry/article/details/50722178 隐马尔可夫模型 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模 ...
- 隐马尔科夫模型(HMM)与词性标注问题
一.马尔科夫过程: 在已知目前状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变 (过去 ).例如森林中动物头数的变化构成——马尔可夫过程.在现实世界中,有很多过程都是马尔可夫过程,如液体 ...
- 隐马尔科夫模型(Hidden Markov Models)
链接汇总 http://www.csie.ntnu.edu.tw/~u91029/HiddenMarkovModel.html 演算法笔记 http://read.pudn.com/downloads ...
- Atitit 马尔可夫过程(Markov process) hmm隐马尔科夫。 马尔可夫链,的原理attilax总结
Atitit 马尔可夫过程(Markov process) hmm隐马尔科夫. 马尔可夫链,的原理attilax总结 1. 马尔可夫过程1 1.1. 马尔科夫的应用 生成一篇"看起来像文章的 ...
- 一文搞懂HMM(隐马尔可夫模型)
什么是熵(Entropy) 简单来说,熵是表示物质系统状态的一种度量,用它老表征系统的无序程度.熵越大,系统越无序,意味着系统结构和运动的不确定和无规则:反之,,熵越小,系统越有序,意味着具有确定和有 ...
- [综]隐马尔可夫模型Hidden Markov Model (HMM)
http://www.zhihu.com/question/20962240 Yang Eninala杜克大学 生物化学博士 线性代数 收录于 编辑推荐 •2216 人赞同 ×××××11月22日已更 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
随机推荐
- genieacs Installation on Ubuntu14.04
Beside the installation guide on the main page, here is a guide to install GenieACS off a freshly in ...
- RandomForest中的feature_importance
随机森林算法(RandomForest)的输出有一个变量是 feature_importances_ ,翻译过来是 特征重要性,具体含义是什么,这里试着解释一下. 参考官网和其他资料可以发现,RF可以 ...
- FOREIGN MySQL 之 多表查询
一.多表联合查询 #创建部门 CREATE TABLE IF NOT EXISTS dept ( did int not null auto_increment PRIMARY KEY, dname ...
- 3D Slicer 4.7.0 VS 2010 Compile 编译
花了将近一周的时间的,终于在VS2010成功的编译了最新版的3D Slicer 4.7.0,感觉快要崩溃了.Slicer用了20多个外部的库,全都要一起编译,完整编译一次起码要七八个小时,光VS的Ou ...
- linux 下 sublime配置
sublime3 import urllib.request,os; pf = 'Package Control.sublime-package'; ipp = sublime.installed_p ...
- SparkContext.union 与 RDD.union
RDD.union,和SparkContext.union都可以将多个RDD聚合成一个UnionRDD. 但不同的是,RDD.union在每次操作时,会创建一个新的数据集合,生成新的RDD,新的RDD ...
- [No0000162]如何不靠运气致富|来自硅谷著名天使投资人的40条致富经
1. Seek wealth, not money or status. Wealth is having assets that earn while you sleep. Money is how ...
- [No0000139]轻量级文本编辑器,Notepad最佳替代品:Notepad++
在详细介绍Notepad++之前,先来解释一下,为何要选择Notepad++,即把常见的一些文本编辑器和Notepad++比较,看看其有哪点好: 常见的文本编辑器有很多,此处,只提及Notepad,N ...
- data-original
<img class="lazy" style="display: inline;" alt="开光纯铜牛摆件" src=" ...
- iPhone开发之使用NSUserDefaults存储数据
NSUserDefaults是什么,有什么用处 对于应用来说,每个用户都有自己的独特偏好设置,而好的应用会让用户根据喜好选择合适的使用方式,把这些偏好记录在应用包的plist文件中,通过NSUserD ...