HBase 安装snappy压缩软件以及相关编码配置
HBase 安装snappy压缩软件以及相关编码配置
前言
在使用HBase过程中因为数据存储冗余、备份数等相关问题占用过多的磁盘空间,以及在入库过程中为了增加吞吐量所以会采用相关的压缩算法来压缩数据,降低存储空间和在入库过程中通过数据压缩提高吞吐量。
HBase-2.1.5
Hadoop-2.7.7
一、HBase安装Snappy压缩软件
snappy-1.1.3下载地址:
wget wget https://github.com/google/snappy/releases/download/1.1.3/snappy-1.1.3.tar.gz
sudo yum -y install gcc-c++ libstdc++-devel
#下面是通过命令直接安装,
sudo yum -y install snappy snappy-devel
$ wget wget https://github.com/google/snappy/releases/download/1.1.3/snappy-1.1.3.tar.gz
$ sudo yum install gcc-c++ libstdc++-devel #安装需要编译snappy的软件
$ tar -zxvf /home/zfll/soft/snappy-1.1.2.tar.gz
$ cd snappy-1.1.3
#安装完成之后重新进行./configure 然后 make
$ ./configure
$ make
$ sudo make install
hbase使用
snappy进行对数据压缩需要再Linux安装snaapy,安装完成之后需要对相关配置文件进行修改,snappy安装完成之后一般是在/usr/local/lib中生成snappy的依赖包
hadoop-2.7.7:因为使用的是当前版本,当前版本中实际上是整合了snappy依赖包的,所以不需要去重新编译一个带有snappy的版本
$ $HADOOP_HOME/bin/hadoop checknative -a
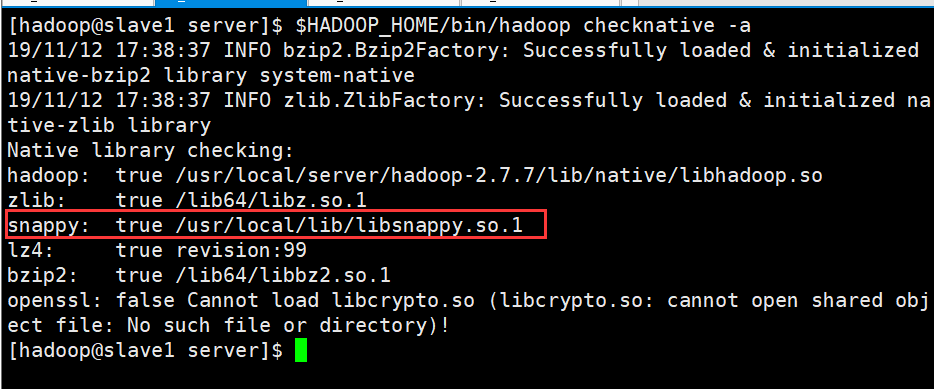
检查当前安装的hadoop版本是否带有snappy
如上图数据中是带有了相关的压缩程序依赖包的
在hadoop安装目录的hadoop/lib/native文件夹下存在如下内容:
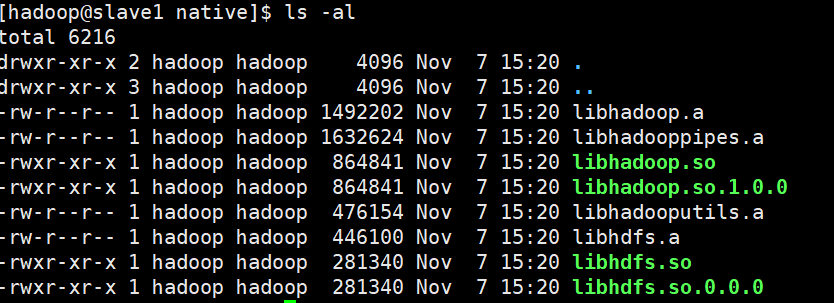
如上内容为在使用snappy压缩的是时候需要依赖的包,在当前版本中已经编译好了,不需要再自己编译版本
安装完成之后,在HBase中使用,使用的时候需要进行相关配置
将依赖复制到HBase目录
将$HADOOP_HOME/lib/native目录下的所有文件复制到$HBase/lib/native/linux-amd64-64目录中,目录不存在则新建
$ mkdir -p $HBASE_HOME/lib/native/linux-amd64-64
$ cp $HADOOP_HOME/lib/native $HBASE_HOME/lib/native/linux-amd64-64
注:上述操作在集群中所有节点都需要进行操作,使得各个节点上的snappy程序在解压缩的时候能够找到依赖
hbase/conf/hbase-site.xml
<property>
<name>hbase.regionserver.codecs</name>
<value>snappy</value>
</property>
在上述文件中添加如上配置
hbase/conf/hbase-env.sh
export HBASE_LIBRARY_PATH=$HBASE_LIBRARY_PATH:$HBASE_HOME/lib/native/linux-amd64-64/:/usr/local/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native/:/usr/local/lib
完成上述配置之后需要跟新hbase-env.sh环境变量,每个节点都更新避免问题,然后关闭HBase重新启动HBase
$ source $HBASE/conf/hbase-env.sh
$ ./$HBase_HOME/bin stop-hbase.sh
$ ./$HBASE_HOME/lib start-hbase.sh
验证是否能够使用
完成上述安装和配置之后需要进行验证
$ hbase shell
$ > CREATE 'snappyTest',{NAME=>'info',COMPRESESSION=>'snappy'}
通过上述命令进行创建一个使用压缩算法snappy的表,看是否能够创建成功,可以再通过一些数据读写操作进行验证
major_compact
参考:
<https://segmentfault.com/a/1190000013211406>
HBase 安装snappy压缩软件以及相关编码配置的更多相关文章
- 关于Hbase开启snappy压缩
版本:自己编译的hbase-1.2.0-cdh5.14.0 默认情况下,Hbase不开启snappy压缩 , 所以在hbase的lib/native目录下什么也没有(我的前提是执行hadoop che ...
- HBase里配置SNAPPY压缩以后regionserver启动不了的问题
配置了HBase的SNAPPY压缩以后,出现regionserver启动不了的问题.分析应该是属性配置错了! 官网上的是:<name>hbase.regionserver.codecs&l ...
- Hadoop 2.2.0和HBase-0.98 安装snappy
1.安装须要的依赖包及软件 须要安装的依赖包有: gcc.c++. autoconf.automake.libtool 须要安装的配套软件有: Java6.Maven 关于上面的依赖包,假设在ubun ...
- 压缩软件Snappy的安装
1.下载源码,通过编译源码安装 tar -zxvf /home/zfll/soft/snappy-1.1.2.tar.gz cd snappy-1.1.2 ./configure make sud ...
- HBase修改压缩格式及Snappy压缩实测分享
一.要点 有关Snappy的相关介绍可参看Hadoop压缩-SNAPPY算法,如果想安装Snappy,可以参看Hadoop HBase 配置 安装 Snappy 终极教程. 1. HBase修改Tab ...
- [转]Snappy压缩库安装和使用之一
Snappy压缩库安装和使用之一 原文地址:http://blog.csdn.net/luo6620378xu/article/details/8521223 近日需要在毕业设计中引入一个压缩库,要求 ...
- 转贴:sudo apt-get install 可以安装的一些软件
Ubuntu 下的一些软件安装sudo apt-get install virtualbox#华主席推荐 2007年年度最佳软件,最佳编辑选择奖得主.....sudo apt-get install ...
- hbase开放lzo压缩
hbase仅仅支持对gzip的压缩,对lzo压缩支持不好. 在io成为系统瓶颈的情况下,一般开启lzo压缩会提高系统的吞吐量. 但这须要參考详细的应用场景,即是否值得进行压缩.压缩率是否足够等等. ...
- 大数据: 完全分布式Hadoop集群-HBase安装
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. 本文基 ...
随机推荐
- jmeter事务控制器
jmeter事务控制器常用于压力测试时如果一个功能包括多个请求时,需要测试这个功能的压力情况,则需要把多个请求放到一个事务控制器里面
- LeetCode 面试题51. 数组中的逆序对
面试题51. 数组中的逆序对 题目来源:https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/ 题目 在数组中的两个数字,如果 ...
- The new SFCB broker fails to start with a SSL-related error: Failure setting ECDH curve name (secp22
# openssl ecparam -list_curves secp384r1 : NIST/SECG curve over a 384 bit prime field secp521r1 : NI ...
- How to use QueryPerformanceCounter? (c++,不使用 .Net)
出处:https://stackoverflow.com/questions/1739259/how-to-use-queryperformancecounter 参考:https://docs.mi ...
- [Inno Setup] 安装完成后调用函数
如果使用了通配符,每拷贝一个文件,函数都会被调用一次. Source: "path\test.exe"; DestDir: {app}; AfterInstall: LoadPer ...
- poj_1323 Game Prediction 贪心
Game Prediction Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 11814 Accepted: 5701 ...
- 【Linux常见命令】split命令
split - split a file into pieces 按照指定的行数或大小分割文件 语法: split [OPTION]... [INPUT [PREFIX]] Output fixed- ...
- iOS Block 页面传值
为什么80%的码农都做不了架构师?>>> 直接上代码 1.定义block @interface TopTypeCollectionView : UIView @property ...
- 解决w3wp.exe占用CPU和内存问题
在WINDOWS2003+IIS6下,经常出现w3wp的内存占用不能及时释放,从而导致服务器响应速度很慢.可以做以下配置进行改善:1.在IIS中对每个网站进行单独的应用程序池配置.即互相之间不影响.2 ...
- Python自动化运维一之psutil
1.1系统性能信息模块psutil 1.1.1下载安装psutil 1. wget https://pypi.python.org/packages/source/p/psutil/psutil- ...